
Moderne Infrastruktur ist verteilt, schnelllebig und zunehmend komplex. Von DevOps-Engineers wird erwartet, dass sie schneller deployen, Probleme früher erkennen, Reaktionen automatisieren und für stabile Systeme sorgen – und dabei die Cloud-Kosten im Griff behalten. Monitoring ist längst kein „Nice-to-have"-Werkzeug mehr, das im Hintergrund läuft. 2025 ist ein guter Monitoring-Stack ein erstklassiger Bestandteil Ihrer Infrastruktur.
Aber die Wahrheit ist:
Die meisten Unternehmen haben keine einheitliche Monitoring-Strategie – sie haben Tool-Chaos.
Fünf Dashboards, drei Alarmsysteme, zwei Clouds – und trotzdem fällt der CPU-Spike erst auf, wenn der Kunde ein Support-Ticket öffnet.
Dieser Artikel zeigt Ihnen Schritt für Schritt, wie Sie einen vollständigen Monitoring-Stack aufbauen – einen, der DevOps-Teams dabei hilft, Probleme zu erkennen, zu diagnostizieren und zu beheben, bevor Nutzer sie überhaupt bemerken.
Was wir abdecken
-
Warum Monitoring 2025 wichtiger ist denn je
-
Die 6 Säulen eines perfekten Monitoring-Stacks
-
Best-fit-Tools (Open Source + SaaS) für jede Schicht
-
Automatisierung & AIOps für schnellere Incident-Reaktion
-
Praxis-Workflows mit SaaS-Monitoring
-
Best Practices für eine zukunftssichere Observability-Kultur
Holen Sie sich einen Kaffee – wir entwerfen das perfekte Monitoring-Ökosystem.
Warum Monitoring 2025 wichtiger ist denn je
Die Trends in der Infrastruktur verschieben sich:
| Trend | Auswirkung |
|---|---|
| Microservices > Monolithen | Mehr verteilte Fehlerquellen |
| Multi-Cloud-Adoption | Schwierigere Sichtbarkeit & Metrik-Korrelation |
| Verteilte Teams & globale Systeme | Bedarf an 24/7-Monitoring & Automatisierung |
| KI-gestützte Nutzer & Workloads | Höhere Performance-Sensibilität |
| Uptime-Erwartung nahe 100 % | Incidents kosten mehr denn je |
Selbst kleine Ausfälle tun weh. Ein paar Minuten Downtime im Checkout können einen E-Commerce-Shop Tausende kosten. Eine Performance-Verschlechterung in einer SaaS-App wirkt sich direkt auf die Churn-Rate aus. Und für Services mit SLAs gilt: Downtime = Geld weg.
Beim Monitoring geht es längst nicht mehr nur um Uptime – sondern um:
✔ Performance-Optimierung
✔ Schutz der User Experience
✔ Schnelle Incident-Reaktion
✔ Vorausschauende Fehlererkennung
✔ Datengetriebene Engineering-Entscheidungen
Ihr Monitoring-Stack ist Frühwarnsystem, Forensik-Labor und Operations-Assistent – alles in einem.
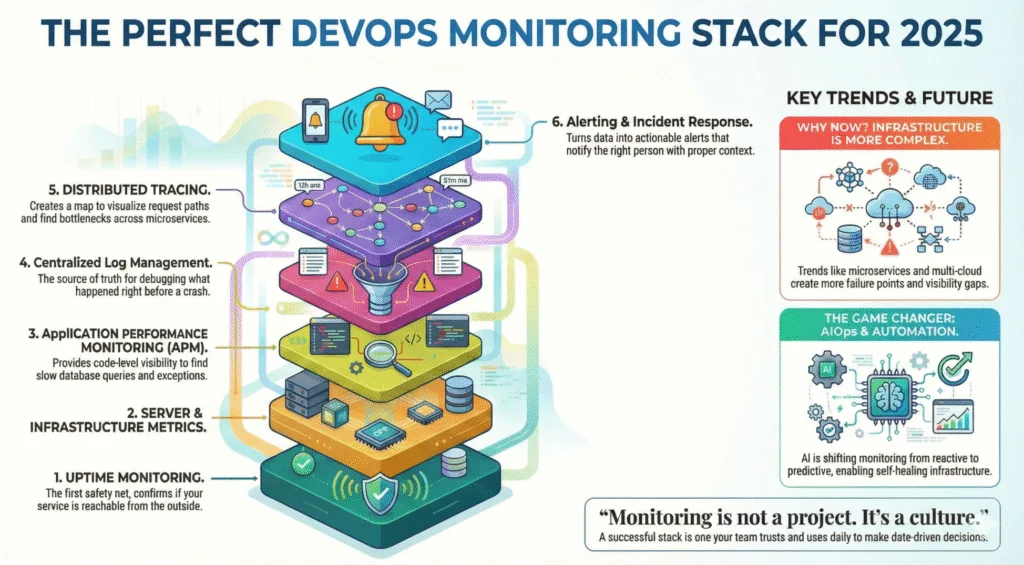
Die 6 Säulen eines perfekten Monitoring-Stacks
Ein ausgereiftes Monitoring-Setup umfasst mehrere Schichten, die zusammenspielen:
-
Uptime-Monitoring & Status-Checks
-
Server- & Infrastruktur-Metriken
-
Application Performance Monitoring (APM)
-
Logs & zentrales Log-Management
-
Tracing & verteilte Observability
-
Alerting, Incident-Response & Automatisierung
Die meisten Ausfälle treten nicht isoliert auf – ein guter Stack korreliert deshalb Metriken über alle Schichten hinweg.
