Apache Kafka Überwachung
Überwachen Sie den Zustand von Apache Kafka-Brokern, Partitionsverzögerungen, Verbrauchergruppen und den Durchsatz in Echtzeit – ganz ohne Konfiguration.
Warum überwachen Sie Apache Kafka?
Apache Kafka ist das Rückgrat von Echtzeit-Datenpipelines und Event-Streaming. Die Überwachung von Kafka gewährleistet den einwandfreien Betrieb der Broker-Cluster, minimale Verzögerungen bei den Konsumenten, eine optimale Partitionsverteilung und eine zuverlässige Nachrichtenübermittlung.
Kafka-Monitoring, erklärt
Kafka-Monitoring erfasst unterreplizierte Partitionen, Offline-Partitionen, Consumer-Group-Lag-Spitzen, ISR-Shrinks, Controller-Ausfälle und Disk-Druck, bevor sie Datenverlust, Fehler nachgelagerter Microservices oder komplette Broker-Ausfälle verursachen. Für CDC-Pipelines, Event-Sourcing-Systeme, Microservice-Eventing und jeden produktiven Kafka-Cluster ist die Sichtbarkeit pro Broker + pro Consumer-Group das, was einen 60-Sekunden-Alarm auf einen nachlaufenden Consumer von dem Fund eines 50-Millionen-Nachrichten-Backlogs am Ende des Tages