InfluxDB Monitoraggio
Monitora in tempo reale la velocità di scrittura di InfluxDB, le prestazioni delle query, le metriche del motore di archiviazione e lo stato delle politiche di conservazione, senza alcuna configurazione.
Perché monitorare InfluxDB?
InfluxDB è il database di serie temporali leader nel settore per metriche, eventi e analisi in tempo reale. Il monitoraggio di InfluxDB garantisce un corretto inserimento dei dati in scrittura, prestazioni ottimali delle query e una gestione adeguata della conservazione dei dati.
Monitoraggio di InfluxDB, in breve
Il monitoraggio di InfluxDB intercetta gli stalli di throughput in scrittura, la cardinalità delle serie fuori controllo (la classica modalità di fallimento di InfluxDB 1.x/2.x), gli arretrati di compaction TSM, i rallentamenti delle query e la crescita del WAL prima che provochino perdita di ingest o timeout di query sulle sue dashboard Grafana. Per pipeline di sensori IoT, backend di metriche applicative e qualsiasi deployment dello stack TICK, la visibilità per database è ciò che separa un avviso di 60 secondi da un incidente di più ore a caccia di datapoint mancanti. Xitoring rileva automaticamente il suo InfluxDB, legge l'endpoint Prometheus nativo /metrics e instrada gli avvisi verso Slack, PagerDuty, Telegram o il suo on-call esistente.
Ciò che monitoriamo
Punti scritti/sec
Tasso di scrittura dei punti dati.
Durata delle query
Tempo medio di esecuzione delle query.
Cardinalità delle serie
Totale delle serie temporali uniche.
Dimensione dello storage
Storage TSM su disco.
Tasso di compattazione
Throughput di compattazione TSM.
Dimensione della cache
Utilizzo della cache di scrittura in memoria.
Byte su disco del WAL
`storage.tsm1.wal.currentSegmentDiskBytes` + `oldSegmentsDiskBytes`. La crescita del WAL senza consolidamento TSM significa che il tempo di recovery al riavvio aumenterà sensibilmente.
Dimensione dello storage su disco
`storage.tsm1.filestore.diskBytes` + numFiles per shard. La tracci rispetto alla sua retention policy: conteggi di file elevati a parità di dimensione dati segnalano frammentazione.
Tasso di HTTP 4xx / 5xx
`httpd.clientError` + `httpd.serverError` (o il Prometheus `http_api_request_errors_total`). I picchi di 4xx segnalano bug di schema/auth lato client; i 5xx segnalano fallimenti lato server.
Connessioni / Fallimenti di autenticazione
`httpd.req` (richieste HTTP totali), `httpd.authFail` (tentativi di autenticazione falliti), `httpd.pingReq`. I picchi di fallimento di autenticazione segnalano Telegraf mal configurato o una rotazione di credenziali andata storta.
Runtime: goroutine e GC
Statistiche runtime Go: `runtime.NumGoroutine` (rilevamento di goroutine leak), `runtime.HeapAlloc` (heap live), `runtime.NumGC`/`PauseTotalNs` (pressione del GC). Intercetti leak e regressioni nei tempi di pausa prima dell'OOM.
Scritture da subscription
`subscriber.pointsWritten` e `subscriber.writeFailures`: quando Kapacitor o pipeline a valle consumano tramite subscription, è così che intercetta la loro backpressure.
Configurabile condizioni di attivazione
Imposta dei trigger personalizzati nella tua dashboard per ricevere una notifica non appena le metriche dell{name}e superano le soglie da te definite.
