CoreDNS Monitorização
Monitorize as taxas de consultas do CoreDNS, as taxas de acertos no cache, a latência de resolução e as taxas de erro em tempo real, sem necessidade de configuração.
Por que monitorizar CoreDNS?
O CoreDNS é o servidor DNS predefinido para o Kubernetes e ambientes nativos da nuvem. A monitorização do CoreDNS garante uma resolução DNS rápida, um bom desempenho do cache e uma descoberta de serviços fiável para a sua infraestrutura.
Monitorização do CoreDNS, explicada
A monitorização do CoreDNS deteta picos de SERVFAIL, quedas no rácio de acertos da cache, latência do plugin forward e reinícios por panic antes que se transformem em falhas de resolução DNS em todo o cluster. Como todos os microsserviços dependem do DNS para descoberta de serviços, um CoreDNS não monitorizado é um modo de falha não monitorizado para todo o seu cluster Kubernetes — os problemas de DNS aparecem como "connection refused aleatórios" em toda a parte. O Xitoring deteta automaticamente o seu CoreDNS, faz scrape de :9153/metrics e encaminha alertas para Slack, PagerDuty, Telegram ou o seu on-call existente.
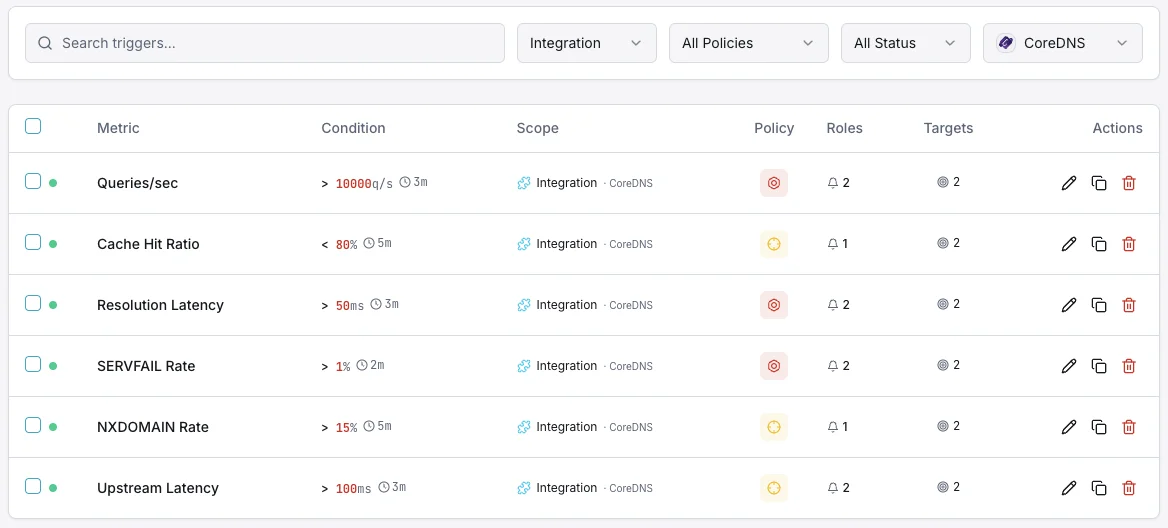
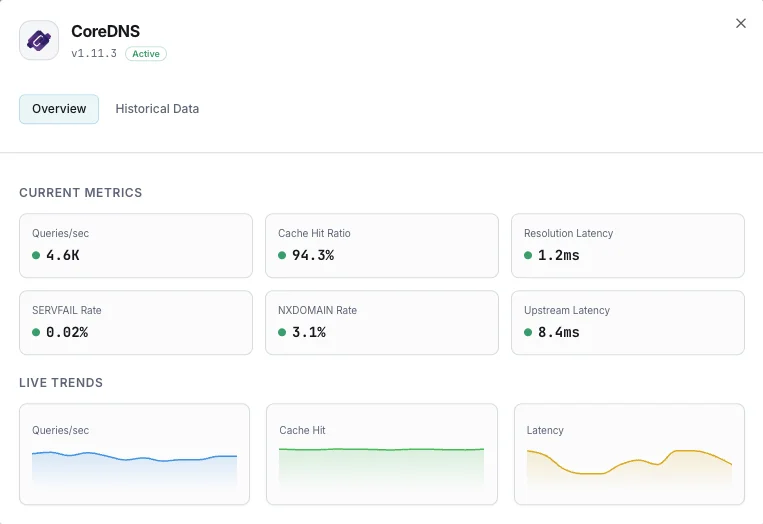
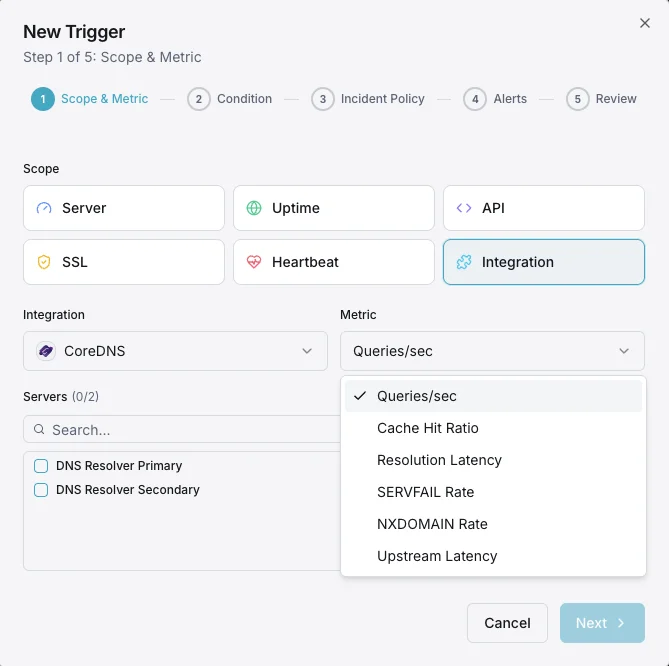
O que monitorizamos
Consultas/s
Taxa de consultas DNS.
