Disk Health Monitorização
Monitorize os atributos SMART dos discos, a temperatura, os setores reatribuídos e os indicadores de falha preditiva em SSDs e HDDs em tempo real.
Por que monitorizar Disk Health?
As falhas de disco são uma das principais causas de perda de dados e de paragens não planeadas. A monitorização do estado dos discos da Xitoring utiliza a tecnologia SMART (Self-Monitoring, Analysis, and Reporting Technology) para emitir alertas antecipados antes que as unidades falhem, abrangendo SSDs, HDDs e configurações RAID, tanto em Linux como em Windows.
Monitorização da saúde do disco, explicada
A monitorização da saúde do disco deteta o crescimento de setores realocados, o desgaste de NVMe, picos de temperatura e indicadores iminentes de falha dias ou semanas antes de as drives morrerem — tempo suficiente para migrar dados e trocar a drive sem downtime. Para servidores de bases de dados, hosts de backup e qualquer workload onde a falha de uma drive significa perda de dados, a monitorização SMART é o alerta com maior ROI que pode configurar. O Xitoring corre smartctl + nvme-cli localmente e encaminha alertas para Slack, PagerDuty, Telegram ou o seu on-call existente.
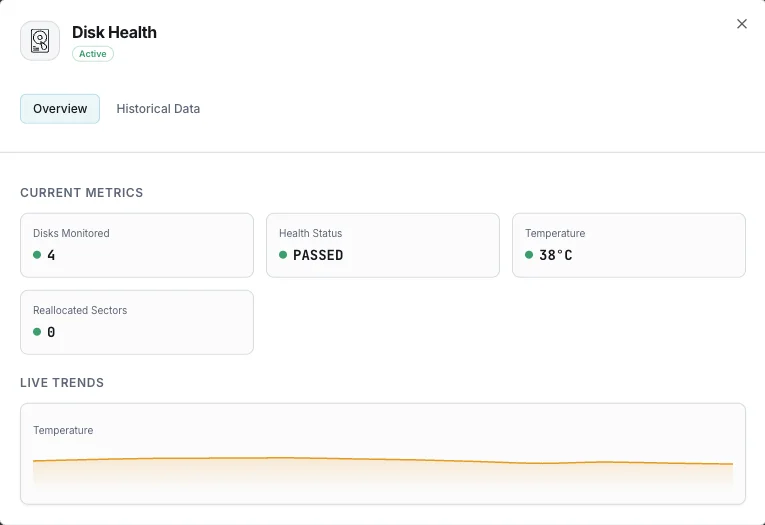
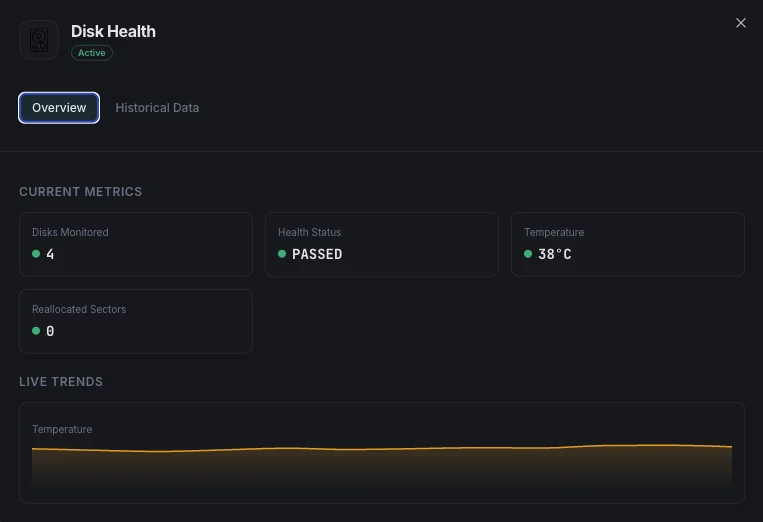
O que monitorizamos
Estado de saúde SMART
Indicador global de saúde do disco (passa/falha).
Temperatura
Temperatura atual do disco em graus Celsius.
Setores realocados
Contagem de setores defeituosos remapeados.
Horas de funcionamento
Horas operacionais totais do disco.
Taxa de erros de leitura
Taxa de erros de leitura encontrados.
Setores pendentes
Setores à espera de serem remapeados.
