InfluxDB Überwachung
Überwachen Sie den Schreibdurchsatz von InfluxDB, die Abfrageleistung, Kennzahlen der Speicher-Engine und den Zustand der Aufbewahrungsrichtlinien in Echtzeit – ganz ohne Konfiguration.
Warum überwachen Sie InfluxDB?
InfluxDB ist die führende Zeitreihendatenbank für Metriken, Ereignisse und Echtzeitanalysen. Durch die Überwachung von InfluxDB werden eine reibungslose Dateneingabe, eine optimale Abfrageleistung und ein ordnungsgemäßes Aufbewahrungsmanagement gewährleistet.
InfluxDB-Monitoring, erklärt
InfluxDB-Monitoring erfasst Write-Throughput-Stalls, ausufernde Series-Kardinalität (der klassische Ausfallmodus von InfluxDB 1.x/2.x), TSM-Compaction-Rückstände, langsame Queries und WAL-Wachstum, bevor sie Ingest-Verluste oder Query-Timeouts auf Ihren Grafana-Dashboards verursachen. Für IoT-Sensor-Pipelines, Application-Metrics-Backends und jede TICK-Stack-Bereitstellung ist die Sichtbarkeit pro Datenbank das, was einen 60-Sekunden-Alarm von einem mehrstündigen Incident auf der Suche nach fehlenden Datenpunkten unterscheidet. Xitoring erkennt Ihre InfluxDB automatisch, liest den nativen /metrics-Prometheus-Endpunkt und leitet Alarme an Slack, PagerDuty, Telegram oder Ihre bestehende Rufbereitschaft.
