Disk Health Monitoraggio
Monitora in tempo reale gli attributi SMART dei dischi, la temperatura, i settori riallocati e gli indicatori predittivi di guasto su SSD e HDD.
Perché monitorare Disk Health?
I guasti ai dischi rappresentano una delle principali cause di perdita di dati e di tempi di inattività imprevisti. Il monitoraggio dello stato dei dischi di Xitoring sfrutta la tecnologia SMART (Self-Monitoring, Analysis, and Reporting Technology) per fornire avvisi tempestivi prima che le unità si guastino, coprendo SSD, HDD e configurazioni RAID sia su Linux che su Windows.
Disk health monitoring, spiegato
Il disk health monitoring intercetta la crescita dei settori riallocati, l’usura degli NVMe, i picchi di temperatura e gli indicatori di guasto imminente giorni o settimane prima che il disco muoia — abbastanza tempo per migrare i dati e sostituirlo senza downtime. Per database server, host di backup e qualsiasi workload in cui un guasto disco significa perdita di dati, il monitoring SMART è l’alert con il ROI più alto che si possa impostare. Xitoring esegue smartctl + nvme-cli localmente e instrada gli alert verso Slack, PagerDuty, Telegram o il suo on-call esistente.
Ciò che monitoriamo
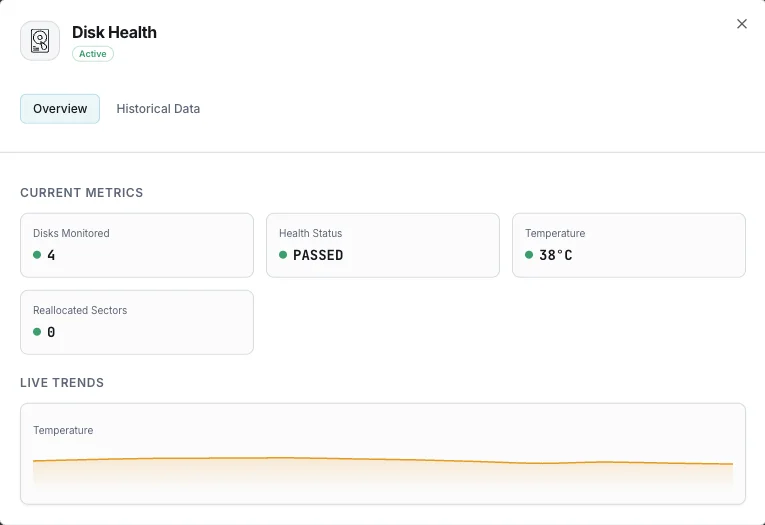
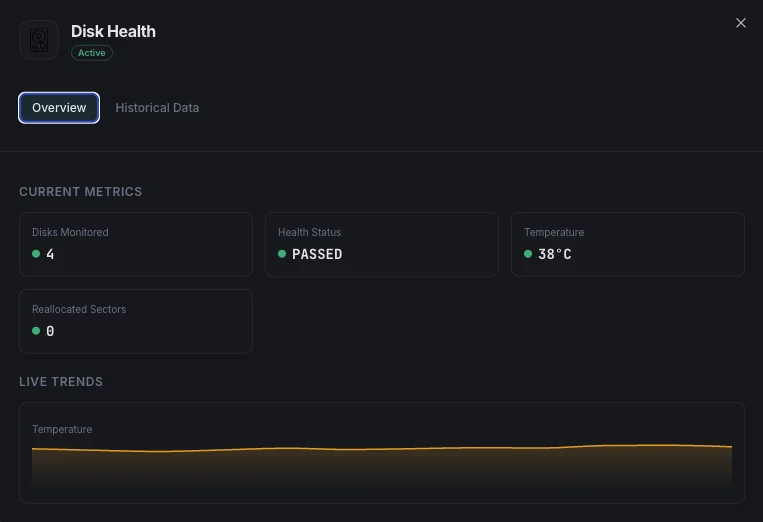
Stato di salute SMART
Indicatore complessivo di salute del disco (pass/fail).
Temperatura
Temperatura attuale del disco in gradi Celsius.
Settori riallocati
Conteggio dei settori danneggiati rimappati.
Ore di accensione
Ore operative totali del disco.
Tasso di errori di lettura
Tasso di errori di lettura riscontrati.
Settori in attesa
Settori in attesa di rimappatura.
