
Lo stack di monitoraggio perfetto: Strumenti e strategie che ogni ingegnere DevOps dovrebbe utilizzare nel 2025
L'infrastruttura moderna è distribuita, in rapida evoluzione e sempre più complessa. Gli ingegneri DevOps devono distribuire più velocemente, individuare prima i problemi, automatizzare le risposte e garantire l'affidabilità dei sistemi, il tutto mantenendo i costi del cloud sotto controllo. Il monitoraggio non è più uno strumento “da avere” che gira in background. Nel 2025, un ottimo stack di monitoraggio è un componente di prima classe della vostra infrastruttura.
Ma ecco la verità:
La maggior parte delle aziende non ha una strategia di monitoraggio unificata, ma un caos di strumenti.
Cinque dashboard, tre sistemi di allerta, due cloud e ancora nessuno si accorge del picco di CPU finché il cliente non apre un ticket di assistenza.
Questo articolo vi aiuta a costruire un stack di monitoraggio completo passo dopo passo - che aiuta i team DevOps individuare, diagnosticare e reagire ai problemi prima ancora che gli utenti se ne accorgano.
Cosa tratteremo
-
Perché il monitoraggio è più importante che mai nel 2025
-
I 6 pilastri di un perfetto stack di monitoraggio
-
Gli strumenti più adatti (open-source + SaaS) per ogni livello
-
Automazione e AIOps per una risposta più rapida agli incidenti
-
Esempi reali di flussi di lavoro che utilizzano Xitoring
-
Le migliori pratiche per costruire una cultura dell'osservabilità a prova di futuro
Prendete il caffè e progettiamo l'ecosistema di monitoraggio perfetto.
Perché il monitoraggio è più importante che mai nel 2025
Le tendenze delle infrastrutture si stanno modificando:
| Tendenza | Risultato |
|---|---|
| Microservizi > Monoliti | Più punti di guasto distribuiti |
| Adozione del multi-cloud | Visibilità e correlazione delle metriche più difficili |
| Team remoti e sistemi globali | Necessità di monitoraggio e automazione 24/7 |
| Utenti e carichi di lavoro potenziati dall'intelligenza artificiale | Sensibilità alle prestazioni più elevate |
| Tempo di attività previsto vicino a 100% | Gli incidenti costano più che mai |
Anche le piccole interruzioni fanno male. Pochi minuti di downtime durante il checkout possono costare migliaia di euro a un negozio di e-commerce. Un degrado delle prestazioni in un'applicazione SaaS influisce direttamente sul tasso di abbandono. E per i servizi con SLA, tempi di inattività = soldi in tasca.
Il monitoraggio non riguarda più solo i tempi di attività, ma anche:
Ottimizzazione delle prestazioni
Protezione dell'esperienza utente
Risposta rapida agli incidenti
Rilevamento predittivo dei guasti
Decisioni ingegneristiche basate sui dati
Il vostro stack di monitoraggio è il vostro sistema di allarme rapido, il vostro laboratorio forense e il vostro assistente operativo, tutto in uno.
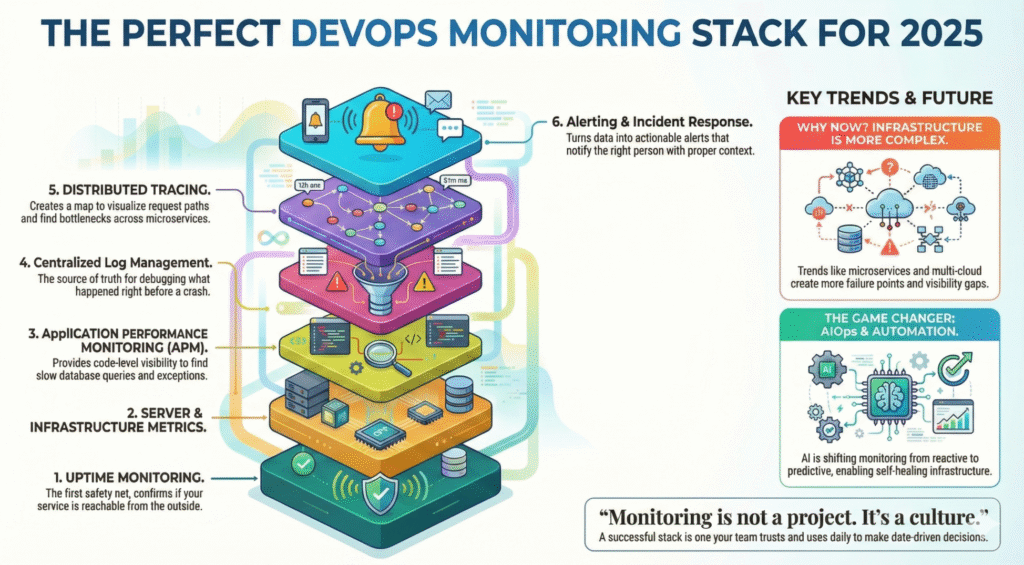
I 6 pilastri di uno stack di monitoraggio perfetto
Una configurazione di monitoraggio matura comprende più livelli che lavorano insieme:
-
Monitoraggio dei tempi di attività e controllo dello stato
-
Metriche del server e dell'infrastruttura
-
Monitoraggio delle prestazioni delle applicazioni (APM)
-
Registri e gestione centralizzata dei registri
-
Tracing e osservabilità distribuita
-
Allarme, risposta agli incidenti e automazione
La maggior parte dei guasti non avviene in modo isolato, quindi un buon stack mette in relazione le metriche su tutti i livelli.
