InfluxDB 監視
設定不要で、InfluxDBの書き込みスループット、クエリパフォーマンス、ストレージエンジンのメトリクス、および保存ポリシーの健全性をリアルタイムで監視できます。
なぜ監視するのか InfluxDB?
InfluxDBは、メトリクス、イベント、リアルタイム分析向けの主要な時系列データベースです。InfluxDBを監視することで、書き込みの正常な取り込み、最適なクエリパフォーマンス、および適切なデータ保持管理を確保できます。
InfluxDB 監視を 解説
InfluxDB 監視は、書き込みスループットの停滞、暴走する系列カーディナリティ(InfluxDB 1.x/2.x の典型的な障害モード)、TSM 圧縮バックログ、クエリの遅延、WAL の肥大化を、取り込みロスや Grafana ダッシュボードのクエリタイムアウトを引き起こす前に検出します。IoT センサーパイプライン、アプリケーションメトリクスバックエンド、あらゆる TICK スタックデプロイメントにおいて、データベースごとの可視性が、60 秒のアラートと、欠落したデータポイントを何時間もかけて追跡する大規模インシデントとの違いを生みます。Xitoring は InfluxDB を自動検出し、ネイティブの /metrics Prometheus エンドポイントを読み取り、Slack、PagerDuty、Telegram、または既存のオンコールにアラートをルーティングします。
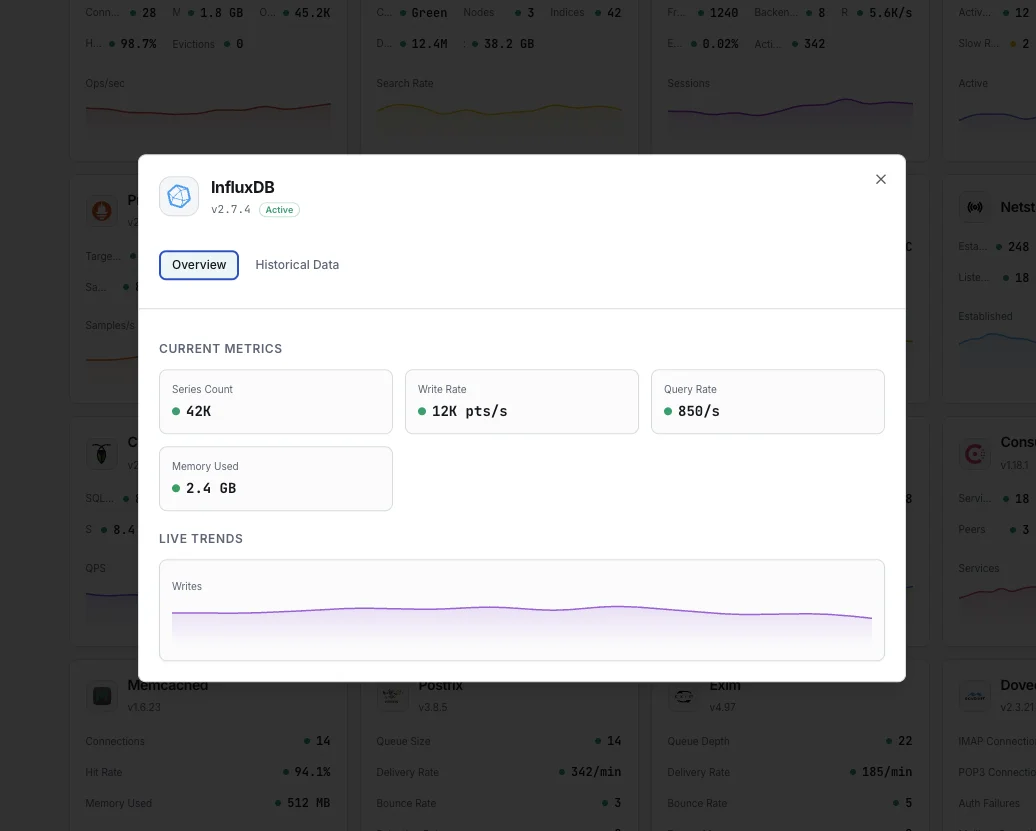
私たちが 監視するもの
書き込みポイント/秒
