CoreDNS Monitoraggio
Monitora in tempo reale la frequenza delle query CoreDNS, la percentuale di cache hit, la latenza di risoluzione e il tasso di errore senza alcuna configurazione.
Perché monitorare CoreDNS?
CoreDNS è il server DNS predefinito per Kubernetes e gli ambienti cloud-native. Il monitoraggio di CoreDNS garantisce una risoluzione DNS rapida, prestazioni ottimali della cache e un rilevamento affidabile dei servizi per la tua infrastruttura.
Monitoring di CoreDNS, spiegato
Il monitoring di CoreDNS intercetta i picchi di SERVFAIL, i cali del cache hit rate, la latenza del plugin forward e i riavvii dovuti a panic prima che si propaghino in fallimenti di risoluzione DNS a livello di cluster. Poiché ogni microservizio dipende dal DNS per la service discovery, un CoreDNS non monitorato è una modalità di guasto non monitorata per l’intero cluster Kubernetes — i problemi di DNS si manifestano come "connection refused casuali" ovunque. Xitoring rileva automaticamente il suo CoreDNS, esegue lo scraping di :9153/metrics e instrada gli alert verso Slack, PagerDuty, Telegram o il suo on-call esistente.
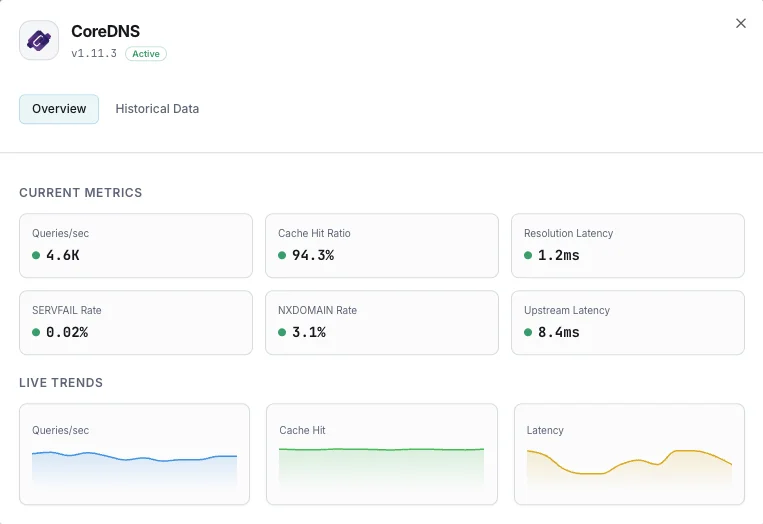
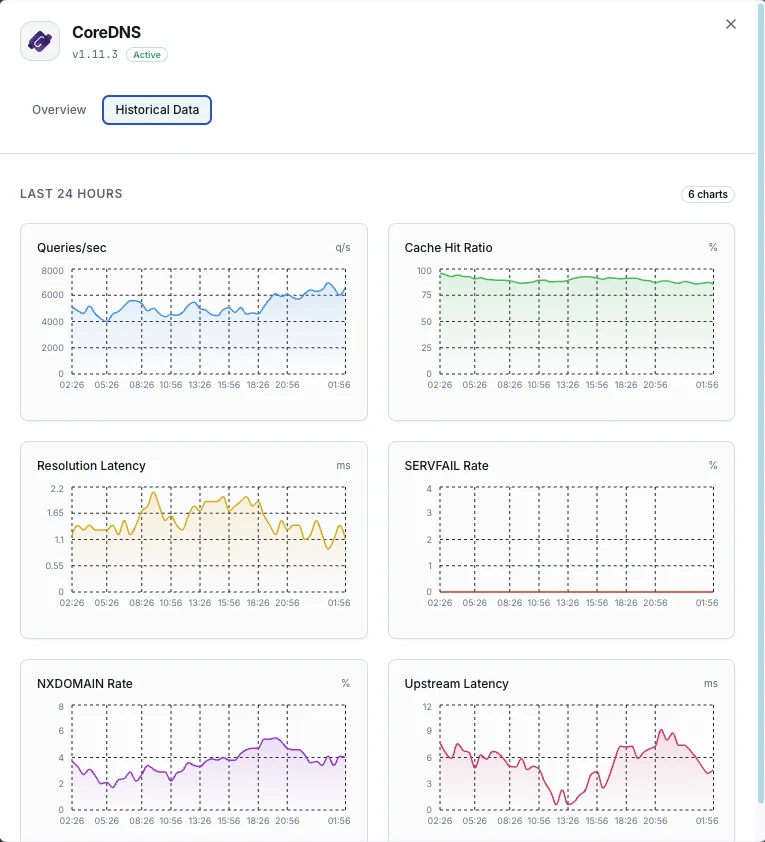
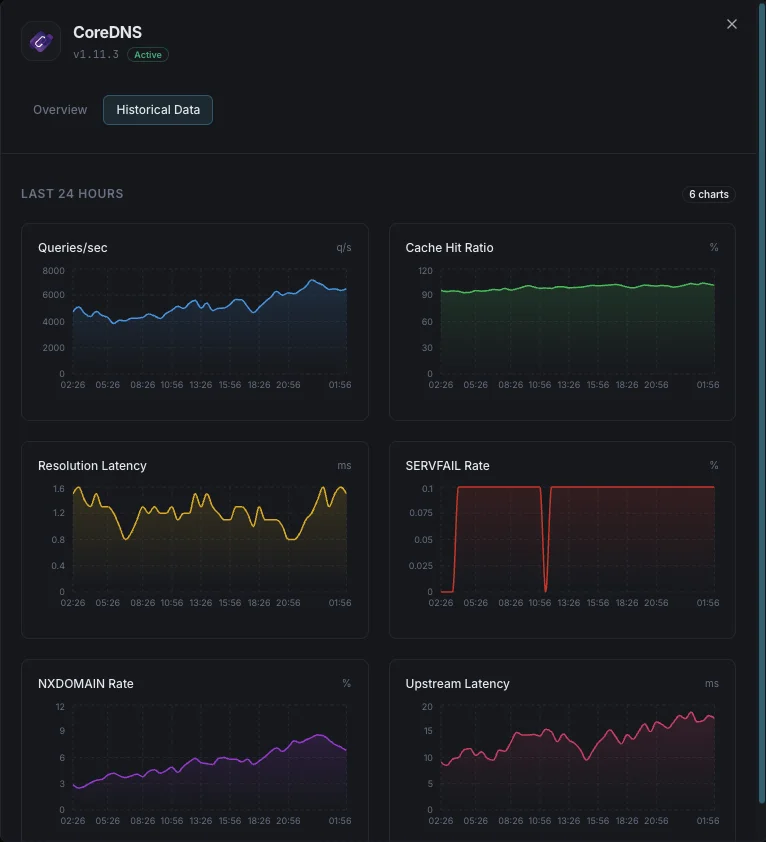
Ciò che monitoriamo
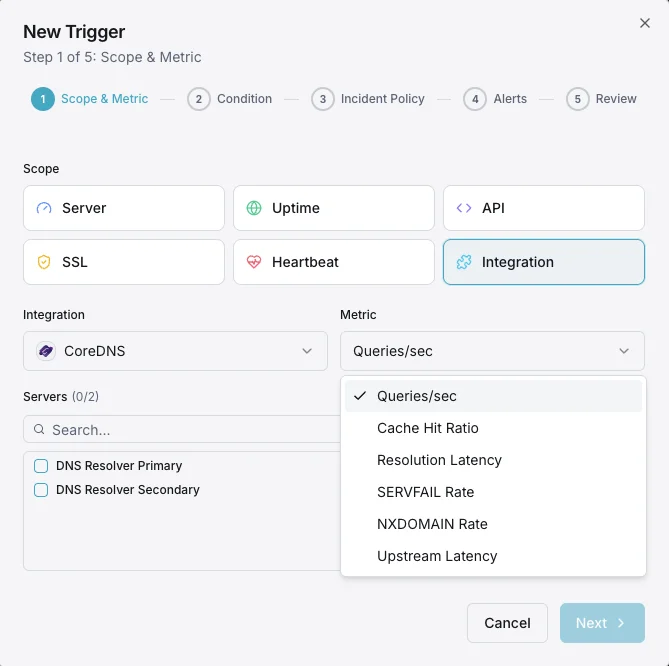
Query/sec
Tasso di query DNS.