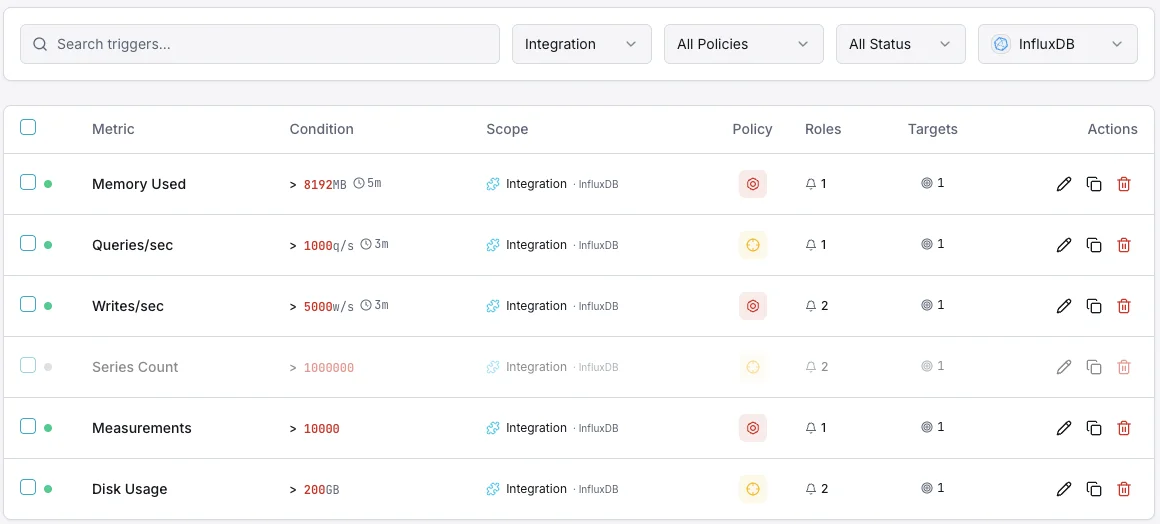
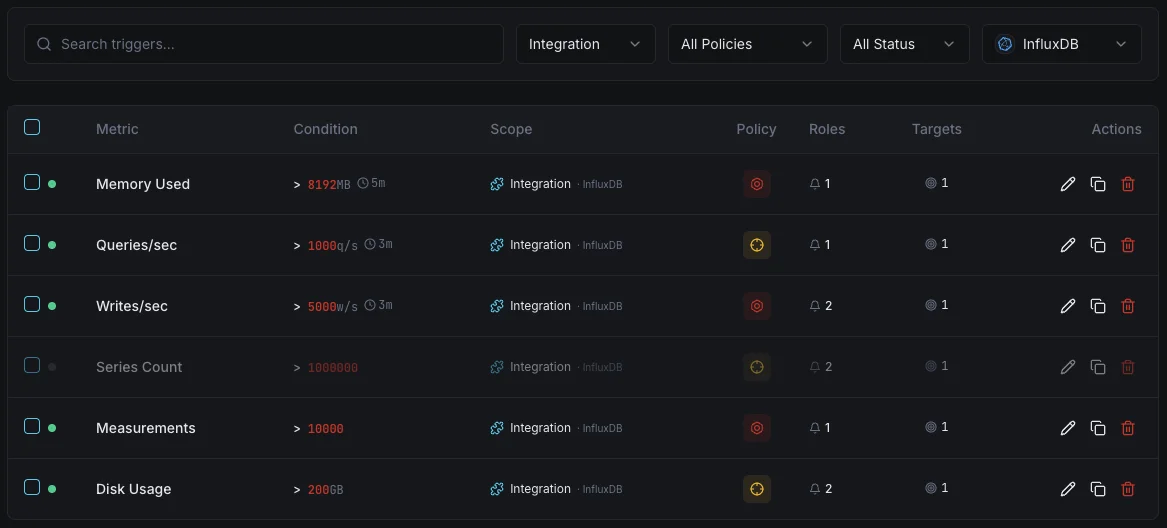
Throughput di scrittura
avvisoSi attiva su anomalie del tasso di scrittura.
Durata delle query
avvisoAvvisa sulle query lente.
Cardinalità delle serie
criticoSi attiva quando la cardinalità è troppo alta.
Dimensione dello storage
criticoSi attiva quando lo storage supera la soglia.
