Disk Health Überwachung
Überwachen Sie die SMART-Attribute, die Temperatur, neu zugewiesene Sektoren und Indikatoren für drohende Ausfälle von SSDs und HDDs in Echtzeit.
Warum überwachen Sie Disk Health?
Festplattenausfälle gehören zu den Hauptursachen für Datenverluste und ungeplante Ausfallzeiten. Die Festplattenüberwachung von Xitoring nutzt die SMART-Technologie (Self-Monitoring, Analysis, and Reporting Technology), um Sie frühzeitig zu warnen, bevor Festplatten ausfallen. Die Überwachung umfasst SSDs, HDDs und RAID-Konfigurationen sowohl unter Linux als auch unter Windows.
Disk-Health-Monitoring, erklärt
Disk-Health-Monitoring erkennt das Wachstum reallokierter Sektoren, NVMe-Abnutzung, Temperaturspitzen und bevorstehende Ausfallanzeichen Tage oder Wochen, bevor Laufwerke sterben — lang genug, um Daten zu migrieren und das Laufwerk ohne Ausfallzeit zu tauschen. Für Datenbankserver, Backup-Hosts und jeden Workload, bei dem ein Laufwerksausfall Datenverlust bedeutet, ist S.M.A.R.T.-Monitoring der Alert mit dem höchsten ROI, den Sie einrichten können. Xitoring führt smartctl + nvme-cli lokal aus und leitet Alerts an Slack, PagerDuty, Telegram oder Ihre bestehende Rufbereitschaft weiter.
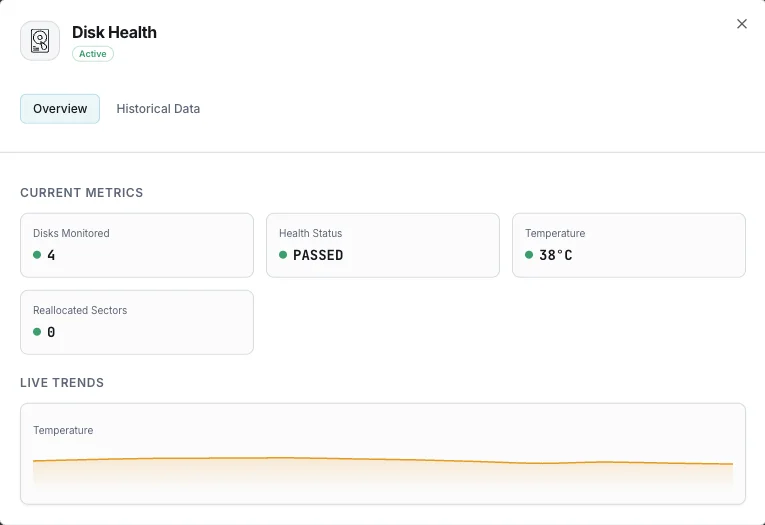
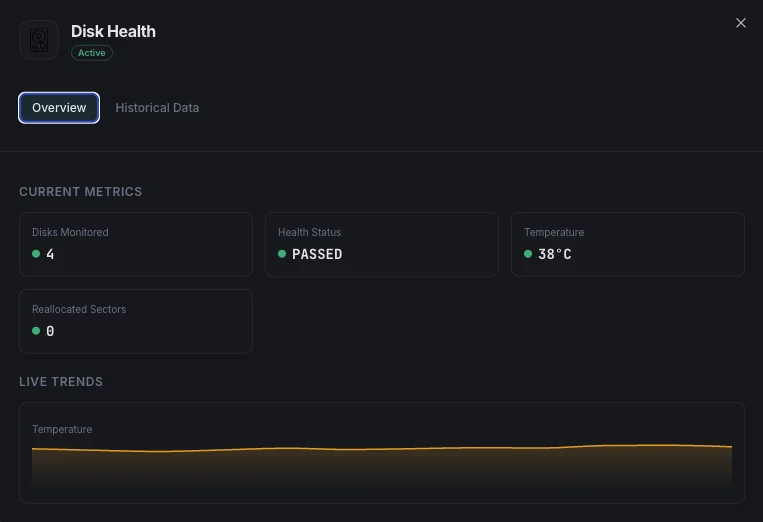
Was wir überwachen
SMART-Gesundheitsstatus
Anzeige für den Gesamtzustand der Festplatte (bestanden/nicht bestanden).
