Nginx Monitoring
Monitor Nginx active connections, accepts/handled, request throughput, reading/writing/waiting state, and dropped-connection rate in real time — agent-based via the stub_status module.
Why monitor Nginx?
Nginx fronts most of the modern web — sitting between users and every other tier in your stack. When connections drop, workers exhaust, or upstreams fail, the symptom shows up at the entry point first. Monitoring catches the root cause minutes before it cascades into a downstream outage.
Nginx monitoring, explained
Nginx monitoring catches dropped connections, upstream failures, and worker-pool exhaustion before they cascade into a downstream outage. Because Nginx sits between users and every other tier in your stack, monitoring it well usually means catching most production incidents at the entry point — instead of debugging from the app server backwards. Xitoring gives you 1-minute visibility into every metric stub_status (and the Nginx Plus API) exposes, plus alerts routed to Slack, PagerDuty, Telegram, or your existing on-call rotation.
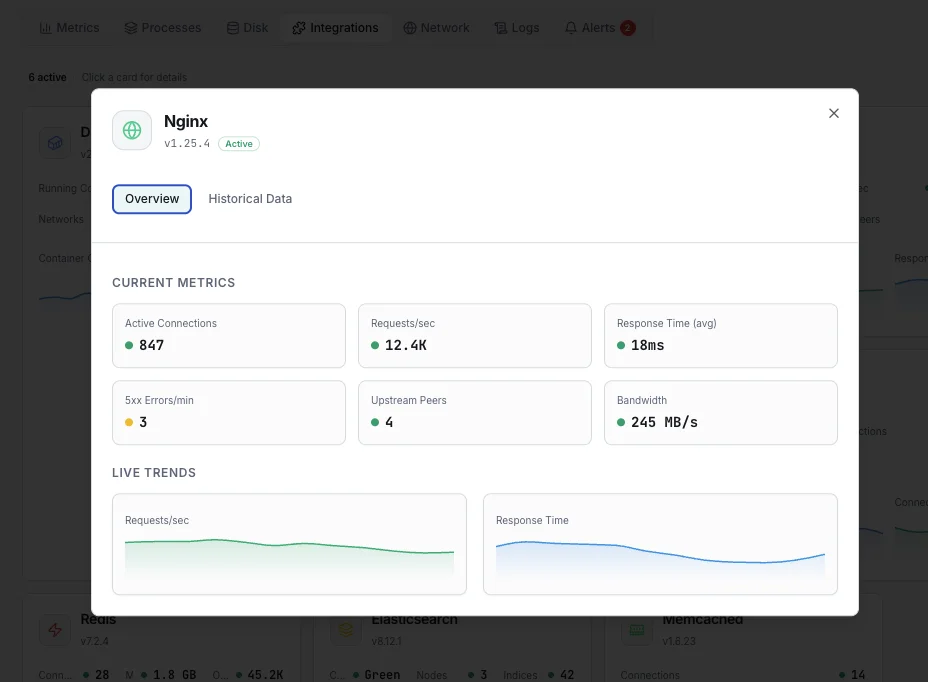
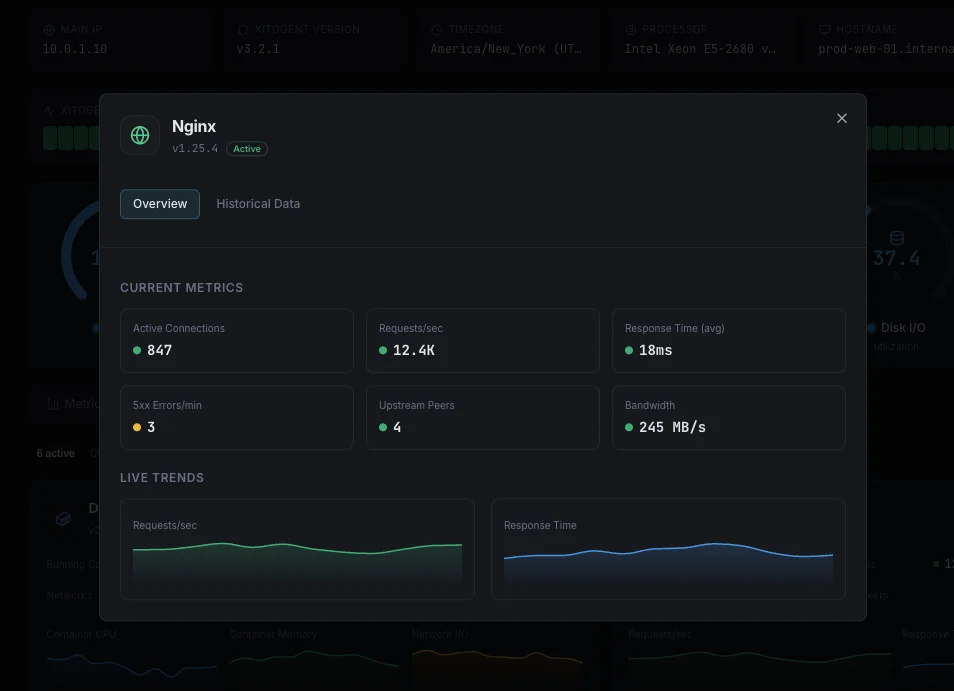
What we monitor
Active Connections
Currently active client connections, including those in waiting state. The first number to watch for capacity saturation.