unterscheidet. Xitoring erkennt Ihre Broker automatisch, liest JMX MBeans + Consumer-Offsets und leitet Alarme an Slack, PagerDuty, Telegram oder Ihre bestehende Rufbereitschaft.
Was wir überwachen
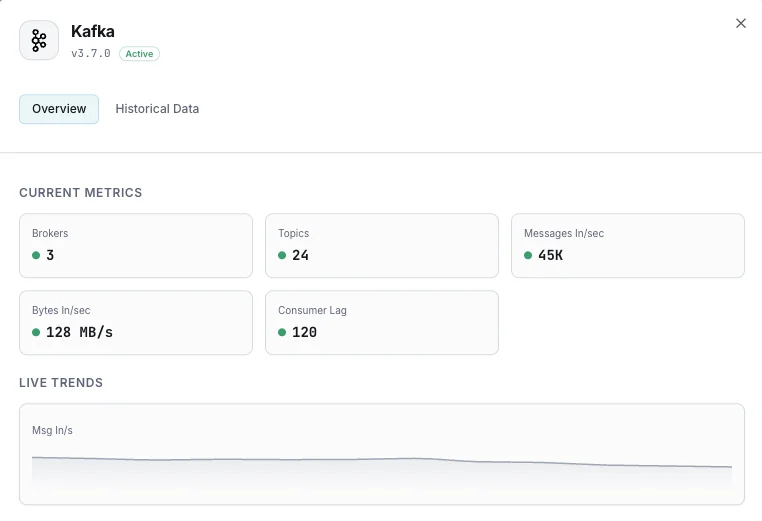
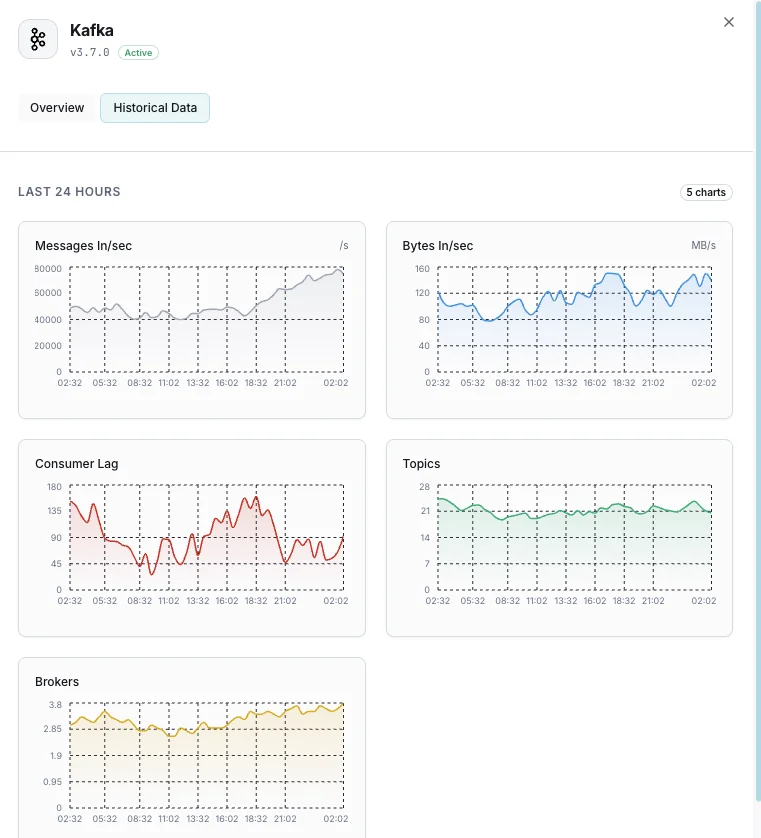
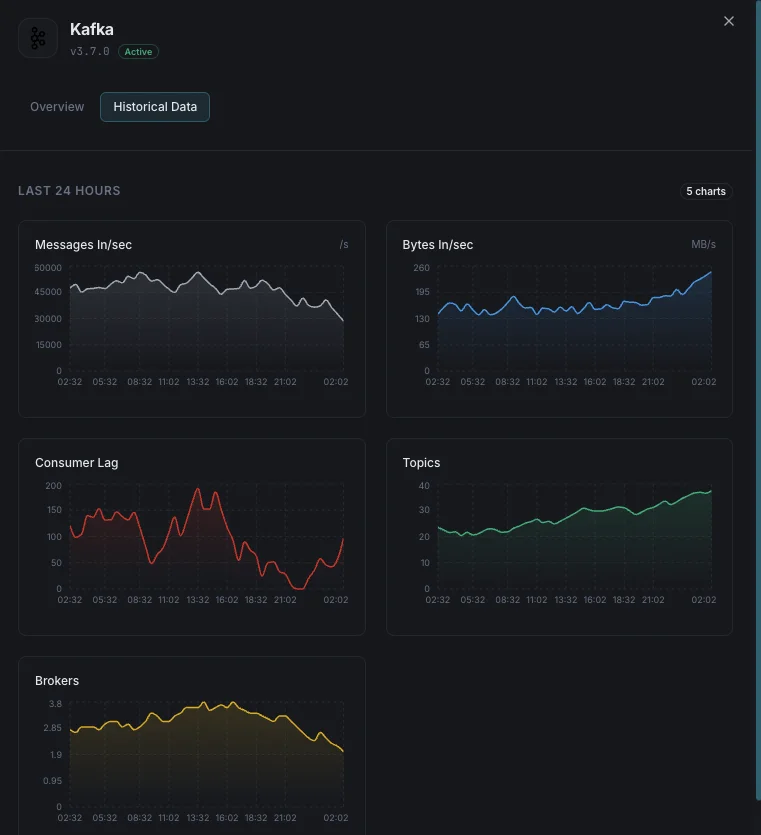
Anzahl Broker
Aktive Broker im Cluster.
Consumer-Lag
Nachrichten-Rückstand je Consumer-Group.
Nachrichten ein/Sek.
Nachrichten-Eingangsrate.
Ein-/Ausgangsbytes
Netzwerkdurchsatz pro Broker.
Unter-replizierte Partitionen
Partitionen unterhalb des Replikationsfaktors.
ISR-Schrumpfungen
Schrumpfungsereignisse von In-Sync-Replicas.
UncleanLeaderElectionsPerSec
Rate, mit der nicht synchrone Replicas zum Leader befördert werden (mit Datenverlust). Sollte 0 sein — ungleich null bedeutet `unclean.leader.election.enable=true` UND ein tatsächlicher Fehlerfall ist eingetreten.
MessagesInPerSec / BytesIn / BytesOut
Durchsatz pro Broker und pro Topic. Plötzliche Rückgänge bei stabiler Producer-Anzahl = Ingest-Problem; plötzliche Spitzen = Retry-Sturm oder ausufernder Producer.