Schauen wir sie uns einzeln an.
1. Uptime-Monitoring – das erste Sicherheitsnetz
Uptime-Checks bestätigen, ob Ihr Dienst von außen erreichbar ist. Das ist entscheidend für:
-
Verfügbarkeits-Tracking
-
SLA-Reporting
-
Erkennung von DNS-, SSL- oder Netzwerkproblemen
-
Frühzeitige Erkennung von Ausfällen, bevor Kunden es merken
Ihr Uptime-Monitor sollte:
-
Von globalen Monitoring-Standorten prüfen
-
HTTP-, TCP-, ICMP-, DNS- und Port-Checks unterstützen
-
Sofort alarmieren, wenn Downtime beginnt
-
Public/Private Status-Pages bereitstellen
-
Historische Uptime und Incidents erfassen
Gute Tools:
🔹 Xitoring (Uptime + Server-Monitoring auf einer Plattform) 🔹 UptimeRobot, Pingdom, BetterUptime 🔹 DIY mit Prometheus + Blackbox Exporter
Beispiel-Workflow mit Xitoring:
Sie konfigurieren Uptime-Checks für APIs und Landing-Pages. Xitoring prüft im Minutentakt von globalen Nodes und alarmiert sofort über Slack/Telegram, sobald die Latenz steigt oder der Endpoint nicht mehr erreichbar ist. Die Status-Page aktualisiert sich automatisch – manuelle Kommunikation entfällt.
2. Server- & Infrastruktur-Monitoring
Hier verfolgen Sie CPU, RAM, Load Average, Disk-IO, Netzwerkdurchsatz, System-Logs und vieles mehr.
Warum das wichtig ist:
Viele Ausfälle haben hier ihren Ursprung – Memory-Leaks, volle Festplatten, CPU-Throttling, Kernel-Probleme, erschöpfte Ressourcen.
Ein Server-Monitoring-Tool sollte 2025 leisten:
✔ Metrik-Erfassung & Dashboards
✔ Schwellwert- und Anomalie-Alarme
✔ Prozess-/Service-Monitoring
✔ Linux- + Windows-Support
✔ Erfassung mit oder ohne Agent
Tools, die Sie in Betracht ziehen sollten:
Open Source: Prometheus + Node Exporter, Zabbix, Grafana
SaaS: Datadog, New Relic, Xitoring für Echtzeit-Insights
Wo Xitoring ins Spiel kommt:
Xitoring installiert einen schlanken Agenten, überwacht Linux-/Windows-Metriken und nutzt KI-gestützte Mustererkennung, um Sie vor ungewöhnlichem Performance-Verhalten zu warnen, bevor es zu Downtime führt.
3. Application Performance Monitoring (APM)
Selbst wenn die Server gesund aussehen: Ihre Anwendung könnte trotzdem schwächeln.
APM liefert:
-
Performance-Traces auf Code-Ebene
-
Erkennung langsamer Endpoints/Datenbank-Queries
-
Memory-Leaks & Exception-Tracking
-
End-to-End-Latenz-Analyse
Wenn Ihre Anwendung schnell wächst oder mehrere Microservices umfasst, ist APM nicht optional – es ist überlebenswichtig.
4. Logs – die Quelle der Wahrheit bei Incidents
Wenn etwas kaputtgeht, schauen Engineers zuerst auf die Dashboards … und dann irgendwann in die Logs.