Importanza del monitoraggio InfluxDB
InfluxDB gestisce dati time-series ad alta velocità. Cardinalità elevata, pressione di scrittura e ritardi di compattazione possono degradare le prestazioni.
- Tieni traccia del throughput di scrittura per la salute dell'ingestione
- Monitora la cardinalità delle serie per prevenire OOM
- Rileva in anticipo le query lente
- Assicurati che la compattazione tenga il passo
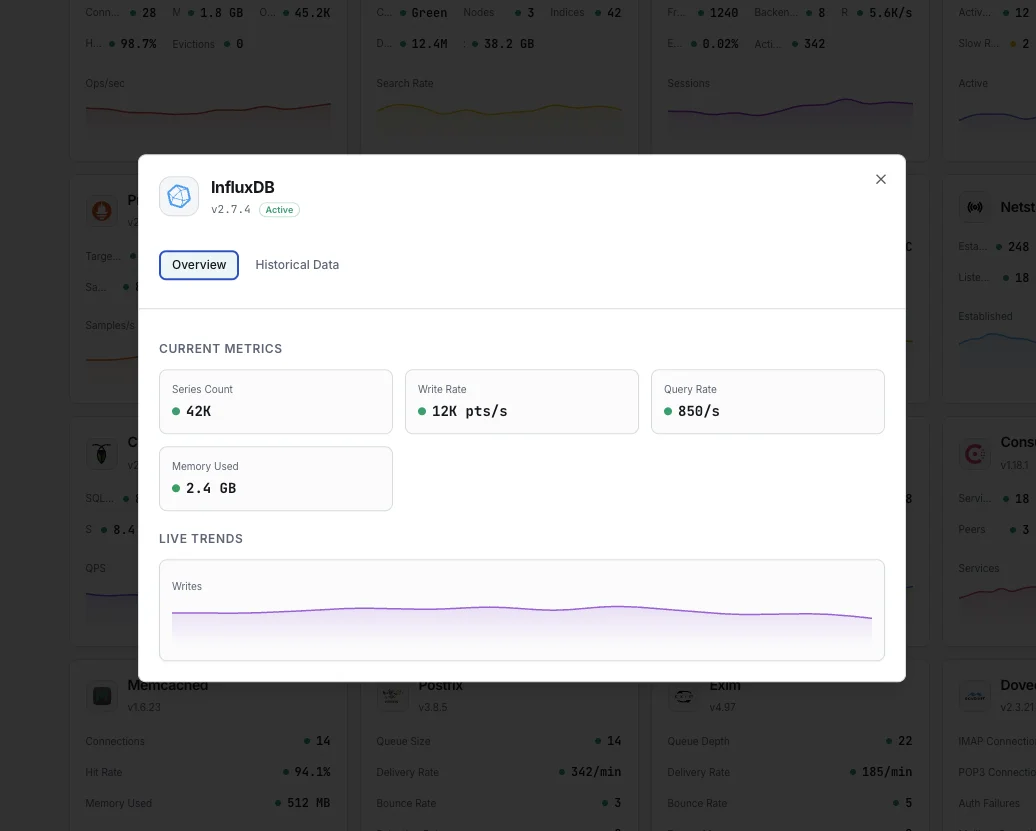
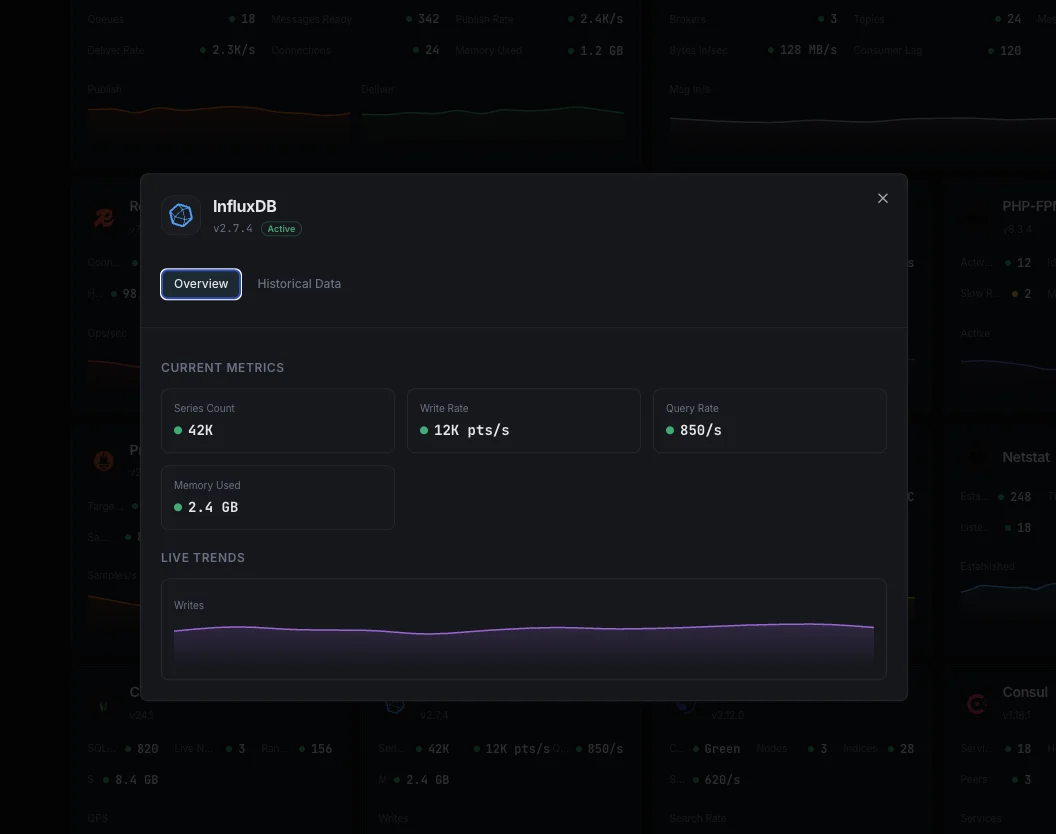
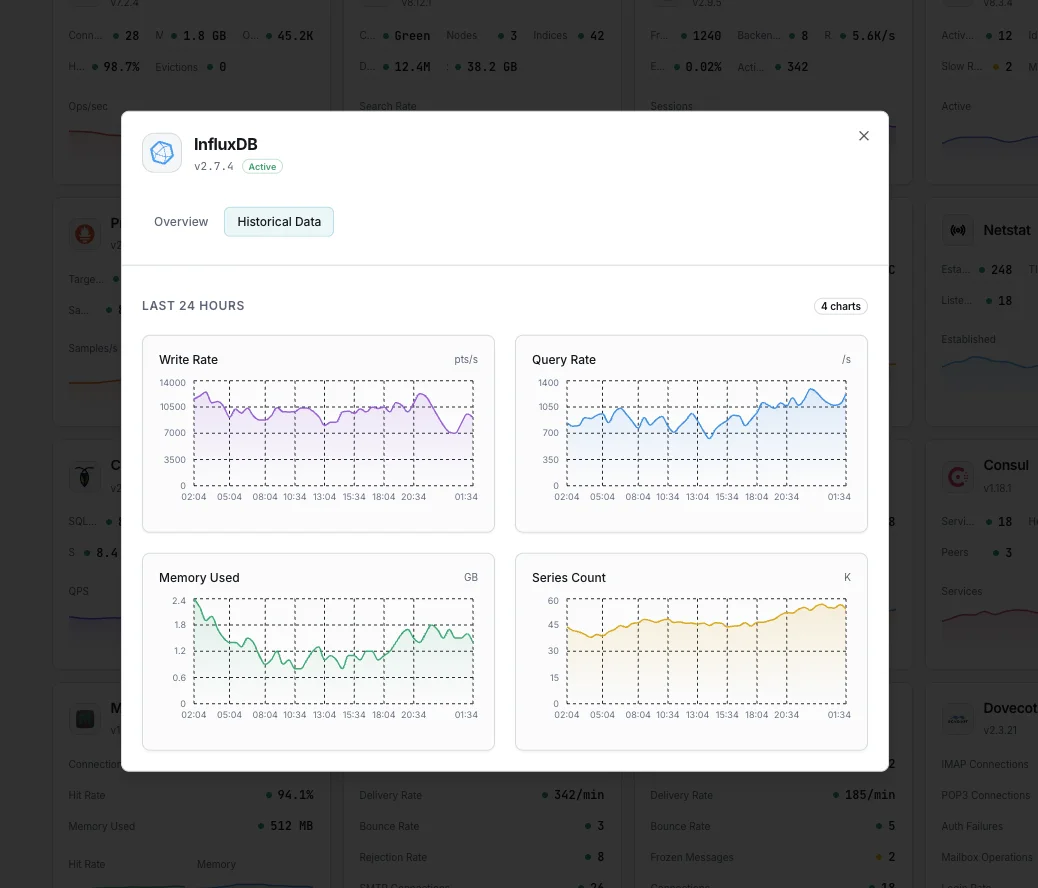
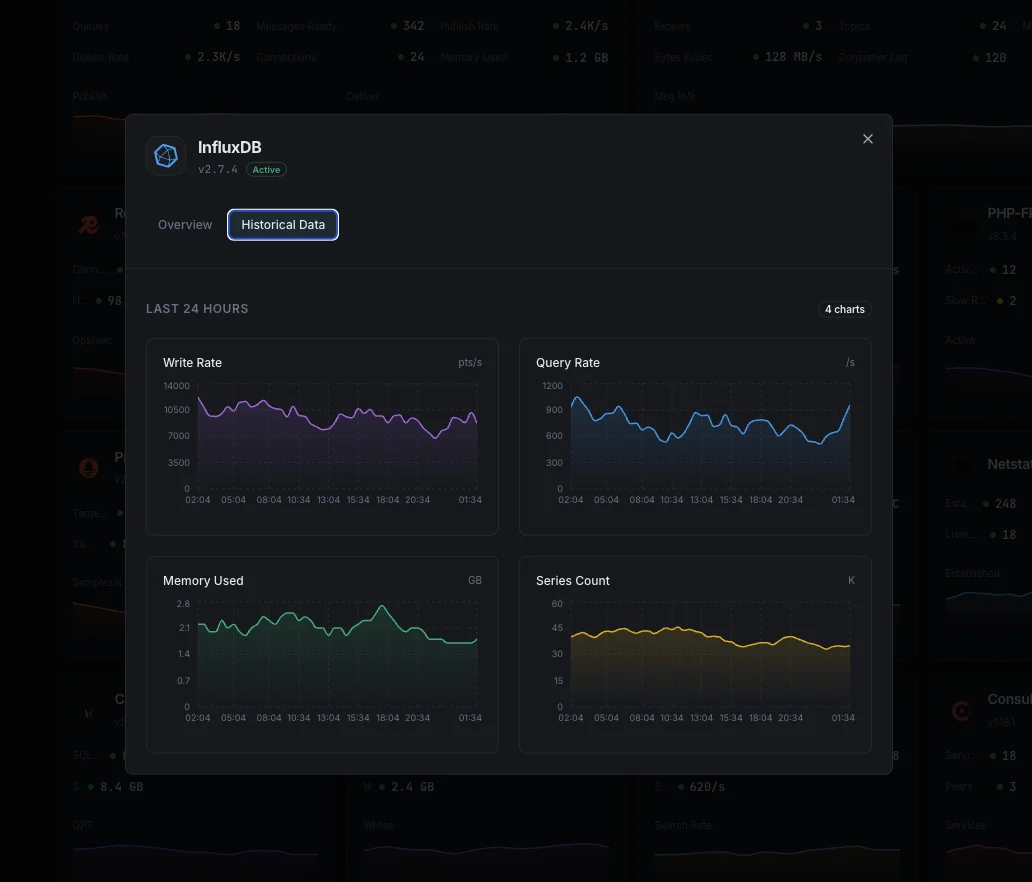
Perché scegliere Xitoring
Monitoraggio InfluxDB zero-config.