Analizziamoli uno per uno.
1. Monitoraggio dei tempi di attività: la prima rete di sicurezza
I controlli sull'uptime confermano se il vostro servizio è raggiungibile dall'esterno. Questo è fondamentale per:
-
Monitoraggio della disponibilità
-
Rapporti SLA
-
Rilevamento di problemi DNS/SSL/di rete
-
Rilevamento precoce delle interruzioni prima che i clienti se ne accorgano
Il monitor del tempo di attività dovrebbe:
-
Ping da più sedi globali
-
Supporta HTTP, TCP, ICMP, DNS e controlli delle porte
-
Avviso immediato quando inizia il downtime
-
Fornisce pagine di stato pubblico/privato
-
Tracciare lo storico dei tempi di attività e degli incidenti
Buoni strumenti:
🔹 Xitoring (Uptime + monitoraggio del server in un'unica piattaforma)
🔹 UptimeRobot, Pingdom, BetterUptime
🔹 Fai da te con Prometheus + Esportatore Blackbox
Esempio di flusso di lavoro con Xitoring:
Configurate i controlli di uptime per le API e le landing page. Xitoring monitora i nodi globali ogni minuto e avvisa istantaneamente via Slack/Telegram se la latenza aumenta o l'endpoint diventa irraggiungibile. La pagina di stato si aggiorna automaticamente, senza bisogno di comunicazioni manuali.
2. Monitoraggio di server e infrastrutture
Qui si tiene traccia della CPU, della RAM, della media di carico, dell'IO del disco, del throughput di rete, dei log di sistema e altro ancora.
Perché è importante:
Molte interruzioni iniziano qui: perdite di memoria, dischi pieni, strozzatura della CPU, problemi del kernel, esaurimento delle risorse.
Uno strumento di monitoraggio dei server nel 2025 dovrebbe fornire:
Raccolta di metriche e cruscotti
Avvisi basati su soglie e anomalie
Monitoraggio dei processi/servizi
Supporto Linux + Windows
Raccolta con o senza agente
Strumenti da considerare:
Open-source: Prometheus + Node Exporter, Zabbix, Grafana
SaaS: Datadog, New Relic, Xitoring per approfondimenti in tempo reale
Dove Xitoring si adatta:
Xitoring installa un agente leggero, monitora le metriche di Linux/Windows e utilizza il rilevamento di pattern AI per avvisare l'utente di comportamenti insoliti delle prestazioni prima che causino un downtime.
3. Monitoraggio delle prestazioni delle applicazioni (APM)
Anche se i server sembrano sani, la vostra applicazione potrebbe essere in difficoltà.
APM fornisce:
-
Tracce delle prestazioni a livello di codice
-
Rilevamento lento dell'endpoint/della query del database
-
Perdite di memoria e tracciamento delle eccezioni
-
Interruzioni della latenza end-to-end
Se la vostra applicazione scala velocemente o si estende su microservizi, l'APM non è facoltativo, ma è la sopravvivenza.
4. I registri - La fonte della verità durante gli incidenti
Quando qualcosa si rompe, gli ingegneri corrono ai dashboard... e poi alla fine ai registri.