Request-Latenz (p99)
p99 der Produce-, Fetch-, Metadata-Request-Handler-Zeit aus `kafka.network:type=RequestMetrics`. Erkennt Broker-Überlast, bevor sie Timeouts auf Client-Seite verursacht.
LeaderCount pro Broker
Partition-Leader pro Broker. Ungleiche Verteilung (ein Broker hält 60 %+ der Leader) = unausgeglichener Cluster, beheben mit `kafka-reassign-partitions.sh` oder.
Log-Größe pro Topic
Aggregierte On-Disk-Log-Größe pro Topic aus `kafka.log:type=Log,name=Size`. Treibt Disk-Space-Alarme und informiert Tiered-Storage-Policies in Kafka 3.8+.
RemoteLogManager (Tiered Storage)
Kafka-3.8+-Tiered-Storage-Metriken: in den Remote-Tier hochgeladene Bytes, Segmente in Remote vs. lokal, Fetch-Latenz aus Remote. Erkennt S3-Konnektivitäts-/IAM-Probleme, die Tiered-Fetches brechen.
Konfigurierbare Alarmauslöser
Richten Sie benutzerdefinierte Trigger in Ihrem Dashboard ein, um benachrichtigt zu werden, sobald die Kennzahlen von „Apache Kafka“ Ihre festgelegten Schwellenwerte überschreiten.
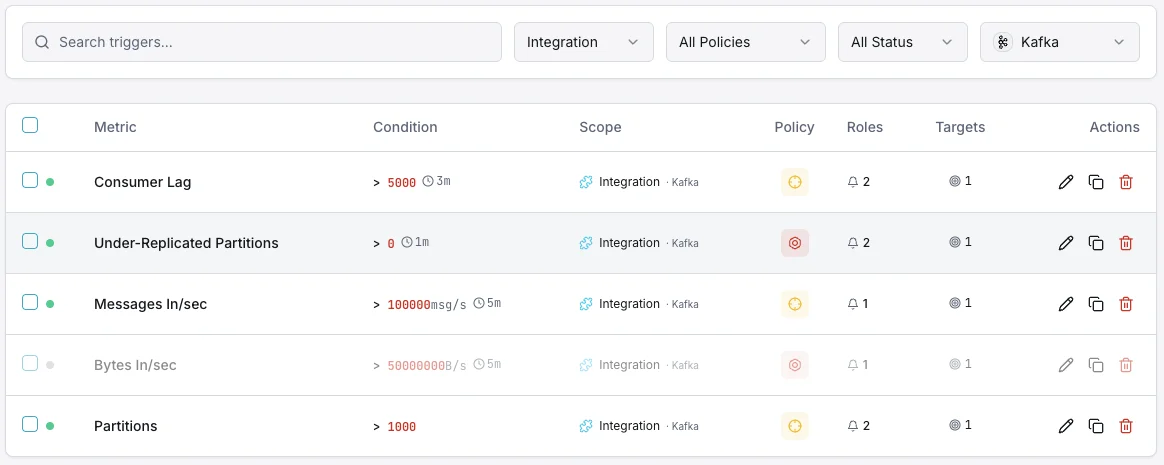
Consumer-Lag
entscheidendWird ausgelöst, wenn ein Consumer zurückfällt.
Unter-replizierte Partitionen
entscheidendWarnungen bei Replikationsproblemen.
Broker ausgefallen
entscheidendWird ausgelöst, wenn ein Broker den Cluster verlässt.
Festplattenbelegung
WarnungWird ausgelöst, wenn die Broker-Festplatte volläuft.
Bedeutung von Kafka-Überwachung
Kafka verarbeitet täglich Billionen von Nachrichten. Consumer-Lag, Broker-Ausfälle und Partitions-Ungleichgewicht können Datenpipelines zum Ausfall bringen.