Temperature_Celsius (SMART 194)
Temperatura atual da drive. Os HDDs degradam-se acima dos 50 °C; SSDs de consumidor fazem throttling acima dos 70 °C. Alerte ao valor máximo definido pelo fabricante menos 10 °C, para aviso antecipado.
UDMA_CRC_Error_Count (SMART 199)
Erros CRC relacionados com o cabo na interface SATA/SAS. Valores em aumento sinalizam um cabo defeituoso ou uma ligação solta — uma correção fácil que é frequentemente confundida com falha de drive.
Desgaste de SSD (Wear_Leveling_Count + Total_LBAs_Written)
Monitorização do endurance do SSD. `Wear_Leveling_Count` normalizado para vida útil restante; `Total_LBAs_Written` mais o TBW nominal da drive dão a percentagem atual de desgaste. Alerte aos 80% usados.
NVMe percentage_used
Do `nvme smart-log` — estimativa do fabricante para a vida consumida (0-100%, pode exceder 100% em drives desgastadas). Aviso acima de 80%; crítico acima de 95%.
NVMe available_spare
Percentagem de capacidade de reserva restante para substituição de bad blocks. Aviso abaixo de 10%; crítico abaixo de 5% (o `available_spare_threshold` é tipicamente definido a esse valor).
NVMe critical_warning
