إدارة متجر على الإنترنت أمر مثير - حتى اليوم الذي يتوقف فيه عن العمل.
ربما يكون ارتفاع مفاجئ في حركة المرور.
ربما يواجه مزود الاستضافة مشاكل.
ربما لم يسير تحديث المكون الإضافي بالطريقة التي كنت تأملها.
مهما كان السبب، فإن وقت التعطل مؤلم. في كل دقيقة لا يتوفر فيها المتجر، لا يمكن للعملاء التسوق، ويستمر إنفاق الإعلانات، ويتم التخلي عن عربات التسوق، وتتعرض السمعة التي عملت بجد لبنائها لضربة قوية.
إذا كنت من أصحاب متاجر Shopify أو WooCommerce، أو كنت تدير متجرًا مشفّرًا بالكامل، فإن مراقبة وقت التشغيل ليست مجرد تفاصيل تقنية - إنها حماية للإيرادات. في هذا الدليل، سنشرح بالتفصيل ما هي مراقبة وقت التشغيل، ولماذا هي مهمة، وكيف يمكن لأصحاب المتاجر (حتى غير التقنيين) تنفيذها بشكل صحيح.
أهمية مراقبة وقت التشغيل في التجارة الإلكترونية أكثر مما تعتقد
لنرسم صورة سريعة.
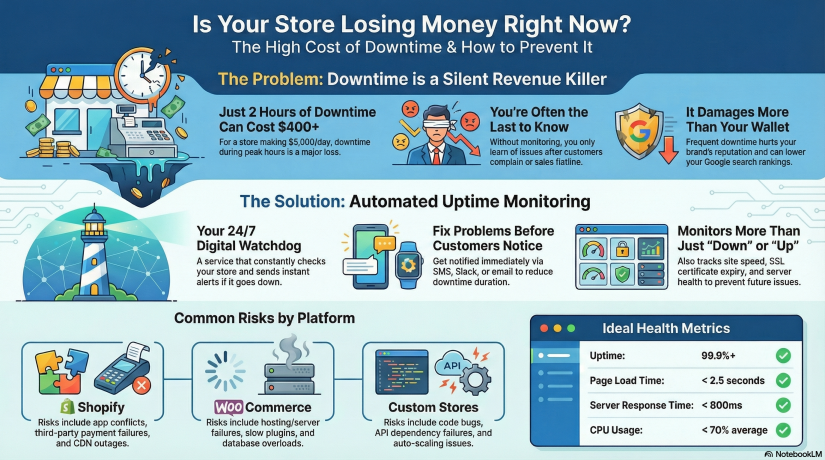
تخيل أن متجرك يصنع $5,000/يوم $5,000/يوم في المبيعات.
هذا عن $208/ساعة.
والآن تخيّل أن متجرك قد تعطّل لمجرد 2 ساعات خلال ذروة حركة المرور.
لقد فقدت للتو أكثر من $400 دون أن يعلموا حتى بحدوث ذلك - والزبائن الذين حاولوا الشراء منك قد لا يعودون مرة أخرى.
الآن قم بتوسيع نطاق ذلك خلال أحداث مثل
-
الجمعة البيضاء/إثنين الإنترنت
-
إطلاق المنتج
-
لحظة انتشار وسائل التواصل الاجتماعي
-
حملة إعلانية مدفوعة الأجر
-
انفجار التسويق عبر البريد الإلكتروني
-
ذروة موسم الأعياد
خلال الأحداث ذات الازدحام الشديد، يمكن أن تكلفك 30 دقيقة فقط من التوقف عن العمل الآلاف.
هذا هو سبب أهمية مراقبة وقت التشغيل. فهي تسمح لك بما يلي:
- اعرف على الفور عندما يتعطل متجرك - قبل أن يعرف عملاؤك
- تقليل وقت التوقف عن العمل مع استجابة أسرع للحوادث
- منع خسارة الإيرادات وحماية الثقة في العلامة التجارية
- تتبع الأداء بمرور الوقت باستخدام مقاييس مراقبة حقيقية
- بناء الموثوقية - مهم لتحسين محركات البحث وولاء العملاء
حتى أن جوجل يأخذ موثوقية الموقع في الحسبان عند الترتيب. لا تحب محركات البحث المواقع الإلكترونية غير الموثوقة - إذا وجدت برامج الزحف متجرك معطلاً بشكل متكرر، فإن تصنيفاتك يمكن السقوط.