- Installazione con un solo comando
- Nodi globali
- Dashboard unificata
- Avvisi multicanale
- Conservazione storica
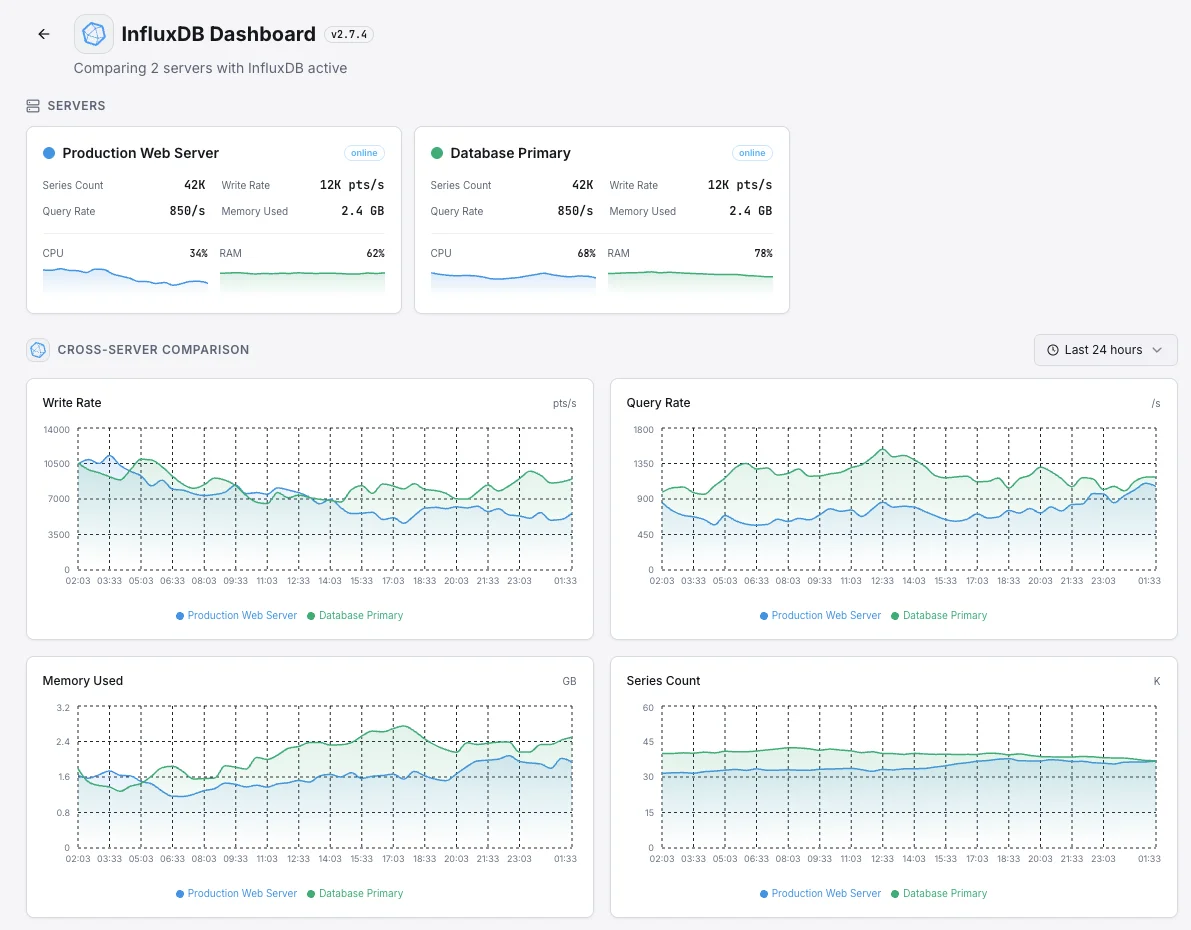