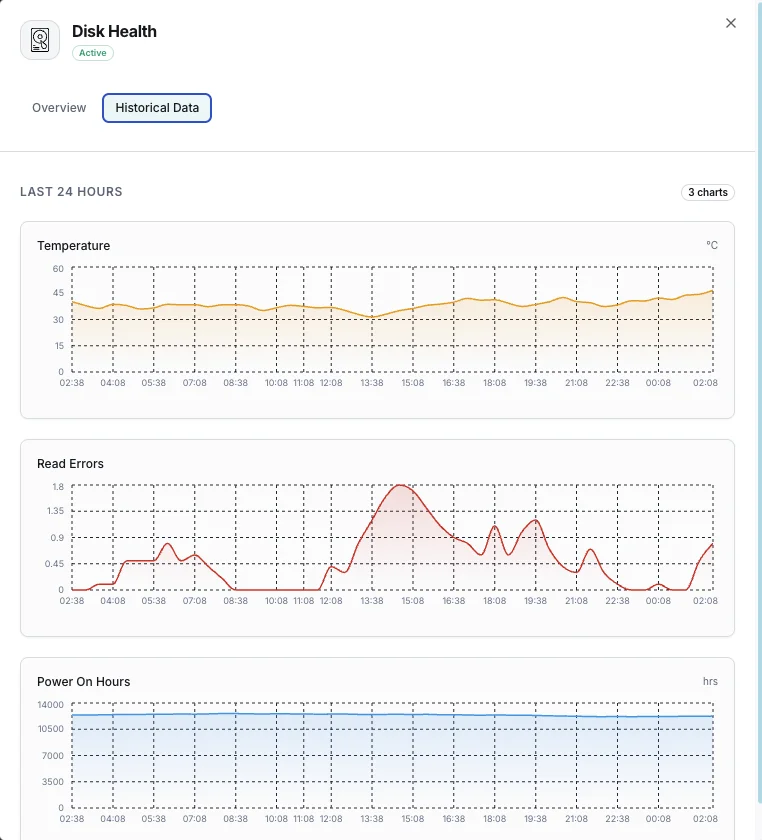
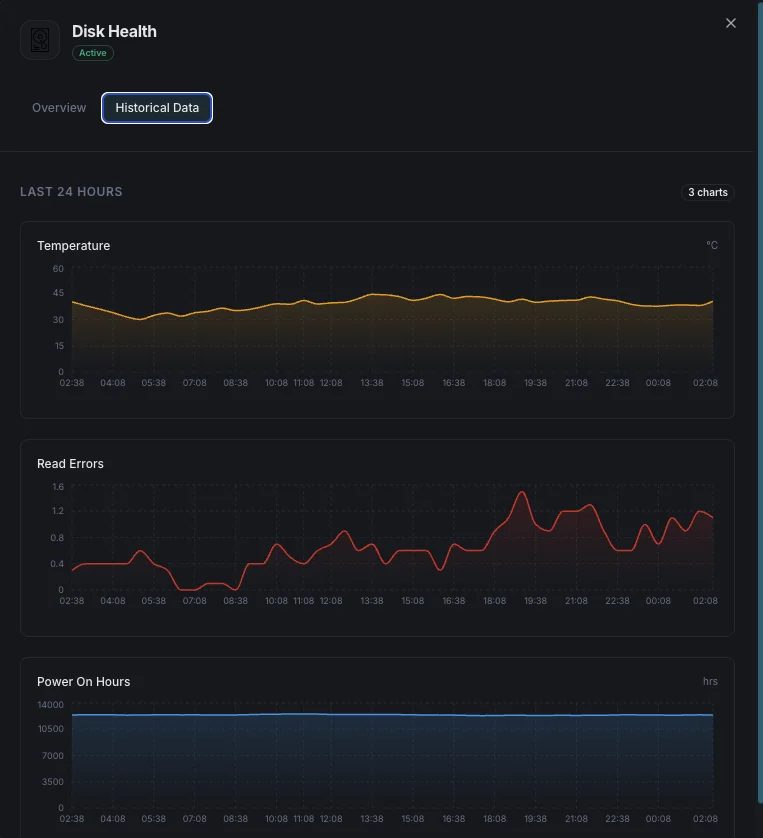
Temperatur
Aktuelle Festplattentemperatur in Grad Celsius.