データポイントの書き込みレート。
クエリ実行時間
クエリの平均実行時間。
シリーズカーディナリティ
ユニークな時系列の総数。
ストレージサイズ
ディスク上のTSMストレージ。
コンパクションレート
TSMコンパクションのスループット。
キャッシュサイズ
インメモリ書き込みキャッシュの使用量。
WAL ディスクバイト数
`storage.tsm1.wal.currentSegmentDiskBytes` + `oldSegmentsDiskBytes`。TSM 統合なしの WAL 成長は、再起動時のリカバリ時間が肥大化することを意味します。
ディスク上のストレージサイズ
`storage.tsm1.filestore.diskBytes` + シャードごとの numFiles。リテンションポリシーと照らして追跡 — 同じデータサイズで高いファイル数はフラグメンテーションを示します。
HTTP 4xx / 5xx レート
`httpd.clientError` + `httpd.serverError`(または Prometheus の `http_api_request_errors_total`)。4xx の急増はクライアントのスキーマ / 認証バグを、5xx はサーバー側の障害を示します。
接続 / 認証失敗
`httpd.req`(HTTP リクエスト総数)、`httpd.authFail`(失敗した認証試行)、`httpd.pingReq`。認証失敗の急増は、設定ミスの Telegraf や認証情報のローテーションの問題を示します。
ランタイム — Goroutine と GC
