
A pilha de monitoramento perfeita: Ferramentas e estratégias que todo engenheiro de DevOps deve usar em 2025
A infraestrutura moderna é distribuída, de rápida movimentação e cada vez mais complexa. Espera-se que os engenheiros de DevOps implementem mais rapidamente, detectem problemas mais cedo, automatizem as respostas e garantam que os sistemas permaneçam confiáveis, tudo isso mantendo os custos da nuvem sob controle. O monitoramento não é mais uma ferramenta “boa de se ter” executada em segundo plano. Em 2025, uma excelente pilha de monitoramento é um componente de primeira classe da sua infraestrutura.
Mas aqui está a verdade:
A maioria das empresas não tem uma estratégia de monitoramento unificada - elas têm um caos de ferramentas.
Cinco painéis, três sistemas de alerta, duas nuvens e, ainda assim, ninguém percebe o pico de CPU até que o cliente abra um tíquete de suporte.
Este artigo ajuda você a criar um pilha de monitoramento completa passo a passo - um que ajude as equipes de DevOps detectar, diagnosticar e reagir a problemas antes mesmo que os usuários percebam.
O que abordaremos
-
Por que o monitoramento é mais importante do que nunca em 2025
-
Os 6 pilares de uma pilha de monitoramento perfeita
-
Ferramentas mais adequadas (código aberto + SaaS) para cada camada
-
Automação e AIOps para uma resposta mais rápida a incidentes
-
Fluxos de trabalho de exemplo real usando Monitoramento
-
Práticas recomendadas para criar uma cultura de observabilidade preparada para o futuro
Pegue seu café - vamos projetar o ecossistema de monitoramento perfeito.
Por que o monitoramento é mais importante do que nunca em 2025
As tendências de infraestrutura estão mudando:
| Tendência | Resultado |
|---|---|
| Microsserviços > Monólitos | Mais pontos de falha distribuídos |
| Adoção de várias nuvens | Visibilidade mais difícil e correlação de métricas |
| Equipes remotas e sistemas globais | Necessidade de monitoramento e automação 24 horas por dia, 7 dias por semana |
| Usuários e cargas de trabalho com tecnologia de IA | Maior sensibilidade de desempenho |
| Expectativas de tempo de atividade próximas a 100% | Os incidentes custam mais do que nunca |
Até mesmo pequenas interrupções prejudicam. Alguns minutos de tempo de inatividade durante o checkout podem custar milhares a uma loja de comércio eletrônico. Uma degradação do desempenho em um aplicativo SaaS afeta diretamente a rotatividade. E para serviços com SLAs, tempo de inatividade = dinheiro fora do bolso.
O monitoramento não é mais apenas uma questão de tempo de atividade, mas sim de:
Otimização do desempenho
Proteção da experiência do usuário
Resposta rápida a incidentes
Detecção preditiva de falhas
Decisões de engenharia orientadas por dados
Sua pilha de monitoramento é seu sistema de alerta antecipado, seu laboratório forense e seu assistente de operações - tudo em um.