Neu zugewiesene Sektoren
Anzahl der neu zugewiesenen fehlerhaften Sektoren.
Betriebsstunden
Gesamtbetriebsstunden der Festplatte.
Lesefehlerrate
Anteil der aufgetretenen Lesefehler.
Branchen mit ausstehenden Ergebnissen
Sektoren, die neu zugeordnet werden müssen.
Temperature_Celsius (SMART 194)
Aktuelle Laufwerkstemperatur. HDDs degradieren über 50°C; Consumer-SSDs drosseln über 70°C. Alarmieren Sie beim vom Hersteller angegebenen Maximum minus 10°C als Frühwarnung.
UDMA_CRC_Error_Count (SMART 199)
Kabelbedingte CRC-Fehler auf der SATA-/SAS-Schnittstelle. Steigende Werte deuten auf ein defektes Kabel oder eine lose Verbindung hin — eine einfache Behebung, die oft fälschlich als Laufwerksausfall diagnostiziert wird.
SSD-Verschleiß (Wear_Leveling_Count + Total_LBAs_Written)
SSD-Endurance-Tracking. `Wear_Leveling_Count` normalisiert die verbleibende Lebensdauer; `Total_LBAs_Written` zusammen mit dem TBW-Rating des Laufwerks ergibt den aktuellen Verschleißanteil. Alarmieren Sie bei 80% Nutzung.
NVMe percentage_used
Aus `nvme smart-log` — Herstellerschätzung der verbrauchten Lebensdauer (0–100%, kann bei abgenutzten Laufwerken 100% übersteigen). Warnung über 80%; kritisch über 95%.
NVMe available_spare
Prozent der verbleibenden Reservekapazität für das Ersetzen defekter Blöcke. Warnung unter 10%; kritisch unter 5% (`available_spare_threshold` ist typischerweise dort gesetzt).
NVMe critical_warning
Bitfeld aus `nvme smart-log`, das markiert: Spare unter Schwellenwert, Temperatur über Schwellenwert, Zuverlässigkeit des Geräts degradiert, Read-only-Modus, Backup des flüchtigen Speichers fehlgeschlagen. Jeder Wert ungleich null = sofortiger Alert.
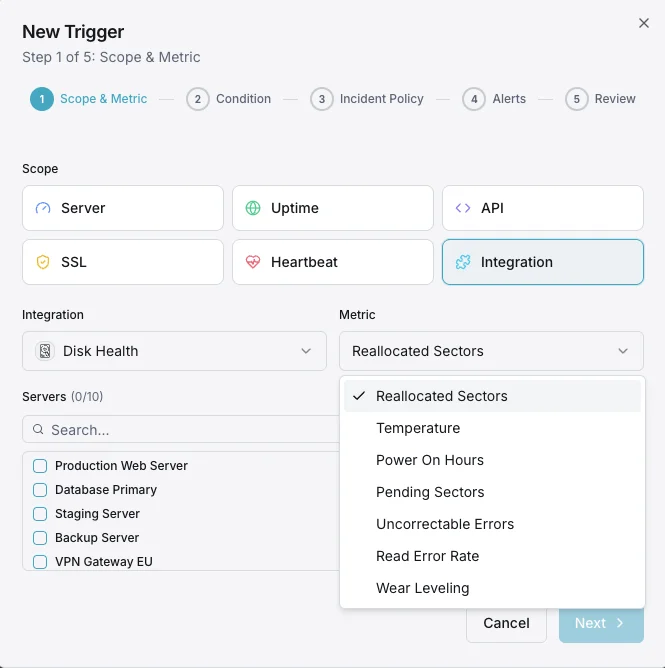
Konfigurierbare Alarmauslöser
Richten Sie benutzerdefinierte Trigger in Ihrem Dashboard ein, um benachrichtigt zu werden, sobald die Kennzahlen von „Disk Health“ Ihre festgelegten Schwellenwerte überschreiten.
