
Ping vs Http monitoring – Which one to choose?
Understanding and diagnosing network issues is critical for any organization that uses the internet to interact with customers. Ping and HTTP monitoring are important resources for network managers and webmasters who want to keep their networks running smoothly and fix problems. Each tool has a distinct purpose, providing insight into various layers of network and application operation.
What is Ping Monitoring?
- What it does: Ping monitoring uses the ICMP (Internet Control Message Protocol) to check the availability of a network device (such as servers, routers, or switches) on the network. It sends a packet of data to a specific IP address and waits for a reply, measuring the time taken for the round-trip.
- Purpose: Its primary purpose is to check the reachability of the host and the round-trip time (RTT) for messages sent from the originating host to a destination computer.
- Use Cases: It is widely used for basic network troubleshooting to check if a host is up and running on the network. It helps in identifying network connectivity issues and the presence of firewalls or network congestion.
- Limitations: Ping monitoring does not provide information about the performance of higher-level protocols (like HTTP) or application-specific issues. It merely tells you if the host is reachable, not if a web service or application is functioning correctly.
HTTP Monitoring:
- What it does: HTTP monitoring involves sending HTTP requests (such as GET or POST) to a web server and evaluating the responses. It checks the status and performance of websites or web services by simulating user access.
- Purpose: The primary purpose is to ensure that a web server is available and responsive from the user’s perspective. It can check for specific content in the response, measure response times, and verify that a web application is functioning as expected.
- Use Cases: It is used to monitor the health and performance of websites and web services. HTTP monitoring can alert administrators to issues with web pages, application errors, or server misconfigurations that affect the user experience.
- Limitations: HTTP monitoring is more resource-intensive than ping monitoring and is specific to web services. It might not detect lower-level network issues that ping could identify, such as problems with network hardware or connectivity issues not related to the HTTP protocol.
To be honest, ping monitoring is a simpler, faster way to evaluate a device’s basic network connectivity and reachability, but HTTP monitoring gives a more in-depth, application-level view of web service availability and performance. Both are complimentary and are frequently used in conjunction to provide comprehensive network and application monitoring techniques. However, the subject of which Monitoring metric is best for you is something we will try to address in this article.
Monitor PING or HTTP?
Choosing between ping and HTTP monitoring depends on what you aim to monitor and the depth of insight you need into your network or web services. Here’s a guideline on which one to use and when:
Use Ping Monitoring When:
- Basic Network Health Checks: You need a quick, straightforward method to check if devices on your network (servers, routers, etc.) are reachable.
- Initial Troubleshooting: You’re diagnosing network connectivity issues, such as whether packets are being lost or if a particular host is down.
- Network Performance: You want to measure network latency and packet loss between two points in the network.
- Simple, Low-Resource Monitoring: You require a low-overhead method to continuously monitor the up/down status of a large number of devices across different locations.
Ping monitoring is ideal for getting a high-level view of network health and is often used as the first step in troubleshooting network issues.
Use HTTP Monitoring When:
- Web Service Availability: You need to ensure that web servers are not just reachable but also serving content correctly to users.
- Application Health Checks: You’re monitoring the performance and functionality of web applications, including error codes, response times, and content accuracy.
- End-User Experience: You want to simulate and measure the experience of a user interacting with a website or web service, ensuring that web pages load correctly and within acceptable time frames.
- Detailed, Application-Level Insight: You require detailed insights into HTTP/HTTPS protocol-level performance and behavior, including status codes, headers, and content.
HTTP monitoring is more suitable for web administrators and developers who need to ensure the quality of service (QoS) of web applications and services from an end-user perspective.
Combining Both for Comprehensive Monitoring:
In many scenarios, it’s beneficial to use both ping and HTTP monitoring together to get a full picture of both network infrastructure health and application performance. This combined approach allows network administrators and webmasters to quickly identify whether an issue is at the network layer or the application layer, facilitating faster troubleshooting and resolution.
- Initial Network Check: Use ping monitoring to verify that the network path to the server is clear and that the server is responding to basic requests.
