
L'infrastructure moderne est distribuée, évolue rapidement et devient de plus en plus complexe. Les ingénieurs DevOps doivent déployer plus rapidement, détecter les problèmes plus tôt, automatiser les réponses et s'assurer que les systèmes restent fiables, tout en maintenant les coûts du cloud à un niveau raisonnable. La surveillance n'est plus un outil “agréable à avoir” fonctionnant en arrière-plan. En 2025, une excellente pile de surveillance est un composant de premier ordre de votre infrastructure.
Mais voici la vérité :
La plupart des entreprises n'ont pas de stratégie de surveillance unifiée - elles ont des outils désordonnés.
Cinq tableaux de bord, trois systèmes d'alerte, deux nuages, et toujours personne ne remarque le pic de CPU jusqu'à ce que le client ouvre un ticket d'assistance.
Cet article vous aide à construire un pile de surveillance complète étape par étape - qui aide les équipes DevOps détecter, diagnostiquer et réagir aux problèmes avant même que les utilisateurs ne s'en aperçoivent.
Ce que nous allons couvrir
-
Pourquoi le suivi est plus important que jamais en 2025
-
Les 6 piliers d'une pile de contrôle parfaite
-
Outils les mieux adaptés (open-source + SaaS) pour chaque couche
-
Automatisation et AIOps pour une réponse plus rapide aux incidents
-
Exemples réels de flux de travail utilisant Xitoring
-
Meilleures pratiques pour construire une culture de l'observabilité à l'épreuve du temps
Prenez votre café - concevons l'écosystème de surveillance parfait.
Pourquoi le contrôle est plus important que jamais en 2025
Les tendances en matière d'infrastructures évoluent :
| Tendance | Résultat |
|---|---|
| Microservices > Monolithes | Plus de points de défaillance répartis |
| Adoption du multi-cloud | Visibilité et corrélation des mesures plus difficiles |
| Équipes à distance et systèmes mondiaux | Besoin de surveillance et d'automatisation 24/7 |
| Utilisateurs et charges de travail alimentés par l'IA | Sensibilité accrue des performances |
| Attentes en matière de temps de disponibilité près de 100% | Les incidents coûtent plus cher que jamais |
Même les petites pannes font mal. Quelques minutes d'indisponibilité lors du paiement peuvent coûter des milliers d'euros à une boutique de commerce électronique. Une dégradation des performances d'une application SaaS a une incidence directe sur le taux de désabonnement. Et pour les services assortis d'accords de niveau de service, un temps d'arrêt est synonyme d'argent perdu.
La surveillance n'est plus seulement une question de temps de fonctionnement, mais aussi d'efficacité :
✔ Optimisation des performances
✔ Protection de l'expérience utilisateur
Réponse rapide aux incidents
Détection prédictive des défaillances
✔ Décisions d'ingénierie fondées sur des données
Votre pile de surveillance est à la fois votre système d'alerte précoce, votre laboratoire médico-légal et votre assistant opérationnel.
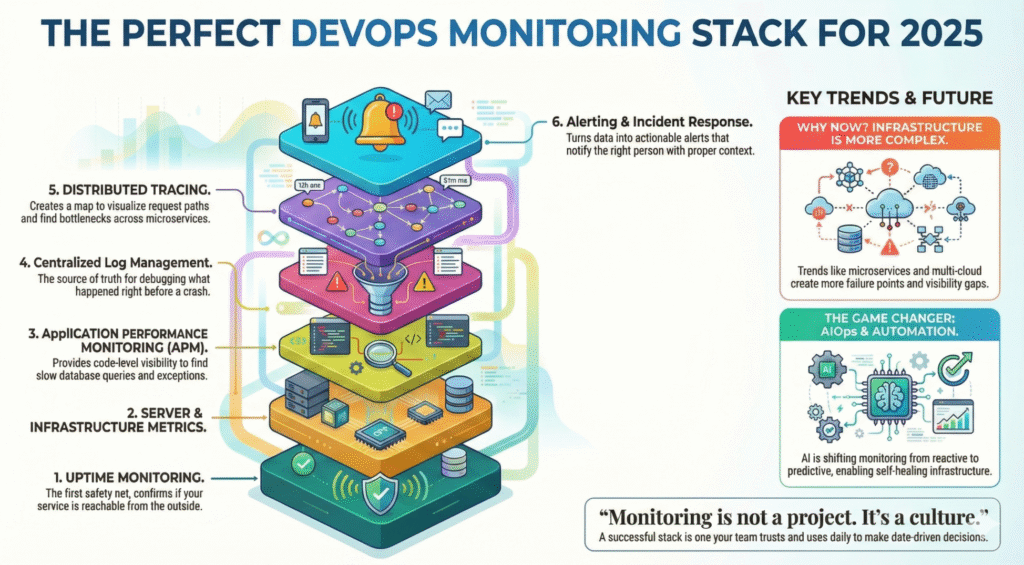
Les 6 piliers d'une pile de contrôle parfaite
Une installation de surveillance mature comprend plusieurs couches qui fonctionnent ensemble :
-
Surveillance de la disponibilité et vérification de l'état
-
Métriques des serveurs et de l'infrastructure
-
Surveillance des performances des applications (APM)
-
Journaux et gestion centralisée des journaux
-
Traçage et observabilité distribuée
-
Alerte, réponse aux incidents et automatisation
La plupart des défaillances ne se produisent pas de manière isolée, c'est pourquoi une bonne pile de données met en corrélation les mesures de toutes les couches.
