現代のインフラは分散し、動きが速く、複雑さを増しています。DevOpsエンジニアは、より迅速なデプロイ、問題の早期発見、対応の自動化、システムの信頼性の確保を、クラウドのコストを抑えながら行うことが求められている。モニタリングはもはや、バックグラウンドで動作する「あれば便利」なツールではありません。2025年、優れたモニタリング・スタックは、インフラストラクチャの一流コンポーネントとなる。.
しかし、ここに真実がある:
ほとんどの企業は統一されたモニタリング戦略を持っていない。.
5つのダッシュボード、3つのアラートシステム、2つのクラウド、それでも顧客がサポートチケットを開くまで誰もCPUの急上昇に気づかない。.
この記事で、そのためのヒントを得よう。 完全モニタリングスタック ステップバイステップ - DevOpsチームを支援するもの ユーザーが気づく前に、問題を検出、診断、対処する。.
取材内容
-
2025年にモニタリングがこれまで以上に重要になる理由
-
完璧なモニタリング・スタックの6つの柱
-
各レイヤーに最適なツール(オープンソース+SaaS
-
自動化とAIOpsによる迅速なインシデント対応
-
実際のワークフロー例 Xitoring
-
将来を見据えた観測可能性文化を構築するためのベストプラクティス
コーヒーでも飲みながら、完璧なモニタリング・エコシステムを設計しましょう。.
2025年にモニタリングがこれまで以上に重要になる理由
インフラのトレンドは変わりつつある:
| トレンド | 結果 |
|---|---|
| マイクロサービス > モノリス | より分散した故障点 |
| マルチクラウドの採用 | より困難な可視化とメトリクスの相関性 |
| リモートチームとグローバルシステム | 24時間365日の監視と自動化が必要 |
| AIを活用したユーザーとワークロード | より高い性能感度 |
| 100%付近の稼働期待値 | インシデントのコストはかつてないほど高い |
小さな停電でも痛手だ。. チェックアウト時の数分間のダウンタイムが、Eコマースストアに数千ドルの損失を与える可能性があります。SaaSアプリのパフォーマンス低下は、解約に直接影響します。また、SLAが設定されているサービスでは、ダウンタイム=資金流出となります。.
モニタリングはもはや稼働時間だけの問題ではない:
パフォーマンスの最適化
ユーザーエクスペリエンスの保護
迅速なインシデント対応
故障予知
データに基づくエンジニアリングの意思決定
モニタリング・スタックは、早期警告システムであり、フォレンジック・ラボであり、オペレーション・アシスタントである。.
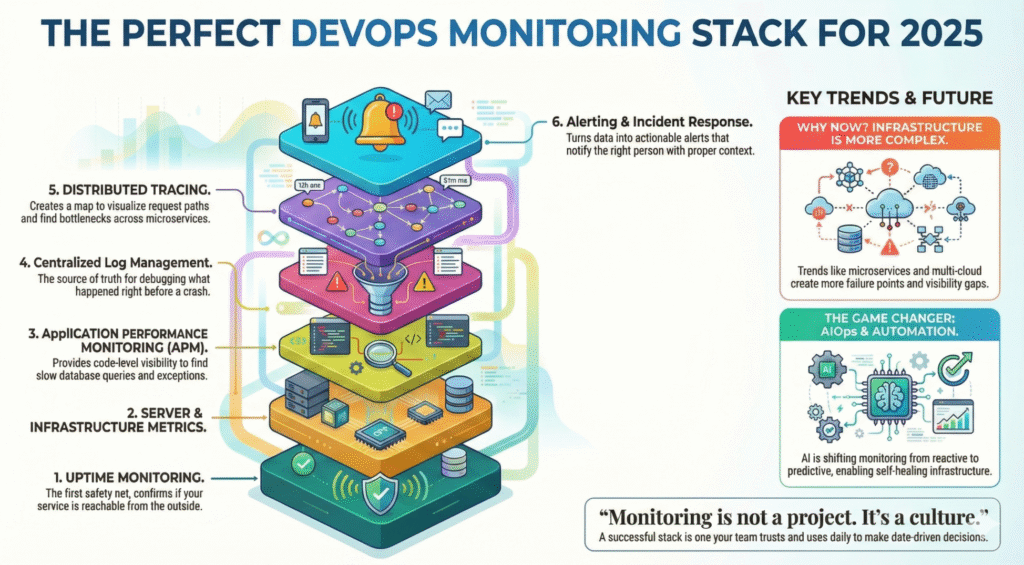
完璧なモニタリング・スタックの6つの柱
成熟したモニタリング・セットアップには、複数のレイヤーが連携している:
-
アップタイム監視とステータスチェック
-
サーバー&インフラ指標
-
アプリケーション・パフォーマンス・モニタリング(APM)
-
ログと集中ログ管理
-
トレースと分散観測可能性
-
アラート、インシデントレスポンス、自動化
ほとんどの失敗は単独では起こらない。だから、優れたスタックはすべてのレイヤーにわたってメトリクスを相関させる。.