- Application Layer Verification: Follow up with HTTP monitoring to ensure that the web services and applications hosted on the server are functioning correctly and efficiently.
By employing both methods, you can ensure a comprehensive monitoring strategy that covers both the infrastructure and application layers, helping to maintain high availability and performance.
What are limitations?
Ping Monitoring Limitations
Ping monitoring, while useful for basic network diagnostics and availability checks, has several limitations:
- Does Not Indicate Service Availability: Ping monitoring only tests the reachability of a host on the network. A server can respond to ping requests while the actual services (like a web server or database) on that host are down or malfunctioning.
- ICMP Blocking: Some networks or firewalls block ICMP traffic (which ping uses) for security reasons. In such cases, a host might appear unreachable via ping, even though it’s functioning correctly and accessible through other protocols like HTTP or SSH.
- Limited Diagnostic Information: Ping provides minimal information — essentially, whether a host is reachable and the round-trip time of packets. It doesn’t give any insights into why a service might be down or the quality of service beyond basic latency.
- No Application-Level Insights: Ping cannot monitor the performance or availability of application-level processes. It won’t help in understanding issues related to web page load times, database query performance, or the health of any application beyond network reachability.
- Potential for Misinterpretation: Network administrators might misinterpret the success of ping tests, assuming that because a server is responding to ping, all services on that server are operational, which might not be the case.
- Network Prioritization Issues: ICMP packets used in ping might be treated with lower priority compared to actual application traffic. During times of network congestion, ping packets might be dropped or delayed, suggesting a problem when the application traffic is flowing normally.
- False Positives/Negatives: Due to ICMP blocking or prioritization, ping monitoring might lead to false positives (indicating a problem when there isn’t one) or false negatives (indicating no problem when there actually is one), especially in environments with strict firewall rules or Quality of Service (QoS) policies.
Despite these limitations, ping monitoring is still a valuable tool in a network administrator’s toolkit for quick checks and initial diagnostics. It is most effective when used in conjunction with other monitoring tools that can provide deeper insights into network and application performance.
HTTP Monitoring Limitations
HTTP monitoring, while powerful for measuring the availability and performance of online services, has also a number of limitations:
- Higher Overhead: Unlike simple ICMP ping requests, HTTP requests require more resources to send and process, both on the monitoring system and the target server. This could impact performance, especially if monitoring is frequent or targets multiple web services.
- Limited to HTTP/HTTPS Protocols: HTTP monitoring is specific to web services and applications that use the HTTP or HTTPS protocols. It cannot directly monitor the status of non-web services or lower-level network issues that might affect overall system performance.
- Does Not Detect Network-Level Issues: While HTTP monitoring can indicate when a web service is down or performing poorly, it may not identify the underlying network-level issues, such as routing problems or network congestion, that could be causing the problem.
- Complex Configuration: Setting up detailed HTTP monitoring (for example, to check the content of a response or to simulate user interactions with a web application) can be complex and time-consuming, requiring in-depth knowledge of the monitored applications.
- False Alarms Due to Content Changes: Monitoring for specific content within a web page response can lead to false alarms if the content changes regularly. Administrators need to constantly update the monitoring parameters to avoid this.
- Dependency on External Factors: HTTP monitoring’s effectiveness can be influenced by external factors such as DNS resolution issues, third-party content delivery networks (CDNs), and external web services. These factors might affect the performance metrics, making it harder to pinpoint issues.
- Security and Access Control Issues: Web applications with authentication, cookies, or session management might require additional configuration to monitor effectively. This could introduce security concerns or complicate setup, especially for secure or sensitive applications.
- Limited Insight into Application Logic: While HTTP monitoring can confirm that a web page is loading or that an application endpoint is responsive, it may not provide insight into deeper application logic issues or database performance unless specifically configured to test those functionalities.
To mitigate these limitations, it’s often best to use HTTP monitoring as part of a broader monitoring strategy that includes other tools and methods. This approach allows for a more comprehensive understanding of both application performance and underlying infrastructure health.
Monitoring from Multiple locations?