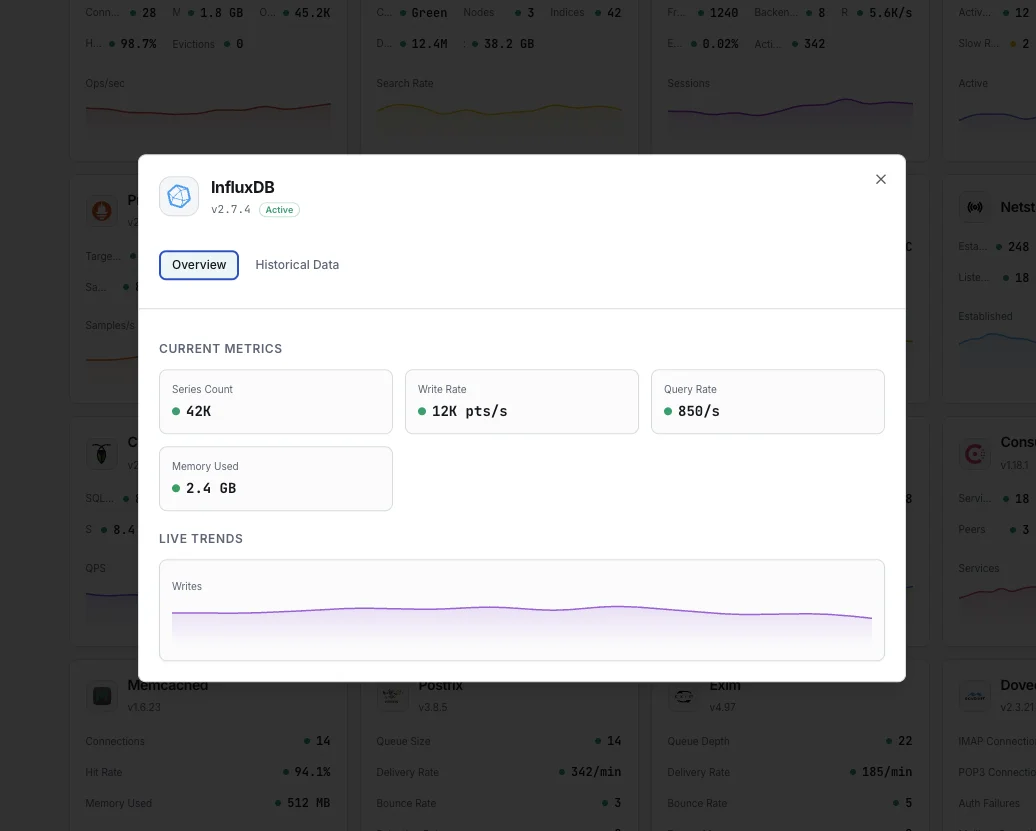
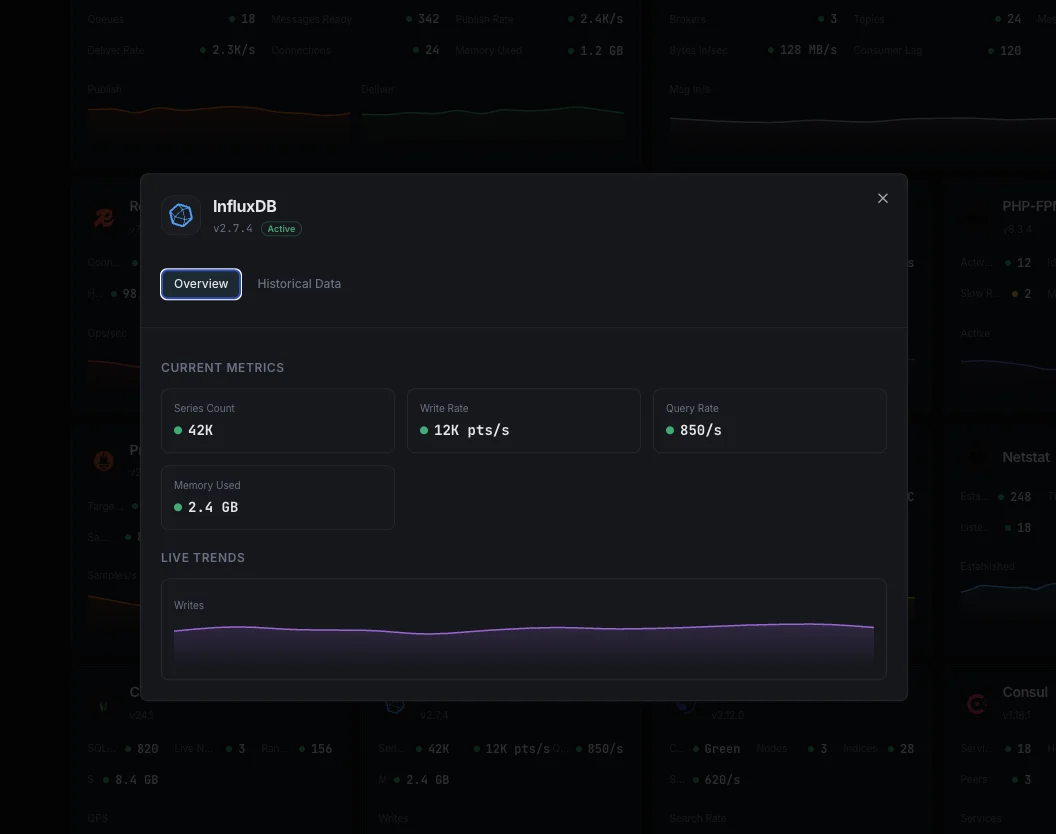
Was wir überwachen
Write Points/Sek.
Rate der geschriebenen Datenpunkte.
Abfragedauer
Durchschnittliche Abfrageausführungszeit.
Series-Kardinalität
Gesamtanzahl der eindeutigen Zeitreihen.
Speichergröße
TSM-Speicher auf der Festplatte.
Compaction-Rate
TSM-Compaction-Durchsatz.
Cache-Größe
In-Memory-Schreibcache-Nutzung.
WAL Disk Bytes
`storage.tsm1.wal.currentSegmentDiskBytes` + `oldSegmentsDiskBytes`. WAL-Wachstum ohne TSM-Konsolidierung bedeutet, dass die Recovery-Zeit beim Neustart explodieren wird.
Storage-Größe auf der Disk
`storage.tsm1.filestore.diskBytes` + numFiles pro Shard. Verfolgen Sie das gegen Ihre Retention Policy — hohe Dateianzahlen bei gleicher Datengröße deuten auf Fragmentierung hin.
HTTP 4xx / 5xx Rate
`httpd.clientError` + `httpd.serverError` (oder Prometheus `http_api_request_errors_total`). 4xx-Spitzen deuten auf Client-Schema-/Auth-Bugs hin; 5xx auf serverseitige Fehler.
Verbindungen / Auth-Fehler
`httpd.req` (gesamte HTTP-Requests), `httpd.authFail` (fehlgeschlagene Auth-Versuche), `httpd.pingReq`. Auth-Fehler-Spitzen weisen auf fehlkonfiguriertes Telegraf oder eine schiefgelaufene Credential-Rotation hin.
