Menjalankan toko online memang mengasyikkan - sampai hari ketika toko tersebut offline.
Mungkin karena lonjakan lalu lintas yang tiba-tiba.
Mungkin penyedia hosting mengalami masalah.
Mungkin pembaruan plugin tidak berjalan seperti yang Anda harapkan.
Apa pun alasannya, waktu henti itu menyakitkan. Setiap menit toko tidak tersedia, pelanggan tidak dapat berbelanja, iklan terus berjalan, troli ditinggalkan, dan reputasi yang telah Anda bangun dengan susah payah menjadi rusak.
Jika Anda adalah pemilik Shopify atau WooCommerce, atau Anda menjalankan toko yang sepenuhnya dikodekan secara khusus, pemantauan waktu aktif bukan hanya detail teknis - ini adalah perlindungan pendapatan. Dalam panduan ini, kami akan menguraikan apa itu pemantauan waktu aktif, mengapa hal itu penting, dan bagaimana pemilik toko (bahkan yang non-teknis) dapat mengimplementasikannya dengan benar.
Mengapa Pemantauan Uptime Lebih Penting untuk eCommerce Daripada yang Anda Pikirkan
Mari kita lukiskan gambaran singkatnya.
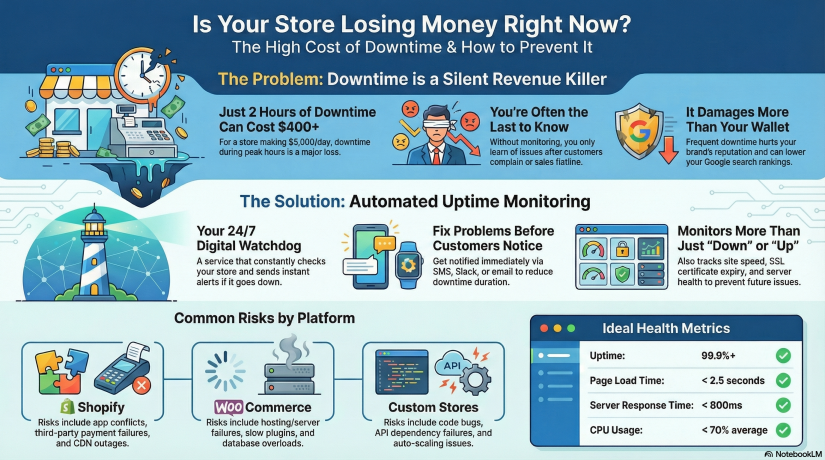
Bayangkan toko Anda membuat $5.000/hari dalam penjualan.
Itu tentang $208/jam.
Sekarang bayangkan toko Anda turun hanya untuk 2 jam selama lalu lintas puncak.
Anda baru saja kehilangan lebih dari $400 tanpa mengetahui hal itu terjadi - dan pelanggan yang mencoba membeli dari Anda mungkin tidak akan kembali lagi.
Sekarang tingkatkan skala itu selama acara seperti:
Selama acara dengan lalu lintas tinggi, waktu henti selama 30 menit saja bisa merugikan ribuan orang.
Inilah sebabnya mengapa pemantauan waktu kerja sangat penting. Ini memungkinkan Anda untuk melakukannya:
- Ketahui secara instan ketika toko Anda sedang down - sebelum pelanggan Anda mengetahuinya
- Mengurangi waktu henti dengan respons insiden yang lebih cepat
- Mencegah kehilangan pendapatan dan melindungi kepercayaan merek
- Melacak kinerja dari waktu ke waktu dengan metrik pemantauan nyata
- Membangun keandalan - penting untuk SEO & loyalitas pelanggan
Google bahkan mempertimbangkan keandalan situs untuk menentukan peringkat. Mesin pencari tidak menyukai situs web yang tidak dapat diandalkan - jika perayap berulang kali menemukan toko Anda turun, peringkat Anda bisa drop.
Apa Sebenarnya Pemantauan Waktu Kerja Itu?