Accepts / sec
Rate of accepted client connections. Spikes flag traffic surges; flat-lines flag broken upstream listeners.
Handled / sec
Rate of handled connections. Should track accepts almost exactly — a divergence means dropped connections from `worker_connections` or fd limits.
Dropped Connections
Computed as accepts − handled. Any non-zero rate is a hard signal that workers are starved and traffic is being shed.
Requests / sec
HTTP request throughput across all server blocks. Compare against connection rate to derive keep-alive efficiency.
Reading
Connections where Nginx is reading the request header. A persistently high value points to slow clients or large request bodies.
Writing
Connections where Nginx is writing the response. High writing combined with rising response times usually means backend or upstream slowness.
Waiting
Idle keep-alive connections waiting for the next request. Healthy reuse keeps this number high; near-zero means clients are reconnecting on every request.
Upstream Response Time
Time spent waiting on upstream servers (Nginx Plus / log-based). Separates Nginx-level latency from backend latency in incident triage.
HTTP 4xx / 5xx Rate
Rate of client and server errors derived from access logs. A 5xx spike with stable request rate points at upstream failures, not traffic.
Open File Descriptors
Current open fd count vs the per-worker limit. Approaching the limit causes the same dropped-connection symptom as low `worker_connections`.
Worker Process Count
Active Nginx worker processes. Worker churn or unexpected restart counts surface OOM events and segfaults invisible to request metrics.
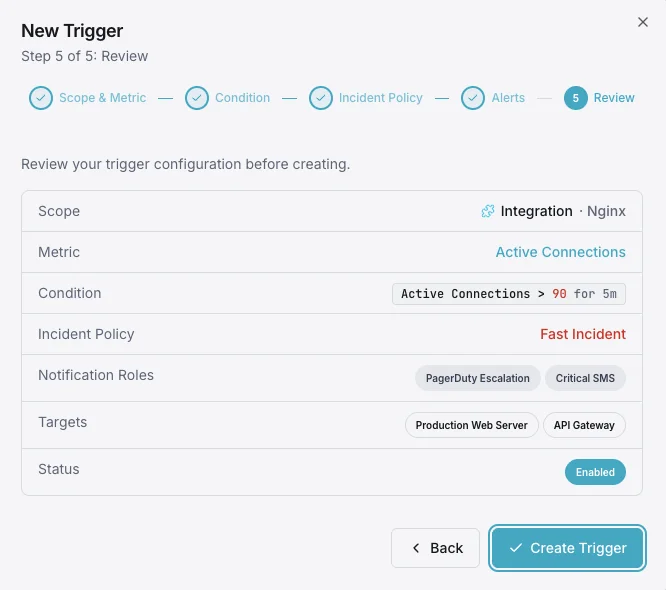
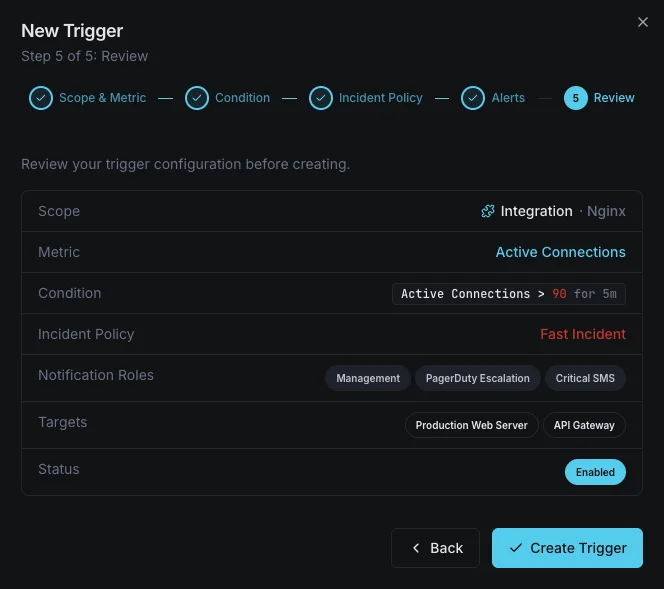
Configurable alert triggers
Set up custom triggers in your dashboard to get notified the moment Nginx metrics cross your defined thresholds.
