
Infrastruktur modern terdistribusi, bergerak cepat, dan semakin kompleks. Insinyur DevOps diharapkan dapat menerapkan lebih cepat, mendeteksi masalah lebih awal, mengotomatiskan respons, dan memastikan sistem tetap andal - semuanya sambil menjaga biaya cloud tetap waras. Pemantauan tidak lagi menjadi alat yang “bagus untuk dimiliki” yang berjalan di latar belakang. Pada tahun 2025, tumpukan pemantauan yang hebat adalah komponen kelas satu dari infrastruktur Anda.
Tapi inilah kebenarannya:
Sebagian besar perusahaan tidak memiliki strategi pemantauan terpadu - mereka memiliki kekacauan alat.
Lima dasbor, tiga sistem peringatan, dua cloud, dan tetap saja tidak ada yang menyadari lonjakan CPU hingga pelanggan membuka tiket dukungan.
Artikel ini membantu Anda membangun tumpukan pemantauan lengkap langkah demi langkah - yang membantu tim DevOps mendeteksi, mendiagnosis, dan bereaksi terhadap masalah bahkan sebelum pengguna menyadarinya.
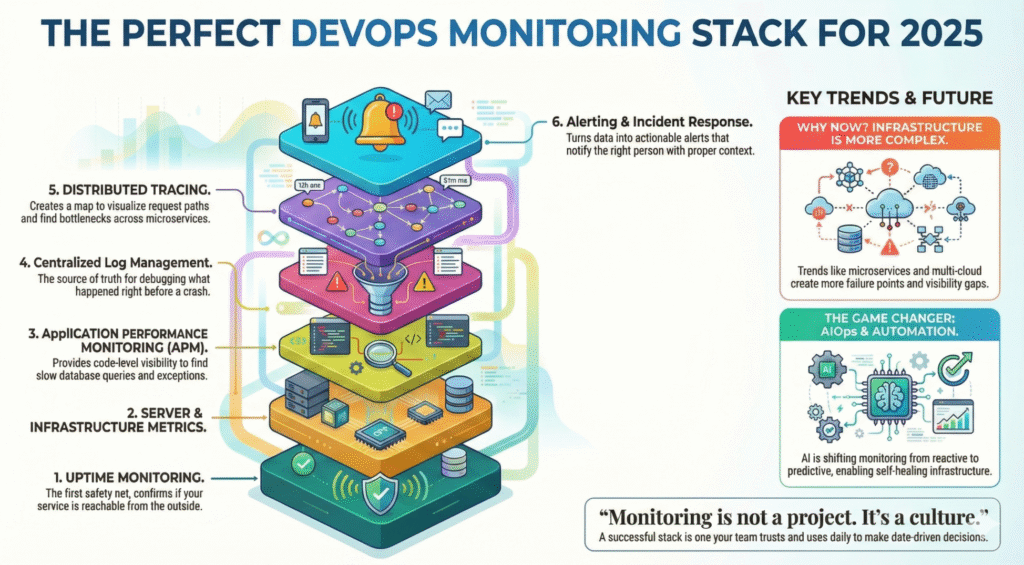
Apa yang akan Kami bahas
-
Mengapa pemantauan menjadi lebih penting di tahun 2025
-
6 pilar dari tumpukan pemantauan yang sempurna
-
Alat bantu yang paling sesuai (sumber terbuka + SaaS) untuk setiap lapisan
-
Otomatisasi & AIOps untuk respons insiden yang lebih cepat
-
Contoh nyata alur kerja menggunakan Xitoring
-
Praktik terbaik untuk membangun budaya pengamatan yang tahan masa depan
Ambil kopi Anda - mari rancang ekosistem pemantauan yang sempurna.
Mengapa Pemantauan Lebih Penting dari Sebelumnya di Tahun 2025
Tren infrastruktur sedang bergeser:
| Tren | Hasil |
|---|---|
| Layanan Mikro > Monolit | Titik kegagalan yang lebih terdistribusi |
| Adopsi multi-cloud | Korelasi visibilitas & metrik yang lebih keras |
| Tim jarak jauh & sistem global | Perlu pemantauan & otomatisasi 24/7 |
| Pengguna & beban kerja yang didukung AI | Sensitivitas kinerja yang lebih tinggi |
| Ekspektasi waktu kerja mendekati 100% | Biaya insiden lebih mahal dari sebelumnya |
Bahkan pemadaman kecil pun terasa menyakitkan. Beberapa menit waktu henti selama pembayaran dapat merugikan toko eCommerce hingga ribuan dolar. Penurunan kinerja dalam aplikasi SaaS secara langsung memengaruhi churn. Dan untuk layanan dengan SLA, waktu henti = uang keluar dari kantong.