Pemantauan waktu aktif adalah layanan yang secara konstan memeriksa situs web Anda untuk memastikannya dapat dijangkau dan berfungsi. Jika ada sesuatu yang gagal - server macet, masalah DNS, pemadaman gateway pembayaran - Anda akan segera diberitahu melalui email, SMS, push, Slack, Telegram, atau saluran lainnya.
Pikirkan pemantauan waktu kerja sebagai Keamanan 24/7 untuk bisnis online Anda.
Sebagian besar pemilik situs web berasumsi bahwa hosting sudah termasuk pemantauan. Ternyata tidak. Perusahaan hosting hanya menjamin waktu aktif infrastruktur (hingga batas tertentu), tetapi mereka tidak secara aktif memberi tahu Anda ketika situs Anda down.
Dengan pemantauan waktu kerja, Anda akan tahu:
✔ Ketika situs web Anda tidak dapat dijangkau
✔ Ketika waktu respons melambat
✔ Jika SSL akan segera kedaluwarsa
✔ Jika sumber daya server kelebihan beban
✔ Jika plugin atau tema menyebabkan kegagalan
Tanpa pemantauan, Anda hanya akan tahu setelah pelanggan mengeluh - atau lebih buruk lagi, setelah memeriksa dasbor pendapatan Anda dan melihat ada yang tidak beres.
Shopify vs WooCommerce vs Toko Khusus - Toko yang Berbeda, Risiko yang Berbeda
Mari kita uraikan risiko umum yang dihadapi setiap platform.
Toko Shopify
Shopify stabil, di-host, dan menangani infrastruktur - tetapi bukan berarti waktu henti tidak bisa terjadi. Risiko meliputi:
-
Konflik tema atau aplikasi
-
Pemadaman CDN
-
Waktu henti regional
-
Kegagalan pembayaran pihak ketiga
-
Kesalahan konfigurasi DNS
-
Toko dinonaktifkan karena masalah penagihan atau kebijakan
Shopify menangani hosting, Anda harus berhati-hati dalam melakukan pemantauan.
Toko WooCommerce (WordPress)
WooCommerce memberi Anda lebih banyak kontrol - tetapi dengan kontrol juga ada tanggung jawab. Risiko:
-
Waktu henti hosting/server
-
Performa yang lambat dari plugin yang berat
-
Masalah caching
-
Sertifikat SSL yang kedaluwarsa
-
Kerentanan atau serangan malware
-
Kelebihan beban basis data selama puncak lalu lintas
Toko WooCommerce harus memantau server + situs web + SSL + DNS + kinerja.
Toko yang Dibangun Khusus
Kebiasaan tidak terbatas - tetapi juga tidak dapat diprediksi. Risiko termasuk:
-
Bug atau masalah penerapan
-
Kegagalan ketergantungan API (kegagalan Stripe/PayPal memutus pembayaran)
-
Ketidakstabilan hosting atau VPS
-
Kesalahan konfigurasi cache
-
Kegagalan penskalaan otomatis
-
Pekerjaan Cron melanggar
-
Kesalahan kode khusus
Toko khusus membutuhkan pendekatan pemantauan yang paling komprehensif.
3 Lapisan Pemantauan yang Dibutuhkan Setiap Toko
1. Pemantauan Waktu Aktif Situs Web
Memeriksa URL Anda dari berbagai wilayah setiap X detik.
Pemantauan yang baik akan menguji lebih dari sekadar “apakah halaman dimuat?” Ini akan menguji:
Jika ada sesuatu yang rusak, Anda akan diberi tahu dalam beberapa menit.
2. Pemantauan Server/Hosting (WooCommerce & Toko Kustom)
Melacak metrik infrastruktur yang lebih dalam seperti:
| Metrik |
Mengapa ini penting |
| Penggunaan CPU |
Lonjakan menyebabkan checkout lambat & crash |
| RAM |
WordPress + plugin = haus memori |
| Disk |
Disk penuh = situs langsung rusak |
| Jaringan |
Kehilangan paket = pemadaman regional |
| Rata-rata beban |
Memprediksi penurunan kinerja |
Di sinilah platform seperti Xitoring menjadi berguna.