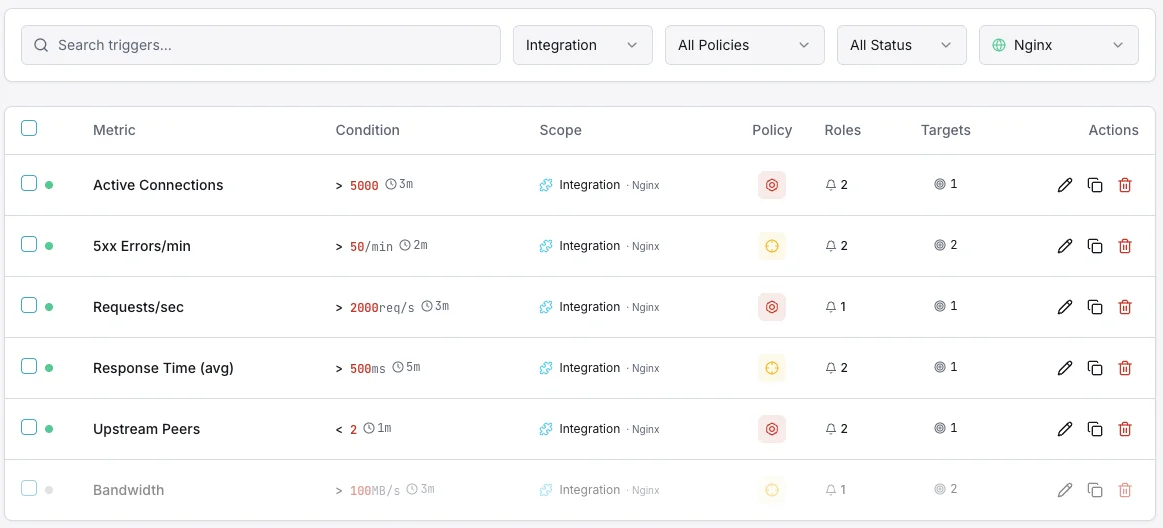
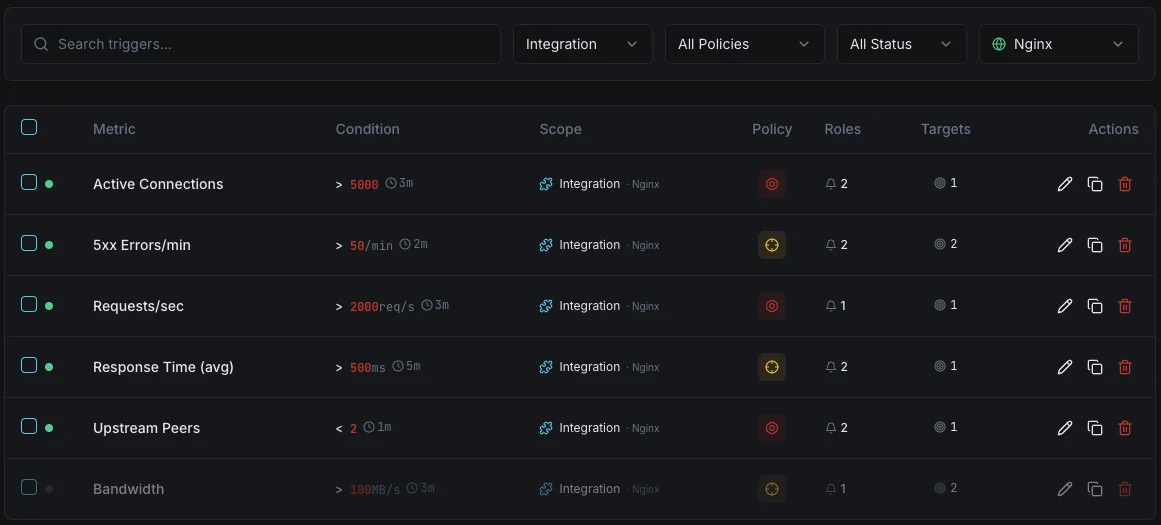
Active Connections
warningFires when the number of active connections exceeds your threshold, indicating the server is under heavy load.