Runtime — Goroutines & GC
Go-Runtime-Stats: `runtime.NumGoroutine` (Goroutine-Leak-Erkennung), `runtime.HeapAlloc` (Live-Heap), `runtime.NumGC`/`PauseTotalNs` (GC-Druck). Leaks und Pause-Zeit-Regressionen erkennen, bevor es zu OOM kommt.
Subscription-Writes
`subscriber.pointsWritten` und `subscriber.writeFailures` — wenn Kapacitor oder nachgelagerte Pipelines über Subscriptions konsumieren, ist das der Weg, ihren Backpressure zu erkennen.
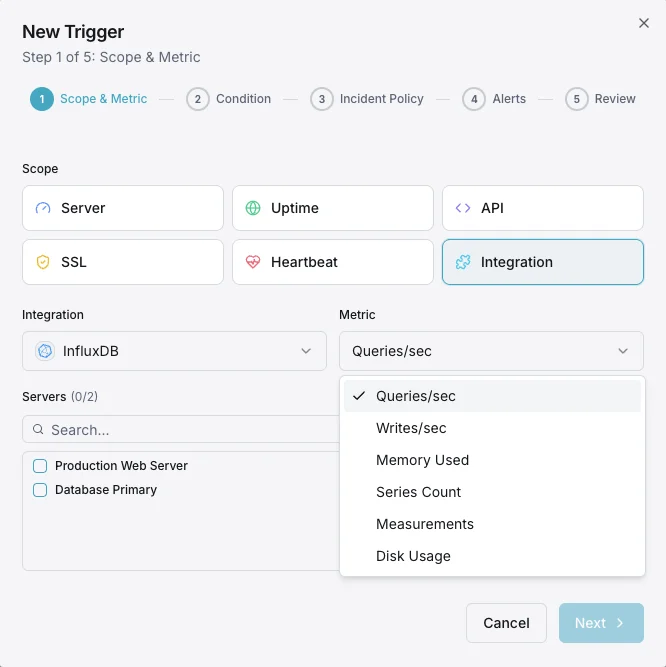
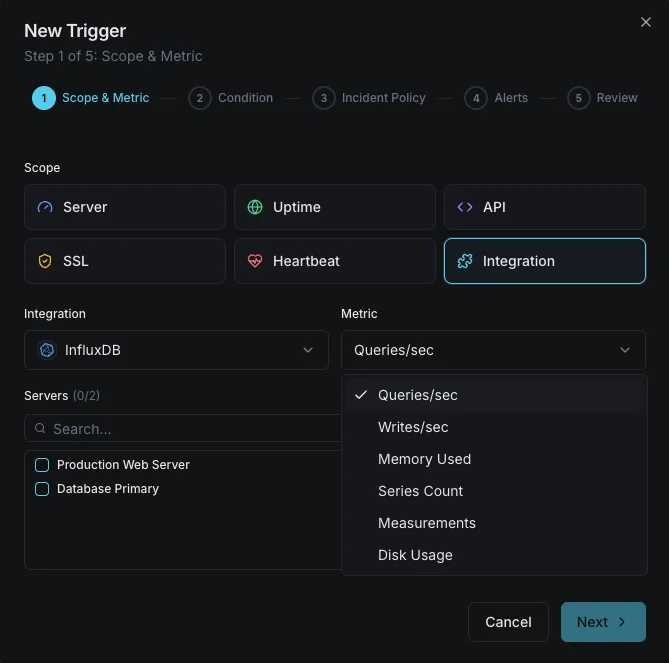
Konfigurierbare Alarmauslöser
Richten Sie benutzerdefinierte Trigger in Ihrem Dashboard ein, um benachrichtigt zu werden, sobald die Kennzahlen von „InfluxDB“ Ihre festgelegten Schwellenwerte überschreiten.