Go ランタイム統計: `runtime.NumGoroutine`(goroutine リーク検出)、`runtime.HeapAlloc`(ライブヒープ)、`runtime.NumGC`/`PauseTotalNs`(GC 負荷)。OOM 前にリークやポーズ時間の劣化を検出します。
サブスクリプション書き込み
`subscriber.pointsWritten` と `subscriber.writeFailures` — Kapacitor やダウンストリームパイプラインがサブスクリプション経由で消費する場合、これがバックプレッシャーを検出する方法です。
設定可能 アラートのトリガー
ダッシュボードでカスタムトリガーを設定し、InfluxDBのメトリクスが定義した閾値を超えた瞬間に通知を受け取れるようにします。
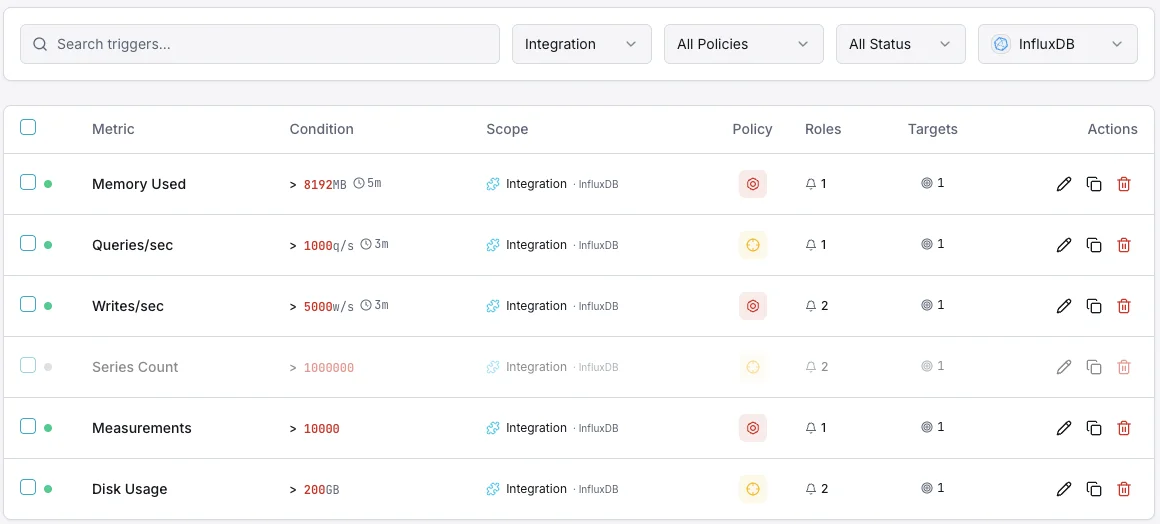
書き込みスループット
警告書き込みレートの異常で発動。
クエリ実行時間
警告遅いクエリでアラート。
シリーズカーディナリティ
重要なカーディナリティが高すぎるときに発動。
ストレージサイズ
重要なストレージが閾値を超えたときに発動。
の重要性: InfluxDB監視
InfluxDBは高速な時系列データを処理します。高カーディナリティ、書き込み圧力、コンパクション遅延はパフォーマンスを低下させます。
- 取り込みの健全性のために書き込みスループットを追跡
- OOMを防ぐためにシリーズカーディナリティを監視
- 遅いクエリを早期に検出
- コンパクションが追いつくように確保