Waiting Connections
warningTriggers when waiting (keep-alive) connections exceed the threshold, which may indicate slow clients or upstream delays.
Requests per Second
criticalAlerts when request rate exceeds normal baselines, useful for detecting traffic surges or DDoS patterns.
Writing Connections
warningFires when too many connections are in the writing state, signaling potential response bottlenecks.
Dropped Connections
criticalTriggers when the difference between accepts and handled increases, indicating resource exhaustion.
Response Time
criticalAlerts when average response time crosses your defined limit, signaling degraded performance.
Importance of Nginx Monitoring
Nginx powers over 35% of all web servers globally and is the backbone of modern microservices architectures. Without proper monitoring, connection saturation, upstream failures, and performance degradation can go undetected.
- Detect connection saturation before users experience timeouts
- Identify upstream server failures and slow backends
- Prevent cascading failures in reverse proxy configurations
- Maintain SLA compliance with real-time performance visibility
- Optimize load balancing with connection state analytics
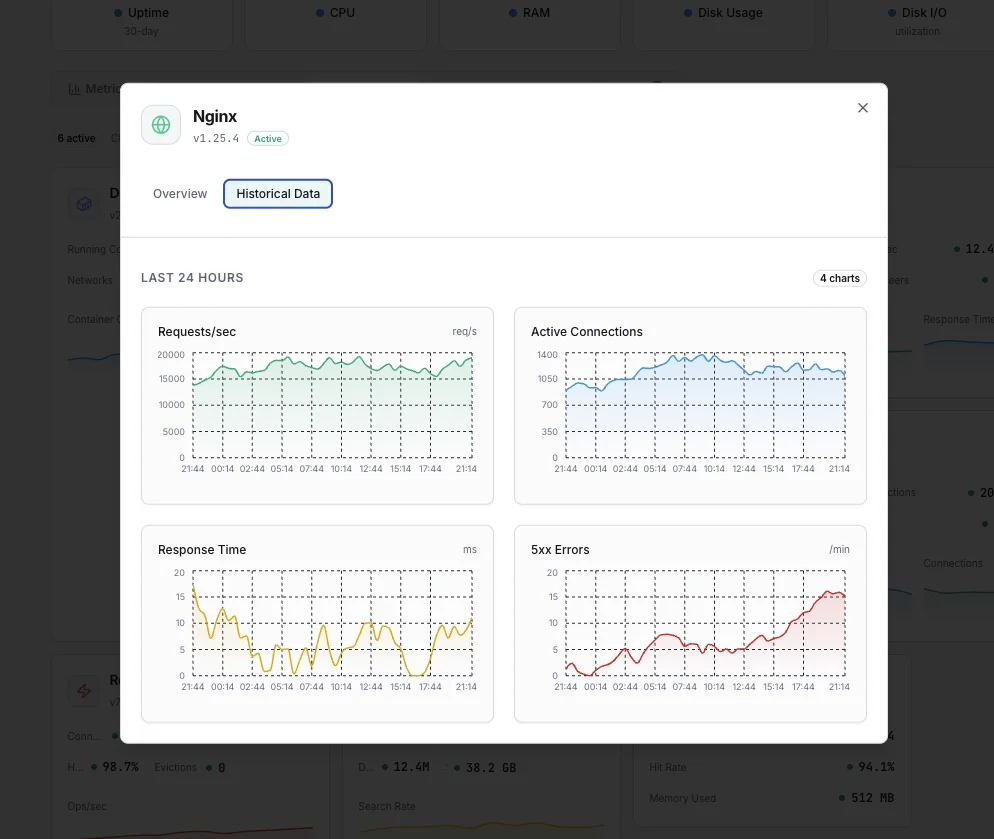
