Rilevamento Anomalie &
Analisi della Causa Principale
Xitoring impara cosa sia la normalità su ogni host e metrica, quindi ti avvisa nel momento in cui il comportamento devia — prima che una soglia statica si attivi. Quando si verifica un incidente, l'analisi della causa principale assistita dall'IA indica direttamente la causa.
Prova Sociale
Scelto da migliaia di utenti — valutato su
Scopri cosa dicono gli utenti reali di Xitoring sulle principali piattaforme di recensioni del mondo.
Cos'è il rilevamento delle anomalie?
Il rilevamento delle anomalie è l'uso di tecniche statistiche e di machine learning per identificare punti dati, eventi o tendenze in un flusso di metriche che deviano significativamente da ciò che è previsto. Nel monitoraggio dell'infrastruttura, sostituisce le fragili soglie statiche con modelli adattivi che apprendono il ritmo normale di ogni sistema — ore di punta, cali del fine settimana, finestre di batch — e segnalano i momenti in cui il comportamento cambia. Ciò offre agli operatori la possibilità di indagare su derive lente e cambiamenti di pattern molto prima che una soglia fissa si attivi.
Chiave Caratteristiche
Tutto ciò che ti serve per Rilevamento Anomalie & Analisi della Causa Principale.
Rilevamento Predittivo con IA
Il machine learning monitora ogni metrica per individuare schemi insoliti — derive lente, passi improvvisi, glitch periodici — e solleva un avviso soft prima che si attivino gli avvisi basati su soglia.
Gestione della Causa Principale
Quando si verifica un incidente, l'IA correla metriche, deployment, avvisi ed eventi host per indicare la probabile causa. Niente più war room di 45 minuti alla ricerca del trigger.
Baselines Apprese Automaticamente
Non è necessario impostare soglie per ogni host. Xitoring crea baselines per host e per metrica che tengono conto automaticamente dei modelli giornalieri, settimanali e stagionali.
Correlazione Multi-Segnale
Le anomalie raramente si manifestano in un solo punto. L'IA correla CPU, memoria, disco, rete, tempo di risposta ed eventi di servizio per individuare la vera storia.
Ridurre la Fatica da Avvisi
Le soglie statiche o si attivano troppo spesso o mancano problemi reali. Il rilevamento adattivo riduce il rumore sopprimendo i comportamenti attesi e rilevando le deviazioni effettive.
Previsioni di Incidenti
Quando una metrica tende verso una modalità di errore nota — dischi che si riempiono, perdite di memoria, latenza che aumenta — l'IA prevede il tempo all'impatto in modo da poter agire in anticipo.
Trova i Problemi Prima Che Diventino Incidenti
Il Rilevamento Anomalie in Xitoring è più di una soglia intelligente. È un ciclo continuo di IA che impara cosa sia la normalità per ogni metrica su ogni host, segnala le deviazioni non appena iniziano e traccia gli incidenti fino alla causa principale quando si verificano.