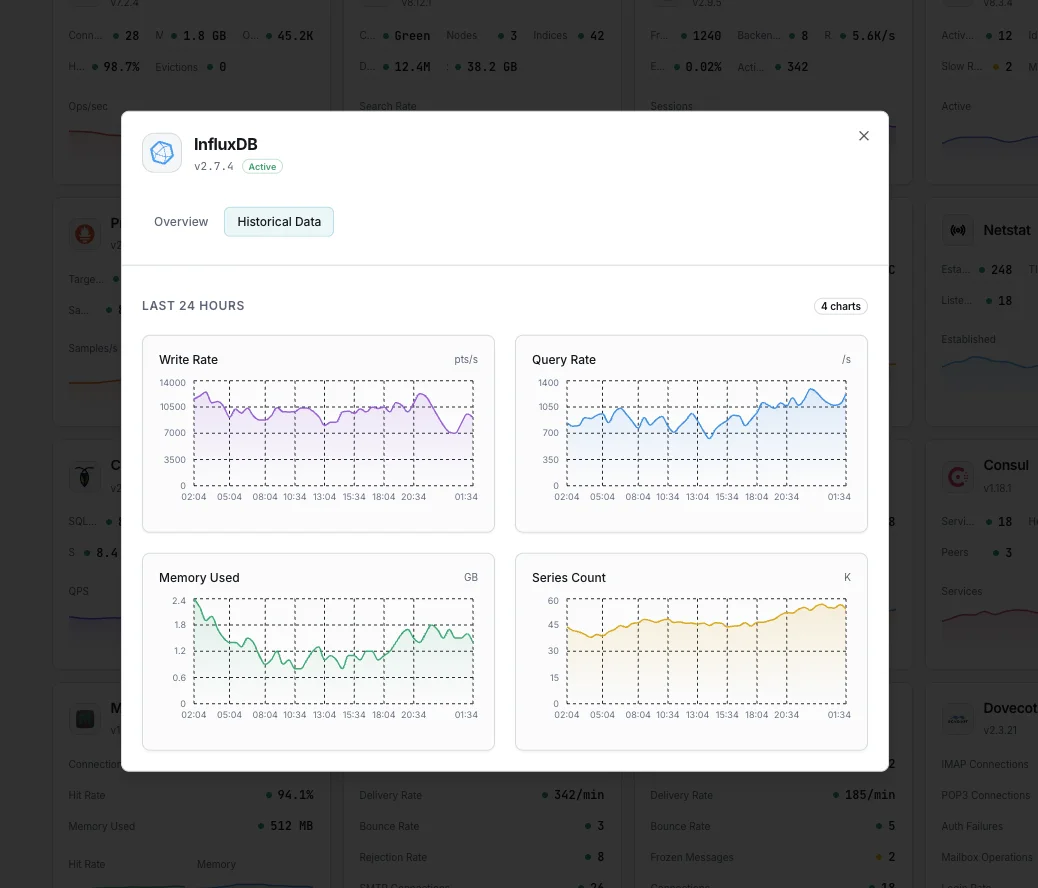
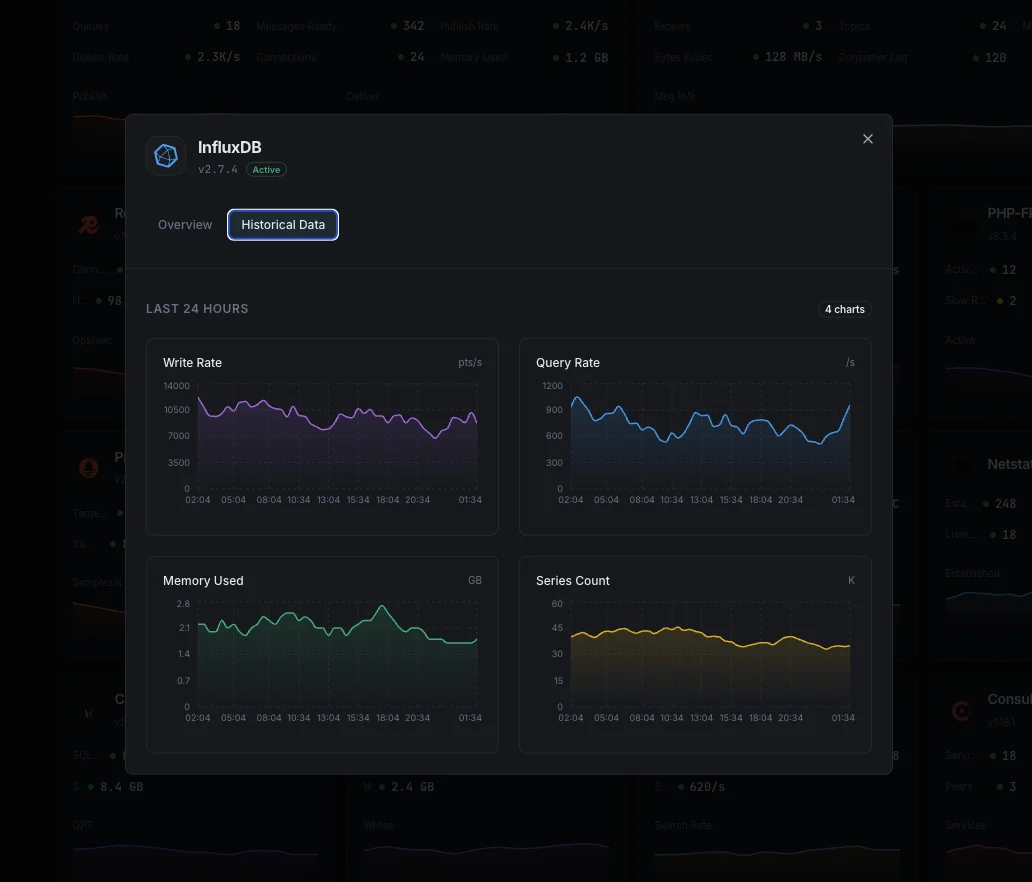
なぜ選ぶべきか: Xitoring
ゼロコンフィグのInfluxDB監視。
- ワンコマンドインストール
- グローバルノード
- 統合ダッシュボード
- マルチチャネルアラート
- 履歴保持
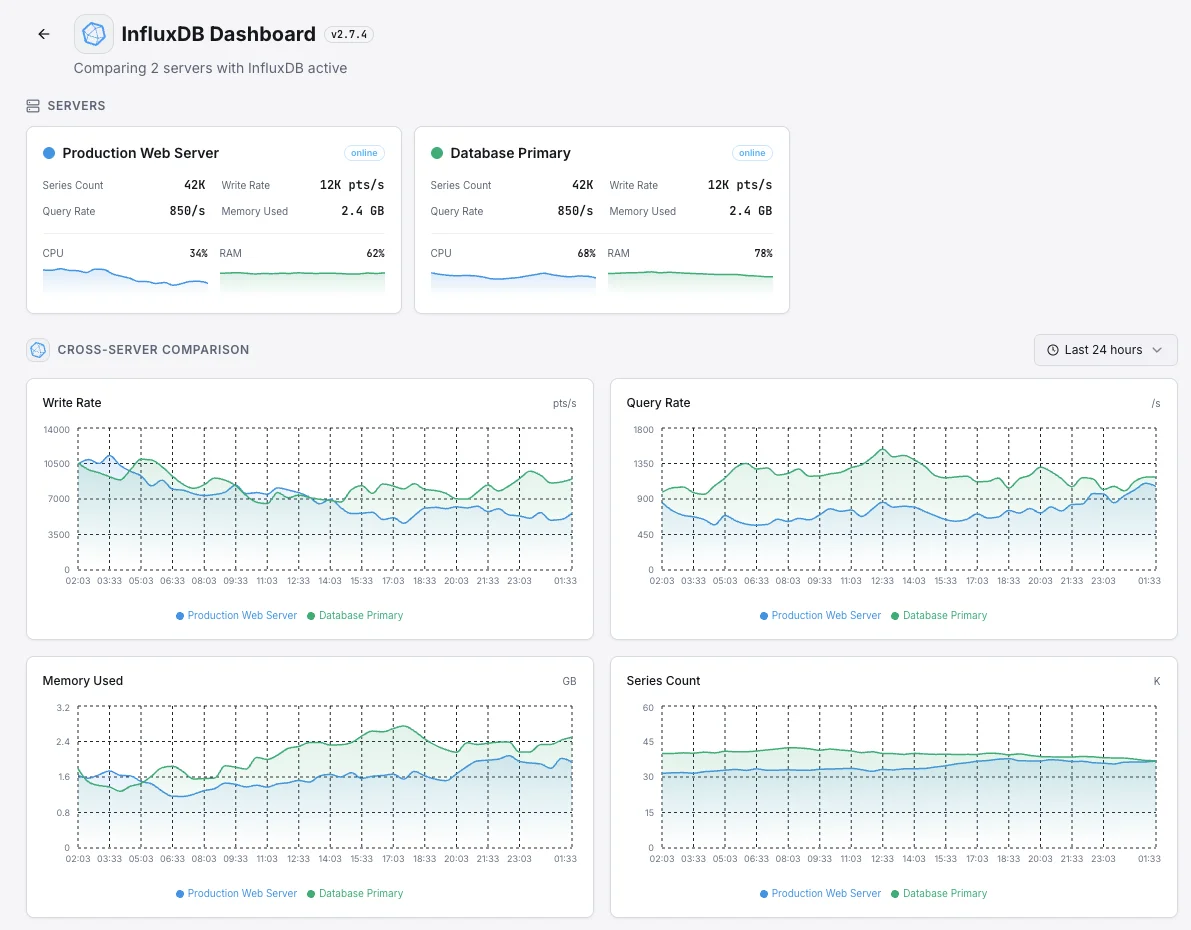
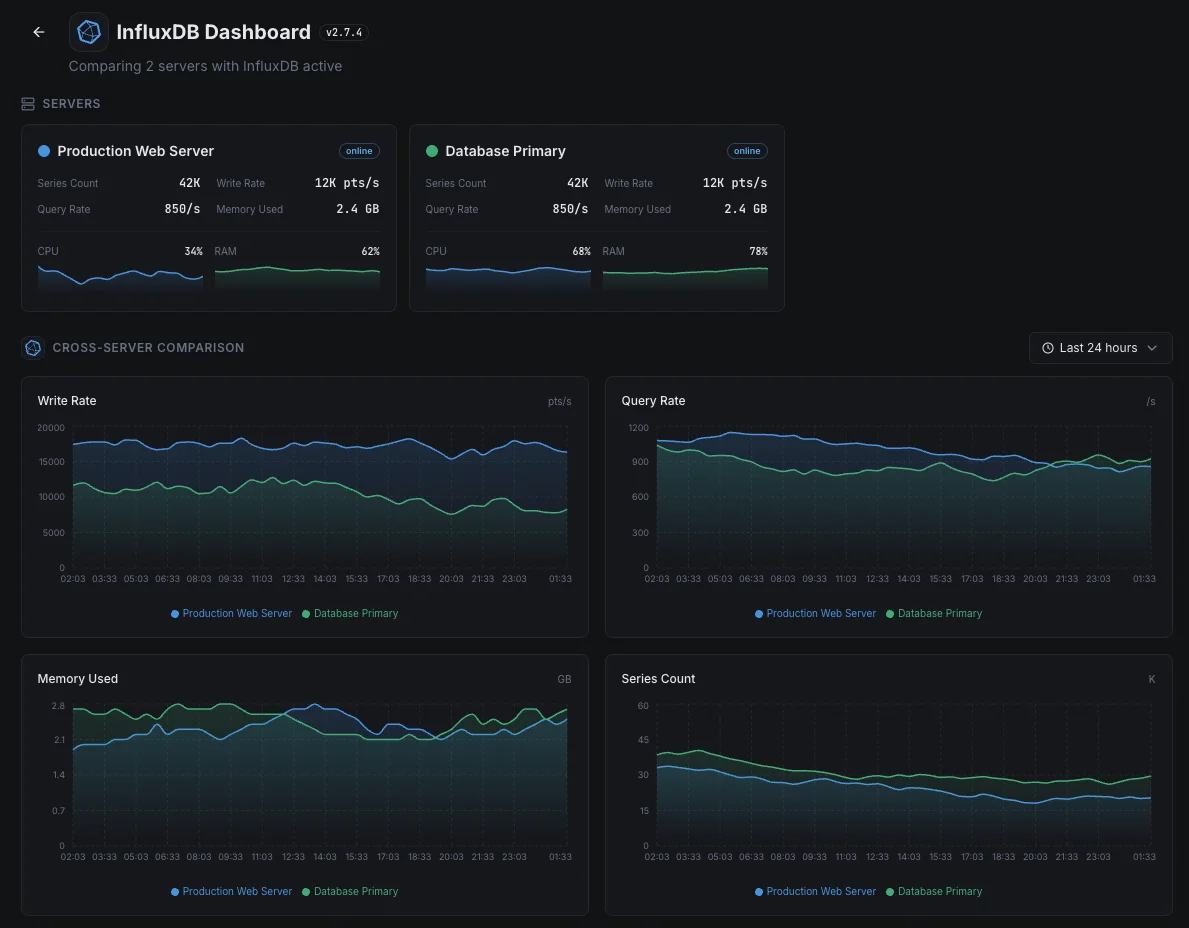
InfluxDB 監視の一般的な シナリオ
InfluxDBが今日一般的に稼働している場所 — そして誰も監視していない場合に何が問題になる可能性があるか。
チームのダッシュボードの背後にあるデータベース
Grafanaや他のツールのダッシュボードが遅いと感じる場合、原因はダッシュボード自体ではなく、その下のデータベースにあることがよくあります。私たちは遅延が実際にどこにあるかを明らかにし、チームが症状を追うのではなく、正しいものを修正できるようにします。
センサーおよびデバイスから流入するデータ
接続されたデバイス、工場設備、IoTセンサーは、毎日毎秒測定値を送信します。パイプラインでの静かなバックアップはデータ損失を意味し、失われたデータは永遠に失われます。私たちはフローをエンドツーエンドで監視し、単一の読み取り値の欠落がアラームを発生させるようにします。
アプリケーションとインフラストラクチャのメトリクスを一箇所で
