
Moderne Infrastrukturen sind verteilt, schnelllebig und zunehmend komplex. Von DevOps-Ingenieuren wird erwartet, dass sie schneller bereitstellen, Probleme früher erkennen, Reaktionen automatisieren und sicherstellen, dass die Systeme zuverlässig bleiben - und das alles, während die Cloud-Kosten im Rahmen bleiben. Überwachung ist nicht länger ein “Nice-to-have”-Tool, das im Hintergrund läuft. Im Jahr 2025 ist ein hervorragender Monitoring-Stack eine erstklassige Komponente Ihrer Infrastruktur.
Aber hier ist die Wahrheit:
Die meisten Unternehmen verfügen nicht über eine einheitliche Überwachungsstrategie, sondern über ein Tool-Chaos.
Fünf Dashboards, drei Warnsysteme, zwei Clouds, und trotzdem bemerkt niemand die CPU-Spitze, bis der Kunde ein Support-Ticket eröffnet.
Dieser Artikel hilft Ihnen beim Aufbau einer vollständiger Überwachungsstapel Schritt für Schritt - einer, der DevOps-Teams hilft Probleme zu erkennen, zu diagnostizieren und darauf zu reagieren, bevor die Benutzer sie überhaupt bemerken.
Was wir behandeln werden
-
Warum Überwachung im Jahr 2025 wichtiger ist als je zuvor
-
Die 6 Säulen eines perfekten Monitoring-Stacks
-
Am besten geeignete Tools (Open-Source + SaaS) für jede Ebene
-
Automatisierung und AIOps für eine schnellere Reaktion auf Vorfälle
-
Reale Beispiel-Workflows mit Xitoring
-
Bewährte Verfahren für den Aufbau einer zukunftssicheren Beobachtungskultur
Schnappen Sie sich Ihren Kaffee - lassen Sie uns das perfekte Überwachungsökosystem entwerfen.
Warum Überwachung im Jahr 2025 wichtiger ist als je zuvor
Die Trends bei der Infrastruktur verschieben sich:
| Trend | Ergebnis |
|---|---|
| Microservices > Monolithen | Mehr verteilte Fehlerpunkte |
| Multi-Cloud-Einführung | Stärkere Sichtbarkeit und Korrelation der Metriken |
| Entfernte Teams und globale Systeme | 24/7-Überwachung und Automatisierung erforderlich |
| KI-gestützte Benutzer und Arbeitslasten | Höhere Leistungsempfindlichkeit |
| Uptime-Erwartungen in der Nähe von 100% | Unfälle kosten mehr als je zuvor |
Selbst kleine Ausfälle schmerzen. Ein paar Minuten Ausfallzeit beim Checkout können einen eCommerce-Shop Tausende kosten. Eine Leistungsverschlechterung in einer SaaS-Anwendung wirkt sich direkt auf die Abwanderung aus. Und bei Diensten mit SLAs bedeuten Ausfallzeiten Geld aus der Tasche.
Bei der Überwachung geht es nicht mehr nur um die Betriebszeit - es geht um:
✔ Leistungsoptimierung
✔ Schutz der Benutzererfahrung
✔ Schnelle Reaktion auf Vorfälle
✔ Vorausschauende Fehlererkennung
✔ Datengesteuerte technische Entscheidungen
Ihr Monitoring-Stack ist Ihr Frühwarnsystem, Ihr forensisches Labor und Ihr Betriebsassistent - alles in einem.
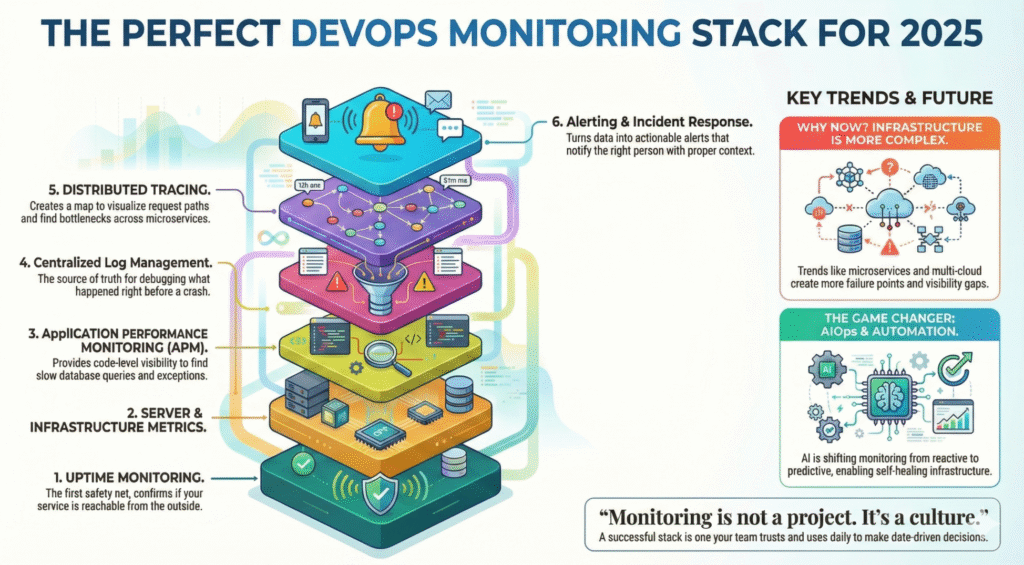
Die 6 Säulen eines perfekten Überwachungsstapels
Ein ausgereiftes Überwachungssystem umfasst mehrere Ebenen, die zusammenarbeiten:
-
Überwachung der Betriebszeit und Statusüberprüfung
-
Server & Infrastruktur Metriken
-
Überwachung der Anwendungsleistung (APM)
-
Protokolle und zentralisierte Protokollverwaltung
-
Verfolgung und verteilte Beobachtbarkeit
-
Alarmierung, Reaktion auf Zwischenfälle und Automatisierung
Die meisten Fehler treten nicht isoliert auf - ein guter Stack korreliert daher Metriken über alle Schichten hinweg.