Bitfield do `nvme smart-log` que sinaliza: reserva abaixo do limiar, temperatura acima do limiar, fiabilidade do dispositivo degradada, modo apenas de leitura, falha do backup de memória volátil. Qualquer valor diferente de zero = alerta imediato.
Configurável condições de alerta
Configure alertas personalizados no seu painel para ser notificado assim que as métricas dDisk Health ultrapassarem os limites que definiu.
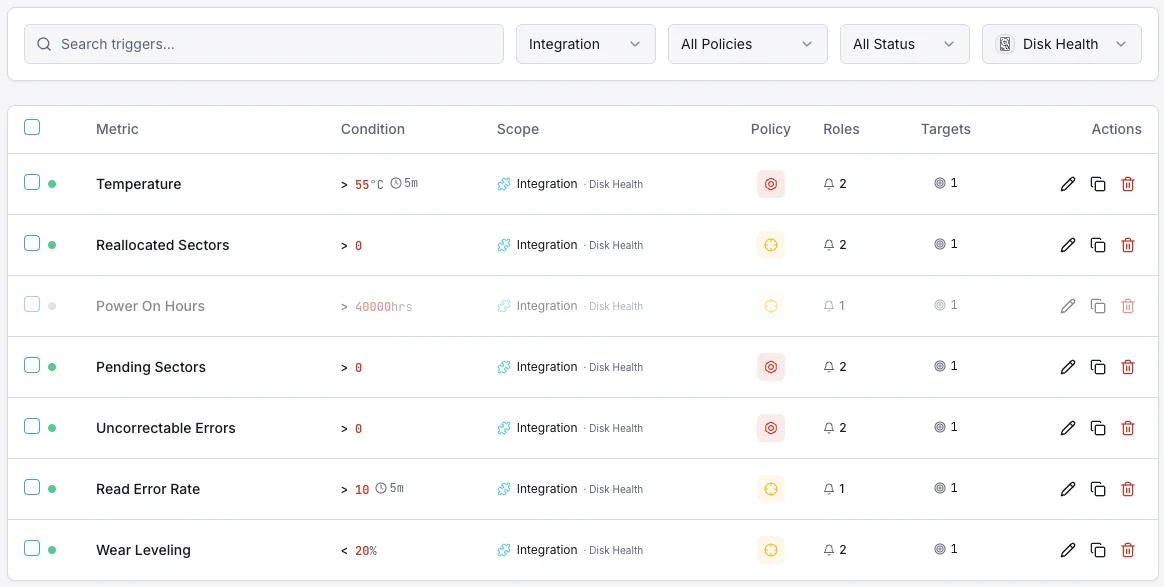
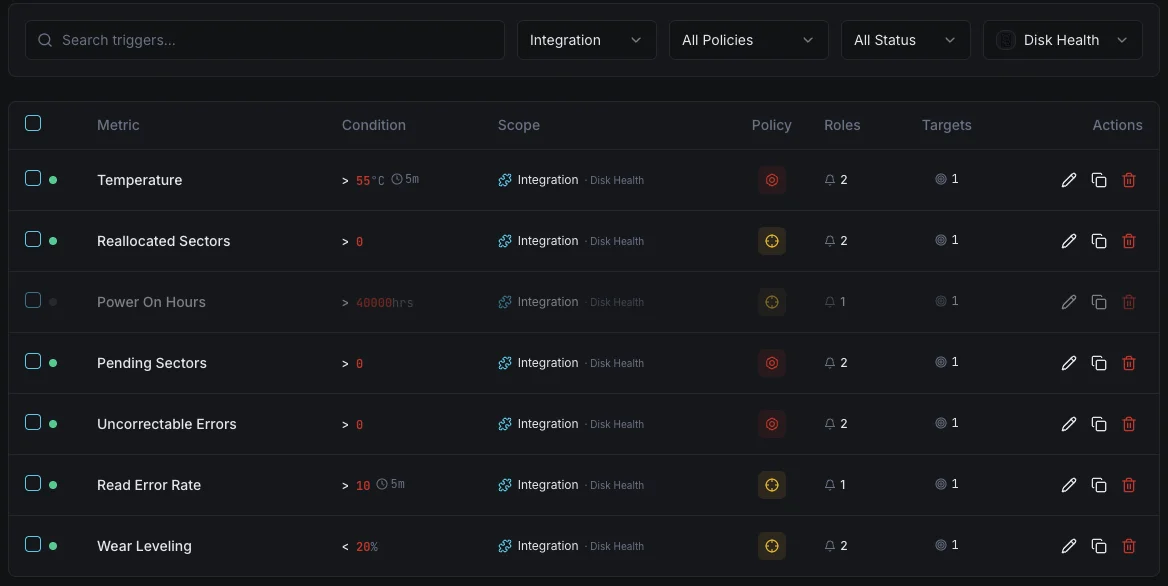
Estado de saúde SMART
críticoDispara quando o SMART reporta um estado de saúde de falha.
Setores realocados
críticoAlerta quando a contagem de setores realocados excede o limite.
Temperatura do disco
avisoDispara quando a temperatura do disco excede o intervalo operacional seguro.
Setores pendentes
avisoDispara quando a contagem de setores pendentes indica falha potencial.
Importância da monitorização da saúde dos discos
As falhas de disco podem resultar em perda de dados e indisponibilidade dispendiosa. A monitorização SMART fornece sinais de aviso precoces — desde temperaturas em subida e setores realocados a aumentar até picos de erros de leitura — para que possa atuar antes de uma drive falhar.
- Evite a perda de dados com deteção precoce de falhas
- Otimize o desempenho identificando estrangulamentos
- Planeie capacidade com análise histórica de tendências