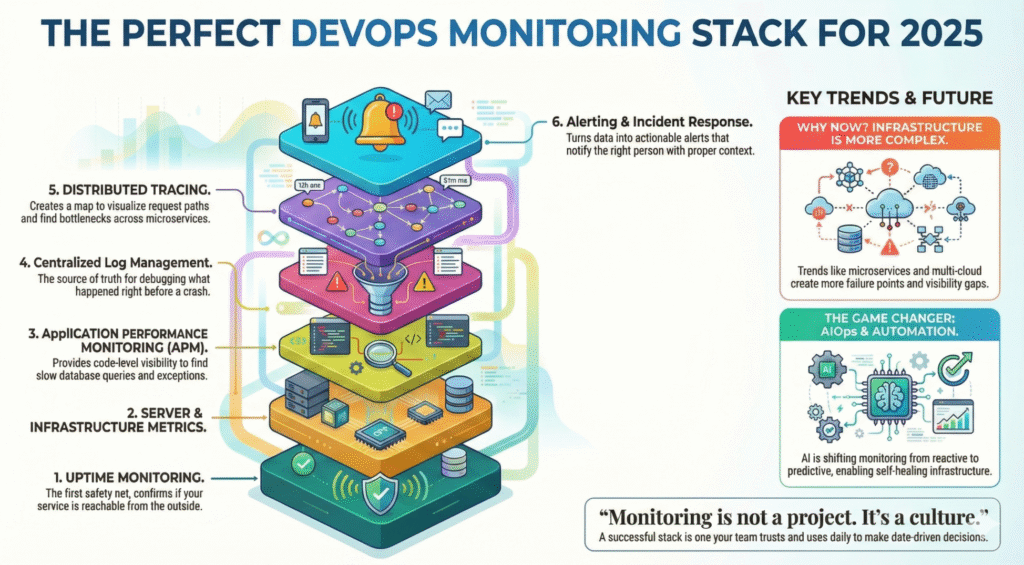
Os 6 pilares de uma pilha de monitoramento perfeita
Uma configuração de monitoramento madura inclui várias camadas trabalhando juntas:
-
Monitoramento do tempo de atividade e verificação de status
-
Métricas de servidor e infraestrutura
-
Monitoramento do desempenho de aplicativos (APM)
-
Registros e gerenciamento centralizado de registros
-
Rastreamento e observabilidade distribuída
-
Alerta, resposta a incidentes e automação
A maioria das falhas não acontece de forma isolada, portanto, uma boa pilha correlaciona métricas em todas as camadas.
Vamos detalhá-los um a um.
1. Monitoramento do tempo de atividade - a primeira rede de segurança
As verificações de tempo de atividade confirmam se o seu serviço pode ser acessado de fora. Isso é fundamental para:
-
Rastreamento de disponibilidade
-
Relatórios de SLA
-
Detecção de problemas de DNS/SSL/rede
-
Detecção antecipada de interrupções antes que os clientes percebam
Seu monitor de tempo de atividade deve:
-
Ping de vários locais globais
-
Suporte a HTTP, TCP, ICMP, DNS e verificações de porta
-
Alerta instantâneo quando o tempo de inatividade começa
-
Fornecer páginas de status públicas/privadas
-
Acompanhe o histórico de tempo de atividade e incidentes
Boas ferramentas:
🔹 Xitoring (Tempo de atividade + monitoramento de servidor em uma única plataforma)
UptimeRobot, Pingdom, BetterUptime
Faça você mesmo com o Prometheus + Blackbox Exporter
Exemplo de fluxo de trabalho com Monitoramento:
Você configura verificações de tempo de atividade para APIs e páginas de destino. O Xitoring monitora os nós globais a cada minuto e alerta instantaneamente via Slack/Telegram se houver picos de latência ou se o endpoint se tornar inacessível. A página de status é atualizada automaticamente, sem necessidade de comunicação manual.
2. Monitoramento de servidores e infraestrutura
É aqui que você rastreia a CPU, a RAM, a média de carga, o IO do disco, a taxa de transferência da rede, os registros do sistema e muito mais.
Por que isso é importante:
Muitas interrupções começam aqui: vazamentos de memória, discos cheios, limitação da CPU, problemas no kernel, exaustão de recursos.
Uma ferramenta de monitoramento de servidor em 2025 deve fornecer:
Coleta de métricas e painéis de controle
Alertas de anomalias e baseados em limites
Monitoramento de processos/serviços
Suporte para Linux e Windows
Coleta com ou sem agente
Ferramentas a serem consideradas:
Código aberto: Prometheus + Node Exporter, Zabbix, Grafana
SaaS: Datadog, New Relic, Xitoring para percepções em tempo real
Onde Monitoramento se encaixa:
O Xitoring instala um agente leve, monitora as métricas do Linux/Windows e usa a detecção de padrões de IA para avisá-lo sobre comportamentos incomuns de desempenho antes que causem tempo de inatividade.
3. Monitoramento do desempenho de aplicativos (APM)
Mesmo que os servidores pareçam saudáveis, seu aplicativo pode estar com problemas.
O APM fornece:
-
Rastreamentos de desempenho em nível de código
-
Detecção lenta de consultas ao endpoint/banco de dados
-
Vazamentos de memória e rastreamento de exceções
-
Quebras de latência de ponta a ponta
Se o seu aplicativo for escalonado rapidamente ou abranger microsserviços, o APM não é opcional - é uma questão de sobrevivência.