Rapporto di cache hit
Percentuale di query servite dalla cache.
Latenza di risoluzione
Tempo medio di risoluzione DNS.
Tasso SERVFAIL
Percentuale di risoluzioni fallite.
Tasso NXDOMAIN
Tasso di query per domini inesistenti.
Latenza upstream
Tempo di risposta delle query inoltrate.
Latenza del plugin Forward
`coredns_forward_request_duration_seconds` per resolver upstream. Separa la latenza interna di CoreDNS da quella del resolver upstream — fondamentale per diagnosticare un 8.8.8.8 lento rispetto a un CoreDNS lento.
Tasso di richieste Forward
`coredns_forward_request_count_total` per upstream. Insieme al cache hit ratio mostra quanto traffico esce effettivamente da CoreDNS per la risoluzione upstream.
Cache delle connessioni Proxy
`coredns_proxy_conn_cache_hits_total` / `_misses_total`. Traccia il riuso delle connessioni TCP verso i resolver upstream — un basso hit rate indica turnover di connessioni, che aumenta la latenza upstream.
Fallimenti del plugin Health
`coredns_health_request_failures_total` — il conteggio dei fallimenti del plugin `health:8080`. Un valore diverso da zero significa che la liveness probe sta fallendo in modo intermittente.
Panic
`coredns_panics_total` — qualsiasi valore diverso da zero indica un bug di CoreDNS o il crash di un plugin che ha causato un panic di una goroutine. Lo abbini al conteggio dei riavvii per il contesto completo del post-mortem.
Runtime Go
`process_resident_memory_bytes` (RSS), `go_goroutines` (conteggio goroutine — rileva leak), `go_gc_duration_seconds` (tempo di pausa GC). Crescita di memoria senza riavvii = leak; crescita del numero di goroutine = plugin o upstream bloccato.
Configurabile condizioni di attivazione
Imposta dei trigger personalizzati nella tua dashboard per ricevere una notifica non appena le metriche dell{name}e superano le soglie da te definite.
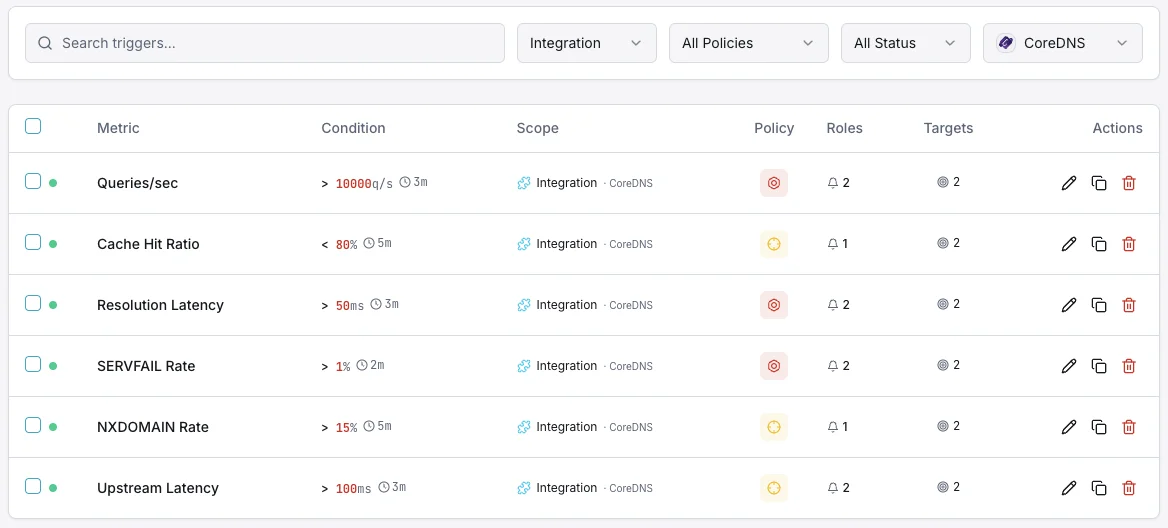
Tasso SERVFAIL
criticoSi attiva in caso di elevato tasso di fallimenti di risoluzione.