Schauen wir uns diese nacheinander an.
1. Überwachung der Betriebszeit - das erste Sicherheitsnetz
Uptime-Checks bestätigen, ob Ihr Dienst von außen erreichbar ist. Dies ist entscheidend für:
-
Verfolgung der Verfügbarkeit
-
SLA-Berichterstattung
-
Erkennung von DNS/SSL/Netzwerkproblemen
-
Frühzeitige Erkennung von Ausfällen, bevor die Kunden sie bemerken
Ihr Betriebszeitmonitor sollte:
-
Ping von mehrere globale Standorte
-
Unterstützung von HTTP, TCP, ICMP, DNS und Portprüfungen
-
Sofortige Warnung bei Beginn der Ausfallzeit
-
Bereitstellung von öffentlichen/privaten Statusseiten
-
Historische Betriebszeiten und Vorfälle verfolgen
Gute Werkzeuge:
🔹 Xitoring (Uptime + Serverüberwachung in einer Plattform)
🔹 UptimeRobot, Pingdom, BetterUptime
🔹 DIY mit Prometheus + Blackbox Exporter
Beispiel-Workflow mit Xitoring:
Sie konfigurieren Betriebszeitprüfungen für APIs und Landing Pages. Xitoring überwacht die globalen Knotenpunkte jede Minute und gibt sofort eine Warnung über Slack/Telegram aus, wenn die Latenzzeit ansteigt oder der Endpunkt nicht mehr erreichbar ist. Die Statusseite wird automatisch aktualisiert - keine manuelle Kommunikation erforderlich.
2. Server- und Infrastrukturüberwachung
Hier können Sie CPU, RAM, durchschnittliche Last, Festplatten-IO, Netzwerkdurchsatz, Systemprotokolle und vieles mehr verfolgen.
Warum das wichtig ist:
Viele Ausfälle beginnen hier - Speicherlecks, volle Festplatten, CPU-Drosselung, Kernel-Probleme, Ressourcenerschöpfung.
Ein Server-Überwachungstool im Jahr 2025 sollte dies ermöglichen:
✔ Metrische Sammlung & Dashboards
✔ Schwellenwert- und Anomalie-Warnungen
✔ Prozess-/Dienstüberwachung
✔ Unterstützung von Linux und Windows
✔ Agent oder agentenlose Sammlung
Zu berücksichtigende Tools:
Open-Source: Prometheus + Node Exporter, Zabbix, Grafana
SaaS: Datadog, New Relic, Xitoring für Einblicke in Echtzeit
Wo Xitoring passt:
Xitoring installiert einen leichtgewichtigen Agenten, überwacht Linux-/Windows-Metriken und verwendet AI-Mustererkennung, um Sie vor ungewöhnlichem Leistungsverhalten zu warnen, bevor es zu Ausfallzeiten kommt.
3. Überwachung der Anwendungsleistung (APM)
Auch wenn die Server gesund aussehen, Ihre Anwendung könnte Probleme haben.
APM bietet:
-
Leistungsspuren auf Code-Ebene
-
Langsame Erkennung von Endpunkten/Datenbankabfragen
-
Speicherlecks und Ausnahmeverfolgung
-
Aufschlüsselung der End-to-End-Latenz
Wenn Ihre Anwendung schnell skaliert oder Mikrodienste umfasst, ist APM nicht optional - es ist überlebenswichtig.
4. Protokolle - Die Quelle der Wahrheit bei Zwischenfällen
Wenn etwas kaputt geht, rennen die Ingenieure zu den Armaturenbrettern... und dann schließlich zu Protokollen.