- Consumer-Lag vor Datenverlust erkennen
- ISR zur Sicherung der Datenhaltbarkeit überwachen
- Broker-Zustand über Cluster hinweg verfolgen
- Partitionsbalance sicherstellen
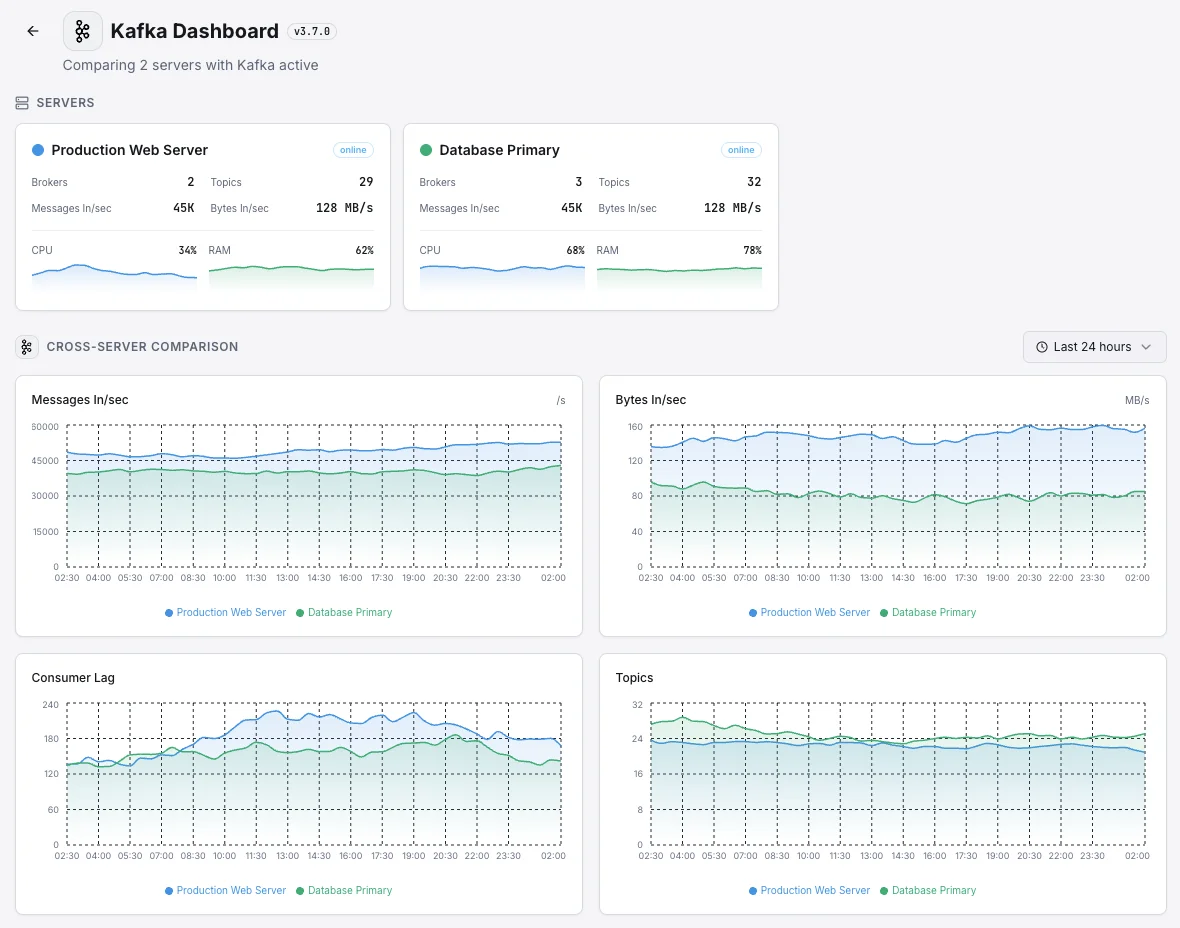
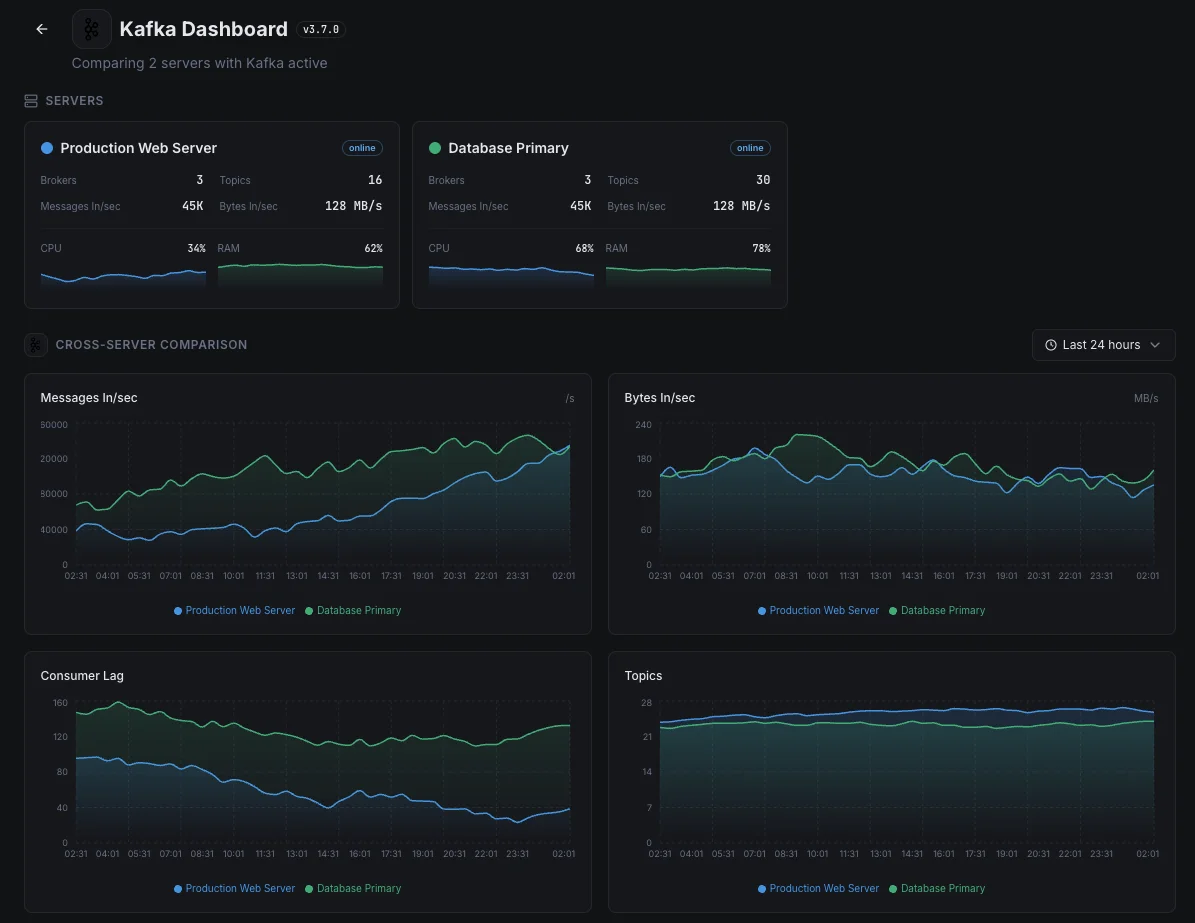
Warum entscheiden Sie sich für Xitoring
Kafka-Überwachung auf Enterprise-Niveau.
- Zero-Config-Setup
- Globale Knoten
- Zentrales Dashboard
- Benachrichtigungen über mehrere Kanäle
- Aufbewahrungsfristen
Häufige Kafka-Monitoring- Szenarien
Wo Kafka heute typischerweise läuft – und was schiefgehen könnte, wenn niemand aufpasst.
Das Messaging-Backbone, das Ihre Apps verbindet
Wenn Kafka die Nachrichten transportiert, die Daten zwischen Ihren Apps bewegen, bedeutet jede Verlangsamung, dass eine App im Stillen zurückfällt – und die Folgen (verzögerte Updates, veraltete Daten, unterbrochene Workflows) zeigen sich erst später. Wir erkennen die Verzögerung in dem Moment, in dem sie beginnt, damit sie niemals zu einem für Kunden sichtbaren Problem wird.