同じデータベースがアプリケーションメトリクスとサーバーメトリクスの両方を保持している場合、データベースの問題はすべてのシグナルを一度に隠してしまいます。私たちはデータベース自体を監視し、インシデント発生時にチーム自身の監視が停止しないようにします。
InfluxDB の 前提条件
これらが揃っていることを確認してください — 揃っていれば、ほとんどの導入は 60 秒で完了します。
- InfluxDB 1.x または 2.x がサーバー上で稼働していること
- Xitogent から InfluxDB の HTTP ポートに到達可能であること(デフォルト 8086)
- オプション: InfluxDB 2.x で認証が有効な場合、読み取り専用トークン
はじめに 議事録
InfluxDB ホストに Xitogent をインストール
InfluxDB が稼働しているホストに軽量な Xitogent 監視エージェントをインストールしてください。
curl -s https://xitoring.com/install.sh | sudo bash -s -- --key=YOUR_API_KEYInfluxDB が到達可能であることを確認
InfluxDB が HTTP ポート(デフォルト 8086)でリッスンしており、Xitogent を実行するホストから到達可能であることを確認してください。Xitogent は integrate 中にホストとポートを尋ねます — 追加の設定変更やエンドポイントの公開は不要です。
sudo xitogent integrateInfluxDB 連携を有効化