- Avvisi predittivi prima degli scatti basati su soglia
- Baselines per host e per metrica apprese automaticamente
- Consapevolezza dei modelli giornalieri, settimanali e stagionali
- Analisi della causa principale assistita dall'IA su ogni incidente
- Correlazione multi-segnale tra CPU, memoria, disco, rete
- Punteggio di gravità per ridurre la fatica da avvisi
- Previsioni del tempo all'impatto per i guasti in tendenza
- Funziona con Slack, PagerDuty, Teams, webhook e altro
- Zero taratura manuale delle soglie
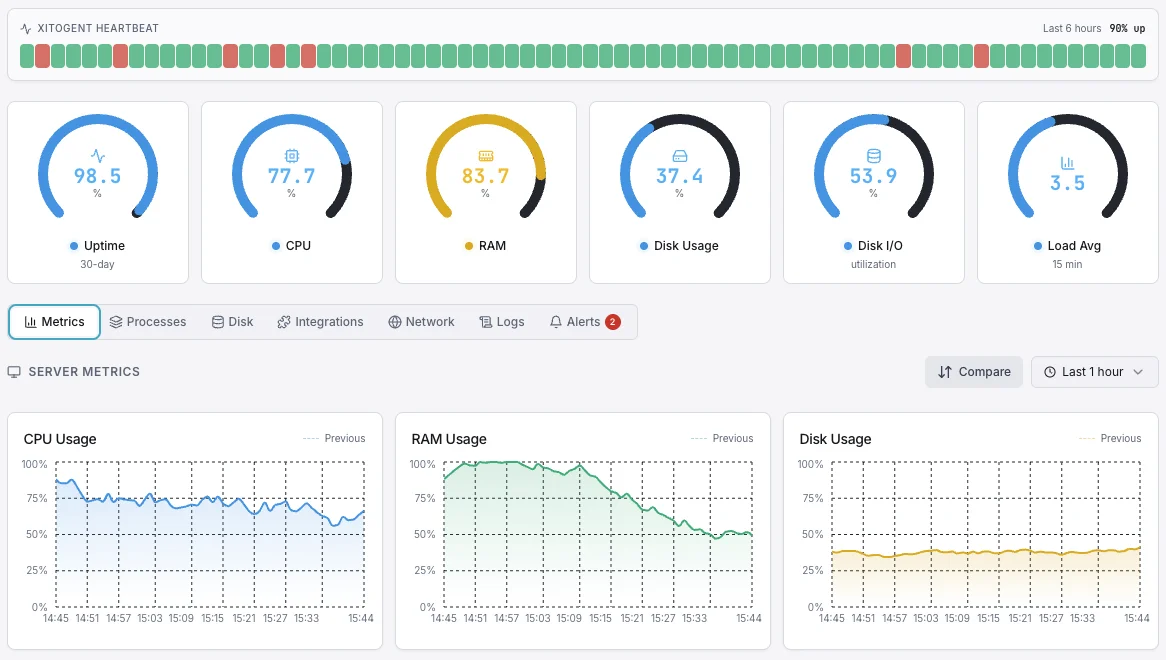
A chi è rivolto
Rilevamento Anomalie Casi d'uso
Scopri come le aziende di diversi settori utilizzano Xitoring per garantire l'affidabilità delle loro infrastrutture.
Flotte Cloud
Le soglie statiche non si adattano a centinaia di istanze AWS, Azure o GCP con carichi di lavoro diversi. Il rilevamento adattivo impara il ritmo di ogni host — nessuna regola per VM da scrivere.
Operazioni su Database
Intercetta regressioni di query lente, derive di replica ed esaurimento del pool di connessioni man mano che i pattern cambiano — molto prima che le metriche di downtime diventino rosse.
Affidabilità E-commerce
Rileva rallentamenti al checkout, derive di latenza dei pagamenti e modelli di abbandono del carrello prima che costino entrate. L'IA vede il calo prima che lo faccia la dashboard.
Piattaforme SaaS
Individua anomalie specifiche del tenant — un carico di lavoro di un cliente che si comporta in modo anomalo, una regione che si degrada — senza scrivere regole di avviso per ogni tenant.
FinTech e Conformità
Rileva schemi di transazione insoliti, picchi di autenticazione e anomalie API che le semplici soglie non rilevano. Documenta ogni rilevamento per le tracce di audit.
Team DevOps e SRE
Trasforma le retrospettive post-incidente in un ciclo più rapido. L'analisi della causa principale indica la modifica, il deployment o il segnale a monte che ha dato il via al problema.
Perché l'Anomalia Rilevamento
Gli avvisi basati su soglie si attivano solo dopo che una metrica ha già superato una linea che avevi stimato mesi fa. Gli incidenti reali iniziano come piccole deviazioni — una lenta perdita di memoria, un aumento di latenza di 50 ms, una coda di checkout che cresce del 2% all'ora. Il Rilevamento delle Anomalie vede queste deviazioni dal primo minuto e ti dà il tempo di agire.