Temperature_Celsius (SMART 194)
Temperatura attuale del disco. Gli HDD si degradano sopra i 50°C; gli SSD consumer fanno throttling sopra i 70°C. Imposti l’alert al massimo dichiarato dal vendor meno 10°C come early warning.
UDMA_CRC_Error_Count (SMART 199)
Errori CRC sull’interfaccia SATA/SAS legati al cavo. Valori in crescita segnalano un cavo difettoso o una connessione lasca — un fix semplice, spesso scambiato per un guasto del disco.
Usura SSD (Wear_Leveling_Count + Total_LBAs_Written)
Tracciamento dell’endurance SSD. `Wear_Leveling_Count` esprime la vita residua normalizzata; `Total_LBAs_Written` confrontato con il TBW dichiarato del disco dà la percentuale di usura attuale. Alert all’80% utilizzato.
NVMe percentage_used
Da `nvme smart-log` — stima del vendor della vita consumata (0–100%, può superare 100% su dischi usurati). Warning sopra l’80%; critico sopra il 95%.
NVMe available_spare
Percentuale di capacità di riserva residua per la sostituzione dei bad block. Warning sotto il 10%; critico sotto il 5% (`available_spare_threshold` è di solito impostato lì).
NVMe critical_warning
Bitfield da `nvme smart-log` che segnala: spare sotto soglia, temperatura sopra soglia, affidabilità del device degradata, modalità read-only, backup della volatile memory fallito. Qualsiasi valore diverso da zero = alert immediato.
Configurabile condizioni di attivazione
Imposta dei trigger personalizzati nella tua dashboard per ricevere una notifica non appena le metriche dell{name}e superano le soglie da te definite.
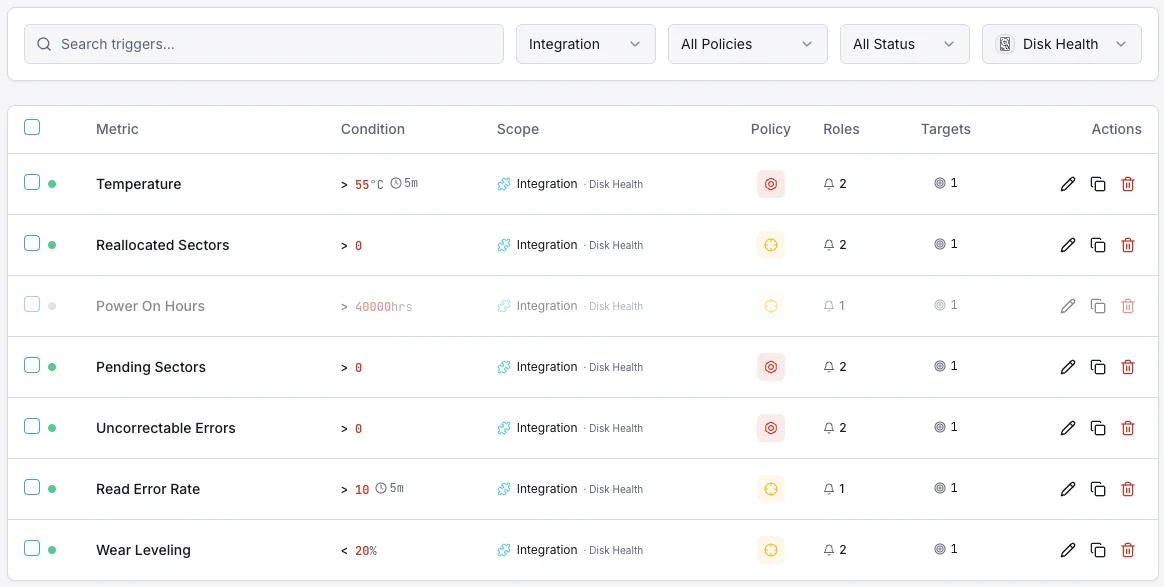
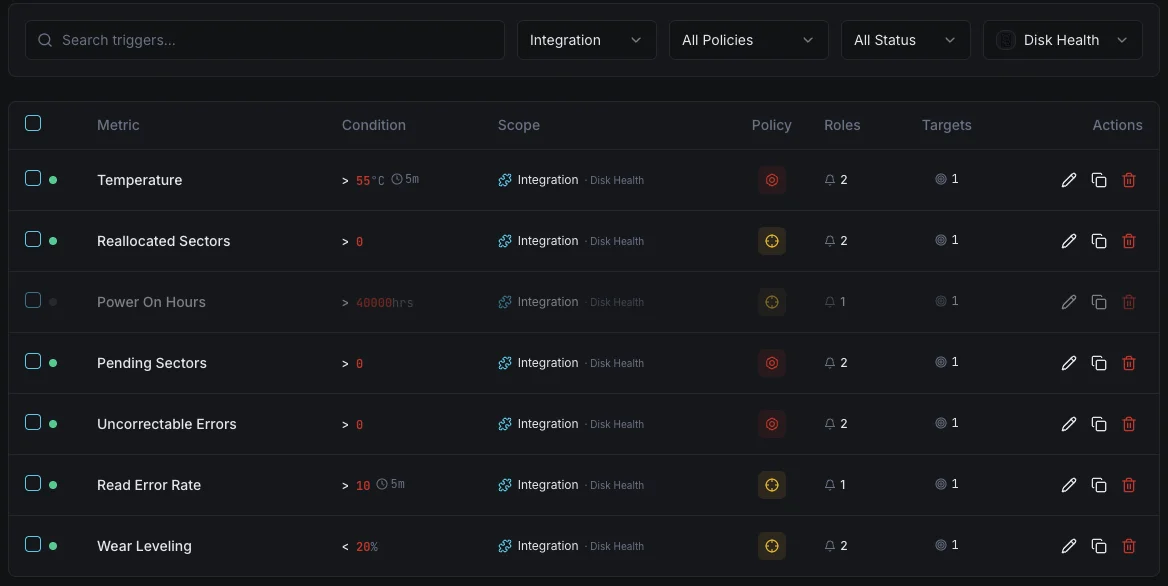
Stato di salute SMART
criticoSi attiva quando SMART segnala uno stato di salute fallito.