Xitoring ダッシュボードまたは CLI から InfluxDB 連携を有効化してください。Xitogent が InfluxDB のバージョンを自動検出し、書き込み、クエリ、ストレージのメトリクス収集を開始します。
アラートしきい値を設定(オプション)
書き込みスループット、クエリ時間、シリーズのカーディナリティにカスタムしきい値を設定し、クエリが遅くなる前に取り込み圧力やタグの暴走を検知できるようにします。
動作確認
サーバー上でこのコマンドを実行して、Xitogent が連携を認識していることを確認してください。約 30 秒以内に新しいメトリクスがダッシュボードに流れ始めます。
sudo xitogent status代替ツールを 検討中ですか?
InfluxDB 監視の代替ツールと比べて Xitoring がどう優れているかをご覧ください — 定額料金、より深い統合、そしてスタック全体をカバーする 1 つのエージェント。



頻繁に 質問をした
InfluxDB 1.x と 2.x?
影響は?
InfluxDB のカーディナリティ問題を検出するにはどうすればよいですか?
InfluxDB の _internal データベースとは何ですか?
InfluxDB の圧縮を監視するにはどうすればよいですか?
InfluxDB 1.x、2.x、3.0 の監視の違いは何ですか?
InfluxDB のクエリ遅延を検出するにはどうすればよいですか?
InfluxDB の TSM ストレージを監視するにはどうすればよいですか?
このインテグレーションは InfluxDB のパフォーマンスに影響しますか?
探検を続けよう