Die zentrale Protokollierung hilft bei der Beantwortung:
-
Was geschah vor dem Absturz?
-
Welcher Dienst hat die Ausnahme ausgelöst?
-
Wurde durch die Bereitstellung ein Fehler eingeführt?
-
Handelt es sich um ein Systemproblem oder eine externe Abhängigkeit?
Log Stack Beispiele:
-
ELK (Elasticsearch + Logstash + Kibana) - flexibel, weit verbreitet
-
Grafana Loki - billiger & skalierbar
-
Graylog, Splunk - Suchfunktionen für Unternehmen
-
Native Cloud-Protokolle - GCP-Protokollierung, AWS CloudWatch
Die Protokollierung muss zentralisiert werden; SSH-ing in Server, um Protokolle zu verfolgen, ist ein Problem für 2010.
5. Verteiltes Tracing - Verstehen des Systemverhaltens
Wenn Anfragen Warteschlangen, Dienste, Load Balancer und Datenbanken durchlaufen - Tracing ist Ihre Karte.
Verteiltes Tracing hilft:
✔ Anfragepfade visualisieren
✔ Identifizierung von Engpässen bei Microservices
✔ Debuggen von Timeouts, Wiederholungen, Fehlschlägen
Normen und Werkzeuge:
-
OpenTelemetry (Industriestandard)
-
Jaeger, Zipkin
-
AWS X-Ray / GCP Cloud Trace
Tracing verknüpft APM + Protokolle + Metriken, um ein vollständiges Bild eines Vorfalls zu erhalten.
6. Alarmierung und Reaktion auf Vorfälle
Die Überwachung ist ohne umsetzbare Warnungen nutzlos. Keiner will geistige Müdigkeit, aber das Schweigen während der Ausfälle ist noch schlimmer.
Ein moderner Alarmierungsworkflow sollte:
-
Erkennen Sie
-
Benachrichtigen Sie die richtige Person
-
Bereitstellung von Kontext (Dashboards, Protokolle)
-
Automatisierte Abhilfemaßnahmen auslösen, wenn möglich
Alert-Kanäle:
-
Slack, Teams, E-Mail
-
PagerDuty / OpsGenie
-
Telegram, SMS
-
Webhooks für die Automatisierung
Xitoring Beispiel:
Wenn die CPU 10 Minuten lang über 90% bleibt, sendet Xitoring Warnungen über Slack und Telegram, fügt Systemmetriken hinzu und kann automatisierte Skripte auslösen (z. B. einen Dienst neu starten oder Pods skalieren).
AIOps und Automatisierung - der Game Changer 2025
Die Entwicklung der Überwachung geht von reaktiv zu prädiktiv.
KI kann bei der Erkennung helfen:
-
Ungewöhnliche Verkehrsspitzen
-
Langsame Speicherlecks
-
Änderungen der Latenzzeit vor den Auswirkungen auf den Nutzer
-
Verhaltenstendenzen, die zum Scheitern führen
Plattformen wie Xitoring integrieren bereits AI-basierte Erkennung von Anomalien, Freigabe:
🔹 Automatische Benachrichtigung vor Ausfällen
🔹 Vorschlag für die Grundursachen
🔹 automatische Auslöser für die Wiederherstellung
Die Zukunft ist selbstheilende Infrastruktur.
Best Practices für DevOps-Teams im Jahr 2025
-
Auf Symptome aufmerksam machen, nicht auf Lärm
Ein CPU-Spike allein ist kein Problem - ein Spike + Latenzerhöhung schon. -
Statusseiten verwenden
Reduziert den Supportaufwand und schafft Vertrauen bei den Kunden. -
SLO/SLI-Metriken verfolgen
Zuverlässigkeit ist messbar, und Sie können nur das verbessern, was Sie verfolgen. -
Beobachten Sie die Einsätze genau
Die meisten Vorfälle werden durch Menschen ausgelöst. -
Überwachung ist kein Projekt. Es ist eine Kultur.
Abschließende Überlegungen
Ein perfekter Überwachungsstack bedeutet nicht, dass Sie das teuerste Tool kaufen oder Ihre Überwachungspipeline übertechnisieren müssen. Es bedeutet, Schichten zu kombinieren, die Ihnen einen Einblick in die Bereiche Benutzeranforderung → Server → Anwendung → Protokolle → Grundursache geben.
Wenn es etwas gibt, das man mitnehmen kann:
Die Überwachung sollte Ihnen nicht sagen, dass etwas schief gelaufen ist - sie sollte Ihnen sagen warum und wie man sie schnell beheben kann.
Ob Sie sich für einen Open-Source-Stack, eine Unternehmensplattform oder eine einheitliche Lösung wie Xitoring das Betriebszeit und Serverüberwachung mit KI-Einsichten kombiniert, liegt der Schlüssel im Aufbau eines Systems, dem Ihr Team vertraut und das es täglich nutzt.