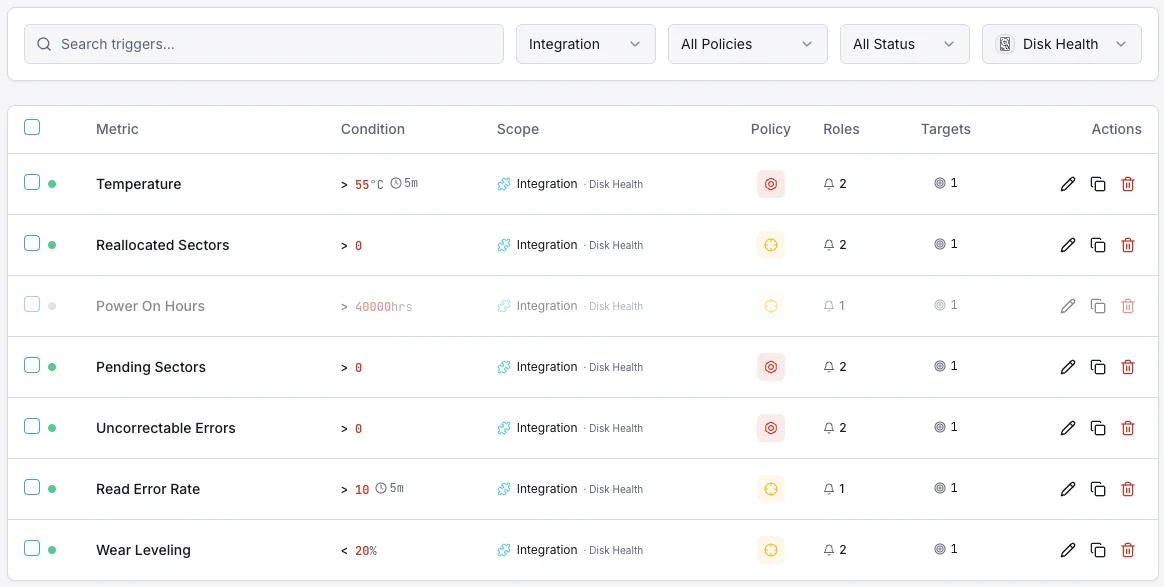
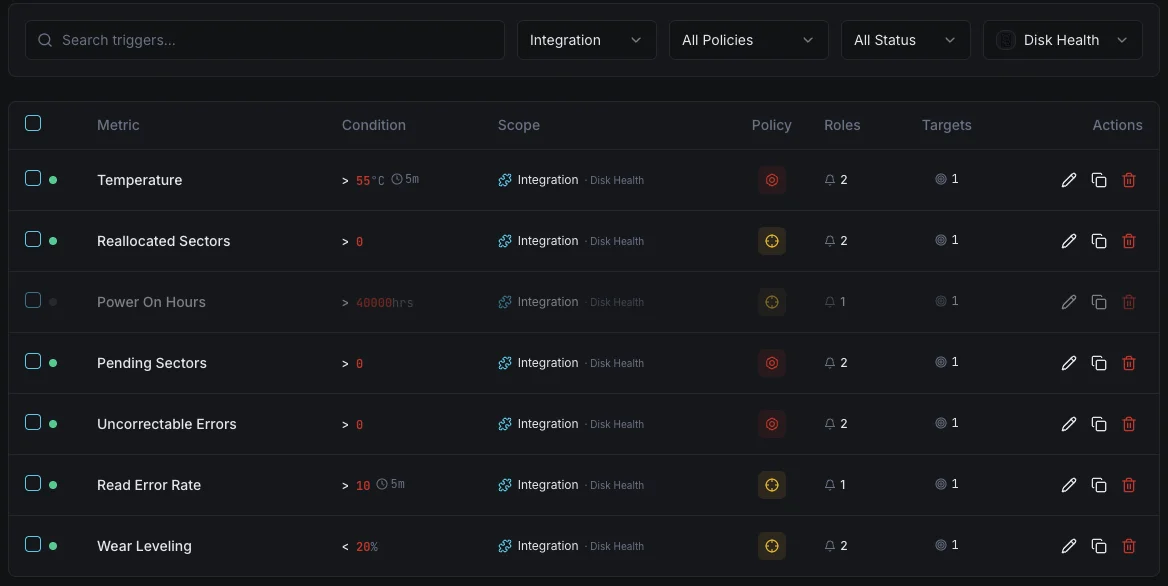
SMART-Gesundheitsstatus
entscheidendWird ausgelöst, wenn SMART einen fehlerhaften Status meldet.
Neu zugewiesene Sektoren
entscheidendWarnung, wenn die Anzahl der neu zugewiesenen Sektoren den Schwellenwert überschreitet.
