
البنية التحتية الحديثة موزعة وسريعة الحركة ومعقدة بشكل متزايد. من المتوقع أن يقوم مهندسو DevOps بالنشر بشكل أسرع، واكتشاف المشكلات في وقت مبكر، وأتمتة الاستجابات، وضمان بقاء الأنظمة موثوقة - كل ذلك مع الحفاظ على سلامة التكاليف السحابية. لم تعد المراقبة أداة “لطيفة” تعمل في الخلفية. في عام 2025، تعد حزمة المراقبة الرائعة مكونًا من الدرجة الأولى في بنيتك الأساسية.
ولكن إليكم الحقيقة:
معظم الشركات ليس لديها استراتيجية مراقبة موحدة، بل لديها فوضى في الأدوات.
خمس لوحات معلومات، وثلاثة أنظمة تنبيه، وسحابتان، ومع ذلك لم يلاحظ أحد ارتفاع وحدة المعالجة المركزية حتى يفتح العميل تذكرة دعم.
تساعدك هذه المقالة في بناء مجموعة المراقبة الكاملة خطوة بخطوة - واحدة تساعد فرق التطوير والعمليات خطوة بخطوة اكتشاف المشاكل وتشخيصها والتفاعل معها قبل أن يلاحظها المستخدمون.
ما سنقوم بتغطيته
-
أهمية المراقبة أكثر من أي وقت مضى في عام 2025
-
الركائز الـ 6 لحزمة المراقبة المثالية
-
أفضل الأدوات المناسبة (مفتوحة المصدر + البرمجيات كخدمة) لكل طبقة
-
الأتمتة و AIOps من أجل استجابة أسرع للحوادث
-
أمثلة حقيقية لسير العمل باستخدام زيتورينج
-
أفضل الممارسات لبناء ثقافة مراقبة مستقبلية واقية من المراقبة
احصل على قهوتك - دعنا نصمم نظاماً بيئياً مثالياً للمراقبة.
أهمية المراقبة أكثر من أي وقت مضى في عام 2025
اتجاهات البنية التحتية آخذة في التحول:
| الاتجاه السائد | النتيجة |
|---|---|
| الخدمات المصغرة > الخدمات الأحادية | المزيد من نقاط الفشل الموزعة |
| اعتماد السحابة المتعددة | رؤية أكثر وضوحًا وارتباط المقاييس |
| فرق العمل عن بُعد والأنظمة العالمية | تحتاج إلى مراقبة وأتمتة على مدار 24/7 |
| المستخدمون المدعومون بالذكاء الاصطناعي وأعباء العمل | حساسية أعلى للأداء العالي |
| توقعات وقت التشغيل بالقرب من 100% | تكلفة الحوادث أكثر من أي وقت مضى |
حتى الانقطاعات الصغيرة تؤلم. يمكن لبضع دقائق من التوقف أثناء الدفع أن تكلف متجر التجارة الإلكترونية الآلاف. ويؤثر تدهور الأداء في تطبيق SaaS تأثيراً مباشراً على معدل التراجع. وبالنسبة للخدمات ذات اتفاقيات مستوى الخدمة SLAs، فإن وقت التعطل = أموال من الجيب.
لم تعد المراقبة تتعلق فقط بوقت التشغيل - بل أصبحت تتعلق بـ
✔ تحسين الأداء
✔ حماية تجربة المستخدم
✔الاستجابة السريعة للحوادث
✔ الكشف التنبؤي للأعطال
✔ القرارات الهندسية المستندة إلى البيانات
مكدس المراقبة الخاص بك هو نظام الإنذار المبكر الخاص بك، ومختبر الطب الشرعي، ومساعد العمليات الخاص بك - كل ذلك في جهاز واحد.