- Individua i problemi prima che gli utenti — e le dashboard — se ne accorgano
- Smetti di scrivere regole di soglia per host che diventano obsolete
- Rileva derive lente che le soglie non attiveranno mai
- Rileva schemi stagionali e del fine settimana che non avevi modellato
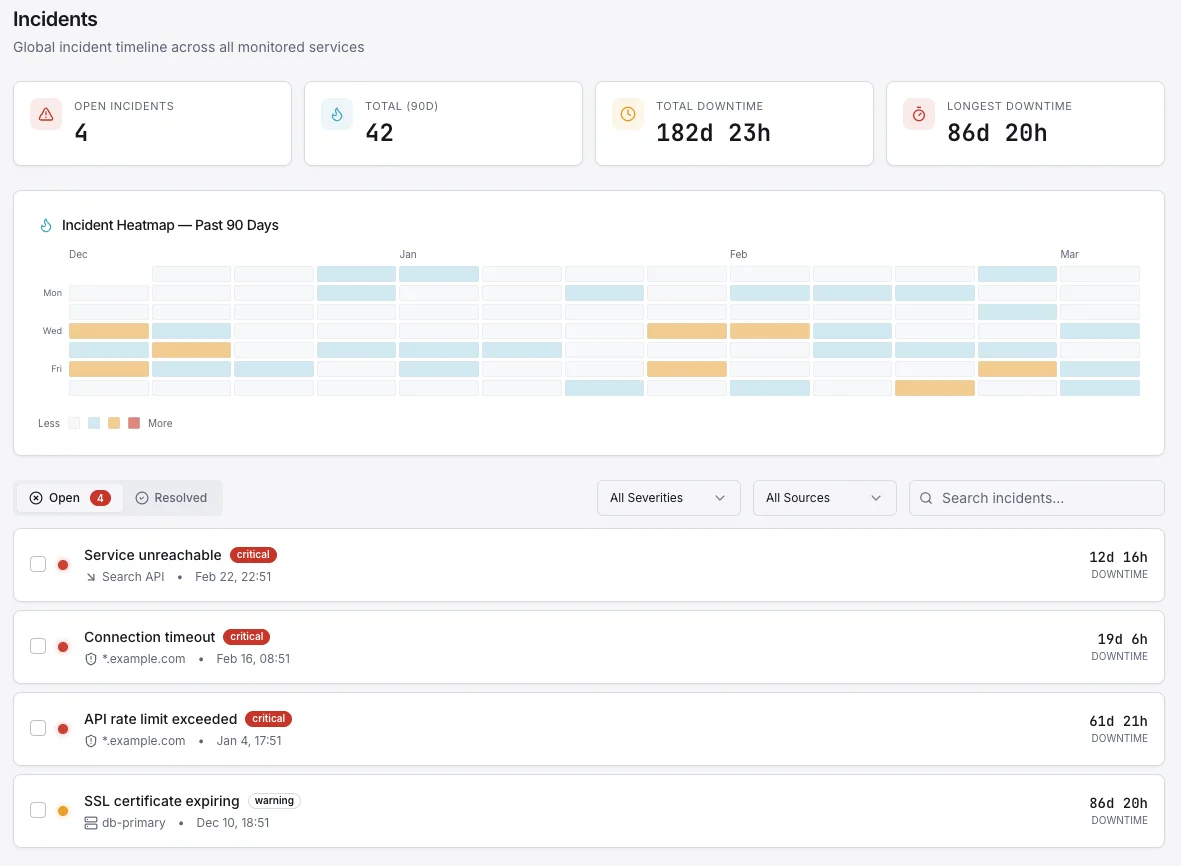
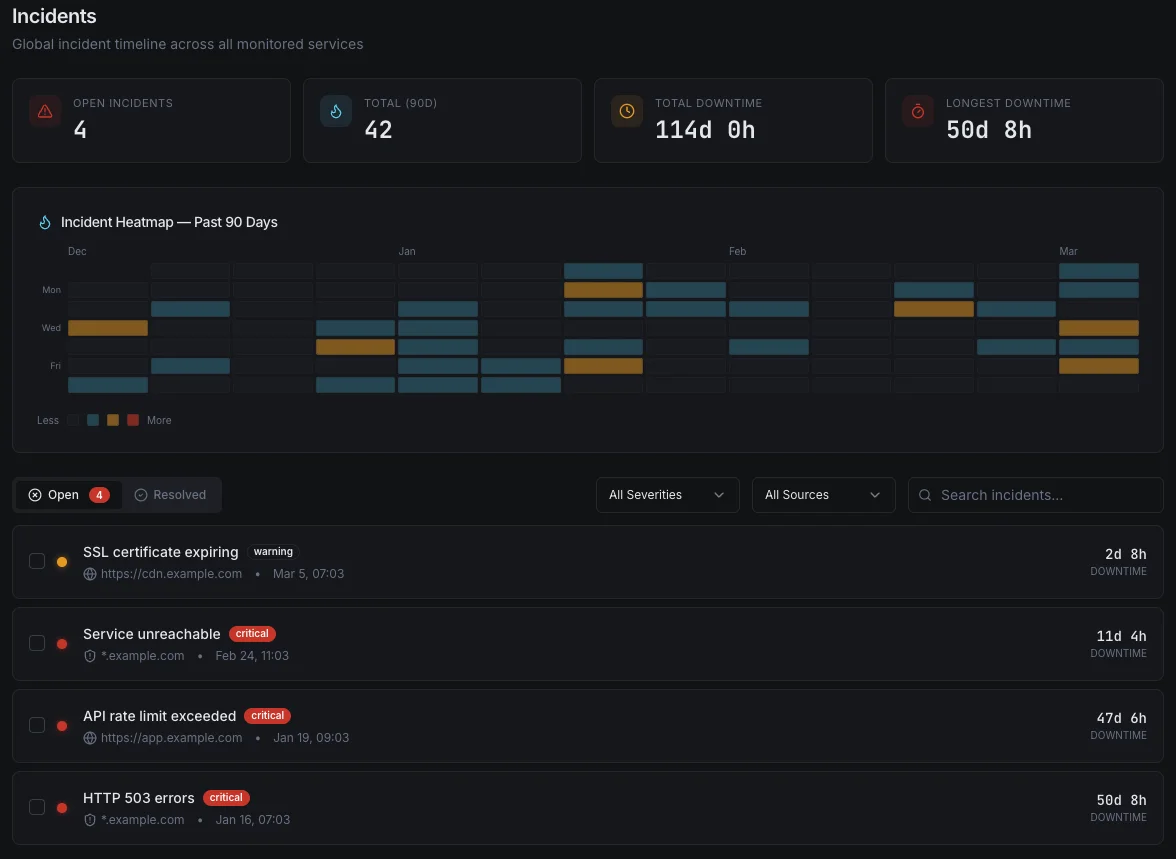
Analisi della Causa Radice, Automatizzata
Quando si verifica un incidente, ogni secondo trascorso a cercare tra le dashboard è un secondo in cui i clienti sentono il disagio. L'IA di Xitoring correla anomalie delle metriche, deployment recenti, eventi di servizio e incidenti storici per indicare la causa probabile — con prove — prima che il tuo reperibile abbia finito di unirsi alla chiamata.
