
La infraestructura moderna está distribuida, se mueve con rapidez y es cada vez más compleja. Se espera que los ingenieros de DevOps desplieguen más rápido, detecten antes los problemas, automaticen las respuestas y garanticen la fiabilidad de los sistemas, al tiempo que mantienen los costes de la nube saneados. La monitorización ya no es una herramienta “deseable” que se ejecuta en segundo plano. En 2025, una gran pila de monitorización es un componente de primera clase de su infraestructura.
Pero esta es la verdad:
La mayoría de las empresas no tienen una estrategia de supervisión unificada, sino un caos de herramientas.
Cinco paneles de control, tres sistemas de alerta, dos nubes, y aun así nadie se da cuenta del pico de CPU hasta que el cliente abre un ticket de soporte.
Este artículo le ayuda a construir un pila de supervisión completa paso a paso, que ayude a los equipos DevOps a detectar, diagnosticar y reaccionar ante los problemas antes de que los usuarios se den cuenta.
Qué trataremos
-
Por qué la vigilancia es más importante que nunca en 2025
-
Los 6 pilares de una pila de supervisión perfecta
-
Herramientas más adecuadas (código abierto + SaaS) para cada capa
-
Automatización y AIOps para una respuesta más rápida a los incidentes
-
Ejemplos reales de flujos de trabajo con Xitoring
-
Buenas prácticas para crear una cultura de observabilidad preparada para el futuro
Coja su café: diseñemos el ecosistema de supervisión perfecto.
Por qué la vigilancia es más importante que nunca en 2025
Las tendencias en infraestructuras están cambiando:
| Tendencia | Resultado |
|---|---|
| Microservicios > Monolitos | Más puntos de fallo distribuidos |
| Adopción de múltiples nubes | Mayor visibilidad y correlación de métricas |
| Equipos remotos y sistemas globales | Necesidad de supervisión y automatización 24 horas al día, 7 días a la semana |
| Usuarios y cargas de trabajo basados en IA | Mayor sensibilidad de rendimiento |
| Expectativas de tiempo de actividad cerca de 100% | Los incidentes cuestan más que nunca |
Incluso los pequeños cortes perjudican. Unos minutos de inactividad durante el proceso de pago pueden costar miles de euros a una tienda de comercio electrónico. Una degradación del rendimiento en una aplicación SaaS afecta directamente a la rotación. Y para los servicios con acuerdos de nivel de servicio, tiempo de inactividad = dinero del bolsillo.
La supervisión ya no es sólo cuestión de tiempo de actividad:
✔ Optimización del rendimiento
✔ Protección de la experiencia del usuario
✔ Respuesta rápida ante incidentes
✔ Detección predictiva de fallos
✔ Decisiones de ingeniería basadas en datos
Su pila de supervisión es su sistema de alerta temprana, su laboratorio forense y su asistente de operaciones, todo en uno.
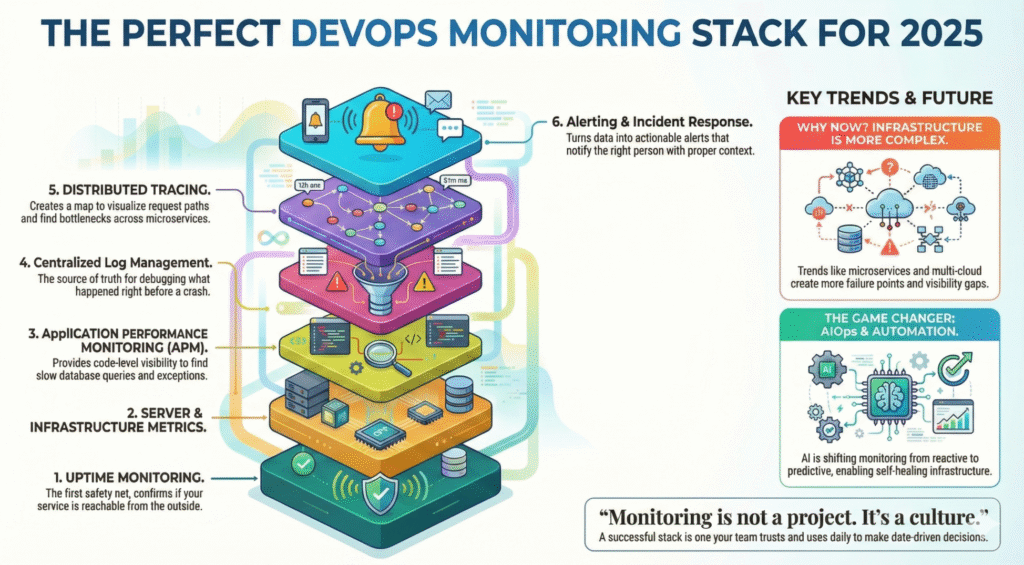
Los 6 pilares de una pila de supervisión perfecta
Una configuración de supervisión madura incluye varias capas que trabajan juntas:
-
Supervisión del tiempo de actividad y comprobación del estado
-
Métricas de servidores e infraestructuras
-
Supervisión del rendimiento de las aplicaciones (APM)
-
Registros y gestión centralizada de registros
-
Rastreo y observabilidad distribuida
-
Alertas, respuesta a incidentes y automatización
La mayoría de los fallos no se producen de forma aislada, por lo que una buena pila correlaciona las métricas en todas las capas.