Examinons-les une à une.
1. Surveillance du temps de fonctionnement - Le premier filet de sécurité
Les contrôles de disponibilité confirment que votre service est accessible de l'extérieur. C'est essentiel pour :
-
Suivi de la disponibilité
-
Rapports sur les accords de niveau de service (SLA)
-
Détection des problèmes DNS/SSL/réseau
-
Détection précoce des pannes avant que les clients ne s'en aperçoivent
Votre moniteur de temps de fonctionnement doit :
-
Ping de plusieurs sites dans le monde
-
Prise en charge des contrôles HTTP, TCP, ICMP, DNS et des ports
-
Alerte instantanée en cas de temps d'arrêt
-
Fournir des pages de statut public/privé
-
Suivi de l'historique des temps de fonctionnement et des incidents
Bons outils :
🔹 Xitoring (Uptime + surveillance du serveur en une seule plateforme)
UptimeRobot, Pingdom, BetterUptime
🔹 Bricolage avec Prometheus + Blackbox Exporter
Exemple de flux de travail avec Xitoring:
Vous configurez des contrôles de temps de fonctionnement pour les API et les pages d'atterrissage. Xitoring surveille les nœuds mondiaux toutes les minutes et alerte instantanément via Slack/Telegram en cas de pic de latence ou si le point d'accès devient inaccessible. La page d'état est mise à jour automatiquement - aucune communication manuelle n'est nécessaire.
2. Surveillance des serveurs et de l'infrastructure
C'est ici que vous suivez l'évolution du processeur, de la mémoire vive, de la charge moyenne, de l'entrée-sortie du disque, du débit du réseau, des journaux du système, etc.
Pourquoi c'est important :
De nombreuses pannes commencent ici - fuites de mémoire, disques pleins, ralentissement du processeur, problèmes de noyau, épuisement des ressources.
En 2025, un outil de surveillance des serveurs devrait fournir les éléments suivants :
✔ Collecte de données et tableaux de bord
✔ Alertes basées sur des seuils et des anomalies
✔ Surveillance des processus/services
Prise en charge de Linux et de Windows
✔ Collecte avec ou sans agent
Outils à prendre en compte :
Open-source : Prometheus + Node Exporter, Zabbix, Grafana
SaaS : Datadog, New Relic, Xitoring pour des informations en temps réel
Où Xitoring s'adapte :
Xitoring installe un agent léger, surveille les métriques Linux/Windows et utilise la détection de modèles d'IA pour vous avertir des comportements de performance inhabituels avant qu'ils n'entraînent des temps d'arrêt.
3. Surveillance des performances des applications (APM)
Même si les serveurs ont l'air en bonne santé, votre application pourrait être en difficulté.
L'APM fournit :
-
Traces de performance au niveau du code
-
Détection lente du point final/de la requête de base de données
-
Fuites de mémoire et suivi des exceptions
-
Ruptures de latence de bout en bout
Si votre application évolue rapidement ou s'étend sur des micro-services, l'APM n'est pas facultatif - c'est une question de survie.
4. Les journaux - la source de vérité en cas d'incident
Lorsque quelque chose tombe en panne, les ingénieurs se tournent vers les tableaux de bord... puis, éventuellement, vers le système d'information de l'entreprise. aux journaux.