ما هي مراقبة وقت التشغيل بالضبط؟
مراقبة وقت التشغيل هي خدمة تتحقق باستمرار من موقعك الإلكتروني للتأكد من إمكانية الوصول إليه وعمله. إذا تعطل شيء ما - تعطل الخادم، أو مشكلة في نظام أسماء النطاقات، أو تعطل بوابة الدفع - يتم إخطارك على الفور عبر البريد الإلكتروني أو الرسائل النصية القصيرة أو الدفع أو Slack أو Telegram أو قنوات أخرى.
فكر في مراقبة وقت التشغيل على أنها أمان على مدار الساعة طوال أيام الأسبوع لنشاطك التجاري عبر الإنترنت.
يفترض معظم مالكي المواقع الإلكترونية أن الاستضافة تتضمن المراقبة. لكنها لا تتضمن ذلك. تضمن شركات الاستضافة وقت تشغيل البنية التحتية فقط (إلى حد معين)، لكنها لا تنبهك بشكل فعال عند تعطل موقعك.
من خلال مراقبة وقت التشغيل، ستعرف:
✔ عندما يتعذر الوصول إلى موقعك الإلكتروني
✔ عندما تتباطأ أوقات الاستجابة
✔إذا أوشكت صلاحية SSL على الانتهاء
✔إذا كانت موارد الخادم محملة فوق طاقتها
✔ إذا تسببت الإضافات أو القوالب في فشل
بدون مراقبة، لن تعرف ذلك إلا بعد أن يشتكي العملاء - أو الأسوأ من ذلك، بعد التحقق من لوحة معلومات الإيرادات ورؤية أن هناك خطأ ما.
Shopify مقابل WooCommerce مقابل المتاجر المخصصة - متاجر مختلفة، ومخاطر مختلفة
دعنا نحلل المخاطر النموذجية التي تواجهها كل منصة.
متاجر Shopify
Shopify مستقر، ومستضاف، ويتعامل مع البنية التحتية - ولكن هذا لا يعني أن التعطل لا يمكن أن يحدث. تشمل المخاطر ما يلي:
Shopify يعتني بالاستضافة, يجب أن تهتم بالمراقبة.
متاجر WooCommerce (ووردبريس)
تمنحك WooCommerce المزيد من التحكم - ولكن مع التحكم تأتي المسؤولية. المخاطر:
-
وقت تعطل الاستضافة/الخادم
-
أداء بطيء من الإضافات الثقيلة
-
مشكلات التخزين المؤقت
-
شهادات SSL منتهية الصلاحية
-
هجمات الثغرات الأمنية أو البرمجيات الخبيثة
-
التحميل الزائد على قاعدة البيانات أثناء ذروة حركة المرور
يجب أن تراقب متاجر WooCommerce خادم + موقع إلكتروني + SSL + DNS + أداء DNS + موقع إلكتروني + أداء.
المتاجر المصممة حسب الطلب
العرف غير محدود - ولكن لا يمكن التنبؤ به أيضاً. تشمل المخاطر ما يلي:
-
الأخطاء أو مشكلات في النشر
-
إخفاقات تبعية واجهة برمجة التطبيقات (إخفاقات Stripe/PayPal تعطل عملية السداد)
-
عدم استقرار الاستضافة أو الخادم الافتراضي الخاص الافتراضي
-
التكوينات الخاطئة لذاكرة التخزين المؤقت
-
فشل التحجيم التلقائي
-
إلغاء وظائف Cron
-
أخطاء التعليمات البرمجية المخصصة
تحتاج المتاجر المخصصة إلى نهج المراقبة الأكثر شمولاً.