Anda dapat memantau keduanya waktu aktif + kesehatan server di satu tempat, yang berarti Anda menangkap masalah lebih awal - sebelum situs down.
3. Pemantauan SSL, DNS & Domain
Hal-hal kecil yang dilupakan oleh pemilik toko, tetapi langsung merusak situs:
-
Kedaluwarsa SSL = browser memblokir pengunjung
-
Kesalahan konfigurasi DNS = situs tidak dapat dijangkau
-
Kedaluwarsa domain = bisnis offline dalam semalam
Toko Anda mungkin sempurna - tetapi SSL yang kedaluwarsa = situs web mati.
Pemantauan mencegah hal ini.
Cara Kerja Alat Pemantauan Waktu Kerja (Perincian Sederhana)
Inilah yang terjadi di dalam sistem pemantauan waktu kerja:
-
Anda menambahkan URL toko Anda ke dasbor
-
Monitor melakukan ping ke situs Anda dari berbagai wilayah global setiap beberapa detik/menit
-
Jika gagal (batas waktu habis/500 kesalahan/respons lambat/masalah SSL), lokasi kedua akan memverifikasi
-
Setelah dikonfirmasi, notifikasi akan langsung dikirim
-
Laporan terperinci mencatat durasi, penyebab & waktu penyelesaian
Ini berarti Anda tidak perlu terus-menerus memeriksa situs Anda secara manual - sistem mengawasinya untuk Anda.
Menyiapkan Pemantauan untuk Toko Anda - Langkah demi Langkah
Bahkan, jika Anda bukan seorang yang ahli teknis, penyiapannya pun sederhana.
Untuk Toko Shopify
Tidak perlu pengaturan server - cukup pantau URL depan Anda.
-
Tambahkan domain toko Anda
-
Pilih saluran peringatan (email/SMS/Telegram/Slack)
-
Mengaktifkan pemantauan waktu respons
-
Tambahkan pemantauan kedaluwarsa SSL
-
Tetapkan interval pemeriksaan (disarankan 1-5 menit)
Langkah lanjutan opsional: pantau URL tertentu (checkout, tambahkan ke keranjang, halaman pembayaran)
Untuk Toko WooCommerce
Anda harus memantau situs web + server + basis data.
-
Tambahkan domain toko Anda untuk pemeriksaan waktu aktif
-
Instal agen server (jika menggunakan hosting VPS)
-
Memantau penggunaan sumber daya (CPU/RAM/Disk)
-
Menambahkan monitor basis data MySQL
-
Mengaktifkan peringatan pembaruan plugin/tema
-
Memantau titik akhir REST API
-
Tambahkan pemantauan SSL & DNS
Bonus: buat sebuah halaman status untuk menampilkan riwayat waktu aktif secara publik.
Untuk Toko Khusus
Buat pengaturan multi-lapisan:
-
Pemantauan waktu aktif HTTP
-
Pemantauan ping
-
Pemantauan pelabuhan (80/443/DB/Redis)
-
Log sumber daya server
-
Pemantauan titik akhir API
-
Pemantauan pekerjaan/antrean cron
-
Tes sintetis untuk aliran kunci
Contoh pengujian sederhana:
Dapatkah pengguna menambahkan produk → checkout → menyelesaikan pembayaran?
Pemantauan sintetis dapat mensimulasikannya secara otomatis.
Bagaimana Xitoring Dapat Membantu (Contoh Terintegrasi Secara Alami)
Meskipun banyak alat yang dapat memonitor situs web, toko eCommerce paling diuntungkan dari platform yang mendukung waktu aktif + pemantauan server + peringatan + halaman status - semuanya bersama-sama.