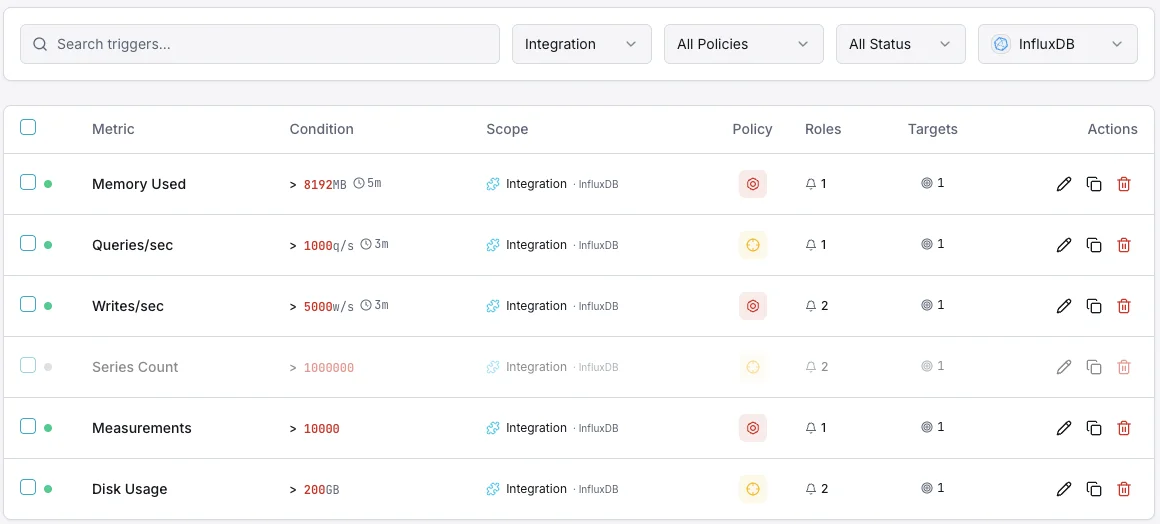
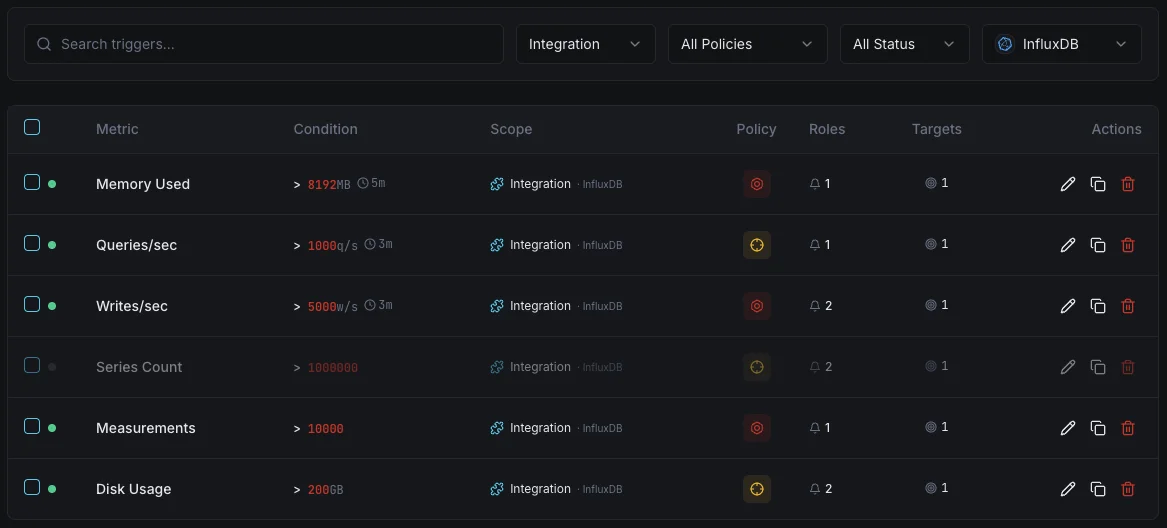
Schreibdurchsatz
WarnungWird bei Anomalien der Schreibrate ausgelöst.
Abfragedauer
WarnungWarnungen bei langsamen Abfragen.
Series-Kardinalität
entscheidendWird ausgelöst, wenn die Kardinalität zu hoch ist.
Speichergröße
entscheidendWird ausgelöst, wenn der Speicherplatz den Schwellenwert überschreitet.
Bedeutung von InfluxDB-Überwachung
InfluxDB verarbeitet schnelllebige Zeitreihendaten. Hohe Kardinalität, Schreibdruck und Compaction-Verzögerungen können die Leistung beeinträchtigen.