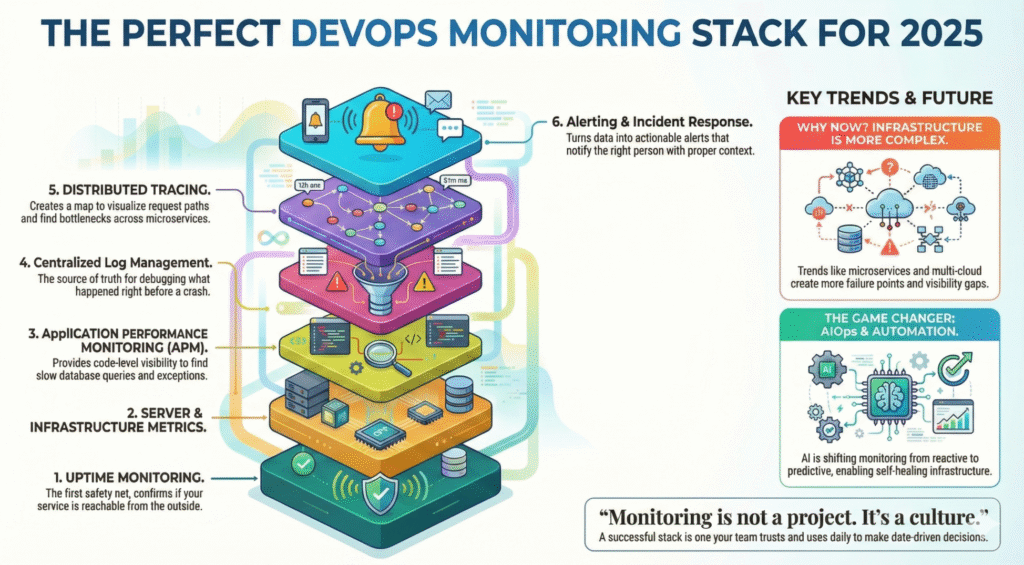
3 طبقات من المراقبة يحتاجها كل متجر
1. مراقبة وقت تشغيل الموقع الإلكتروني
تحقق من عنوان URL الخاص بك من مناطق متعددة كل X ثانية.
ستختبر المراقبة الجيدة أكثر من مجرد “هل يتم تحميل الصفحة؟ سوف تختبر:
إذا تعطل شيء ما، يتم تنبيهك في غضون دقائق.
2. مراقبة الخادم/الاستضافة (WooCommerce والمتاجر المخصصة)
تتبع مقاييس البنية التحتية الأعمق مثل:
| متري |
ما أهمية ذلك |
| استخدام وحدة المعالجة المركزية |
تتسبب الطفرات في بطء الخروج والتعطل |
| ذاكرة الوصول العشوائي |
ووردبريس + إضافات = متعطش للذاكرة |
| القرص |
قرص ممتلئ = تعطل الموقع على الفور |
| الشبكة |
فقدان الحزمة = الانقطاعات الإقليمية |
| متوسط التحميل |
التنبؤ بتدهور الأداء |
هذا هو المكان الذي توجد فيه منصات مثل زيتورينج تصبح مفيدة.
يمكنك مراقبة كل من وقت التشغيل + صحة الخادم في مكان واحد, ، مما يعني أنك تكتشف المشاكل مبكراً - قبل أن يتعطل الموقع.
3. مراقبة SSL و DNS والنطاق
أشياء صغيرة ينساها أصحاب المتاجر، ولكنها تحطم المواقع على الفور:
-
انتهاء صلاحية SSL = تحظر المتصفحات الزوار
-
سوء تهيئة DNS = يتعذر الوصول إلى الموقع
-
انتهاء صلاحية النطاق = العمل دون اتصال بالإنترنت بين عشية وضحاها
قد يكون متجرك مثاليًا - ولكن SSL منتهي الصلاحية = موقع متوقف عن العمل.
المراقبة تمنع ذلك.