Rapporto di cache hit
avvisoAvvisa quando l'efficacia della cache diminuisce.
Latenza di risoluzione
avvisoSi attiva in caso di risoluzione DNS lenta.
Tasso di query
avvisoSi attiva su volumi di query insoliti.
Importanza del monitoraggio CoreDNS
Il DNS è il fondamento della connettività di rete. Una risoluzione DNS lenta o fallimentare impatta su ogni servizio della tua infrastruttura.
- Garantire una risoluzione DNS rapida
- Rilevare immediatamente i picchi di SERVFAIL
- Monitorare la cache per prestazioni ottimali
- Monitorare lo stato dei resolver upstream
Perché scegliere Xitoring
Monitoraggio CoreDNS zero-config.
- Installazione con un solo comando
- Nodi globali
- Dashboard unificata
- Avvisi multicanale
Scenari comuni di monitoring per CoreDNS
Dove viene solitamente eseguito CoreDNS al giorno d'oggi — e cosa potrebbe andare storto se nessuno lo tenesse d'occhio.
Il DNS all'interno di un'applicazione Kubernetes
Ogni componente di un'applicazione Kubernetes utilizza CoreDNS per individuare tutti gli altri componenti. Quando il sistema rallenta o inizia a presentare malfunzionamenti, gli utenti riscontrano strani errori intermittenti in tutta l'applicazione. Rileviamo il rallentamento nel momento stesso in cui si verifica, in modo che un piccolo intoppo nel DNS non si traduca in un misterioso disservizio per i clienti.
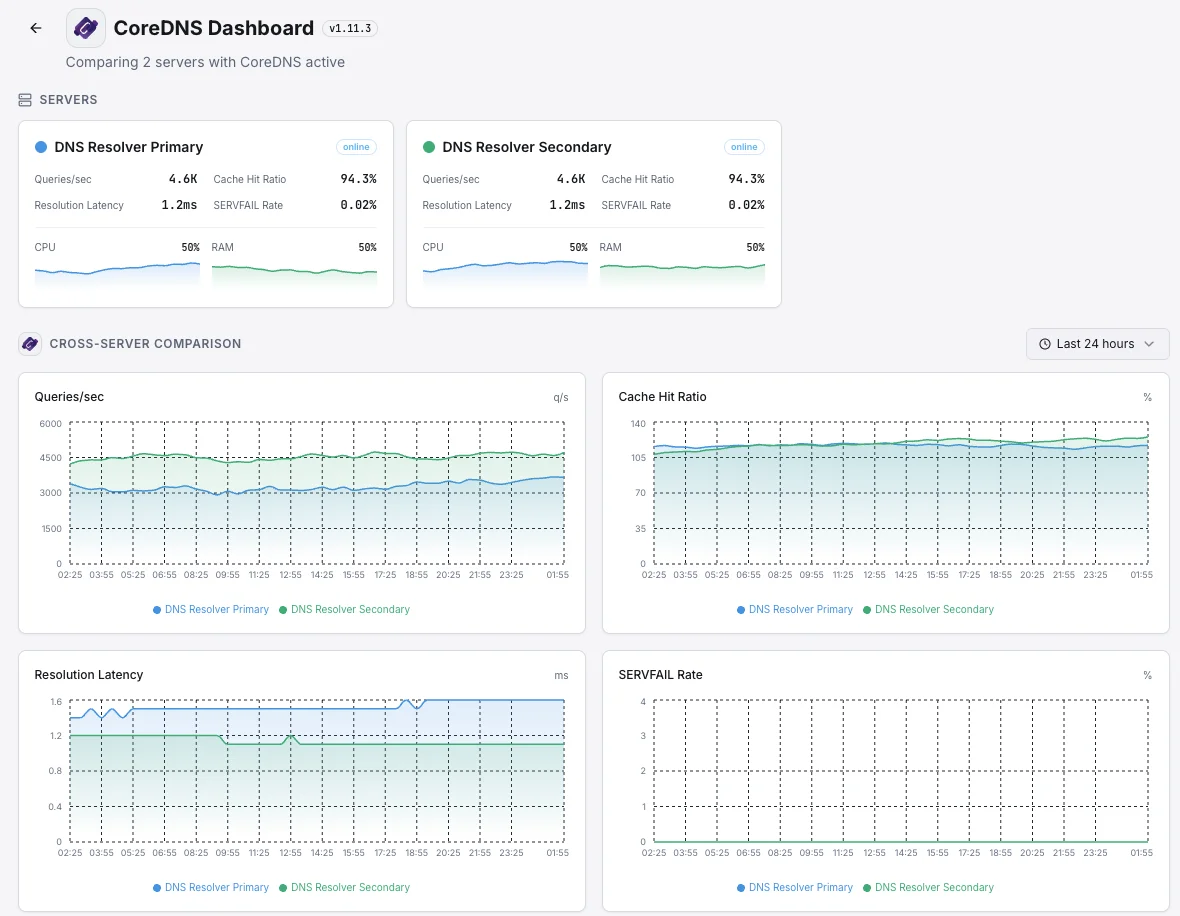
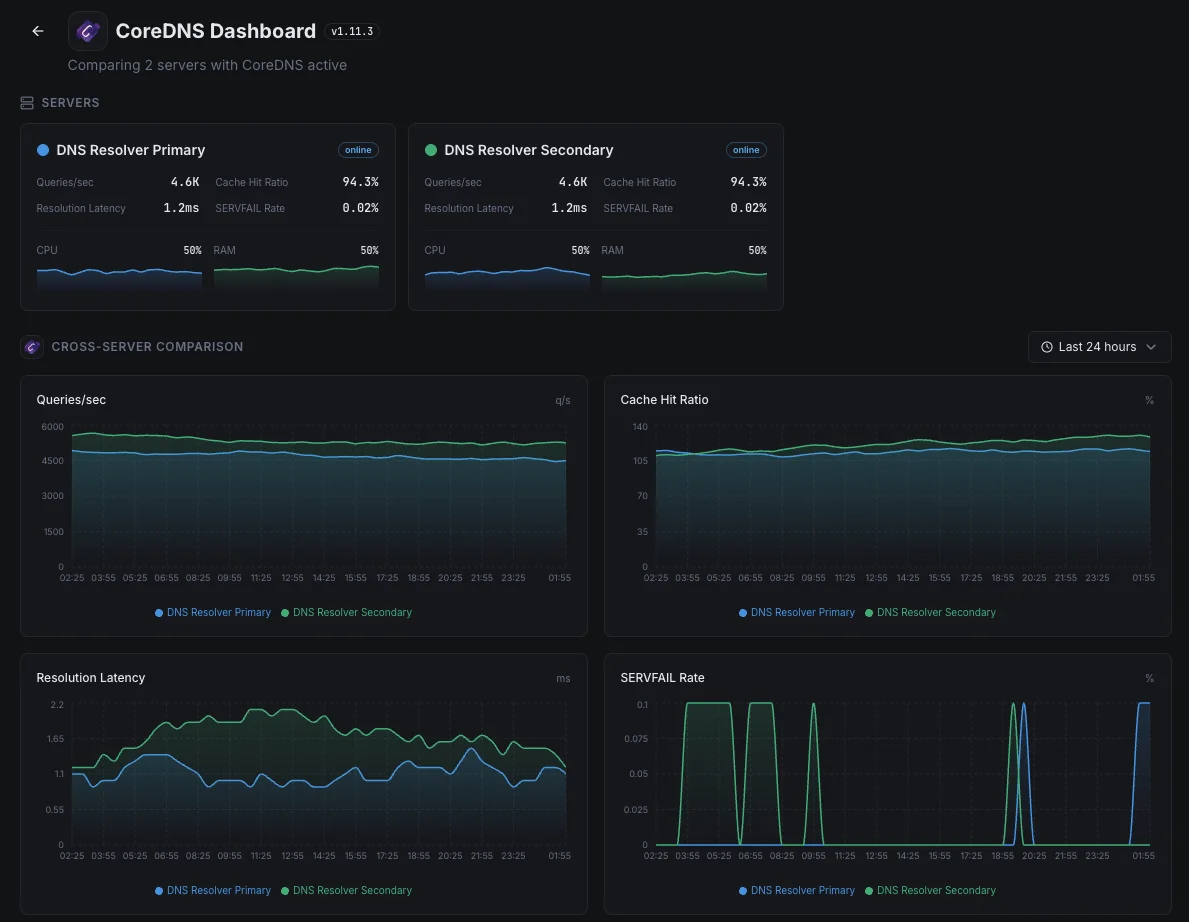
Grandi cluster con cache DNS locali
Le implementazioni di Kubernetes su larga scala prevedono l'installazione di una piccola cache DNS su ogni server per garantire la velocità del sistema. Quando una di queste cache non funziona correttamente, solo una parte del traffico ne risente, rendendo difficile individuarne il problema. Ci assicuriamo che ciascuna di esse svolga correttamente il proprio compito, in modo che un singolo nodo difettoso non possa compromettere silenziosamente il servizio per una parte dei vostri utenti.