Kafka läuft in Kubernetes
Wenn Kafka in Kubernetes läuft, verschiebt die Plattform es ständig – und ein routinemäßiger Neustart kann das Sicherheitsnetz, das Ihre Daten schützt, kurzzeitig schwächen. Wir überwachen jeden Neustart und jede Neuausrichtung, damit ein normales Update das System nicht unbemerkt einen Fehler von Datenverlust entfernt zurücklassen kann.
Selbstverwaltetes Kafka für große Datenmengen
Unternehmen, die ihr eigenes Kafka in großem Maßstab betreiben, benötigen es felsenfest – es transportiert normalerweise die wertvollsten Daten, die sie haben. Wir überwachen die Signale, die es gesund halten, damit das Team sich auf die Entwicklung von Produkten konzentrieren kann, anstatt die Messaging-Schicht zu bekämpfen.
Voraussetzungen für Apache Kafka
Stellen Sie sicher, dass diese Punkte erfüllt sind — danach ist die Installation eine Sache von 60 Sekunden.
- Kafka-Broker mit aktiviertem JMX (Standardport 9999)
- Netzwerkerreichbarkeit von Xitogent zu jedem JMX-Port der Broker
- JMX-Authentifizierungsanmeldedaten, falls Security konfiguriert ist
Erste Schritte in Minuten
Xitogent auf jedem Broker installieren
Installieren Sie den ressourcenschonenden Xitogent-Monitoring-Agenten auf jedem Kafka-Broker, den Sie überwachen möchten.
curl -s https://xitoring.com/install.sh | sudo bash -s -- --key=YOUR_API_KEYJMX auf jedem Broker aktivieren
Kafka stellt Broker-Metriken über JMX bereit. Setzen Sie `KAFKA_JMX_OPTS`, um einen JMX-Listener (typischerweise Port 9999) auf jedem Broker zu aktivieren, laden Sie den Dienst neu und prüfen Sie, dass der Agent-Host den JMX-Port erreichen kann.
sudo xitogent integrateKafka-Integration aktivieren
Aktivieren Sie die Kafka-Integration über das Xitoring-Dashboard oder die CLI. Xitogent erkennt Broker-IDs, Topics und Consumer-Groups im Cluster automatisch.
Alarmschwellen konfigurieren (optional)
Legen Sie eigene Schwellenwerte für Consumer-Lag, unterrepublizierte Partitionen oder Broker-Down-Ereignisse fest, um Replikationsprobleme und Rückstau zu erkennen, bevor Consumer zurückfallen.
Funktion überprüfen
Führen Sie diesen Befehl auf dem Server aus, um zu bestätigen, dass Xitogent die Integration erkannt hat. Innerhalb von etwa 30 Sekunden werden frische Metriken in Ihr Dashboard gestreamt.
sudo xitogent statusErwägen Sie Alternativen?
Sehen Sie, wie sich Xitoring gegen die Alternativen für Apache Kafka-Monitoring schlägt — Pauschalpreise, tiefere Integrationen und ein Agent, der Ihren gesamten Stack abdeckt.



Häufig gestellte Fragen
Kafka-Versionen?
ZooKeeper oder KRaft?
Was sind unterreplizierte Partitionen und wie behebe ich sie?
Wie überwache ich Kafka-Broker-JMX-Metriken mit Prometheus?
Was ist der KRaft-Modus und wie ändert sich das Monitoring ohne ZooKeeper?
Wie erkenne ich Kafka-Offline-Partitionen?
Wie überwache ich einen Kafka-Cluster auf Kubernetes (Strimzi)?
Kafka vs. Redpanda Monitoring — was ist anders?
Welche Kafka-Versionen werden unterstützt?
Apache Kafka überwachen heute
In weniger als 60 Sekunden eingerichtet. Keine Kreditkarte erforderlich. Umfassende Kennzahlen vom ersten Tag an.
Kostenlose Testversion startenEntdecke weiter