L'enregistrement centralisé permet de répondre à cette question :
-
Que s'est-il passé avant l'accident ?
-
Quel est le service qui a déclenché l'exception ?
-
Le déploiement a-t-il introduit un bogue ?
-
S'agit-il d'un problème de système ou d'une dépendance externe ?
Exemples de piles de journaux :
-
ELK (Elasticsearch + Logstash + Kibana) - flexible, largement utilisé
-
Grafana Loki - moins cher et évolutif
-
Graylog, Splunk - les capacités de recherche de l'entreprise
-
Journaux natifs du cloud - GCP Logging, AWS CloudWatch
La journalisation doit être centralisée ; le fait de se connecter en SSH à des serveurs pour consulter les journaux est un problème qui date de 2010.
5. Traçage distribué - Comprendre le comportement du système
Lorsque les demandes passent par des files d'attente, des services, des équilibreurs de charge et des bases de données, le traçage est votre carte.
Le traçage distribué est utile :
✔ Visualiser le cheminement des demandes
✔ Identifier les goulets d'étranglement dans les microservices
✔ Déboguer les délais, les tentatives, les échecs
Normes et outils :
-
OpenTelemetry (norme industrielle)
-
Jaeger, Zipkin
-
AWS X-Ray / GCP Cloud Trace
Le traçage relie APM + journaux + métriques pour révéler l'image complète d'un incident.
6. Alerte et réponse aux incidents
La surveillance est inutile si elle ne s'accompagne pas d'alertes exploitables. Personne ne souhaite alerte fatigue, mais le silence pendant les pannes est encore pire.
Un flux de travail d'alerte moderne doit
-
Détecter
-
Informer la bonne personne
-
Fournir un contexte (tableaux de bord, journaux)
-
Déclencher une remédiation automatisée lorsque cela est possible
Canaux d'alerte :
-
Slack, Teams, Email
-
PagerDuty / OpsGenie
-
Telegram, SMS
-
Webhooks pour l'automatisation
Xitoring Exemple :
Lorsque le CPU reste au-dessus de 90% pendant 10 minutes, Xitoring envoie des alertes via Slack et Telegram, joint des métriques système et peut déclencher des scripts automatisés (par exemple, redémarrer un service ou mettre à l'échelle des pods).
AIOps et automatisation - Le changement de donne en 2025
L'évolution de la surveillance passe de réactive à prédictive.
L'IA peut aider à détecter :
-
Pics de trafic inhabituels
-
Fuites de mémoire lentes
-
Changements de latence avant l'impact sur l'utilisateur
-
Les tendances comportementales qui mènent à l'échec
Des plateformes comme Xitoring intègrent déjà Détection d'anomalies basée sur l'IA, permettant :
🔹 alerte automatique en cas de panne
🔹 suggestion de causes profondes
🔹 déclencheurs de récupération automatisés
L'avenir est infrastructure auto-réparatrice.
Meilleures pratiques pour les équipes DevOps en 2025
-
Alerte sur les symptômes, pas sur le bruit
Un pic de CPU seul n'est pas un problème - un pic + une augmentation de la latence l'est. -
Utiliser les pages d'état
Réduit la charge d'assistance et crée un climat de confiance avec les clients. -
Suivi des indicateurs SLO/SLI
La fiabilité est mesurable, et vous ne pouvez améliorer que ce que vous suivez. -
Observer attentivement les déploiements
La plupart des incidents sont dus à des rejets humains. -
Le suivi n'est pas un projet. C'est une culture.
Réflexions finales
Une pile de surveillance parfaite ne signifie pas qu'il faille acheter l'outil le plus cher ou concevoir à l'excès votre pipeline d'observabilité. Il s'agit de combiner des couches qui vous donnent une visibilité depuis la demande de l'utilisateur → le serveur → l'application → les journaux → la cause première.
S'il y a une chose à retenir :
Le contrôle ne doit pas vous indiquer que quelque chose a mal tourné, il doit vous indiquer pourquoi et comment y remédier rapidement.
Que vous choisissiez une pile de logiciels libres, une plateforme d'entreprise ou une solution unifiée telle que Xitoring qui combine le temps de disponibilité + la surveillance des serveurs avec des informations d'IA, la clé est de construire un système en lequel votre équipe a confiance et qu'elle utilise quotidiennement.