DNS pubblico per il tuo dominio
Quando CoreDNS è il servizio che risponde alle richieste DNS relative al tuo dominio su Internet, un'interruzione significa che gli utenti non riescono affatto a raggiungere il tuo sito. Monitoriamo i segnali che indicano che il servizio è attivo e risponde correttamente, in modo che il tuo marchio e i tuoi ricavi non subiscano perdite invisibili mentre il DNS smette silenziosamente di funzionare.
Prerequisiti per CoreDNS
Assicurati di avere tutto questo in posizione — la maggior parte delle installazioni dura 60 secondi una volta soddisfatte le condizioni.
- CoreDNS 1.x in esecuzione sul server
- Plugin Prometheus abilitato nel tuo Corefile (porta predefinita 9153)
- Raggiungibilità di rete da Xitogent verso l'endpoint metrics
Inizia con verbali
Installa Xitogent sul tuo server
Se non l'hai già fatto, installa il leggero agente di monitoraggio Xitogent sull'host che esegue CoreDNS.
curl -s https://xitoring.com/install.sh | sudo bash -s -- --key=YOUR_API_KEYAbilita il plugin prometheus in CoreDNS
CoreDNS espone metriche in formato Prometheus tramite il suo plugin prometheus (endpoint predefinito :9153/metrics). Aggiungi `prometheus :9153` al tuo Corefile, ricarica CoreDNS e conferma che l'endpoint metrics sia raggiungibile dall'host dell'agente.
sudo xitogent integrateAbilita l'integrazione CoreDNS
Usa la dashboard di Xitoring o la CLI per abilitare l'integrazione CoreDNS. Xitogent rileva automaticamente l'endpoint metrics e inizia a raccogliere metriche di query, cache e latenza.
Configura le soglie di allerta (opzionale)
Imposta soglie personalizzate per SERVFAIL Rate, Cache Hit Ratio o latenza di risoluzione per essere avvisato non appena affidabilità o prestazioni DNS peggiorano.
Verifica che funzioni
Esegui questo comando sul server per confermare che Xitogent ha rilevato l'integrazione. In circa 30 secondi nuove metriche cominceranno a comparire sulla tua dashboard.
sudo xitogent statusStai valutando alternative?
Scopri come Xitoring si confronta con le alternative per il monitoraggio di CoreDNS — prezzi fissi, integrazioni più approfondite e un unico agente che copre l'intero stack.



Spesso domande poste
CoreDNS di Kubernetes?
Metriche di Prometheus?
Cosa fa il plugin kubernetes?
Come monitoro il cache hit ratio di CoreDNS?
Cosa significa NXDOMAIN nelle metriche di CoreDNS?
Come faccio il debug di CoreDNS in Kubernetes?
Come monitoro la latenza del plugin forward di CoreDNS?
Quando dovrei usare NodeLocal DNSCache?
Quali versioni di CoreDNS sono supportate?
Inizia a monitorare CoreDNS oggi
Configurazione in meno di 60 secondi. Non è richiesta alcuna carta di credito. Statistiche complete fin dal primo giorno.
Inizia la prova gratuita