ひとつひとつ分解してみよう。.
1.アップタイム監視 - 最初のセーフティネット
アップタイムチェックは、サービスが外部から到達可能かどうかを確認します。これは次のような場合に重要です:
-
アベイラビリティ・トラッキング
-
SLAレポート
-
DNS/SSL/ネットワークの問題の検出
-
顧客が気付く前に停電を早期発見
稼働時間モニターはそうあるべきだ:
-
からのPing 複数のグローバル拠点
-
HTTP、TCP、ICMP、DNS、ポートチェックをサポート
-
ダウンタイムが始まると即座に警告
-
公的/私的ステータスページの提供
-
過去の稼働時間とインシデントを追跡
良い道具だ:
🔹 Xitoring(アップタイム+サーバー監視を1つのプラットフォームで実現)
UptimeRobot、Pingdom、BetterUptime
Prometheus + Blackbox ExporterでDIY。
ワークフロー例 Xitoring:
APIとランディングページのアップタイムチェックを設定します。Xitoringはグローバルノードから1分ごとに監視し、レイテンシが急増したり、エンドポイントが到達不能になった場合、即座にSlack/Telegram経由で警告を発します。ステータスページは自動的に更新されます。.
2.サーバーとインフラの監視
ここでは、CPU、RAM、ロードアベレージ、ディスクIO、ネットワークスループット、システムログなどを追跡します。.
なぜそれが重要なのか:
メモリリーク、ディスクの満杯、CPUのスロットリング、カーネルの問題、リソースの枯渇などだ。.
2025年のサーバー監視ツールはこうあるべきだ:
指標収集とダッシュボード
閾値ベースの異常アラート
プロセス/サービス監視
Linux + Windows サポート
エージェントまたはエージェントレス収集
検討すべきツール
オープンソース:Prometheus + Node Exporter、Zabbix、Grafana
SaaS:Datadog、New Relic、, Xitoringによるリアルタイムの洞察
どこ Xitoring フィットする:
Xitoringは、軽量エージェントをインストールし、Linux/Windowsのメトリクスを監視し、AIパターン検出を使用して、ダウンタイムが発生する前に異常なパフォーマンス動作を警告します。.
3.アプリケーション・パフォーマンス・モニタリング(APM)
たとえサーバーが健康そうに見えてもだ、, あなたのアプリケーションは苦労しているかもしれない.
APMは提供する:
-
コードレベルのパフォーマンス・トレース
-
エンドポイント/データベースクエリの検出が遅い
-
メモリリークと例外の追跡
-
エンド・ツー・エンドの遅延内訳
アプリケーションが高速にスケールしたり、マイクロサービスにまたがる場合、APMはオプションではない。.
4.ログ - 事件発生時の真実の情報源
何かが壊れると、エンジニアはダッシュボードに走り......そして最終的には ログへ.