Settori riallocati
criticoAvvisa quando il numero di settori riallocati supera la soglia.
Temperatura del disco
avvisoSi attiva quando la temperatura del disco supera l'intervallo operativo sicuro.
Settori in attesa
avvisoSi attiva quando il numero di settori in attesa indica un possibile guasto.
Importanza del monitoraggio della salute del disco
I guasti dei dischi possono causare perdita di dati e downtime costosi. Il monitoraggio SMART fornisce segnali di allarme precoci — dall'aumento delle temperature all'incremento dei settori riallocati fino ai picchi di errori di lettura — così puoi intervenire prima che un disco si rompa.
- Previeni la perdita di dati con il rilevamento precoce dei guasti
- Ottimizza le prestazioni identificando i colli di bottiglia
- Pianifica la capacità con l'analisi storica dei trend
- Mantieni la conformità con il monitoraggio dell'integrità dei dati
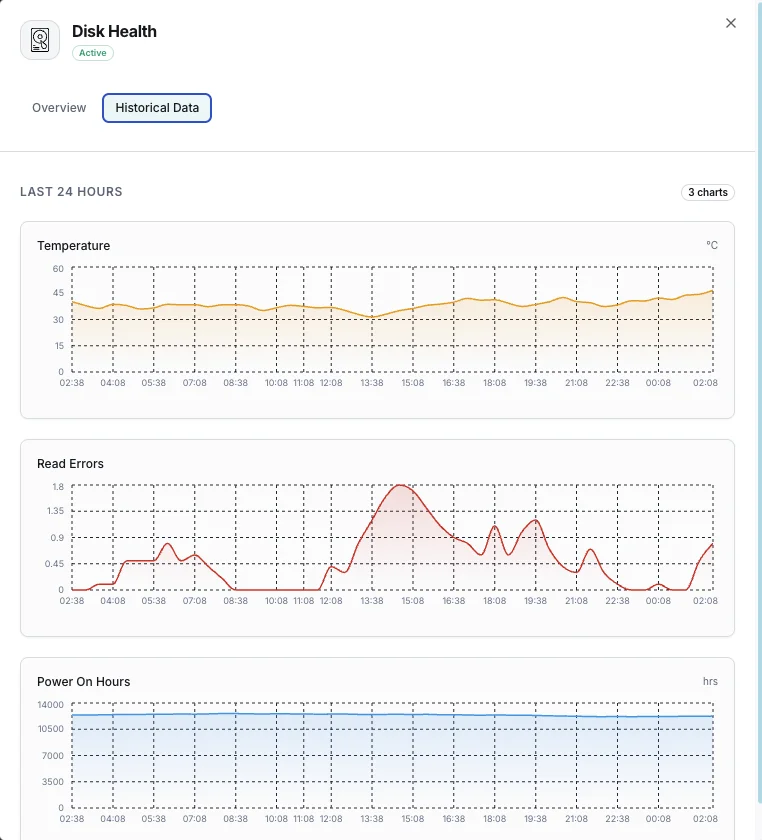
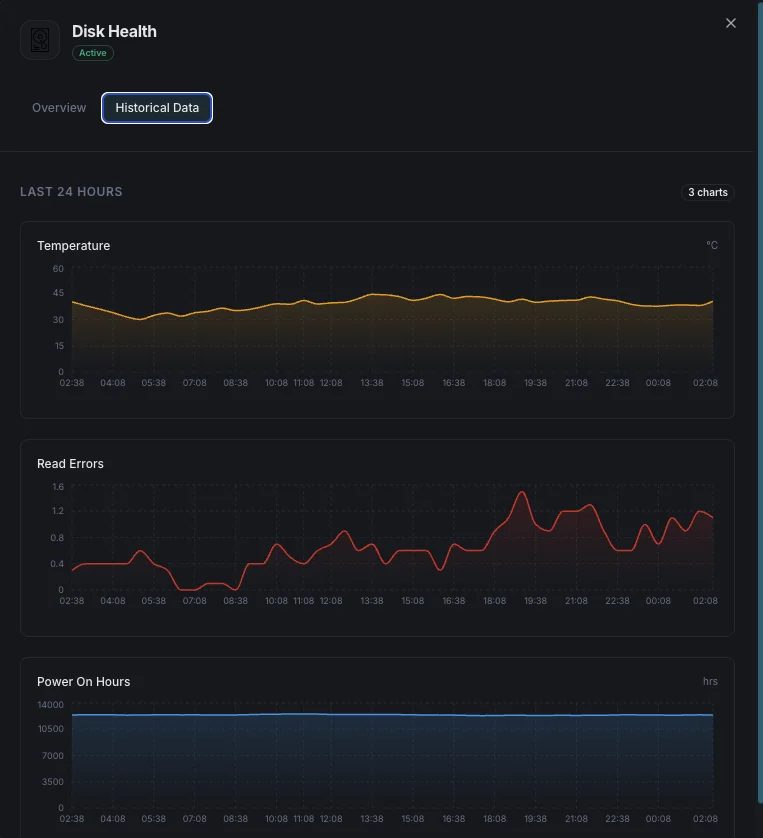
Perché scegliere Xitoring
Xitoring fornisce monitoraggio della salute del disco zero-config con integrazione SMART per tutti i tipi di disco. Ottieni avvisi in tempo reale, trend storici e indicatori predittivi di guasto in una dashboard unificata.
- Compatibile con SSD, HDD e array RAID
- Configurazione con un solo comando su Linux e Windows
- Soglie personalizzabili sugli attributi SMART
- Alerting multicanale per eventi critici del disco
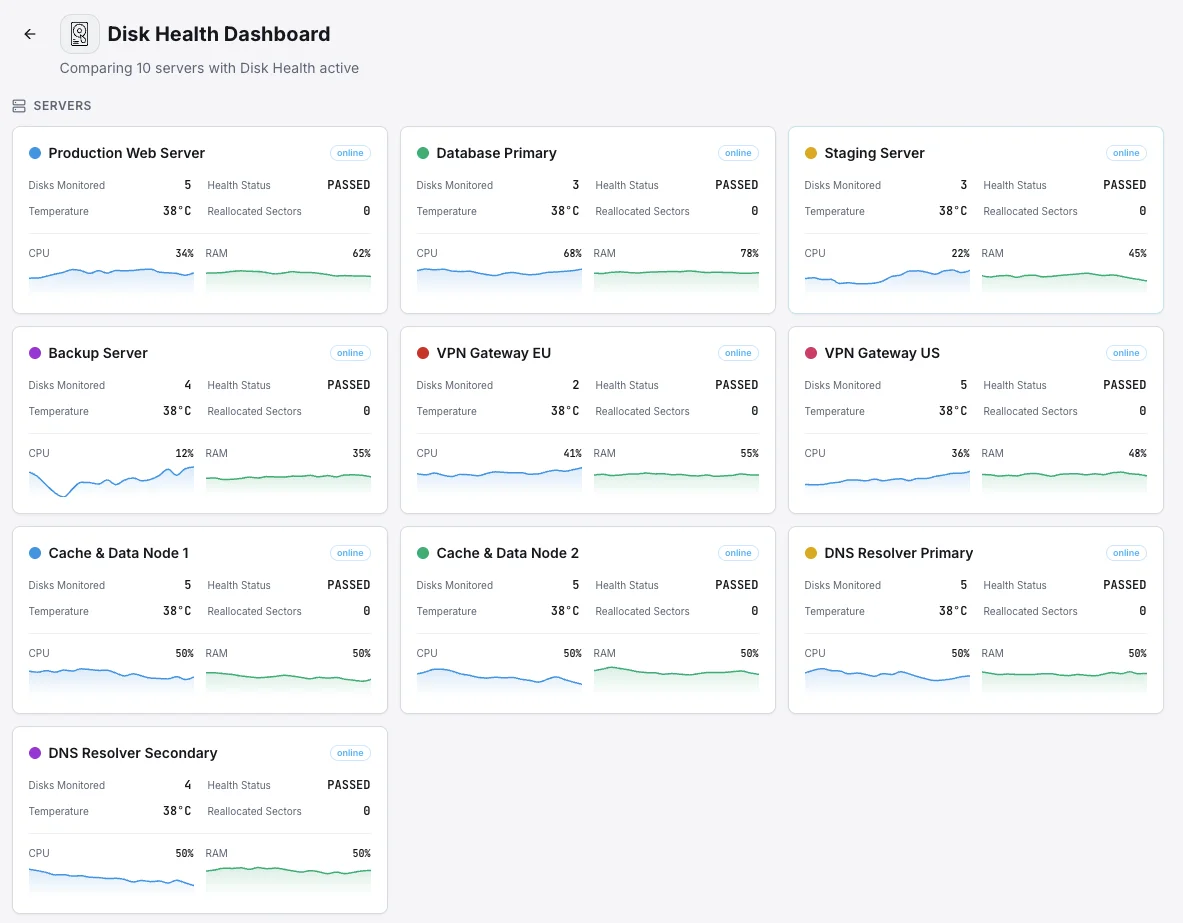
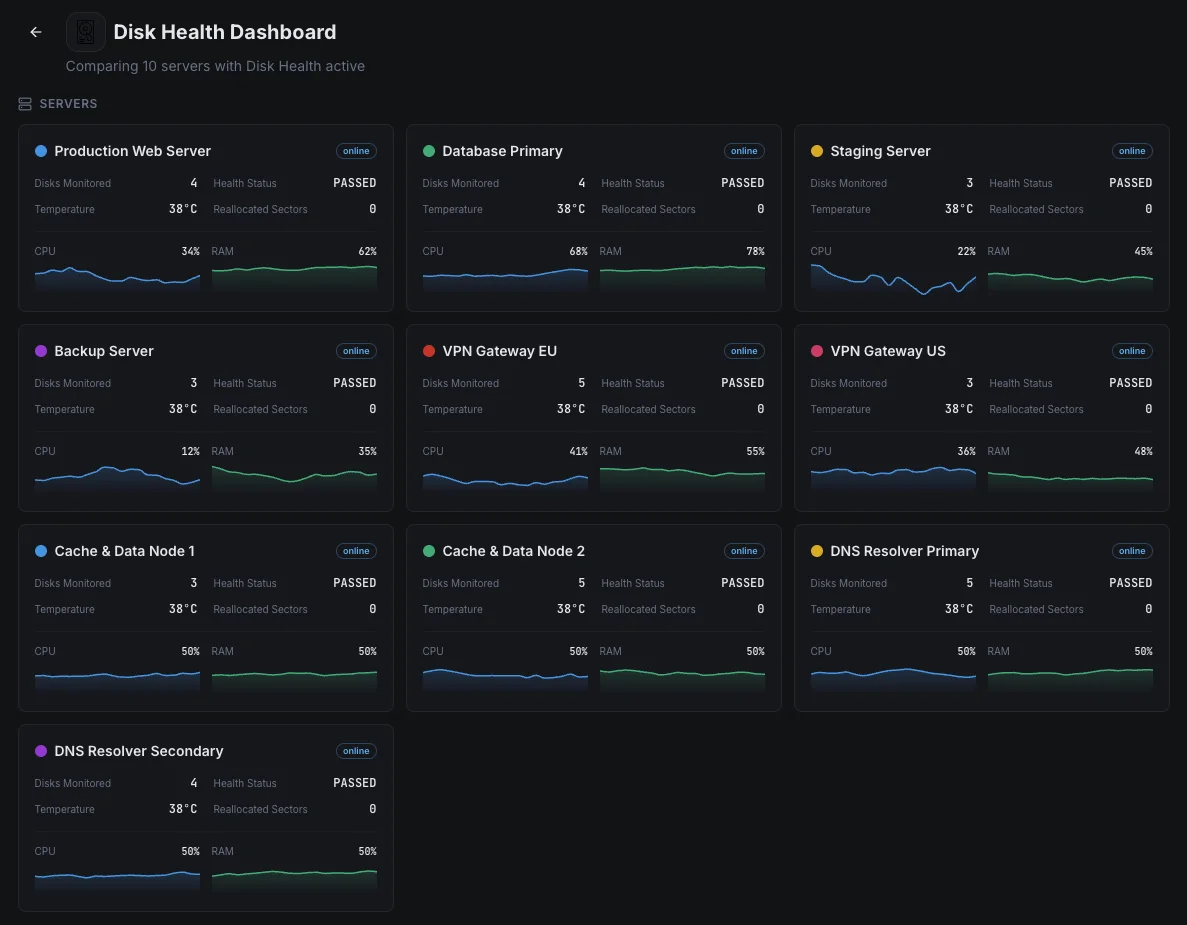
Scenari comuni di disk health monitoring
È proprio grazie al monitoraggio dei dischi che, nella maggior parte dei casi, si riesce a individuare i guasti alle unità prima che causino danni concreti.