Pemantauan bukan hanya tentang waktu kerja saja - ini tentang:
✔ Optimalisasi kinerja
✔ Perlindungan pengalaman pengguna
✔ Respon insiden yang cepat
✔ Deteksi kegagalan prediktif
✔ Keputusan teknik berbasis data
Tumpukan pemantauan Anda adalah sistem peringatan dini, laboratorium forensik, dan asisten operasi Anda - semuanya menjadi satu.
6 Pilar dari Tumpukan Pemantauan yang Sempurna
Pengaturan pemantauan yang matang mencakup beberapa lapisan yang bekerja bersama:
-
Pemantauan Waktu Kerja & Pemeriksaan Status
-
Metrik Server & Infrastruktur
-
Pemantauan Kinerja Aplikasi (APM)
-
Log & Manajemen Log Terpusat
-
Penelusuran & Pengamatan Terdistribusi
-
Peringatan, Respons Insiden & Otomatisasi
Sebagian besar kegagalan tidak terjadi secara terpisah - jadi stack yang baik menghubungkan metrik di semua lapisan.
Mari kita bahas satu per satu.
1. Pemantauan Uptime - Jaring Pengaman Pertama
Pemeriksaan waktu aktif mengonfirmasi apakah layanan Anda dapat dijangkau dari luar. Hal ini sangat penting:
-
Pelacakan ketersediaan
-
Pelaporan SLA
-
Mendeteksi masalah DNS/SSL/jaringan
-
Deteksi pemadaman dini sebelum pelanggan menyadarinya
Pemantau waktu aktif Anda seharusnya:
-
Ping dari beberapa lokasi global
-
Mendukung pemeriksaan HTTP, TCP, ICMP, DNS & port
-
Peringatan secara instan ketika waktu henti dimulai
-
Menyediakan halaman status publik/pribadi
-
Melacak waktu aktif & insiden historis
Alat yang bagus:
🔹 Xitoring (Waktu aktif + pemantauan server dalam satu platform)
🔹 UptimeRobot, Pingdom, BetterUptime
🔹 DIY dengan Prometheus + Eksportir Blackbox
Contoh Alur Kerja dengan Xitoring:
Anda mengonfigurasi pemeriksaan waktu aktif untuk API dan halaman arahan. Xitoring memonitor dari node global setiap menit dan langsung memberi tahu melalui Slack/Telegram jika latensi melonjak atau titik akhir tidak dapat dijangkau. Halaman status diperbarui secara otomatis - tidak perlu komunikasi manual.
2. Pemantauan Server & Infrastruktur
Di sinilah Anda melacak CPU, RAM, rata-rata beban, IO disk, throughput jaringan, log sistem, dan banyak lagi.
Mengapa ini penting:
Banyak pemadaman dimulai dari sini - kebocoran memori, disk penuh, pelambatan CPU, masalah kernel, kehabisan sumber daya.
Alat pemantauan server pada tahun 2025 harus menyediakan:
✔ Pengumpulan & dasbor metrik
✔ Peringatan berbasis ambang batas & anomali
✔ Pemantauan proses/layanan
✔ Dukungan Linux + Windows
✔ Agen atau koleksi tanpa agen
Alat yang Perlu Dipertimbangkan:
Sumber terbuka: Prometheus + Eksportir Node, Zabbix, Grafana
SaaS: Datadog, New Relic, Xitoring untuk wawasan waktu nyata
Di mana Xitoring cocok:
Xitoring menginstal agen ringan, memantau metrik Linux/Windows, dan menggunakan deteksi pola AI untuk memperingatkan Anda tentang perilaku kinerja yang tidak biasa sebelum menyebabkan downtime.
3. Pemantauan Kinerja Aplikasi (APM)
Bahkan jika server terlihat sehat, aplikasi Anda mungkin mengalami masalah.
APM menyediakan:
-
Jejak kinerja tingkat kode
-
Deteksi kueri titik akhir/database yang lambat
-
Kebocoran memori & pelacakan pengecualian
-
Kerusakan latensi ujung ke ujung
Jika aplikasi Anda berskala cepat atau menjangkau layanan mikro, APM bukanlah pilihan - ini adalah kelangsungan hidup.
4. Log - Sumber Kebenaran Selama Insiden
Ketika ada yang rusak, para teknisi berlari ke dasbor... dan akhirnya ke log.
Penebangan terpusat membantu menjawabnya:
-
Apa yang terjadi sebelum kecelakaan?