4. Registros - a fonte da verdade durante incidentes
Quando algo quebra, os engenheiros correm para os painéis... e depois, eventualmente para os registros.
O registro centralizado ajuda a responder:
-
O que aconteceu antes do acidente?
-
Qual serviço gerou a exceção?
-
A implantação introduziu um bug?
-
É um problema do sistema ou uma dependência externa?
Exemplos de pilha de registros:
-
ELK (Elasticsearch + Logstash + Kibana) - flexível, amplamente utilizado
-
Grafana Loki - mais barato e escalável
-
Graylog, Splunk - recursos de pesquisa empresarial
-
Registros nativos da nuvem - Registro do GCP, AWS CloudWatch
O registro de logs deve ser centralizado; o SSH nos servidores para acompanhar os logs é um problema de 2010.
5. Rastreamento distribuído - Entendendo o comportamento do sistema
Quando as solicitações passam por filas, serviços, balanceadores de carga e bancos de dados, o rastreamento é o seu mapa.
O rastreamento distribuído ajuda:
Visualizar caminhos de solicitação
Identificar gargalos nos microsserviços
Depurar tempos limite, novas tentativas e falhas
Padrões e ferramentas:
-
OpenTelemetry (padrão do setor)
-
Jaeger, Zipkin
-
Rastreamento de nuvem do AWS X-Ray / GCP
O rastreamento vincula APM + logs + métricas para revelar o quadro completo de um incidente.
6. Alerta e resposta a incidentes
O monitoramento é inútil sem alertas acionáveis. Ninguém quer fadiga de alerta, Mas o silêncio durante as interrupções é ainda pior.
Um fluxo de trabalho de alerta moderno deve:
-
Detectar
-
Notificar a pessoa certa
-
Fornecer contexto (painéis de controle, registros)
-
Acionar a correção automatizada quando possível
Canais de alerta:
-
Slack, Teams, E-mail
-
PagerDuty / OpsGenie
-
Telegram, SMS
-
Webhooks para automação
Xitoring Exemplo:
Quando a CPU fica acima de 90% por 10 minutos, o Xitoring envia alertas via Slack e Telegram, anexa métricas do sistema e pode acionar scripts automatizados (por exemplo, reiniciar um serviço ou dimensionar pods).
AIOps e automação - o divisor de águas de 2025
A evolução do monitoramento está passando de reativo para preditivo.
A IA pode ajudar a detectar:
-
Picos de tráfego incomuns
-
Vazamentos de memória lentos
-
Mudanças na latência antes do impacto sobre o usuário
-
Tendências de comportamento que levam ao fracasso
Plataformas como a Xitoring já integram Detecção de anomalias baseada em IA, habilitando:
Alerta automático antes de interrupções
🔹 sugestão de causas básicas
Gatilhos de recuperação automatizados
O futuro é infraestrutura de autocorreção.
Práticas recomendadas para equipes de DevOps em 2025
-
Alerta sobre os sintomas, não sobre o ruído
O pico de CPU sozinho não é um problema, mas um pico + aumento de latência sim. -
Usar páginas de status
Reduz a carga de suporte e aumenta a confiança dos clientes. -
Acompanhar as métricas de SLO/SLI
A confiabilidade é mensurável, e você pode melhorar apenas o que rastreia. -
Observe atentamente as implantações
A maioria dos incidentes são liberações humanas. -
O monitoramento não é um projeto. É uma cultura.
Considerações finais
Uma pilha de monitoramento perfeita não significa comprar a ferramenta mais cara ou projetar excessivamente seu pipeline de observabilidade. Significa combinar camadas que lhe dão visibilidade da solicitação do usuário → servidor → aplicativo → registros → causa raiz.
Se houver uma conclusão:
O monitoramento não deve lhe dizer que algo deu errado, mas sim que por que e como corrigi-lo rapidamente.
Quer você escolha uma pilha de código aberto, uma plataforma corporativa ou uma solução unificada como a Monitoramento que combina tempo de atividade + monitoramento de servidor com insights de IA, a chave é criar um sistema em que sua equipe confie e use diariamente.