- Correlare CPU, memoria, disco, rete e metriche delle app in pochi secondi
- Rileva deployment recenti e modifiche alla configurazione in prossimità dell'incidente
- Confronta con incidenti storici con impronte simili
- Genera un riepilogo dell'incidente in linguaggio semplice per l'analisi post-mortem
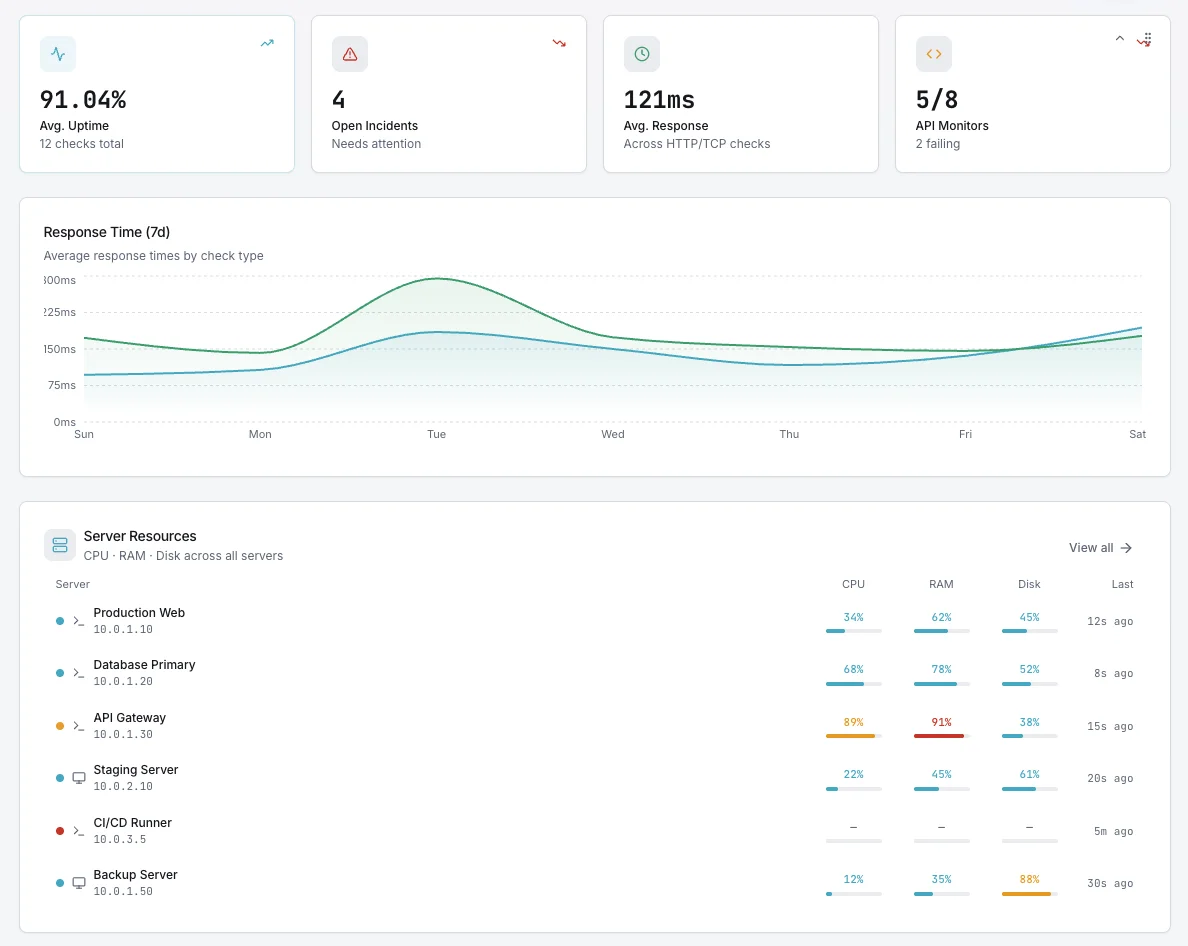
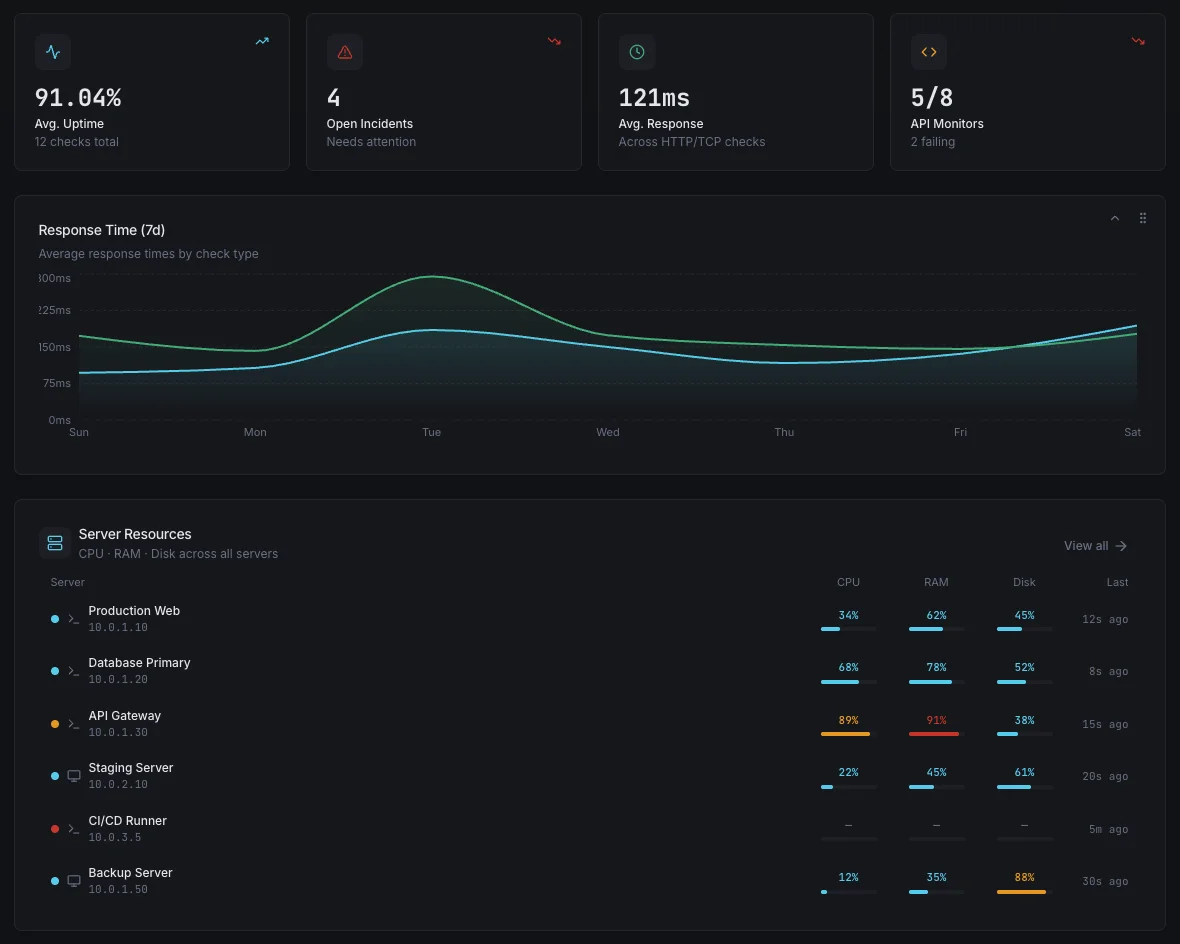
Come Funziona
Nessuna Taratura Manuale
Attivalo per host o a livello di flotta. Le baselines si auto-calibrano durante una finestra di apprendimento — nessuna soglia da discutere, nessuna regola da mantenere man mano che la tua infrastruttura cresce.
Sensibile alla Gravità
Non ogni anomalia è un incidente. I rilevamenti sono classificati per gravità, raggio d'azione e impatto storico, in modo che il personale di guardia venga avvisato solo per segnali reali.