一元化されたロギングはその答えに役立つ:
-
事故の前に何があったのか?
-
どのサービスが例外を発生させたのか?
-
デプロイはバグを導入したのか?
-
システムの問題か、外部依存か?
ログスタックの例:
-
ELK (Elasticsearch + Logstash + Kibana) - フレキシブル、広く使用されている
-
グラファナ・ロキ - より安価でスケーラブル
-
Graylog, Splunk - エンタープライズ検索機能
-
クラウドネイティブログ - GCP Logging、AWS CloudWatch
ログの記録は一元化されていなければならない。SSHでサーバーにログインしてログを記録するのは2010年の問題である。.
5.分散トレース - システムの挙動を理解する
リクエストがキュー、サービス、ロードバランサー、データベースを通過するとき、トレースはあなたの地図となる。.
分散トレースが役立つ
リクエストパスの可視化
マイクロサービス間のボトルネックの特定
タイムアウト、リトライ、失敗のデバッグ
基準とツール:
-
OpenTelemetry(業界標準)
-
イェーガー、ジプキン
-
AWS X-Ray / GCP Cloud Trace
トレースは、APM+ログ+メトリクスを結びつけ、インシデントの全体像を明らかにする。.
6.アラートとインシデントレスポンス
行動可能なアラートがなければ、モニタリングは役に立たない。誰も 注意力疲労, しかし、停電中の沈黙はもっとひどい。.
最新のアラートワークフローはこうあるべきだ:
-
検出
-
適切な人物に通知する
-
コンテキストを提供する(ダッシュボード、ログ)
-
可能な限り自動修復をトリガーする
アラート・チャンネル
-
Slack、チーム、Eメール
-
PagerDuty/オプスジェニー
-
Telegram、SMS
-
オートメーション用Webhook
Xitoringの例:
CPUが90%以上の状態が10分間続くと、XitoringはSlackとTelegram経由でアラートを送信し、システムメトリクスを添付し、自動化スクリプト(サービスの再起動やポッドのスケールなど)をトリガーできる。.
AIOpsとオートメーション - 2025年のゲームチェンジャー
モニタリングの進化は、反応的なものから予測的なものへと移行しつつある。.
AIは検知を助けることができる:
-
異常なトラフィックの急増
-
遅いメモリリーク
-
ユーザーに影響を与える前のレイテンシーの変化
-
失敗につながる行動傾向
Xitoringのようなプラットフォームはすでに統合されている AIによる異常検知, 可能にする:
停電前の自動アラート 🔹。
根本原因の示唆
🔹 自動回復トリガー
未来は 自己修復インフラ.
2025年のDevOpsチームのベストプラクティス
-
ノイズではなく、症状に注意
CPUのスパイクだけでは問題ではなく、スパイク+レイテンシの増加が問題なのだ。. -
ステータスページの使用
サポートの負担を軽減し、顧客との信頼関係を築く。. -
SLO/SLI指標を追跡する
信頼性は測定可能であり、追跡したものだけを改善することができる。. -
配備をよく観察する
ほとんどの事故は人為的なものだ。. -
モニタリングはプロジェクトではない。文化なのだ。.
最終的な感想
完璧なモニタリング・スタックとは、最も高価なツールを購入することでも、観測可能なパイプラインを過剰に設計することでもない。ユーザーリクエスト → サーバー → アプリケーション → ログ → 根本原因という可視性を提供するレイヤーを組み合わせることを意味する。.
ひとつだけ収穫があるとすれば:
モニタリングは、何かが間違っていたことを伝えるべきでない。 なぜ そして、それを素早く解決する方法。.
オープンソースのスタック、エンタープライズ・プラットフォーム、または以下のような統合ソリューションのいずれを選択するかにかかわらず。 Xitoring アップタイム+サーバー監視とAIインサイトを組み合わせたシステムで、重要なのは、チームが信頼し、毎日使用するシステムを構築することです。.