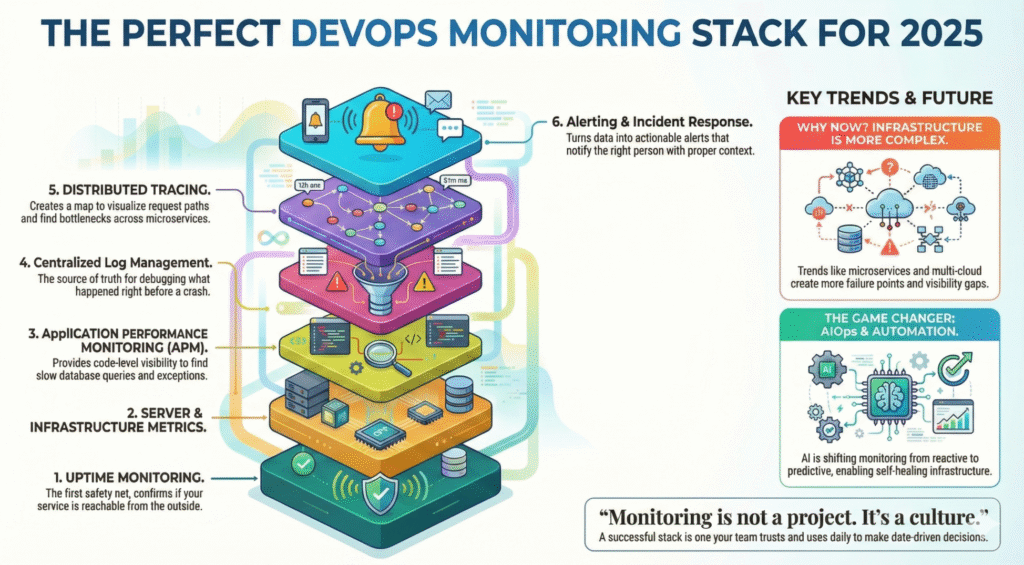
الركائز الـ 6 لحزمة المراقبة المثالية
يتضمن إعداد المراقبة الناضج طبقات متعددة تعمل معًا:
-
مراقبة وقت التشغيل والتحقق من الحالة
-
مقاييس الخادم والبنية التحتية
-
مراقبة أداء التطبيقات (APM)
-
السجلات وإدارة السجلات المركزية
-
التتبع والمراقبة الموزعة
-
التنبيه والاستجابة للحوادث والأتمتة
لا تحدث معظم الإخفاقات بمعزل عن بعضها البعض - لذا فإن المكدس الجيد يربط المقاييس عبر جميع الطبقات.
دعونا نفصلها واحداً تلو الآخر.
1. مراقبة وقت التشغيل - شبكة الأمان الأولى
تؤكد عمليات التحقق من وقت التشغيل ما إذا كان يمكن الوصول إلى خدمتك من الخارج. هذا أمر بالغ الأهمية لـ
-
تتبع التوفر
-
الإبلاغ عن اتفاقية مستوى الخدمة
-
اكتشاف مشكلات DNS/SSL/شبكة DNS/SSL/الشبكة
-
الكشف المبكر عن انقطاع التيار الكهربائي قبل أن يلاحظ العملاء
يجب أن تكون شاشة مراقبة وقت التشغيل الخاصة بك:
-
بينج من مواقع عالمية متعددة
-
دعم HTTP و TCP و ICMP و DNS وفحص المنافذ
-
تنبيه فوري عند بدء التوقف عن العمل
-
توفير صفحات الحالة العامة/الخاصة
-
تتبع وقت التشغيل والحوادث التاريخية
أدوات جيدة:
🔹 Xitoring (وقت التشغيل + مراقبة الخادم في منصة واحدة)
🔹 U_1F539↩ UptimeRobot, Pingdom, BetterUptime
🔹 اصنعها بنفسك باستخدام Prometheus + Blackbox Exporter
مثال على سير العمل مع زيتورينج:
يمكنك تكوين عمليات التحقق من وقت التشغيل لواجهات برمجة التطبيقات والصفحات المقصودة. يراقب Xitoring من العقد العالمية كل دقيقة وينبه على الفور عبر Slack/Telegram إذا ارتفع زمن الاستجابة أو أصبحت نقطة النهاية غير قابلة للوصول. يتم تحديث صفحة الحالة تلقائيًا - لا يلزم إجراء اتصالات يدوية.