Festplattentemperatur
WarnungWird ausgelöst, wenn die Festplattentemperatur den sicheren Betriebsbereich überschreitet.
Branchen mit ungewissem Ausgang
WarnungLöst einen Alarm aus, wenn die Anzahl der ausstehenden Sektoren auf einen möglichen Ausfall hindeutet.
Bedeutung von Überwachung des Festplattenzustands
Festplattenausfälle können zu Datenverlusten und kostspieligen Ausfallzeiten führen. Die SMART-Überwachung liefert Frühwarnzeichen – von steigenden Temperaturen über eine zunehmende Anzahl neu zugewiesener Sektoren bis hin zu Spitzenwerten bei Lesefehlern –, sodass Sie Maßnahmen ergreifen können, bevor eine Festplatte ausfällt.
- Verhindern Sie Datenverluste durch frühzeitige Fehlererkennung
- Optimieren Sie die Leistung, indem Sie Engpässe identifizieren
- Kapazitätsplanung mit historischer Trendanalyse
- Sicherstellung der Einhaltung der Vorschriften zur Überwachung der Datenintegrität
Warum sich für uns entscheiden? Xitoring
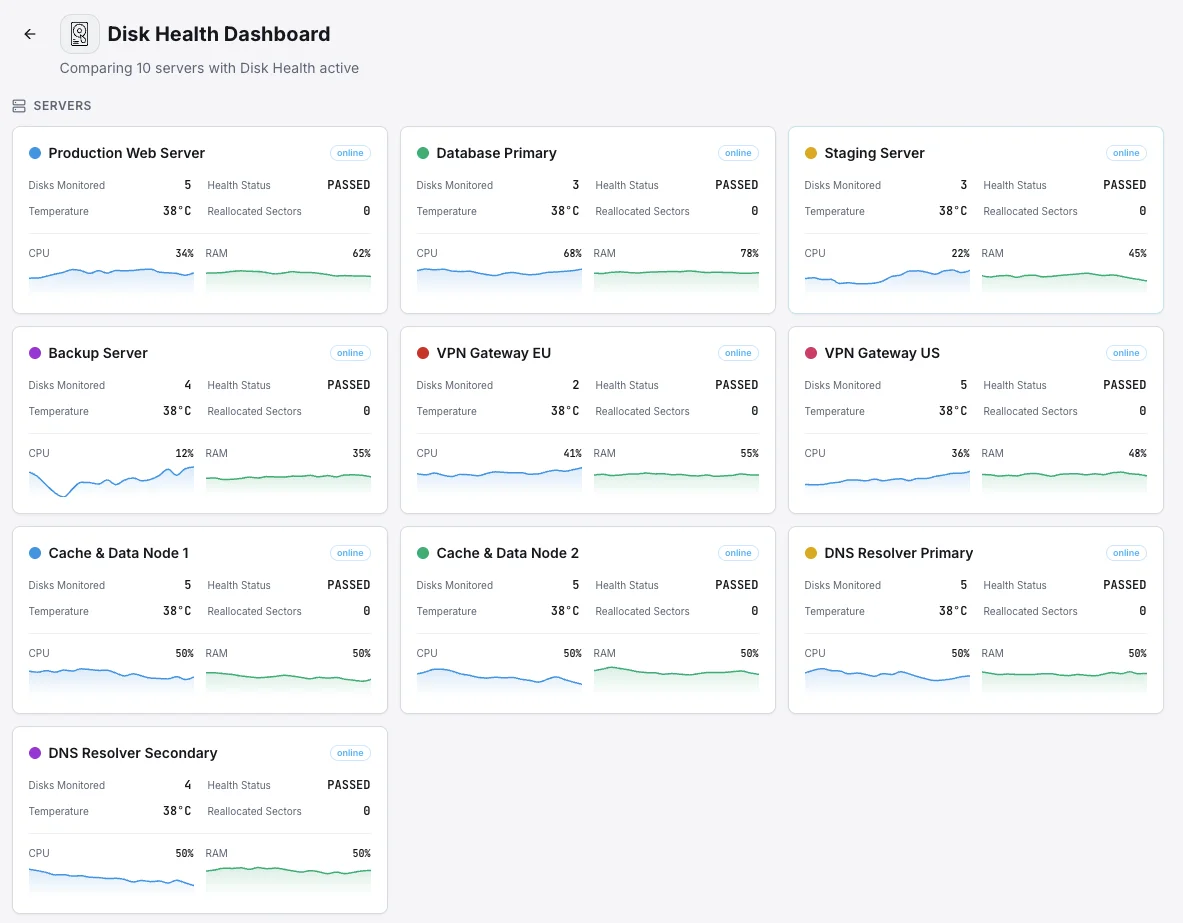
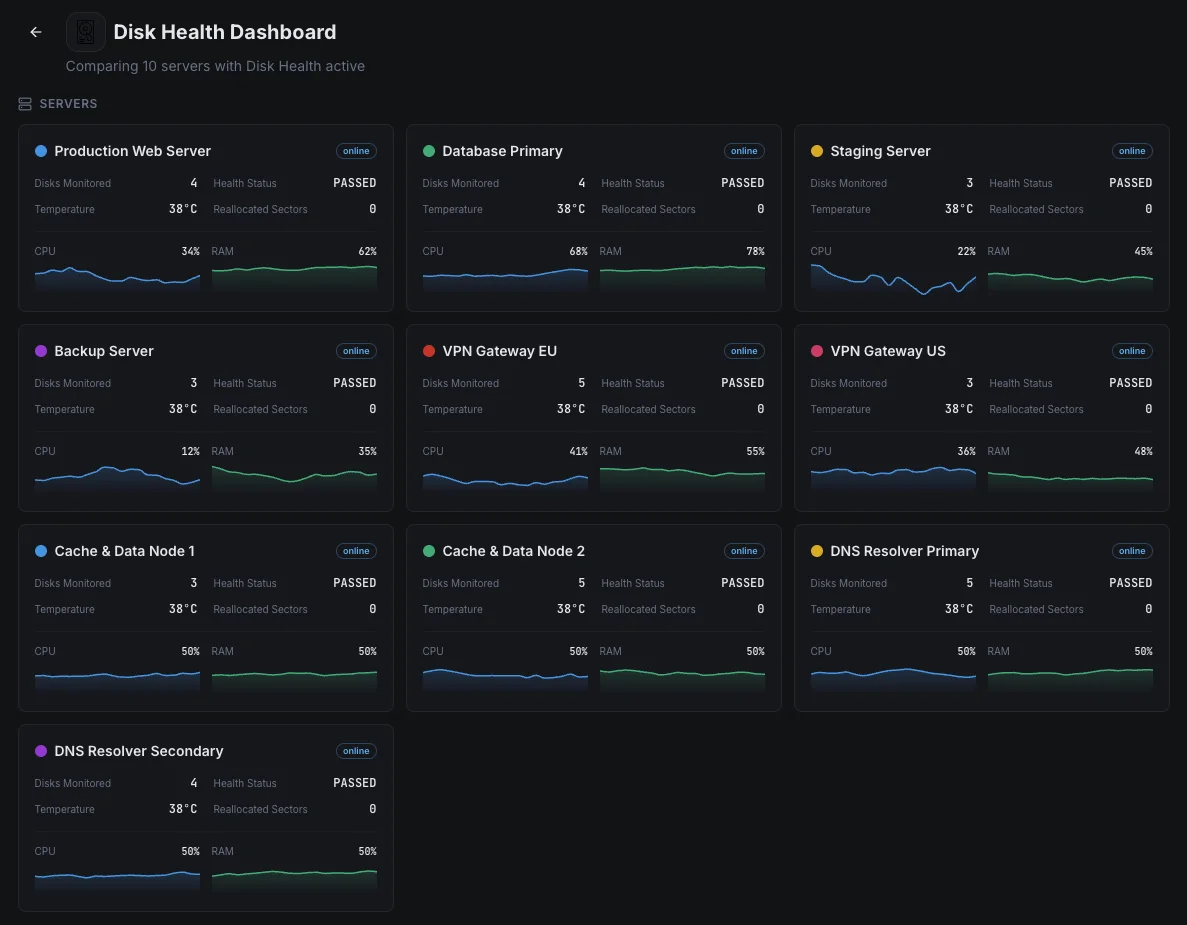
Xitoring bietet eine konfigurationsfreie Überwachung des Festplattenzustands mit SMART-Integration für alle Festplattentypen. Erhalten Sie Echtzeit-Benachrichtigungen, historische Trends und vorausschauende Ausfallindikatoren in einem einheitlichen Dashboard.