كيفية عمل أدوات مراقبة وقت التشغيل (تفصيل بسيط)
إليك ما يحدث داخل نظام مراقبة وقت التشغيل:
-
يمكنك إضافة عنوان URL لمتجرك إلى لوحة التحكم
-
تقوم الشاشة باختبار الأصوات في موقعك من مناطق عالمية مختلفة كل بضع ثوانٍ/دقائق
-
إذا فشل (مهلة/500 خطأ/خطأ 500/500/بطء الاستجابة/مشكلة في SSL)، يتحقق موقع ثانٍ
-
بمجرد التأكيد، يتم إرسال الإشعارات على الفور
-
تقرير مفصل يسجل المدة والسبب ووقت الحل
وهذا يعني أنك لست مضطرًا إلى التحقق من موقعك يدويًا باستمرار، فالنظام يراقبه نيابةً عنك.
إعداد المراقبة لمتجرك - خطوة بخطوة
حتى لو لم تكن خبيراً تقنياً، فإن الإعداد بسيط.
لمتاجر Shopify
لا يلزم إعداد خادم - فقط راقب عنوان URL الأمامي الخاص بك.
-
إضافة نطاق متجرك
-
اختر قنوات التنبيه (البريد الإلكتروني/الرسائل النصية القصيرة/Telegram/سلاك)
-
تمكين مراقبة وقت الاستجابة
-
إضافة مراقبة انتهاء صلاحية SSL
-
تعيين فواصل زمنية للتحقق (يوصى بـ 1-5 دقائق)
خطوة متقدمة اختيارية: مراقبة عناوين URL محددة (الدفع، والإضافة إلى عربة التسوق، وصفحة الدفع)
لمتاجر WooCommerce
يجب أن تراقب موقع إلكتروني + خادم + قاعدة بيانات.
-
إضافة نطاق متجرك للتحقق من وقت التشغيل
-
تثبيت وكيل الخادم (إذا كنت تستخدم استضافة VPS)
-
مراقبة استخدام الموارد (وحدة المعالجة المركزية/ذاكرة التخزين العشوائي/القرص)
-
إضافة مراقب قاعدة بيانات MySQL
-
تمكين تنبيه تحديث المكون الإضافي/القالب
-
مراقبة نقاط نهاية واجهة برمجة تطبيقات REST API
-
إضافة مراقبة SSL و DNS
المكافأة: أنشئ صفحة الحالة لإظهار سجل وقت التشغيل علنًا.
للمتاجر المخصصة
إنشاء إعداد متعدد الطبقات:
-
مراقبة وقت تشغيل HTTP
-
مراقبة بينغ
-
مراقبة المنافذ (80/443/DB/DB/Redis)
-
سجلات موارد الخادم
-
مراقبة نقطة نهاية واجهة برمجة التطبيقات (API)
-
مراقبة مهام/قائمة مهام/قائمة انتظار Cron
-
الاختبارات التركيبية للتدفقات الرئيسية
مثال اختبار بسيط:
هل يمكن للمستخدم إضافة منتج ← الدفع ← إتمام عملية الدفع؟
يمكن للمراقبة التركيبية محاكاة ذلك تلقائياً.
كيف يمكن لـ Xitoring المساعدة (مثال متكامل بشكل طبيعي)
على الرغم من أن العديد من الأدوات يمكنها مراقبة المواقع الإلكترونية، إلا أن متاجر التجارة الإلكترونية تستفيد أكثر من غيرها من منصة تدعم كل من وقت التشغيل + مراقبة الخادم + التنبيهات + صفحات الحالة - كل ذلك معاً.
يسمح لك Xitoring بما يلي:
-
إضافة فحوصات وقت التشغيل لمتاجر Shopify/WooCommerce/المتاجر المخصصة
-
مراقبة وحدة المعالجة المركزية، وذاكرة الوصول العشوائي، وذاكرة الوصول العشوائي، والقرص، وشبكة الخوادم الخاصة بك
-
إنشاء عام أو خاص صفحات الحالة
-
تلقي تنبيهات عبر البريد الإلكتروني، والرسائل النصية القصيرة، وSlack، وTelegram والمزيد
-
اكتشاف الحالات الشاذة باستخدام رؤى مدعومة بالذكاء الاصطناعي
-
تجنب وقت التوقف عن العمل مع التنبيهات التلقائية قبل حدوث العطل
وبدلاً من التنقل بين أدوات متعددة، يمكنك الحصول على نظرة عامة شاملة عن صحة متجرك.