2. مراقبة الخوادم والبنية التحتية
هذا هو المكان الذي يمكنك فيه تتبع وحدة المعالجة المركزية وذاكرة الوصول العشوائي ومتوسط التحميل وإدخال البيانات على القرص وإنتاجية الشبكة وسجلات النظام والمزيد.
ما أهمية ذلك:
تبدأ العديد من حالات الانقطاع هنا - تسرب الذاكرة، وامتلاء الأقراص، واختناق وحدة المعالجة المركزية، ومشكلات النواة واستنفاد الموارد.
يجب أن توفر أداة مراقبة الخادم في عام 2025:
✔ تجميع المقاييس ولوحات المعلومات
✔ التنبيهات القائمة على العتبة والتنبيهات الشاذة
✔ مراقبة العمليات/الخدمة
✔ دعم لينكس + ويندوز
✔ التجميع بالوكيل أو بدون وكيل
الأدوات التي يجب مراعاتها:
مفتوح المصدر: Prometheus + Node Exporter، Zabbix، Grafana
SaaS: Datadog, New Relic, Xitoring للحصول على رؤى في الوقت الفعلي
المكان زيتورينج يناسبك:
يقوم Xitoring بتثبيت وكيل خفيف الوزن، ويراقب مقاييس لينكس/ويندوز، ويستخدم اكتشاف أنماط الذكاء الاصطناعي لتحذيرك من سلوكيات الأداء غير الاعتيادية قبل أن تتسبب في حدوث توقف.
3. مراقبة أداء التطبيقات (APM)
حتى لو كانت الخوادم تبدو سليمة, قد يكون تطبيقك يعاني.
توفر APM:
-
تتبع الأداء على مستوى الرمز
-
بطء اكتشاف نقطة النهاية/اكتشاف استعلام قاعدة البيانات
-
تسريبات الذاكرة وتتبع الاستثناءات
-
أعطال زمن الانتقال من طرف إلى طرف
إذا كان تطبيقك يتوسع بسرعة أو يمتد على خدمات مصغرة، فإن إدارة أداء التطبيقات ليست اختيارية، بل هي ضرورة حتمية.
4. السجلات - مصدر الحقيقة خلال الحوادث
عندما ينكسر شيء ما، يركض المهندسون إلى لوحات المعلومات... ثم في النهاية إلى السجلات.
يساعد التسجيل المركزي في الإجابة على السؤال:
-
ماذا حدث قبل الحادث؟
-
ما الخدمة التي قامت بإلقاء الاستثناء؟
-
هل أدخلت عملية النشر خطأ؟
-
هل هي مشكلة في النظام أم تبعية خارجية؟
أمثلة على مكدس السجل:
-
ELK (Elasticsearch + Logstash + Kibana) - مرنة ومستخدمة على نطاق واسع
-
جرافانا لوكي - أرخص وقابلة للتطوير
-
غراي لوج، سبانك - إمكانات البحث في المؤسسات
-
السجلات الأصلية للسحابة - تسجيل GCP، AWS CloudWatch
يجب أن يكون التسجيل مركزيًا؛ فالدخول إلى الخوادم لتعقب السجلات هو مشكلة عام 2010.
5. التتبع الموزع - فهم سلوك النظام
عندما تمر الطلبات عبر قوائم الانتظار، والخدمات، وموازنات التحميل، وقواعد البيانات - التتبع هو خريطتك.