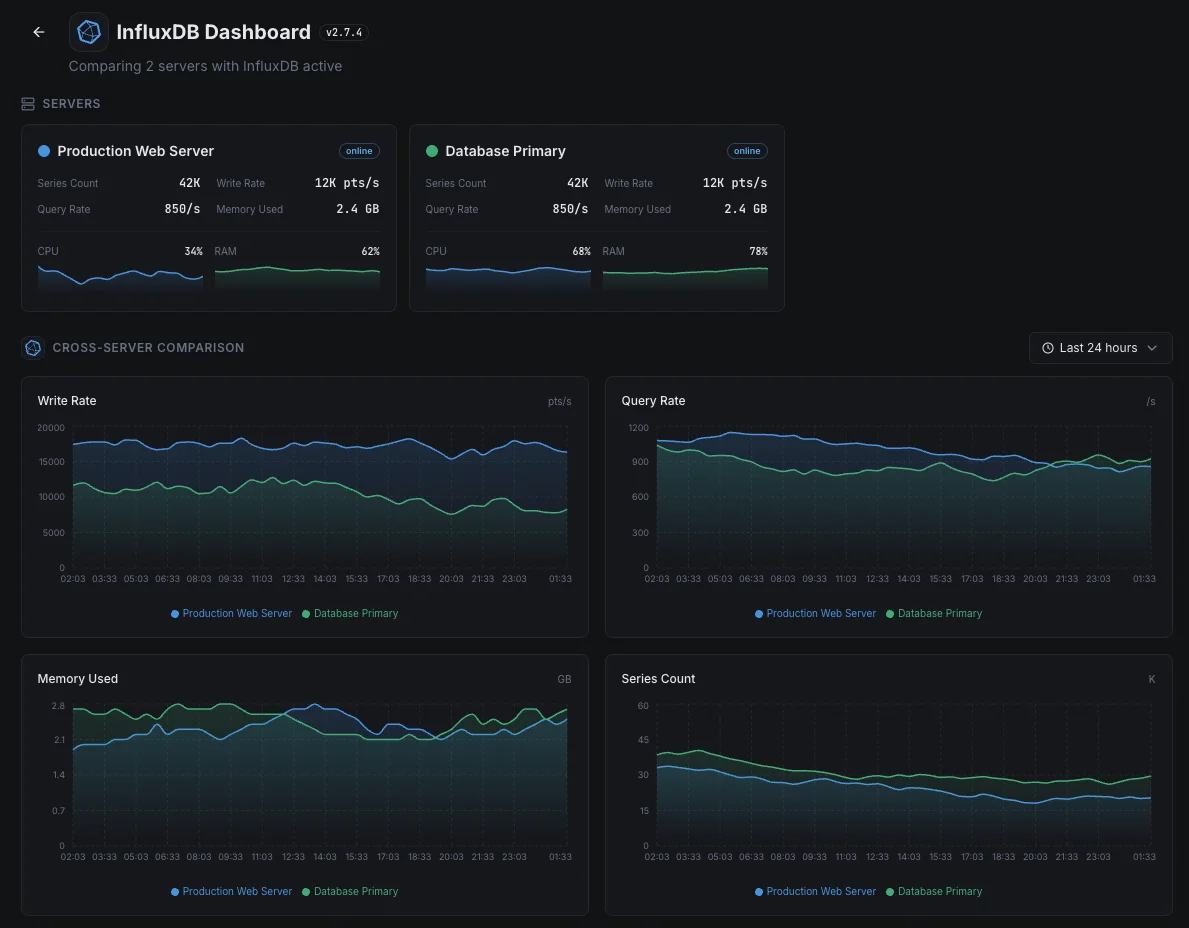
Scenari comuni di monitoraggio di InfluxDB
Dove InfluxDB viene tipicamente eseguito oggi — e cosa potrebbe andare storto se nessuno lo monitora.