- Schreibdurchsatz verfolgen, um die Ingestion-Gesundheit sicherzustellen
- Series-Kardinalität überwachen, um OOM-Situationen zu vermeiden
- Langsame Abfragen frühzeitig erkennen
- Sicherstellen, dass die Compaction Schritt hält
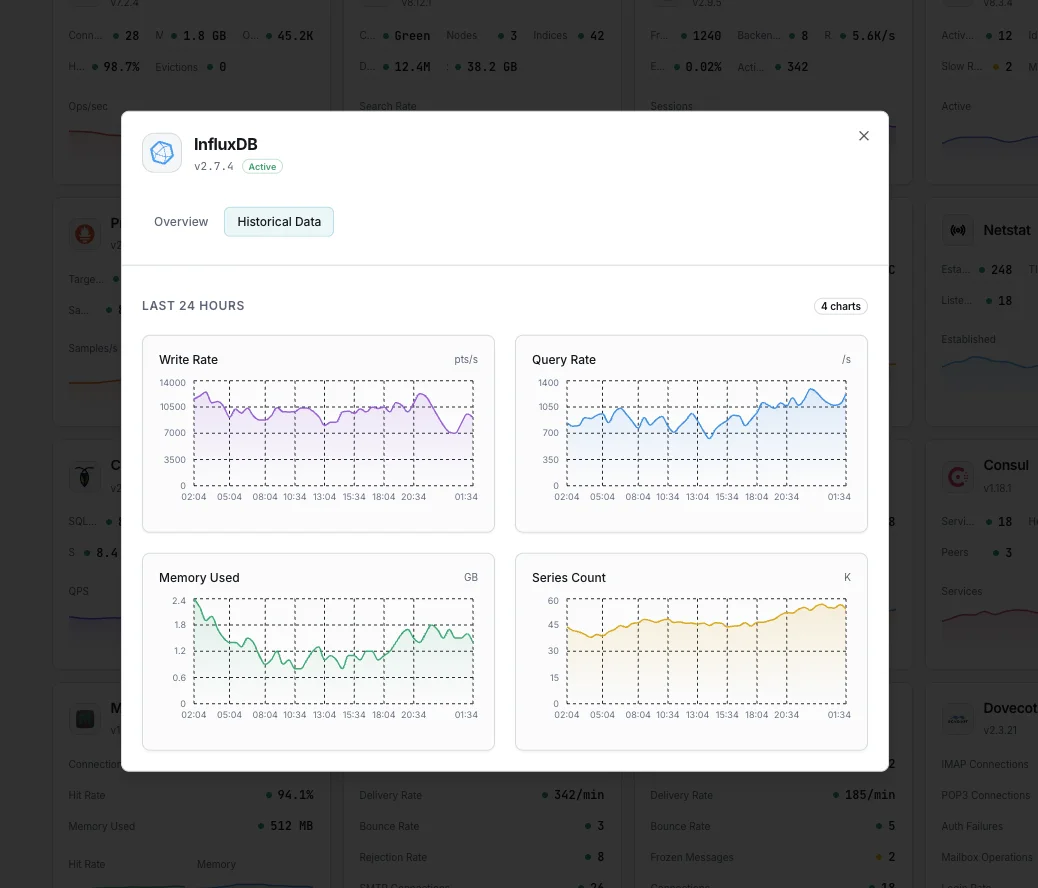
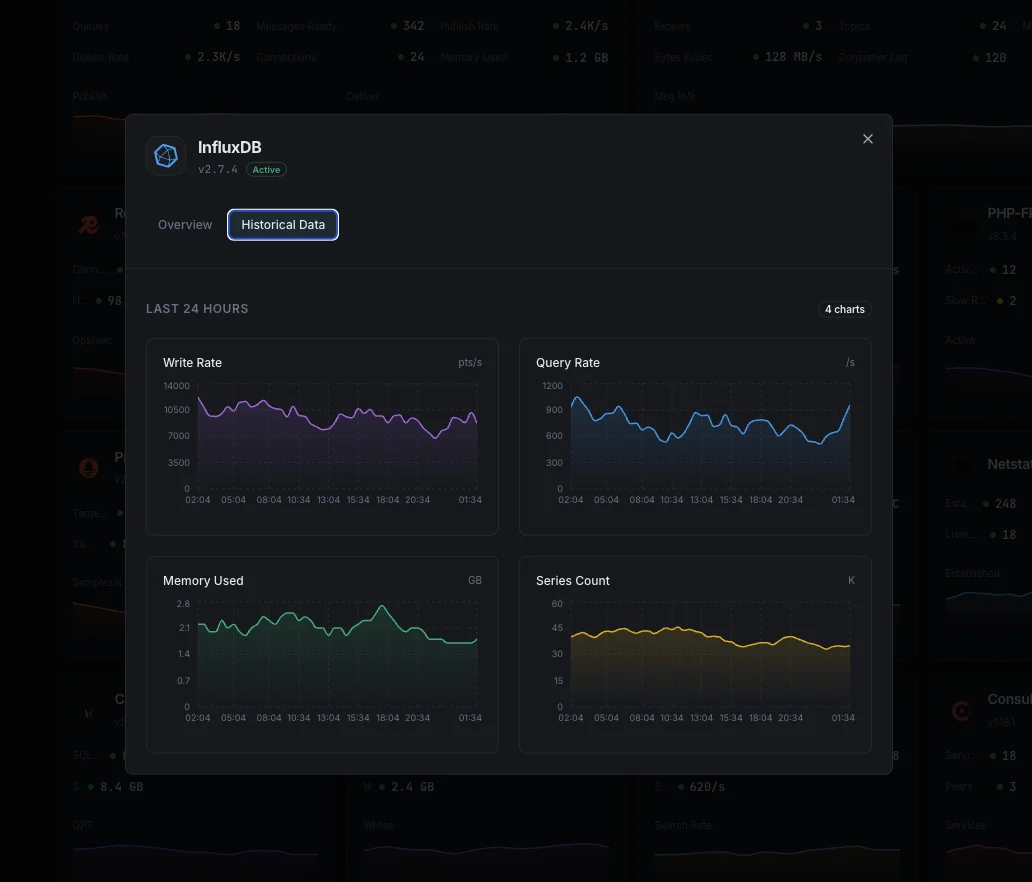
Warum entscheiden Sie sich für Xitoring
Zero-Config-InfluxDB-Überwachung.
- Installation mit einem einzigen Befehl
- Globale Knoten
- Zentrales Dashboard
- Benachrichtigungen über mehrere Kanäle