-
Layanan mana yang memberikan pengecualian?
-
Apakah penerapan tersebut menimbulkan bug?
-
Apakah ini masalah sistem atau ketergantungan eksternal?
Contoh Tumpukan Log:
-
ELK (Elasticsearch + Logstash + Kibana) - fleksibel, banyak digunakan
-
Grafana Loki - lebih murah & terukur
-
Graylog, Splunk - kemampuan pencarian perusahaan
-
Log asli cloud - Pencatatan GCP, AWS CloudWatch
Pencatatan harus terpusat; SSH ke server untuk mengekor log adalah masalah tahun 2010.
5. Penelusuran Terdistribusi - Memahami Perilaku Sistem
Ketika permintaan melewati antrean, layanan, penyeimbang beban, dan basis data - penelusuran adalah peta Anda.
Bantuan penelusuran terdistribusi:
✔ Memvisualisasikan jalur permintaan
✔ Mengidentifikasi hambatan di seluruh layanan mikro
✔ Waktu habis debug, percobaan ulang, kegagalan
Standar & Alat:
-
OpenTelemetri (standar industri)
-
Jaeger, Zipkin
-
Jejak Awan X-Ray / GCP AWS
Penelusuran menghubungkan APM + log + metrik bersama-sama untuk mengungkapkan gambaran lengkap dari sebuah insiden.
6. Peringatan & Respons Insiden
Pemantauan tidak berguna tanpa peringatan yang dapat ditindaklanjuti. Tidak ada yang mau kelelahan waspada, tetapi keheningan selama pemadaman listrik bahkan lebih buruk lagi.
Alur kerja peringatan yang modern seharusnya demikian:
-
Mendeteksi
-
Beri tahu orang yang tepat
-
Menyediakan konteks (dasbor, log)
-
Memicu remediasi otomatis jika memungkinkan
Saluran Peringatan:
-
Kelonggaran, Tim, Email
-
PagerDuty / OpsGenie
-
Telegram, SMS
-
Webhook untuk otomatisasi
Contoh Xitoring:
Ketika CPU tetap berada di atas 90% selama 10 menit, Xitoring mengirimkan peringatan melalui Slack dan Telegram, melampirkan metrik sistem, dan dapat memicu skrip otomatis (mis., memulai ulang layanan atau skala pod).
AIOps & Otomasi - Pengubah Permainan 2025
Evolusi pemantauan bergerak dari reaktif → prediktif.
AI dapat membantu mendeteksi:
-
Lonjakan lalu lintas yang tidak biasa
-
Kebocoran memori yang lambat
-
Perubahan latensi sebelum dampak pengguna
-
Tren perilaku yang menyebabkan kegagalan
Platform seperti Xitoring sudah terintegrasi Deteksi anomali berbasis AI, memungkinkan:
🔹 peringatan otomatis sebelum pemadaman listrik
🔹 saran tentang akar masalah
🔹 pemicu pemulihan otomatis
Masa depan adalah infrastruktur penyembuhan diri.
Praktik Terbaik untuk Tim DevOps di Tahun 2025
-
Waspada terhadap gejala, bukan kebisingan
Lonjakan CPU saja tidak menjadi masalah - lonjakan + peningkatan latensi yang menjadi masalah. -
Gunakan halaman status
Mengurangi beban dukungan dan membangun kepercayaan dengan pelanggan. -
Melacak metrik SLO/SLI
Keandalan dapat diukur, dan Anda dapat meningkatkan hanya apa yang Anda lacak. -
Amati penyebaran dengan cermat
Sebagian besar insiden adalah pelepasan manusia. -
Pemantauan bukanlah sebuah proyek. Ini adalah sebuah budaya.
Pikiran Akhir
Tumpukan pemantauan yang sempurna bukan berarti membeli alat yang paling mahal atau merekayasa secara berlebihan pipeline pengamatan Anda. Ini berarti menggabungkan lapisan yang memberi Anda visibilitas dari permintaan pengguna → server → aplikasi → log → penyebab utama.
Jika ada satu hal yang bisa dibawa pulang:
Pemantauan seharusnya tidak memberi tahu Anda bahwa ada sesuatu yang salah - pemantauan seharusnya memberi tahu Anda mengapa dan cara memperbaikinya dengan cepat.
Apakah Anda memilih stack sumber terbuka, platform perusahaan, atau solusi terpadu seperti Xitoring yang menggabungkan waktu aktif + pemantauan server dengan wawasan AI, kuncinya adalah membangun sistem yang dipercaya dan digunakan oleh tim Anda setiap hari.