Il database dietro le dashboard del tuo team
Quando le dashboard in Grafana o un altro strumento risultano lente, la causa è spesso il database sottostante — non la dashboard stessa. Mettiamo in evidenza dove risiede effettivamente la lentezza in modo che il team risolva il problema giusto invece di inseguire il sintomo.
Dati in arrivo da sensori e dispositivi
Dispositivi connessi, apparecchiature di fabbrica e sensori IoT inviano misurazioni ogni secondo di ogni giorno. Un backup silenzioso nella pipeline significa dati persi — e i dati persi sono persi per sempre. Monitoriamo il flusso end-to-end in modo che una singola lettura persa faccia scattare l'allarme.
Metriche di app e infrastruttura in un unico posto
Quando lo stesso database contiene sia le metriche dell'app che quelle del server, un problema con il database nasconde ogni segnale contemporaneamente. Monitoriamo il database stesso in modo che il monitoraggio del team non si spenga mai durante un incidente.
Prerequisiti per InfluxDB
Assicurati di avere tutto questo in posizione — la maggior parte delle installazioni dura 60 secondi una volta soddisfatte le condizioni.
- InfluxDB 1.x o 2.x in esecuzione sul server
- Porta HTTP di InfluxDB raggiungibile da Xitogent (predefinita 8086)
- Opzionale: un token in sola lettura se l'autenticazione di InfluxDB 2.x è abilitata
Inizia con verbali
Installa Xitogent sul tuo host InfluxDB
Installa il leggero agente di monitoraggio Xitogent sull'host che esegue InfluxDB.
curl -s https://xitoring.com/install.sh | sudo bash -s -- --key=YOUR_API_KEYConferma che InfluxDB sia raggiungibile
Verifica che InfluxDB sia in ascolto sulla sua porta HTTP (predefinita 8086) e raggiungibile dall'host che esegue Xitogent. Xitogent chiederà host e porta durante l'integrate — non sono richieste ulteriori modifiche di configurazione o esposizioni di endpoint.
sudo xitogent integrateAbilita l'integrazione InfluxDB
Usa la dashboard di Xitoring o la CLI per abilitare l'integrazione InfluxDB. Xitogent rileva automaticamente la tua versione di InfluxDB e inizia a raccogliere metriche di scrittura, query e archiviazione.
Configura le soglie di allerta (opzionale)
Imposta soglie personalizzate per Write Throughput, durata delle query o cardinalità delle serie per intercettare pressione sull'ingestion e crescita incontrollata dei tag prima che le query rallentino.
Verifica che funzioni
Esegui questo comando sul server per confermare che Xitogent ha rilevato l'integrazione. In circa 30 secondi nuove metriche cominceranno a comparire sulla tua dashboard.
sudo xitogent statusStai valutando alternative?
Scopri come Xitoring si confronta con le alternative per il monitoraggio di InfluxDB — prezzi fissi, integrazioni più approfondite e un unico agente che copre l'intero stack.



Spesso domande poste
InfluxDB 1.x e 2.x?
Impatto?
Come rilevo i problemi di cardinalità in InfluxDB?
Cos'è il database _internal in InfluxDB?
Come monitoro le compaction di InfluxDB?
Qual è la differenza tra il monitoraggio di InfluxDB 1.x, 2.x e 3.0?
Come rilevo la lentezza delle query in InfluxDB?
Come monitoro lo storage TSM di InfluxDB?
Questa integrazione influirà sulle prestazioni di InfluxDB?
Inizia a monitorare InfluxDB oggi
Configurazione in meno di 60 secondi. Non è richiesta alcuna carta di credito. Statistiche complete fin dal primo giorno.
Inizia la prova gratuitaContinua a esplorare