- Aufbewahrungsfristen
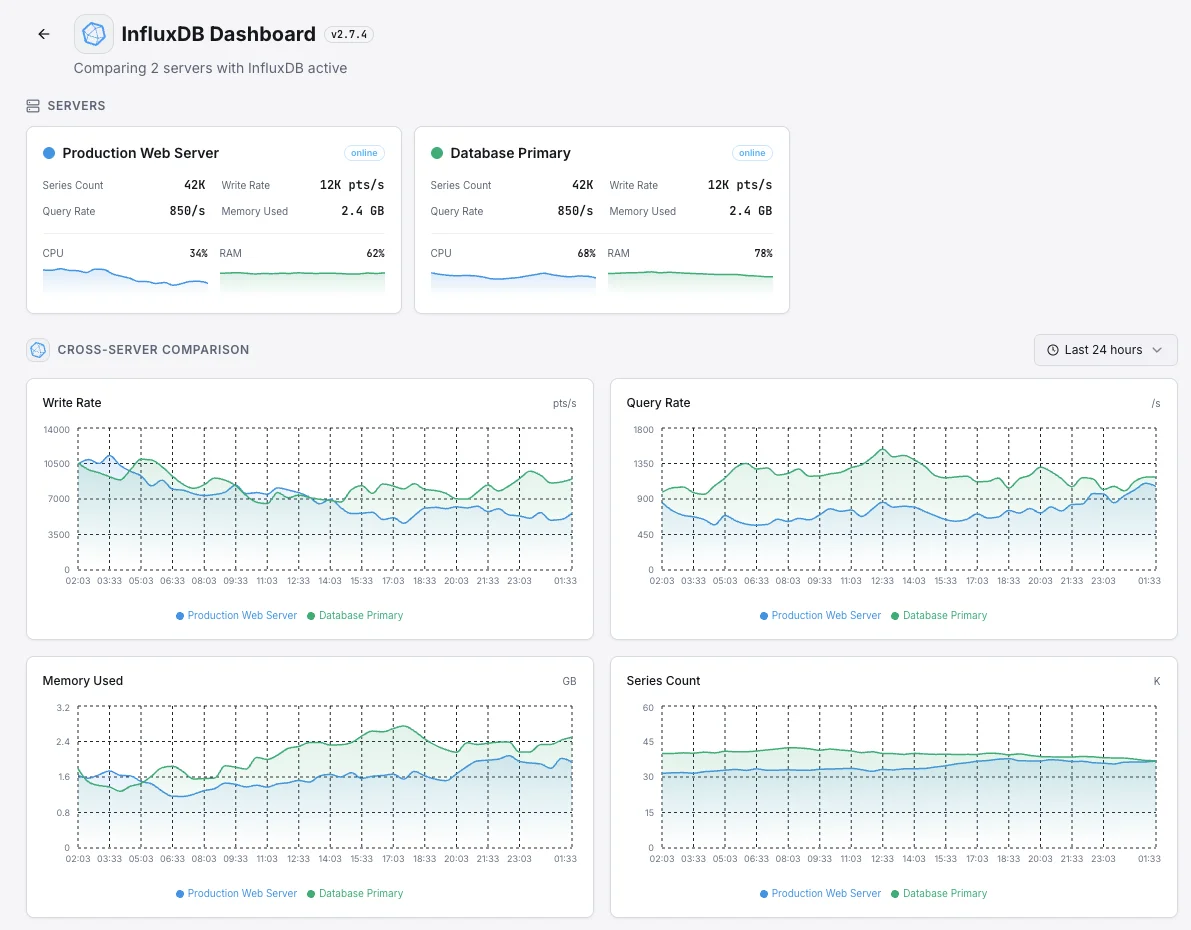
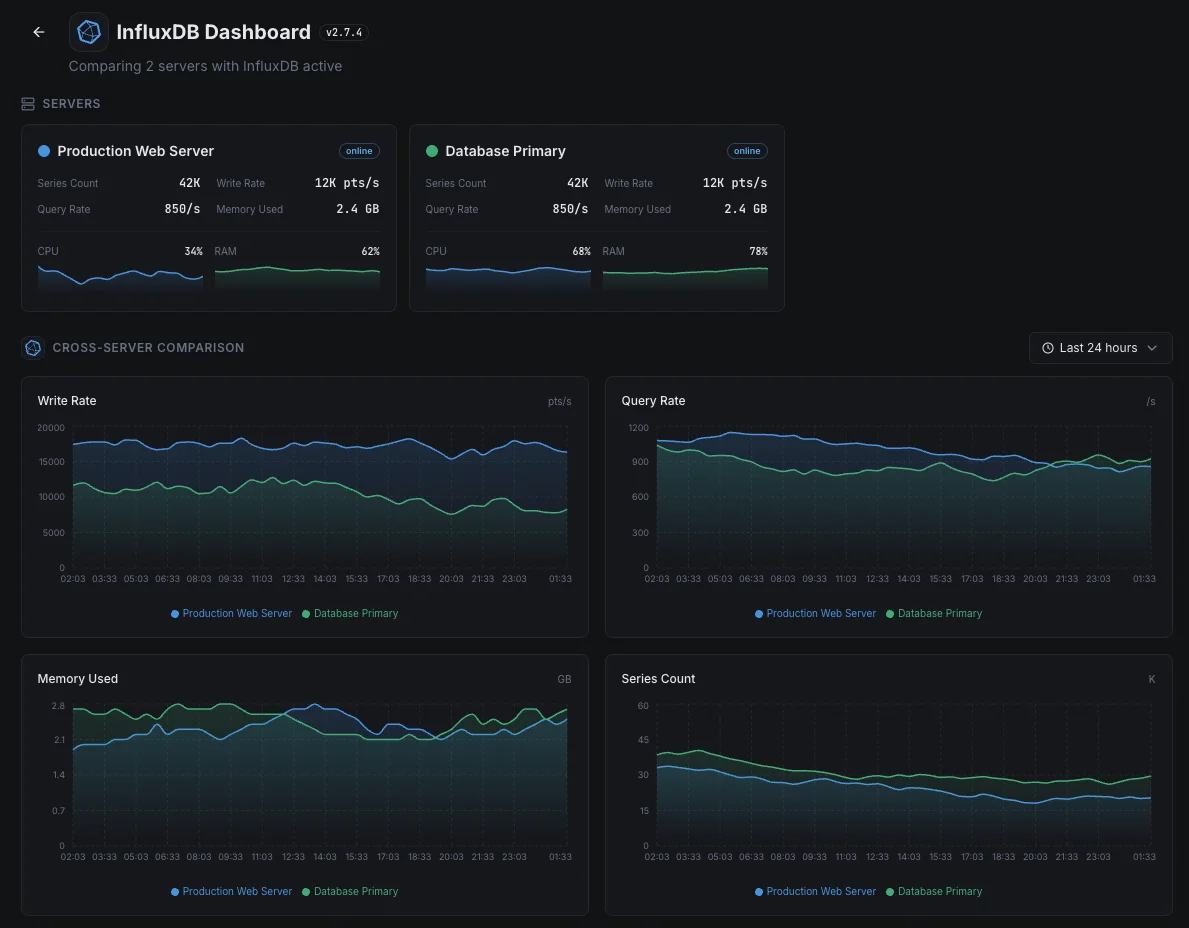
Häufige InfluxDB-Monitoring- Szenarien
Wo InfluxDB heute typischerweise läuft – und was schiefgehen könnte, wenn niemand aufpasst.
