
注目記事Server Monitoring
2026年版・Linuxサーバー監視ツールベスト10:オープンソース、SaaS、統合プラットフォームを徹底比較
Linuxサーバー監視ツール10種を、メトリクスのカバレッジ、ディストリビューション対応、コンテナ認識、アラートの深さ、誠実な価格設定で比較。2台でも2,000台でも、あなたの環境に合った最適なツールを見つけてください。
May 15, 20263 min read
続きを読む 監視、インシデント管理、およびインフラの信頼性維持に関する知見。

ステータスページプロバイダー10種を、サブスクライバー管理、インシデントワークフロー、カスタムブランディング、マルチコンポーネントの深さ、誠実な価格設定で比較。単一プロダクトから規制業界の企業まで、聴衆に合った最適なものを見つけてください。
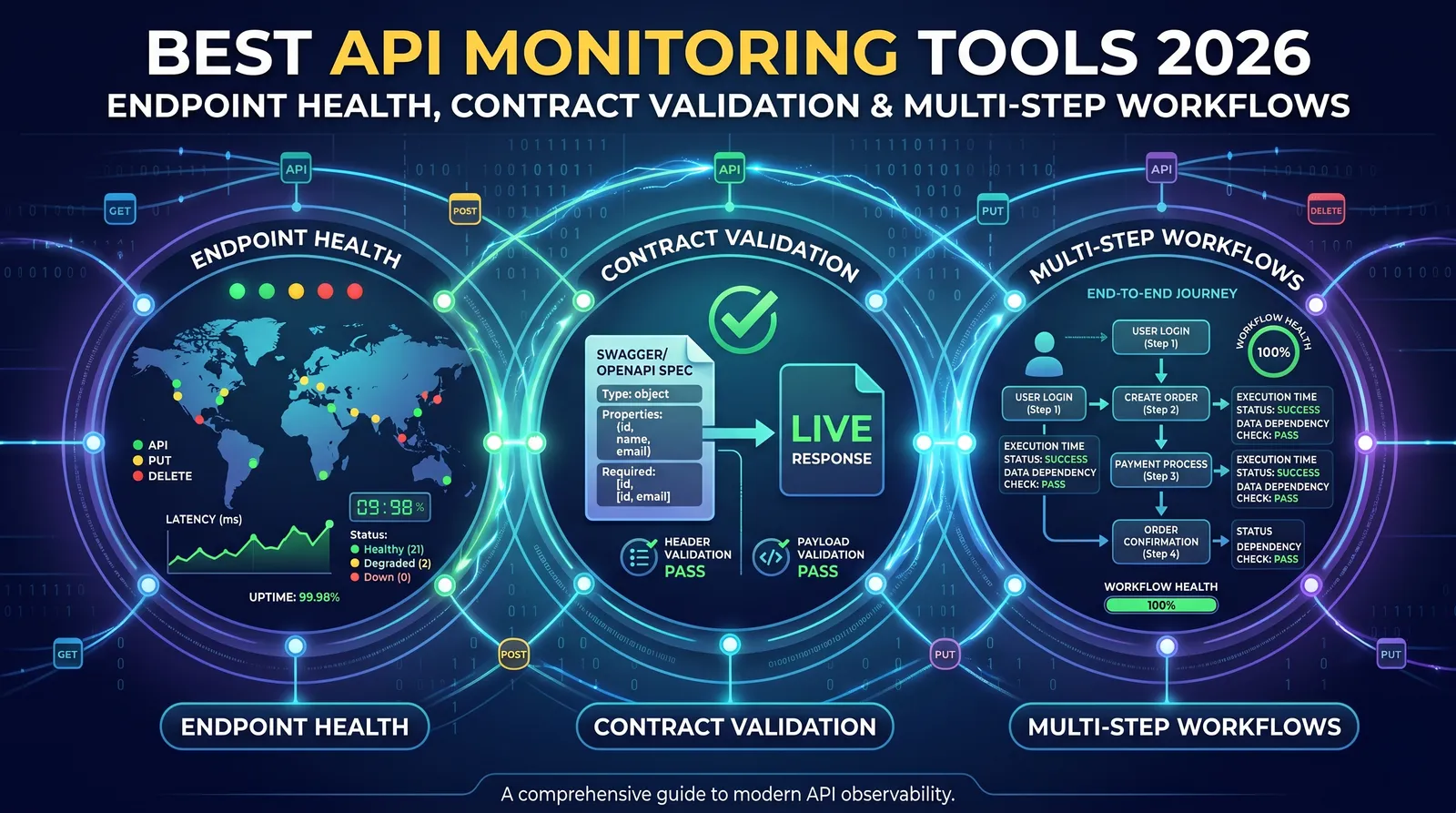
API監視ツール10種を、レスポンスアサーション、マルチステップワークフロー、認証サポート、誠実な価格設定で比較。数本の公開APIから数千の内部マイクロサービスまで、エンドポイント規模に合った最適なツールを見つけてください。

cronジョブ・ハートビート監視ツール10種を、スケジュール追跡、サイレント障害検知、実行時間アラート、誠実な価格設定で比較。夜間バックアップ1本から数千の分散スケジュールタスクまで、バックグラウンドジョブに合う最適なツールを見つけてください。

SSL監視ツール10種を、有効期限アラート、チェーン検証、TLS解析、誠実な価格設定で比較。1サイトでもマルチテナントSaaSでも、ドメインの規模に合った最適なツールを見つけてください。

サーバー監視ツール12種を、エージェントのフットプリント、OSカバレッジ、アラートの深さ、誠実な総コストで比較。1台の開発サーバーから数千の本番ホストまで、フリートに合った最適なツールを見つけてください。

各チームは3〜4本のツールを単一プラットフォームへ置き換えています。2026年の稼働監視ツールトップ10を、統合の時代をどれだけうまく乗りこなせるかでランキングしました。

Dockerコンテナ監視は、稼働中のコンテナのヘルス、パフォーマンス、リソース消費量――CPU、メモリ、ネットワーク、再起動――をリアルタイムで追跡します。

2026年の最良のウェブサイト監視ツール――無料と有料――を稼働、ページ速度、SSL、トランザクションで比較し、数分で選択しましょう。