- Mantenha a conformidade com monitorização de integridade de dados
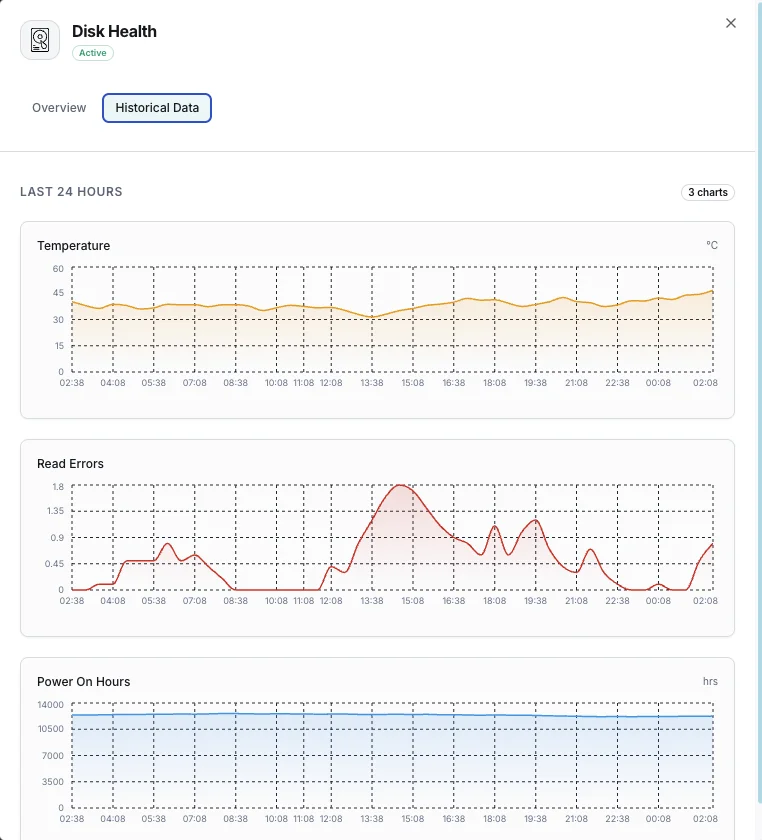
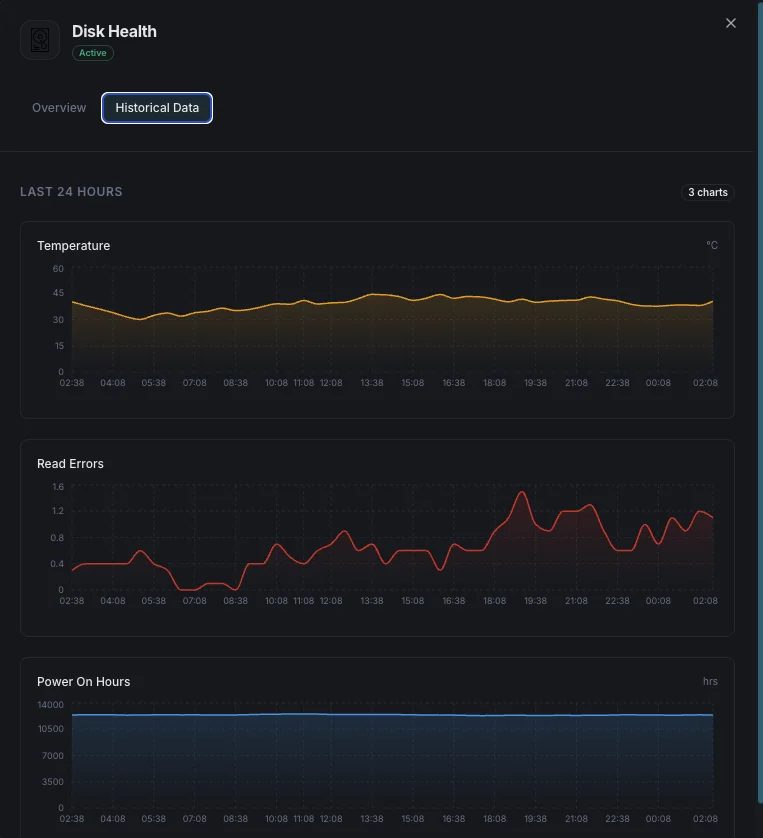
Porquê escolher Xitoring
O Xitoring fornece monitorização de saúde de disco zero-config com integração SMART para todos os tipos de disco. Obtenha alertas em tempo real, tendências históricas e indicadores preditivos de falha num dashboard unificado.
- Compatível com SSDs, HDDs e arrays RAID
- Configuração num único comando em Linux e Windows
- Limiares personalizáveis para atributos SMART
- Alertas multicanal para eventos críticos de disco
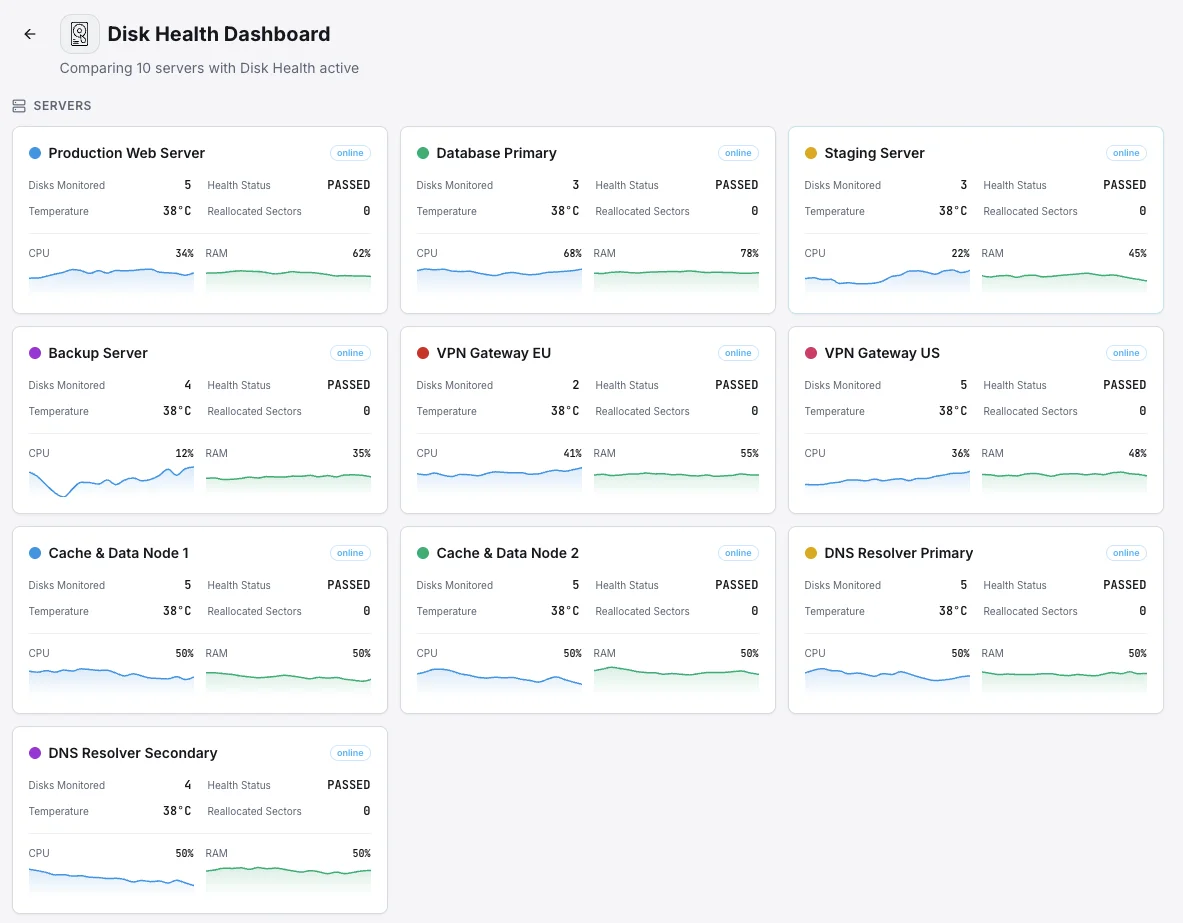
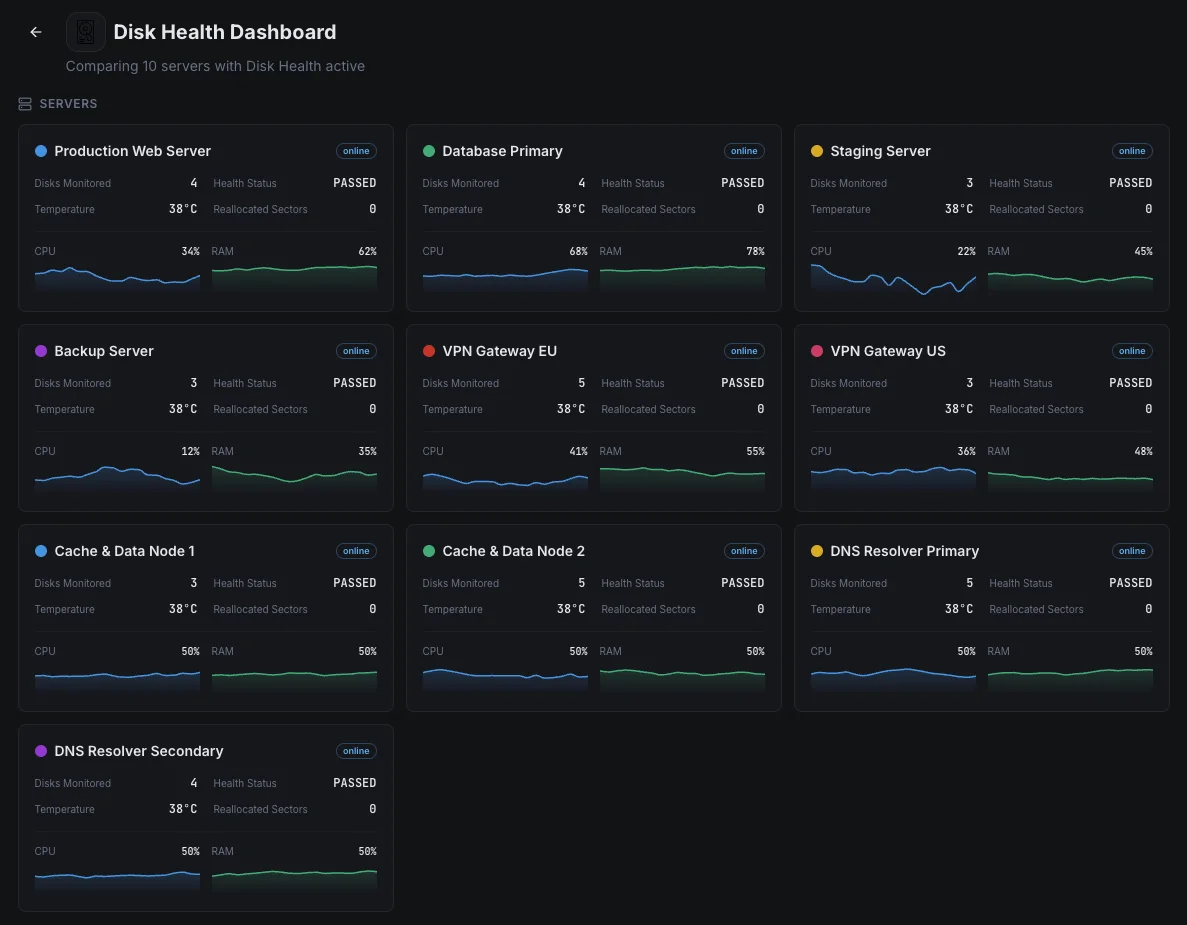
Cenários comuns de monitorização da saúde do disco
Onde a monitorização de disco mais frequentemente deteta falhas de unidade antes que causem danos reais.
Servidores de base de dados
Uma unidade avariada numa base de dados pode significar tempo de inatividade, encomendas perdidas ou, no pior dos casos, dados corrompidos. Monitorizamos cada unidade para detetar os primeiros sinais de falha para que a equipa possa substituir um disco com problemas no seu próprio horário — e não no meio de uma interrupção às 3 da manhã.
Servidores de backup e arquivo