ليس ترويجيًا - مجرد مثال واقعي لكيفية تقليل أصحاب المتاجر من الضغط الناتج عن التوقف عن العمل.
سيناريوهات التعطل في العالم الحقيقي وكيف تنقذك المراقبة
السيناريو 1 - ارتفاع حركة المرور يعطل WooCommerce
الجمعة الأسود + الاستضافة المشتركة = تحميل زائد على الخادم.
بدون مراقبة:
لا تلاحظ ذلك إلا بعد رسائل البريد الإلكتروني الغاضبة أو ثبات المبيعات.
مع المراقبة:
تنبيه ارتفاع وحدة المعالجة المركزية/ذاكرة التخزين العشوائي → زيادة طاقة الخادم → تجنب التعطل.
السيناريو 2 - تطبيق Shopify يكسر تطبيق Shopify عملية الدفع
يتعارض تطبيق زيادة المبيعات المثبت حديثاً مع القالب الخاص بك.
تلتقط المراقبة قفزة في أوقات الاستجابة + حالات فشل الخروج. تستعيد النسخ الاحتياطي بسرعة - لا توجد خسارة كبيرة في الإيرادات.
السيناريو 3 - انتهاء صلاحية SSL الموقع المخصص
تحذيرات المتصفح تقتل التحويلات. يمكن منعها بسهولة.
تنبهك المراقبة قبل أيام أو أسابيع من حدوثها. تجنب الأزمات.
مؤشرات الأداء الرئيسية التي يجب على أصحاب المتاجر تتبعها
أن تظل مستقرًا وسريعًا:
| مؤشر الأداء الرئيسي |
الهدف المثالي |
| وقت التشغيل |
99.9%+ 99.9%+ كحد أدنى |
| وقت تحميل الصفحة |
< أقل من 2.5 ثانية |
| وقت الاستجابة |
<800 مللي ثانية في المتوسط |
| انتهاء صلاحية SSL |
> 30 يومًا قبل التجديد |
| استخدام وحدة المعالجة المركزية |
<70% متوسط الحمل 70% |
| معدل الخطأ |
أقرب ما يكون إلى 0% قدر الإمكان |
حتى المبتدئين يمكنهم تتبعها.
أفضل الممارسات للحفاظ على متجرك متصلاً بالإنترنت وسريعًا
- تشغيل المراقبة على مدار الساعة طوال أيام الأسبوع - لا تعتمد على الفحوصات اليدوية
- اختبار وقت التشغيل من مواقع عالمية متعددة
- مراقبة تدفقات المستخدمين المهمة، وليس فقط الصفحة الرئيسية
- استخدم شبكة CDN والتخزين المؤقت لشبكة CDN للحصول على أوقات استجابة أسرع
- راقب دائمًا SSL و DNS وانتهاء صلاحية النطاق
- الحفاظ على تحديث الإضافات/المواضيع وتأمينها
- ضبط التنبيه على قنوات متعددة (البريد الإلكتروني + الرسائل النصية القصيرة/Telegram)
أداة المراقبة هي حزام الأمان الخاص بك. تأمل ألا تحتاج إليها أبداً، ولكن عندما تحتاج إليها فإنها تنقذك.
في النهاية
سواء كان متجرك على الإنترنت يعمل على Shopify أو WooCommerce أو منصة مخصصة، فإن مراقبة وقت التشغيل هي واحدة من أبسط الخطوات وأذكىها لحماية الإيرادات. سيحدث التعطل في نهاية المطاف - ما يهم هو مدى سرعة معرفتك به وسرعة إصلاحه.
المراقبة ليست مجرد بنية تحتية تقنية - حماية الأعمال.
إنه الحفاظ على السمعة.
إنه تأمين على الإيرادات.
ولحسن الحظ، أصبح إعداده اليوم أسهل من أي وقت مضى.
استغرق 10 دقائق، وأضف إعداد المراقبة، وقم بتوصيل التنبيهات - ستكون ممتنًا في المستقبل.