Xitoring memungkinkan Anda untuk melakukannya:
-
Tambahkan pemeriksaan waktu aktif untuk Shopify/WooCommerce/Toko khusus
-
Memantau CPU, RAM, Disk, Jaringan server Anda
-
Buat publik atau pribadi halaman status
-
Menerima peringatan melalui email, SMS, Slack, Telegram & lainnya
-
Mendeteksi anomali menggunakan wawasan yang didukung AI
-
Hindari waktu henti dengan peringatan otomatis sebelum kegagalan terjadi
Alih-alih menyulap beberapa alat, Anda mendapatkan gambaran umum menyeluruh tentang kesehatan toko Anda.
Bukan promosi - hanya contoh realistis tentang bagaimana pemilik toko mengurangi stres akibat downtime.
Skenario Waktu Henti Dunia Nyata & Bagaimana Pemantauan Menyelamatkan Anda
Skenario 1 - Lonjakan lalu lintas membuat WooCommerce macet
Black Friday + shared hosting = server kelebihan beban.
Tanpa pemantauan:
Anda baru menyadarinya setelah ada email yang berisi kemarahan atau garis datar penjualan.
Dengan pemantauan:
Peringatan lonjakan CPU/RAM → meningkatkan daya server → waktu henti dapat dihindari.
Skenario 2 - Aplikasi Shopify merusak checkout
Aplikasi upsell yang baru diinstal bertentangan dengan tema Anda.
Pemantauan menangkap lonjakan waktu respons + kegagalan pembayaran. Anda memulihkan cadangan dengan cepat - tidak ada kehilangan pendapatan yang besar.
Skenario 3 - SSL situs khusus kedaluwarsa
Peringatan peramban mematikan konversi. Mudah dicegah.
Pemantauan memberi tahu Anda beberapa hari atau beberapa minggu sebelumnya. Krisis dapat dihindari.
KPI yang Harus Dilacak Pemilik Toko
Agar tetap stabil dan cepat:
| KPI |
Target Ideal |
| Waktu kerja |
Minimum 99,9% + minimum |
| Waktu muat halaman |
<2,5 detik |
| Waktu respons |
<Rata-rata 800ms |
| Kedaluwarsa SSL |
> 30 hari sebelum perpanjangan |
| Penggunaan CPU |
<Beban rata-rata 70% |
| Tingkat kesalahan |
Sedekat mungkin dengan 0% |
Bahkan para pemula pun bisa melacaknya.
Praktik Terbaik untuk Menjaga Toko Anda Tetap Online & Cepat
- Jalankan pemantauan 24/7 - jangan mengandalkan pemeriksaan manual
- Menguji waktu kerja dari beberapa lokasi global
- Pantau arus pengguna yang penting, bukan hanya beranda
- Gunakan CDN & caching untuk waktu respons yang lebih cepat
- Selalu pantau kedaluwarsa SSL, DNS & domain
- Selalu perbarui dan amankan plugin/tema
- Mengatur peringatan ke beberapa saluran (email + SMS/Telegram)
Alat pemantauan adalah sabuk pengaman Anda. Anda berharap tidak akan pernah membutuhkannya - tetapi ketika Anda membutuhkannya, alat ini akan menyelamatkan Anda.
Pada akhirnya!
Baik toko online Anda berjalan di Shopify, WooCommerce, atau platform khusus, pemantauan waktu aktif adalah salah satu langkah paling sederhana dan cerdas untuk melindungi pendapatan. Downtime pada akhirnya akan terjadi - yang penting adalah seberapa cepat Anda mengetahuinya dan seberapa cepat Anda memperbaikinya.
Pemantauan bukan hanya infrastruktur teknis - itu adalah perlindungan bisnis.
Ini adalah pelestarian reputasi.
Ini adalah asuransi pendapatan.
Dan untungnya, saat ini pengaturannya lebih mudah dari sebelumnya.
Luangkan waktu 10 menit, tambahkan pengaturan pemantauan, sambungkan peringatan - di masa depan Anda akan berterima kasih.