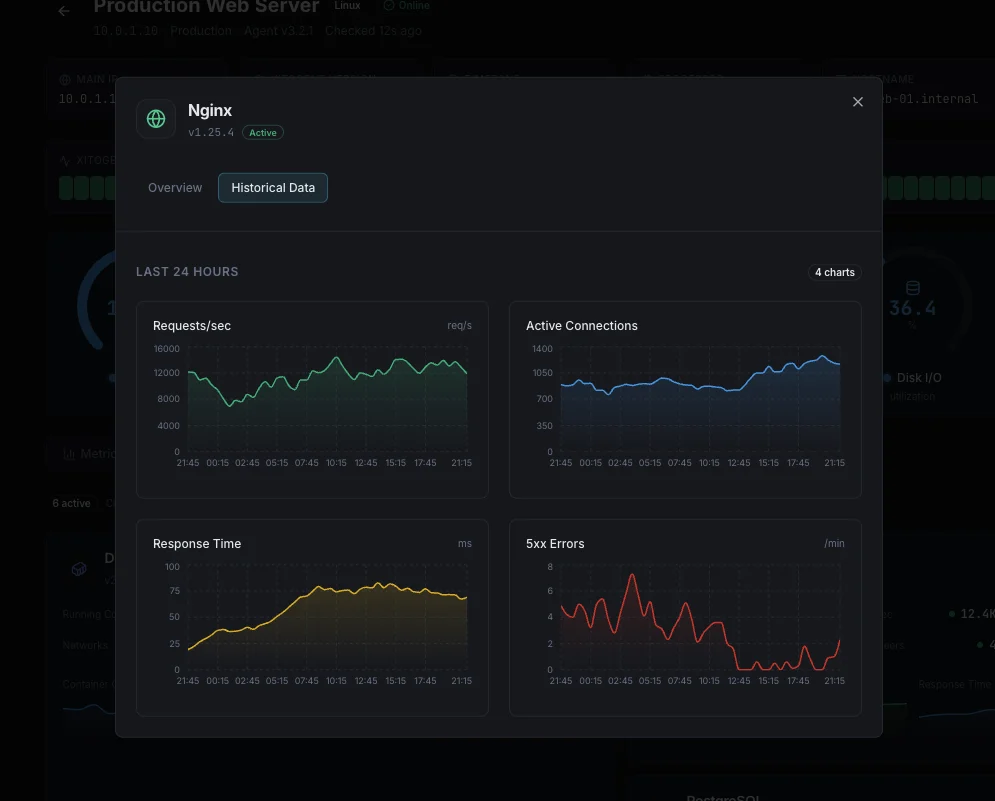
Why Choose Xitoring
Xitoring delivers enterprise-grade Nginx monitoring with zero-config setup. Our lightweight agent auto-discovers your Nginx instances, starts collecting metrics in under 60 seconds, and integrates with your existing notification channels.
- One-command install — no complex YAML or config files
- 15+ global monitoring nodes for low-latency checks
- Unified dashboard for servers, services, and uptime
- Flexible alerting via Slack, PagerDuty, Telegram & more
- Historical data retention for capacity planning & audits
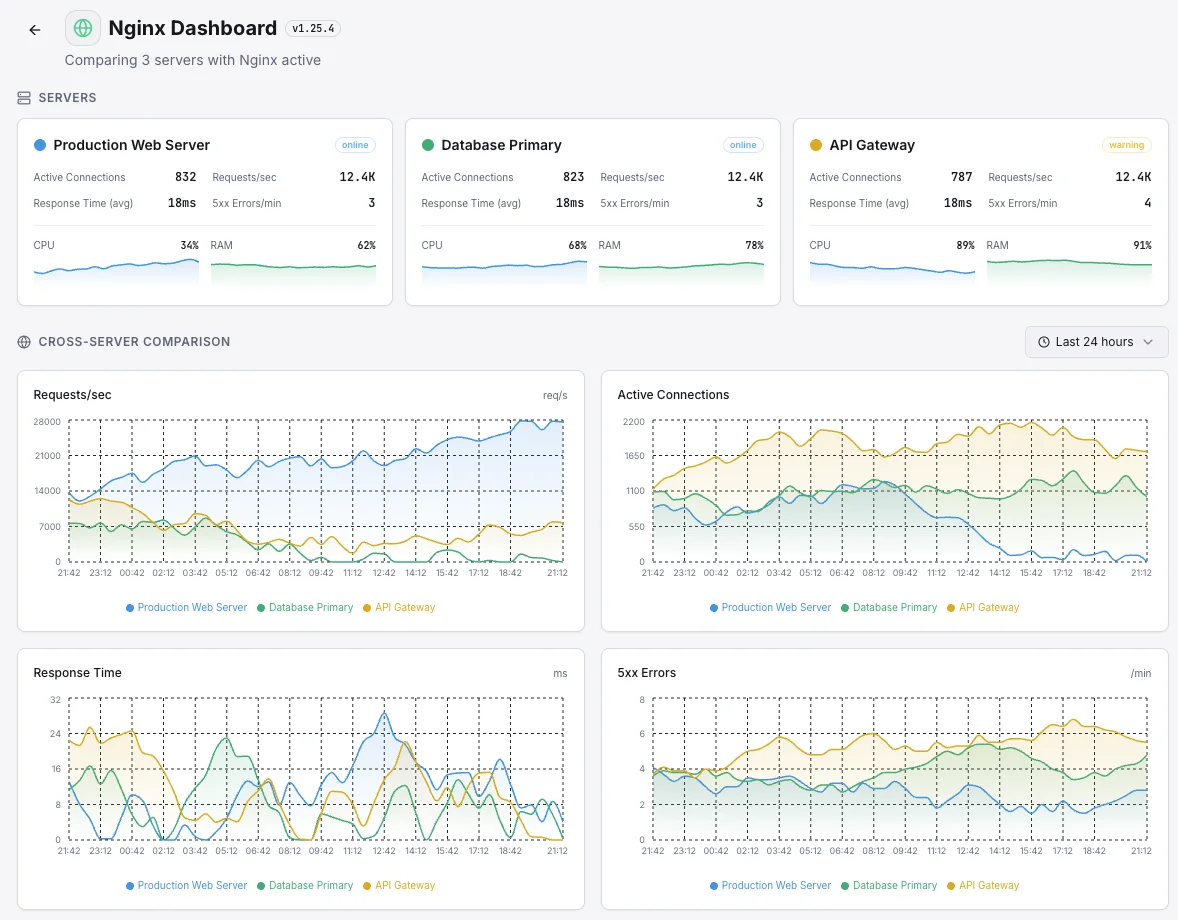
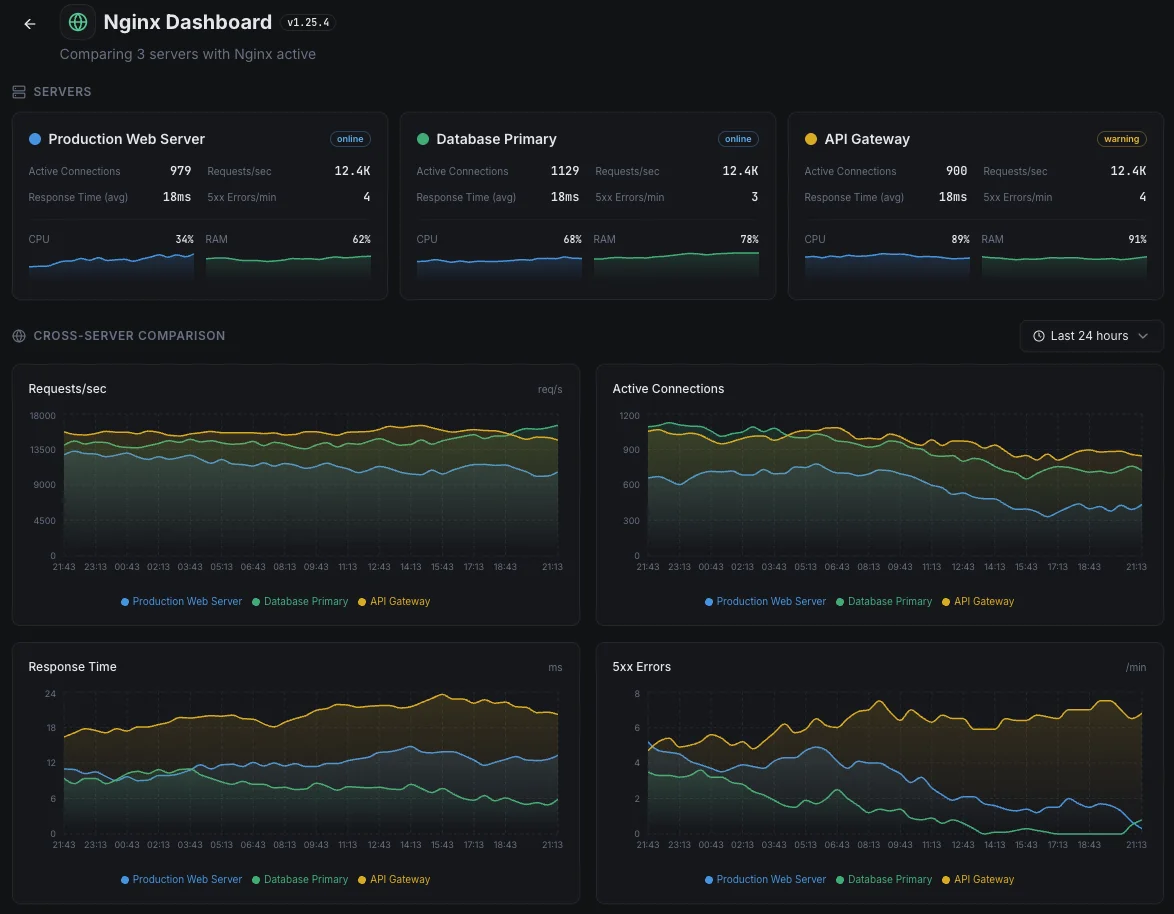
Common Nginx monitoring scenarios
Where Nginx typically runs today — and what could go wrong if no one's watching.
Web server in front of an app
Nginx is usually the first thing your visitors talk to — and the app behind it is usually where the actual work happens. When the site feels slow, it matters whether the slowness is in Nginx or in the app. We separate the two so the right team fixes the right thing.
Entry point for a Kubernetes app
In Kubernetes, Nginx is often the door to your entire app. A misstep there — a bad config push, an expired certificate, a failing rollout — can briefly take everything offline. We catch the warning signs early so routine deployments don't turn into customer-visible outages.