Die Datenbank hinter den Dashboards Ihres Teams
Wenn Dashboards in Grafana oder einem anderen Tool langsam erscheinen, liegt die Ursache oft in der darunterliegenden Datenbank – nicht im Dashboard selbst. Wir zeigen auf, wo die Langsamkeit tatsächlich liegt, damit das Team das Richtige behebt, anstatt dem Symptom hinterherzujagen.
Datenfluss von Sensoren und Geräten
Verbundene Geräte, Fabrikausrüstung und IoT-Sensoren senden jede Sekunde jedes Tages Messwerte. Ein stiller Rückstau in der Pipeline bedeutet Datenverlust – und verlorene Daten sind für immer verloren. Wir überwachen den Fluss von Ende zu Ende, damit ein einziger verlorener Messwert Alarm auslöst.
App- und Infrastrukturmetriken an einem Ort
Wenn dieselbe Datenbank sowohl App-Metriken als auch Server-Metriken enthält, verbirgt ein Problem mit der Datenbank alle Signale auf einmal. Wir überwachen die Datenbank selbst, damit das eigene Monitoring des Teams während eines Vorfalls niemals ausfällt.
Voraussetzungen für InfluxDB
Stellen Sie sicher, dass diese Punkte erfüllt sind — danach ist die Installation eine Sache von 60 Sekunden.
- InfluxDB 1.x oder 2.x läuft auf dem Server
- InfluxDB-HTTP-Port von Xitogent aus erreichbar (Standard 8086)
- Optional: ein Read-only-Token, falls InfluxDB 2.x-Authentifizierung aktiviert ist
Erste Schritte in Minuten
Xitogent auf Ihrem InfluxDB-Host installieren
Installieren Sie den ressourcenschonenden Xitogent-Monitoring-Agenten auf dem Host, auf dem InfluxDB läuft.
curl -s https://xitoring.com/install.sh | sudo bash -s -- --key=YOUR_API_KEYBestätigen, dass InfluxDB erreichbar ist
Prüfen Sie, dass InfluxDB auf seinem HTTP-Port (Standard 8086) lauscht und vom Xitogent-Host aus erreichbar ist. Xitogent fragt während der Integration nach Host und Port — zusätzliche Konfigurationsanpassungen oder Endpunkt-Freigaben sind nicht erforderlich.
sudo xitogent integrateInfluxDB-Integration aktivieren
Aktivieren Sie die InfluxDB-Integration über das Xitoring-Dashboard oder die CLI. Xitogent erkennt Ihre InfluxDB-Version automatisch und beginnt mit der Erfassung von Schreib-, Query- und Storage-Metriken.
Alarmschwellen konfigurieren (optional)
Legen Sie eigene Schwellenwerte für Schreibdurchsatz, Query-Dauer oder Series-Kardinalität fest, um Ingest-Druck und unkontrolliertes Tag-Wachstum zu erkennen, bevor Queries langsamer werden.
Funktion überprüfen
Führen Sie diesen Befehl auf dem Server aus, um zu bestätigen, dass Xitogent die Integration erkannt hat. Innerhalb von etwa 30 Sekunden werden frische Metriken in Ihr Dashboard gestreamt.
sudo xitogent statusErwägen Sie Alternativen?
Sehen Sie, wie sich Xitoring gegen die Alternativen für InfluxDB-Monitoring schlägt — Pauschalpreise, tiefere Integrationen und ein Agent, der Ihren gesamten Stack abdeckt.



Häufig gestellte Fragen
InfluxDB 1.x und 2.x?
Auswirkungen?
Wie erkenne ich InfluxDB-Kardinalitätsprobleme?
Was ist die _internal-Datenbank in InfluxDB?
Wie überwache ich InfluxDB-Compactions?
Was ist der Unterschied zwischen InfluxDB-1.x-, -2.x- und -3.0-Monitoring?
Wie erkenne ich Langsamkeit bei InfluxDB-Queries?
Wie überwache ich InfluxDB-TSM-Storage?
Beeinträchtigt diese Integration die InfluxDB-Performance?
InfluxDB überwachen heute
In weniger als 60 Sekunden eingerichtet. Keine Kreditkarte erforderlich. Umfassende Kennzahlen vom ersten Tag an.
Kostenlose Testversion startenEntdecke weiter