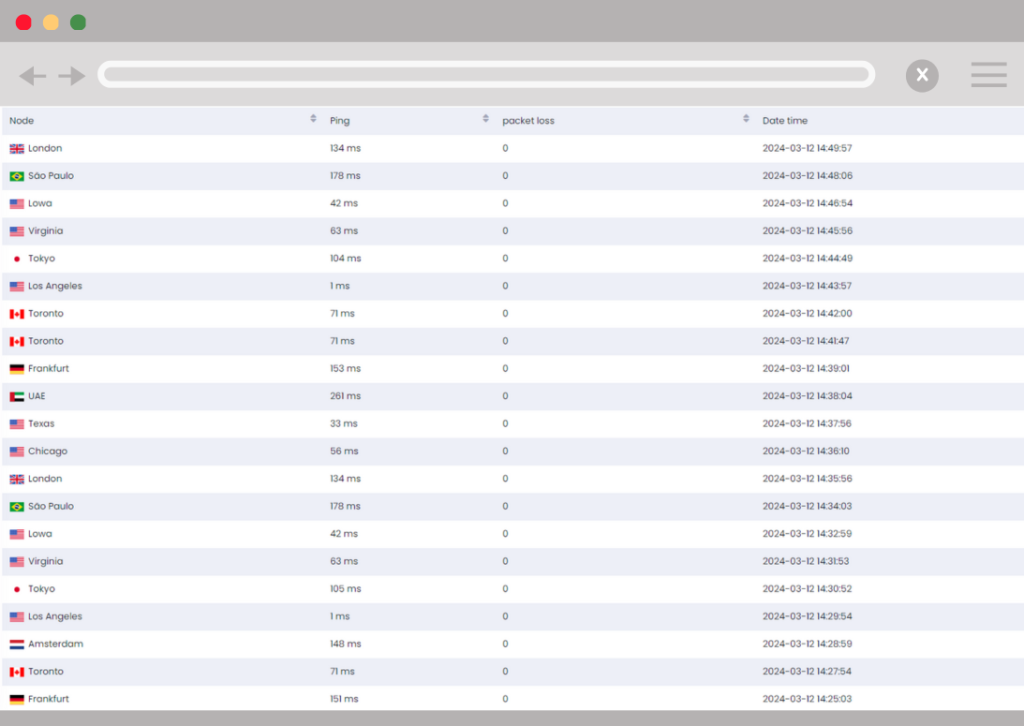
Monitoring multiple geographical locations may considerably improve server performance analysis and optimization efforts, especially for companies serving a worldwide audience. With Xitoring’s global nodes you are able to get your services monitored from more than 15 locations around the world, which is helping you to increase performance of your server and applications.
- Identifying Geographic Performance Variances – Monitoring from multiple locations allows you to find differences in how users view your service throughout the world. For example, a server may react rapidly to queries from one location but slowly to others owing to network latency, routing pathways, or regional internet service provider (ISP) difficulties. Identifying these variations enables focused optimization.
- Load Balancer Effectiveness – Multi-location monitoring allows for reviewing the performance of load balancing strategies used across several servers or data centers. It helps to guarantee that traffic is dispersed equally and that all users, regardless of location, receive efficient service.
- Network Path and Latency Issues – Monitoring from various locations allows you to trace the network paths data takes to reach different users and identify potential bottlenecks or latency issues within those paths. With this information, you can work with ISPs, choose better hosting locations, or implement network optimizations to improve data delivery routes.
- Disaster Recovery and Failover Testing – Multi-location monitoring can be crucial for testing the effectiveness of disaster recovery and failover systems. By simulating access from different regions, you can ensure that these systems activate correctly in response to an outage and that users are rerouted to backup systems without significant performance degradation.
- Optimizing for Mobile Users – Considering the variability of mobile networks across regions, monitoring from multiplie locations can help optimize performance for mobile users. This includes adjusting for slower mobile networks or optimizing content delivery for the specific characteristics of mobile connectivity in different areas.
Did you know you can start monitoring your websites from multiple locations around the world for free?