Vamos a desglosarlas una por una.
1. Supervisión del tiempo de actividad: la primera red de seguridad
Las comprobaciones del tiempo de actividad confirman si su servicio es accesible desde el exterior. Esto es fundamental para:
-
Seguimiento de la disponibilidad
-
Informes SLA
-
Detección de problemas de DNS/SSL/red
-
Detección precoz de cortes antes de que los clientes se den cuenta
Tu monitor de tiempo de actividad debería:
-
Ping desde múltiples sedes en todo el mundo
-
Soporta HTTP, TCP, ICMP, DNS y comprobación de puertos
-
Alerta instantánea cuando comienza el tiempo de inactividad
-
Proporcionar páginas de estado públicas/privadas
-
Seguimiento histórico del tiempo de actividad y las incidencias
Buenas herramientas:
🔹 Xitoring (Tiempo de actividad + supervisión de servidores en una sola plataforma)
🔹 UptimeRobot, Pingdom, BetterUptime
🔹 Bricolaje con Prometheus + Blackbox Exporter
Ejemplo de flujo de trabajo con Xitoring:
Configure comprobaciones de tiempo de actividad para API y páginas de destino. Xitoring supervisa los nodos globales cada minuto y alerta al instante a través de Slack/Telegram si se producen picos de latencia o no se puede acceder al punto final. La página de estado se actualiza automáticamente, sin necesidad de comunicaciones manuales.
2. Supervisión de servidores e infraestructuras
Aquí se realiza un seguimiento de la CPU, la RAM, la carga media, la entrada/salida de disco, el rendimiento de la red, los registros del sistema y mucho más.
Por qué es importante:
Muchas interrupciones comienzan aquí: fugas de memoria, discos llenos, estrangulamiento de la CPU, problemas del kernel, agotamiento de recursos.
Una herramienta de monitorización de servidores en 2025 debería proporcionar:
✔ Recopilación de métricas y cuadros de mando
Alertas basadas en umbrales y anomalías
✔ Supervisión de procesos/servicios
✔ Compatibilidad con Linux y Windows
✔ Recogida con o sin agente
Herramientas a tener en cuenta:
De código abierto: Prometheus + Node Exporter, Zabbix, Grafana
SaaS: Datadog, New Relic, Xitoring para información en tiempo real
Dónde Xitoring encaja:
Xitoring instala un agente ligero, supervisa las métricas de Linux/Windows y utiliza la detección de patrones de IA para advertirle de comportamientos de rendimiento inusuales antes de que provoquen tiempos de inactividad.
3. Supervisión del rendimiento de las aplicaciones (APM)
Aunque los servidores parezcan sanos, su aplicación podría tener problemas.
APM proporciona:
-
Trazas de rendimiento a nivel de código
-
Detección lenta del punto final/consulta de la base de datos
-
Fugas de memoria y seguimiento de excepciones
-
Interrupciones de latencia de extremo a extremo
Si su aplicación se escala rápidamente o abarca microservicios, APM no es opcional: es supervivencia.