Funziona con i Tuoi Canali
Gli avvisi di anomalia fluiscono attraverso gli stessi canali di notifica dei controlli statici — Slack, email, SMS, PagerDuty, Teams, webhook e oltre 15 altri.
Cerchi strumenti AI?
AIOps — Chiedi qualsiasi cosa alla tua infrastruttura
Il rilevamento delle anomalie monitora eventuali problemi. AIOps ti permette di chiedere informazioni al riguardo. Scopri come l’assistente AI integrato nel pannello di controllo porta le operazioni conversazionali su Xitoring.
Scopri le funzionalità AIOpsVuoi configurare un agente di intelligenza artificiale? Scopri il server MCP
Spesso domande poste
Domande frequenti su Rilevamento Anomalie & Analisi della Causa Principale.
Come funziona il rilevamento delle anomalie di Xitoring?
È solo una soglia intelligente?
Cos'è l'analisi della causa radice?
Ho ancora bisogno di soglie statiche?
Quanto dura il periodo di apprendimento?
Questo aumenterà il volume dei miei avvisi?
Quali metriche supportano il rilevamento delle anomalie?
Questo richiede una configurazione aggiuntiva o un nuovo agente?
In che modo l'abbinamento tra il rilevamento delle anomalie e l'analisi delle cause alla radice consente di ridurre i tempi di risposta agli incidenti?
Smetti di Reagire. Inizia a Prevedere.
Le soglie statiche rilevano i problemi dopo che hanno causato danni. L'IA di Xitoring impara il ritmo di ogni host e rileva comportamenti insoliti prima che gli utenti se ne accorgano. Attivala una volta — gli avvisi diventeranno più intelligenti da quel momento.
Inizia la prova gratuita