Zentralisiertes Logging beantwortet Fragen wie:
-
Was ist vor dem Crash passiert?
-
Welcher Service hat die Exception geworfen?
-
Hat das Deployment einen Bug eingeführt?
-
Ist es ein Systemproblem oder eine externe Abhängigkeit?
Beispiele für Log-Stacks:
-
ELK (Elasticsearch + Logstash + Kibana) – flexibel, weit verbreitet
-
Grafana Loki – günstiger und skalierbar
-
Graylog, Splunk – Enterprise-Suchfunktionen
-
Cloud-native Logs – GCP Logging, AWS CloudWatch
Logs müssen zentralisiert sein; per SSH auf Servern Logs zu tailen ist ein Problem von 2010.
5. Distributed Tracing – Systemverhalten verstehen
Wenn Requests durch Queues, Services, Loadbalancer und Datenbanken laufen, ist Tracing Ihre Landkarte.
Distributed Tracing hilft beim:
✔ Visualisieren von Request-Pfaden
✔ Identifizieren von Bottlenecks zwischen Microservices
✔ Debuggen von Timeouts, Retries und Fehlern
Standards & Tools:
-
OpenTelemetry (Industriestandard)
-
Jaeger, Zipkin
-
AWS X-Ray / GCP Cloud Trace
Tracing verbindet APM, Logs und Metriken zu einem Gesamtbild eines Incidents.
6. Alerting & Incident-Response
Monitoring ist wertlos ohne handlungsrelevante Alarme. Niemand will Alert-Fatigue, aber Stille während eines Ausfalls ist noch schlimmer.
Ein moderner Alerting-Workflow sollte:
-
Erkennen
-
Die richtige Person benachrichtigen
-
Kontext liefern (Dashboards, Logs)
-
Wenn möglich automatisierte Gegenmaßnahmen auslösen
Alarmkanäle:
-
Slack, Teams, E-Mail
-
PagerDuty / OpsGenie
-
Telegram, SMS
-
Webhooks für Automatisierung
Xitoring-Beispiel:
Bleibt die CPU 10 Minuten lang über 90 %, sendet Xitoring Alarme über Slack und Telegram, hängt System-Metriken an und kann automatisierte Skripte auslösen (z. B. einen Service neu starten oder Pods skalieren).
AIOps & Automatisierung – der Game Changer 2025
Die Entwicklung im Monitoring geht von reaktiv → prädiktiv.
KI kann erkennen:
-
Ungewöhnliche Traffic-Spikes
-
Schleichende Memory-Leaks
-
Latenzveränderungen, bevor Nutzer sie spüren
-
Verhaltensmuster, die zu Ausfällen führen
Plattformen wie Xitoring integrieren bereits KI-basierte Anomalie-Erkennung und ermöglichen:
🔹 automatische Alarme vor Ausfällen
🔹 Vorschläge zu möglichen Ursachen
🔹 automatisierte Recovery-Trigger
Die Zukunft heißt selbstheilende Infrastruktur.
Best Practices für DevOps-Teams 2025
-
Auf Symptome alarmieren, nicht auf Rauschen Ein CPU-Spike allein ist noch kein Problem – ein Spike plus Latenzanstieg schon.
-
Status-Pages nutzen Reduziert die Support-Last und schafft Vertrauen bei Kunden.
-
SLO-/SLI-Metriken erfassen Zuverlässigkeit ist messbar – verbessern lässt sich nur, was man misst.
-
Deployments genau beobachten Die meisten Incidents sind hausgemachte Releases.
-
Monitoring ist kein Projekt. Es ist eine Kultur.
Fazit
Ein perfekter Monitoring-Stack heißt nicht, das teuerste Tool zu kaufen oder die Observability-Pipeline zu überfrachten. Es heißt, Schichten zu kombinieren, die Ihnen Sichtbarkeit von User-Request → Server → Anwendung → Logs → Root Cause geben.
Wenn Sie nur eines mitnehmen:
Monitoring sollte Ihnen nicht nur sagen, dass etwas schiefgelaufen ist – es sollte Ihnen sagen, warum, und wie Sie es schnell beheben.
Egal, ob Sie sich für einen Open-Source-Stack, eine Enterprise-Plattform oder eine vereinheitlichte Lösung wie Xitoring entscheiden, die Uptime- und Server-Monitoring mit KI-Insights kombiniert: Entscheidend ist, dass Sie ein System bauen, dem Ihr Team vertraut und das es täglich nutzt.