Server di database
Il guasto di un disco in un database può comportare tempi di inattività, perdita di ordini o, nel peggiore dei casi, il danneggiamento dei dati. Monitoriamo ogni disco alla ricerca dei primi segnali di malfunzionamento, in modo che il team possa sostituire un disco difettoso secondo i propri tempi, senza doverlo fare nel bel mezzo di un'interruzione del servizio alle 3 del mattino.
Server di backup e archiviazione
Il problema specifico delle unità di backup è che un guasto rimane invisibile fino al momento in cui si ha effettivamente bisogno del backup — e a quel punto è troppo tardi. Testiamo ogni unità secondo un programma prestabilito e individuiamo tempestivamente eventuali segni di usura, in modo che non ti capiti mai di cercare un backup che non c'è.
Server che scrivono grandi quantità di dati (SSD)
Gli SSD hanno un numero limitato di operazioni di scrittura prima di esaurirsi, e i database molto sollecitati e le app che gestiscono grandi quantità di dati li consumano più rapidamente di quanto la maggior parte dei team creda. Monitoriamo l'usura in termini di percentuali, in modo che le unità vengano sostituite per tempo, e non solo dopo un guasto improvviso e irreversibile.
Prerequisiti per Disk Health
Assicurati di avere tutto questo in posizione — la maggior parte delle installazioni dura 60 secondi una volta soddisfatte le condizioni.
- Server Linux (Debian/Ubuntu, RHEL/CentOS, o distribuzione compatibile)
- Pacchetto smartmontools installato (smartctl) e lsblk disponibile
- Accesso sudo / root — i dati SMART richiedono permessi elevati
Inizia con verbali
Installa i prerequisiti (Linux)
Installa smartmontools per abilitare la raccolta dei dati SMART. Assicurati che lsblk sia disponibile sul sistema.
# Ubuntu/Debian
sudo apt-get install smartmontools
# CentOS/RHEL
sudo yum install smartmontoolsAbilita l'integrazione Disk Health
Esegui il comando integrate e seleziona Disk Health. Xitogent rileva automaticamente i tuoi dischi e inizia a raccogliere dati SMART. Nessun prerequisito richiesto su Windows.
xitogent integrateVerifica che funzioni
Esegui questo comando sul server per confermare che Xitogent ha rilevato l'integrazione. In circa 30 secondi nuove metriche cominceranno a comparire sulla tua dashboard.
sudo xitogent statusStai valutando alternative?
Scopri come Xitoring si confronta con le alternative per il monitoraggio di Disk Health — prezzi fissi, integrazioni più approfondite e un unico agente che copre l'intero stack.



Spesso domande poste
Quali tipi di disco sono supportati?
Devo installare qualche programma in più?
Posso monitorare le unità NVMe?
Con quale frequenza vengono raccolti i dati?
Quali attributi SMART predicono il guasto del disco?
Come monitoro la salute dei dischi NVMe?
Come monitoro la salute del disco su Windows?
Con che frequenza dovrei eseguire i self-test smartctl?
Funziona con array RAID?
Inizia a monitorare Disk Health oggi
Configurazione in meno di 60 secondi. Non è richiesta alcuna carta di credito. Statistiche complete fin dal primo giorno.
Inizia la prova gratuita