- Unterstützt SSDs, HDDs und RAID-Arrays
- Einrichtung mit einem einzigen Befehl unter Linux und Windows
- Anpassbare Schwellenwerte für SMART-Attribute
- Mehrkanal-Benachrichtigung bei kritischen Festplattenereignissen
Häufige Disk-Health-Monitoring- Szenarien
Wo die Festplattenüberwachung Laufwerksausfälle am häufigsten erkennt, bevor sie echten Schaden anrichten.
Datenbankserver
Ein ausgefallenes Laufwerk in einer Datenbank kann Ausfallzeiten, verlorene Bestellungen oder im schlimmsten Fall beschädigte Daten bedeuten. Wir überwachen jedes Laufwerk auf frühe Anzeichen eines Ausfalls, damit das Team eine problematische Festplatte nach eigenem Zeitplan austauschen kann – und nicht mitten in einem Ausfall um 3 Uhr morgens.
Backup- und Archivserver
Das einzigartige Problem bei Backup-Laufwerken ist, dass ein Ausfall unsichtbar bleibt, bis zu dem Tag, an dem Sie das Backup tatsächlich benötigen – dann ist es zu spät. Wir testen jedes Laufwerk nach einem Zeitplan und decken Verschleiß frühzeitig auf, damit Sie niemals nach einem Backup greifen, das nicht vorhanden ist.
Server, die viele Daten schreiben (SSDs)
SSDs haben eine begrenzte Anzahl von Schreibvorgängen, bevor sie verschleißen, und stark frequentierte Datenbanken und datenintensive Anwendungen verbrauchen sie schneller, als die meisten Teams erkennen. Wir verfolgen den Verschleiß in einfachen Prozentangaben, damit Laufwerke rechtzeitig ausgetauscht werden – nicht erst nach einem plötzlichen, nicht wiederherstellbaren Ausfall.
Voraussetzungen für Disk Health
Stellen Sie sicher, dass diese Punkte erfüllt sind — danach ist die Installation eine Sache von 60 Sekunden.
- Linux-Server (Debian/Ubuntu, RHEL/CentOS oder kompatible Distribution)
- Paket smartmontools installiert (smartctl) und lsblk verfügbar
- sudo-/root-Zugriff — SMART-Daten erfordern erhöhte Berechtigungen
Erste Schritte in Minuten
Voraussetzungen installieren (Linux)
Installieren Sie smartmontools, um die SMART-Datenerfassung zu ermöglichen. Stellen Sie sicher, dass lsblk auf Ihrem System verfügbar ist.
# Ubuntu/Debian
sudo apt-get install smartmontools
# CentOS/RHEL
sudo yum install smartmontoolsDisk-Health-Integration aktivieren
Führen Sie den integrate-Befehl aus und wählen Sie Disk Health. Xitogent erkennt Ihre Festplatten automatisch und beginnt mit der SMART-Datenerfassung. Unter Windows sind keine Voraussetzungen erforderlich.
xitogent integrateFunktion überprüfen
Führen Sie diesen Befehl auf dem Server aus, um zu bestätigen, dass Xitogent die Integration erkannt hat. Innerhalb von etwa 30 Sekunden werden frische Metriken in Ihr Dashboard gestreamt.
sudo xitogent statusErwägen Sie Alternativen?
Sehen Sie, wie sich Xitoring gegen die Alternativen für Disk Health-Monitoring schlägt — Pauschalpreise, tiefere Integrationen und ein Agent, der Ihren gesamten Stack abdeckt.



Häufig gestellte Fragen
Welche Festplattentypen werden unterstützt?
Muss ich zusätzliche Software installieren?
Kann ich NVMe-Laufwerke überwachen?
Wie oft werden Kennzahlen erfasst?
Welche SMART-Attribute sagen Laufwerksausfälle voraus?
Wie überwache ich die Gesundheit von NVMe-Laufwerken?
Wie überwache ich die Disk-Health unter Windows?
Wie oft sollte ich smartctl-Self-Tests ausführen?
Funktioniert dies mit RAID-Arrays?
Disk Health überwachen heute
In weniger als 60 Sekunden eingerichtet. Keine Kreditkarte erforderlich. Umfassende Kennzahlen vom ersten Tag an.
Kostenlose Testversion starten