O problema único com as unidades de backup é que uma falha permanece invisível até ao dia em que realmente precisa do backup — altura em que já é tarde demais. Testamos cada unidade numa base regular e detetamos o desgaste precocemente para que nunca procure um backup que não existe.
Servidores que escrevem muitos dados (SSDs)
Os SSDs têm um número limitado de escritas antes de se desgastarem, e bases de dados movimentadas e aplicações com muitos dados esgotam-nos mais rapidamente do que a maioria das equipas percebe. Monitorizamos o desgaste em percentagens claras para que as unidades sejam substituídas a tempo — e não após uma falha súbita e irrecuperável.
Pré-requisitos para Disk Health
Certifique-se de que tem tudo isto pronto — depois disso, a maioria das instalações leva 60 segundos.
- Servidor Linux (Debian/Ubuntu, RHEL/CentOS ou distribuição compatível)
- Pacote smartmontools instalado (smartctl) e lsblk disponível
- Acesso sudo / root — os dados SMART exigem permissões elevadas
Comece a minutos
Instalar pré-requisitos (Linux)
Instale o smartmontools para ativar a recolha de dados SMART. Garanta que o lsblk está disponível no seu sistema.
# Ubuntu/Debian
sudo apt-get install smartmontools
# CentOS/RHEL
sudo yum install smartmontoolsAtivar a integração Disk Health
Execute o comando integrate e selecione Disk Health. O Xitogent deteta automaticamente os seus discos e começa a recolher dados SMART. Não são necessários pré-requisitos no Windows.
xitogent integrateConfirme que está a funcionar
Execute este comando no servidor para confirmar que o Xitogent detetou a integração. Em cerca de 30 segundos começam a chegar novas métricas ao seu painel.
sudo xitogent statusEstá a considerar alternativas?
Veja como o Xitoring se compara às alternativas para a monitorização de Disk Health — preços fixos, integrações mais profundas e um único agente que cobre toda a sua stack.



Frequentemente perguntas feitas
Que tipos de discos são suportados?
Preciso de instalar software adicional?
Posso monitorizar unidades NVMe?
Com que frequência são recolhidos os indicadores?
Que atributos SMART preveem falha de drive?
Como monitorizo a saúde de uma drive NVMe?
Como monitorizo a saúde do disco em Windows?
Com que frequência devo correr self-tests do smartctl?
Funciona com arrays RAID?
Comece a monitorizar Disk Health hoje
Configure em menos de 60 segundos. Não é necessário cartão de crédito. Estatísticas completas desde o primeiro dia.
Iniciar período de avaliação gratuita