يساعد التتبع الموزع:
✔ تصور مسارات الطلبات
✔ تحديد الاختناقات عبر الخدمات المصغرة
✔ تصحيح مهلات التصحيح، وإعادة المحاولات، وحالات الفشل
المعايير والأدوات:
-
OpenTelemetry (معيار الصناعة)
-
جايجر، زيبكين
-
تتبع سحابة AWS X-Ray / GCP Cloud Trace
يربط التتبع بين إدارة أداء APM + السجلات + المقاييس معًا للكشف عن الصورة الكاملة للحادث.
6. الإنذار والاستجابة للحوادث
لا فائدة من المراقبة بدون تنبيهات قابلة للتنفيذ. لا أحد يريد إرهاق التنبيه, ، ولكن الصمت أثناء الانقطاعات أسوأ من ذلك.
يجب أن يكون سير عمل التنبيهات الحديثة:
-
الكشف عن
-
قم بإبلاغ الشخص المناسب
-
توفير السياق (لوحات المعلومات، والسجلات)
-
تشغيل المعالجة الآلية عند الإمكان
قنوات التنبيه:
-
سلاك وفرق العمل والبريد الإلكتروني
-
PagerDuty / OpsGenie
-
Telegram، SMS
-
Webhooks للتشغيل الآلي
Xitoring مثال:
عندما تظل وحدة المعالجة المركزية أعلى من 90% لمدة 10 دقائق، يرسل Xitoring تنبيهات عبر Slack وTelegram، ويرفق مقاييس النظام، ويمكنه تشغيل البرامج النصية الآلية (على سبيل المثال، إعادة تشغيل الخدمة أو توسيع نطاق القرون).
AIOps والأتمتة - مغير قواعد اللعبة لعام 2025
تنتقل مراقبة التطور من مراقبة التطور من تفاعلي → تنبؤي.
يمكن أن يساعد الذكاء الاصطناعي في الكشف عن:
-
طفرات غير عادية في حركة المرور
-
تسرب بطيء للذاكرة
-
تغييرات الكمون قبل تأثير المستخدم
-
الاتجاهات السلوكية التي تؤدي إلى الفشل
منصات مثل Xitoring تدمج بالفعل اكتشاف الشذوذ القائم على الذكاء الاصطناعي, التمكين
🔹 التنبيه التلقائي قبل انقطاع التيار الكهربائي
🔹 اقتراح الأسباب الجذرية
🔹 مشغلات الاسترداد الآلي
المستقبل هو بنية تحتية ذاتية التعافي.
أفضل الممارسات لفرق DevOps في عام 2025
-
تنبيه على الأعراض وليس على الضوضاء
ارتفاع وحدة المعالجة المركزية وحده لا يمثل مشكلة - بل زيادة الارتفاع + زمن الوصول هي المشكلة. -
استخدام صفحات الحالة
يقلل من عبء الدعم ويبني الثقة مع العملاء. -
تتبع مقاييس SLO/SLI
الموثوقية قابلة للقياس، ويمكنك تحسين ما تتبعه فقط. -
مراقبة عمليات النشر عن كثب
معظم الحوادث عبارة عن إطلاقات بشرية. -
المراقبة ليست مشروعاً. إنها ثقافة.
الأفكار النهائية
لا تعني حزمة المراقبة المثالية شراء الأداة الأغلى ثمناً أو المبالغة في هندسة خط أنابيب المراقبة. إنه يعني الجمع بين الطبقات التي تمنحك الرؤية من طلب المستخدم ← الخادم ← التطبيق ← السجلات ← السبب الجذري.
إذا كانت هناك فائدة واحدة
لا يجب أن تخبرك المراقبة أن هناك خطأ ما حدث - بل يجب أن تخبرك لماذا وكيفية إصلاحه بسرعة.
سواء اخترت حزمة مفتوحة المصدر أو منصة مؤسسية أو حلاً موحدًا مثل زيتورينج الذي يجمع بين مراقبة وقت التشغيل + مراقبة الخادم مع رؤى الذكاء الاصطناعي، فالمفتاح هو بناء نظام يثق به فريقك ويستخدمه يومياً.