Distributing traffic across multiple app servers
When Nginx spreads traffic across many servers, one struggling server can quietly poison the experience for a slice of users. We catch the failing server early so it gets removed from rotation before more visitors are affected.
Prerequisites for Nginx
Make sure you've got these in place — most installs are a 60-second job once they are.
- Nginx with the
http_stub_status_modulecompiled in (verify withnginx -V 2>&1 | grep stub_status) - A
/nginx_statuslocation block enabled and accessible from localhost (allow 127.0.0.1; deny all;) - Read access to the Nginx config and access/error logs
Get started in minutes
Install Xitogent on your server
If you haven't already, install the lightweight Xitogent monitoring agent on your server.
curl -s https://xitoring.com/install.sh | sudo bash -s -- --key=YOUR_API_KEYEnable stub_status in Nginx
Add a `/nginx-status` location block to your Nginx configuration with `stub_status;` enabled and access restricted to localhost. Reload Nginx, then verify with `curl http://127.0.0.1/nginx-status`.
# In your Nginx server block:
location /nginx-status {
stub_status;
access_log off;
server_tokens on;
allow 127.0.0.1;
deny all;
}Enable the Nginx integration
Use the Xitoring dashboard or CLI to enable the Nginx integration. Xitogent will auto-detect your Nginx instance.
sudo xitogent integrateConfigure alert thresholds (optional)
Set custom thresholds for metrics like active connections, request rate, or response time to get notified when something needs attention.
Verify it's working
Run this command on the server to confirm Xitogent picked up the integration. Fresh metrics will start streaming to your dashboard within ~30 seconds.
sudo xitogent statusConsidering alternatives?
See how Xitoring stacks up against the alternatives for Nginx monitoring — flat pricing, deeper integrations, and one agent that covers your whole stack.



Frequently asked questions
What is Nginx monitoring?
Why is monitoring Nginx important?
How do I enable stub_status in Nginx?
Can I monitor Nginx without Nginx Plus?
How do I monitor Nginx upstream servers?
How do I monitor Nginx as a reverse proxy?
Can I monitor multiple Nginx instances on one server?
What Nginx versions are supported?
How often are metrics collected?
Start monitoring Nginx today
Set up in under 60 seconds. No credit card required. Full metrics from day one.
Start Free Trial