4. Registros - La fuente de la verdad durante los incidentes
Cuando algo se rompe, los ingenieros corren a los cuadros de mando... y luego, finalmente a los registros.
El registro centralizado ayuda a responder:
-
¿Qué ocurrió antes del accidente?
-
¿Qué servicio lanzó la excepción?
-
¿El despliegue ha introducido un error?
-
¿Es un problema del sistema o una dependencia externa?
Ejemplos de pila de registro:
-
ELK (Elasticsearch + Logstash + Kibana) - flexible, ampliamente utilizado
-
Grafana Loki - más barato y escalable
-
Graylog, Splunk - funciones de búsqueda empresarial
-
Registros nativos de la nube - GCP Logging, AWS CloudWatch
El registro debe estar centralizado; entrar por SSH en los servidores para seguir los registros es un problema de 2010.
5. Rastreo distribuido - Comprender el comportamiento del sistema
Cuando las solicitudes pasan por colas, servicios, equilibradores de carga y bases de datos, el rastreo es su mapa.
El rastreo distribuido ayuda:
✔ Visualizar rutas de solicitud
✔ Identificar cuellos de botella a través de microservicios.
✔ Depurar tiempos de espera, reintentos, fallos
Normas y herramientas:
-
OpenTelemetry (estándar del sector)
-
Jaeger, Zipkin
-
Rastreo de la nube de AWS X-Ray / GCP
El rastreo une APM + registros + métricas para revelar la imagen completa de un incidente.
6. Alertas y respuesta a incidentes
La supervisión es inútil sin alertas procesables. Nadie quiere fatiga por alerta, pero el silencio durante los cortes es aún peor.
Un flujo de trabajo de alerta moderno debería:
-
Detectar
-
Notificar a la persona adecuada
-
Proporcionar contexto (cuadros de mando, registros)
-
Activar la corrección automática cuando sea posible
Canales de alerta:
-
Slack, equipos, correo electrónico
-
PagerDuty / OpsGenie
-
Telegram, SMS
-
Webhook para automatización
Xitoring Ejemplo:
Cuando la CPU se mantiene por encima de 90% durante 10 minutos, Xitoring envía alertas a través de Slack y Telegram, adjunta métricas del sistema y puede activar scripts automatizados (por ejemplo, reiniciar un servicio o escalar pods).
AIOps y automatización: el cambio de 2025
La evolución de la vigilancia está pasando de reactiva → predictiva.
La IA puede ayudar a detectar:
-
Picos de tráfico inusuales
-
Fugas de memoria lentas
-
Cambios de latencia antes del impacto en el usuario
-
Tendencias de comportamiento que conducen al fracaso
Plataformas como Xitoring ya integran Detección de anomalías basada en IA, habilitando:
🔹 autoalerta antes de los cortes
🔹 sugerencia de causas profundas
🔹 activadores automáticos de recuperación
El futuro es infraestructura autorreparable.
Mejores prácticas para los equipos DevOps en 2025
-
Alerta ante los síntomas, no ante el ruido
Un pico de CPU por sí solo no es un problema, pero sí lo es un pico + un aumento de la latencia. -
Utilizar páginas de estado
Reduce la carga de asistencia y genera confianza entre los clientes. -
Seguimiento de las métricas SLO/SLI
La fiabilidad se puede medir y sólo se puede mejorar lo que se controla. -
Observar de cerca los despliegues
La mayoría de los incidentes son liberaciones humanas. -
La supervisión no es un proyecto. Es una cultura.
Reflexiones finales
Una pila de monitorización perfecta no significa comprar la herramienta más cara o sobrediseñar su canal de observabilidad. Significa combinar capas que le den visibilidad desde la solicitud del usuario → servidor → aplicación → registros → causa raíz.
Si hay que sacar algo en claro:
La supervisión no debería decirte que algo ha ido mal, sino que debería decirte por qué y cómo solucionarlo rápidamente.
Tanto si elige una pila de código abierto, una plataforma empresarial o una solución unificada como Xitoring que combina el tiempo de actividad y la supervisión de servidores con la inteligencia artificial, la clave está en crear un sistema en el que su equipo confíe y que utilice a diario.