La registrazione centralizzata aiuta a rispondere:
-
Cosa è successo prima dell'incidente?
-
Quale servizio ha lanciato l'eccezione?
-
L'implementazione ha introdotto un bug?
-
Si tratta di un problema di sistema o di una dipendenza esterna?
Esempi di stack di log:
-
ELK (Elasticsearch + Logstash + Kibana) - flessibile, ampiamente utilizzato
-
Grafana Loki - più economico e scalabile
-
Graylog, Splunk - funzionalità di ricerca aziendale
-
Registri nativi del cloud - GCP Logging, AWS CloudWatch
Le registrazioni devono essere centralizzate; l'accesso ai server tramite SSH per controllare i registri è un problema del 2010.
5. Tracing distribuito - Comprendere il comportamento del sistema
Quando le richieste passano attraverso code, servizi, bilanciatori di carico e database, il tracciamento è la vostra mappa.
Il tracciamento distribuito aiuta:
Visualizzare i percorsi delle richieste
Identificare i colli di bottiglia tra i microservizi.
Debug di timeout, tentativi e fallimenti
Standard e strumenti:
-
OpenTelemetry (standard industriale)
-
Jaeger, Zipkin
-
AWS X-Ray / GCP Cloud Trace
Il tracciamento unisce APM + log + metriche per rivelare il quadro completo di un incidente.
6. Allarme e risposta agli incidenti
Il monitoraggio non serve a nulla senza avvisi che permettano di agire. Nessuno vuole stanchezza da allerta, ma il silenzio durante le interruzioni è ancora peggiore.
Un moderno flusso di lavoro di alerting dovrebbe:
-
Rilevare
-
Avvisare la persona giusta
-
Fornire un contesto (dashboard, log)
-
Attivare la correzione automatica quando possibile
Canali di avviso:
-
Slack, Teams, e-mail
-
PagerDuty / OpsGenie
-
Telegram, SMS
-
Webhook per l'automazione
Xitoring Esempio:
Quando la CPU rimane al di sopra di 90% per 10 minuti, Xitoring invia avvisi via Slack e Telegram, allega metriche di sistema e può attivare script automatici (ad esempio, riavviare un servizio o scalare i pod).
AIOps e automazione - Il cambiamento di gioco del 2025
L'evoluzione del monitoraggio sta passando da reattivo a predittivo.
L'intelligenza artificiale può aiutare a rilevare:
-
Picchi di traffico insoliti
-
Perdite di memoria lente
-
Variazione della latenza prima dell'impatto sull'utente
-
Tendenze comportamentali che portano al fallimento
Piattaforme come Xitoring integrano già Rilevamento delle anomalie basato sull'intelligenza artificiale, abilitazione:
🔹 avviso automatico prima delle interruzioni
🔹 suggerimento delle cause principali
🔹 trigger di recupero automatico
Il futuro è infrastruttura autorigenerante.
Le migliori pratiche per i team DevOps nel 2025
-
Attenzione ai sintomi, non al rumore
Il picco della CPU da solo non è un problema, ma lo è un picco + un aumento della latenza. -
Utilizzare le pagine di stato
Riduce il carico di assistenza e crea fiducia nei clienti. -
Tracciare le metriche SLO/SLI
L'affidabilità è misurabile e si può migliorare solo ciò che si tiene sotto controllo. -
Osservare da vicino le implementazioni
La maggior parte degli incidenti è dovuta a rilasci umani. -
Il monitoraggio non è un progetto. È una cultura.
Pensieri finali
Uno stack di monitoraggio perfetto non significa acquistare lo strumento più costoso o ingegnerizzare in modo eccessivo la pipeline di osservabilità. Significa combinare livelli che vi diano visibilità dalla richiesta dell'utente → al server → all'applicazione → ai log → alla causa principale.
Se c'è un risultato da trarre:
Il monitoraggio non dovrebbe dirvi che qualcosa è andato storto, ma dovrebbe dirvi che perché e come risolverlo velocemente.
Sia che si scelga uno stack open-source, una piattaforma aziendale o una soluzione unificata come Xitoring che combina il monitoraggio del tempo di attività e dei server con le intuizioni dell'intelligenza artificiale, la chiave è la creazione di un sistema di cui il team si fida e che utilizza quotidianamente.