Rácio de cache hit
Percentagem de consultas servidas a partir da cache.
Latência de resolução
Tempo médio de resolução DNS.
Taxa de SERVFAIL
Percentagem de resoluções falhadas.
Taxa NXDOMAIN
Taxa de consultas a domínios inexistentes.
Latência upstream
Tempo de resposta das consultas reencaminhadas.
Latência do plugin Forward
`coredns_forward_request_duration_seconds` por resolver upstream. Separa a latência interna do CoreDNS da latência do resolver upstream — crítico para diagnosticar se o lento é o 8.8.8.8 ou o próprio CoreDNS.
Taxa de pedidos Forward
`coredns_forward_request_count_total` por upstream. Combinado com o rácio de acertos da cache, mostra quanto tráfego sai efetivamente do CoreDNS para resolução upstream.
Cache de ligações do Proxy
`coredns_proxy_conn_cache_hits_total` / `_misses_total`. Acompanha a reutilização de ligações TCP para resolvers upstream — um rácio de acertos baixo significa churn de ligações, aumentando a latência upstream.
Falhas do plugin Health
`coredns_health_request_failures_total` — a contagem de falhas do próprio plugin `health:8080`. Um valor diferente de zero significa que a sonda de liveness está a falhar de forma intermitente.
Panics
`coredns_panics_total` — qualquer valor diferente de zero é um bug do CoreDNS ou um crash de plugin que provocou um panic de goroutine. Combine com a contagem de reinícios para obter contexto completo de post-mortem.
Runtime do Go
`process_resident_memory_bytes` (RSS), `go_goroutines` (contagem de goroutines — deteta fugas), `go_gc_duration_seconds` (tempo de pausa do GC). Crescimento de memória sem reinícios = fuga; crescimento da contagem de goroutines = plugin ou upstream bloqueado.
Configurável condições de alerta
Configure alertas personalizados no seu painel para ser notificado assim que as métricas dCoreDNS ultrapassarem os limites que definiu.
Taxa de SERVFAIL
críticoDispara em caso de alta taxa de falhas de resolução.
Rácio de cache hit
avisoAlerta quando a eficácia da cache cai.
Latência de resolução
avisoDispara em caso de resolução DNS lenta.
Taxa de consultas
avisoDispara em volumes de consultas inusitados.
Importância da monitorização do CoreDNS
O DNS é a base da conectividade de rede. Uma resolução DNS lenta ou falhada afeta todos os serviços na sua infraestrutura.
- Garantir uma resolução DNS rápida
- Detetar picos de SERVFAIL imediatamente
- Monitorizar a cache para um desempenho ótimo
- Acompanhar a saúde dos resolvers upstream
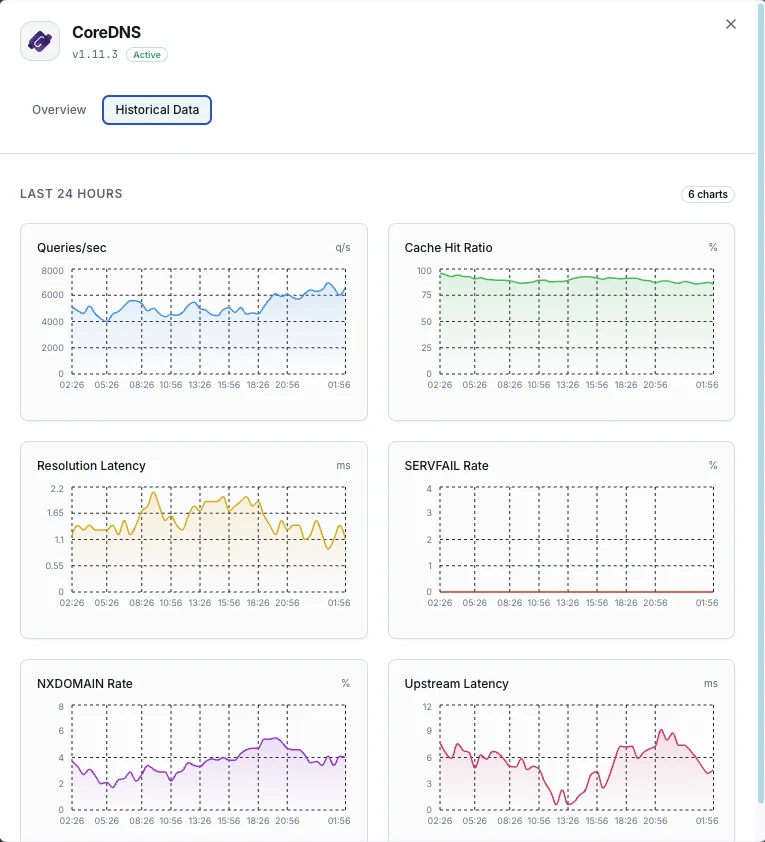
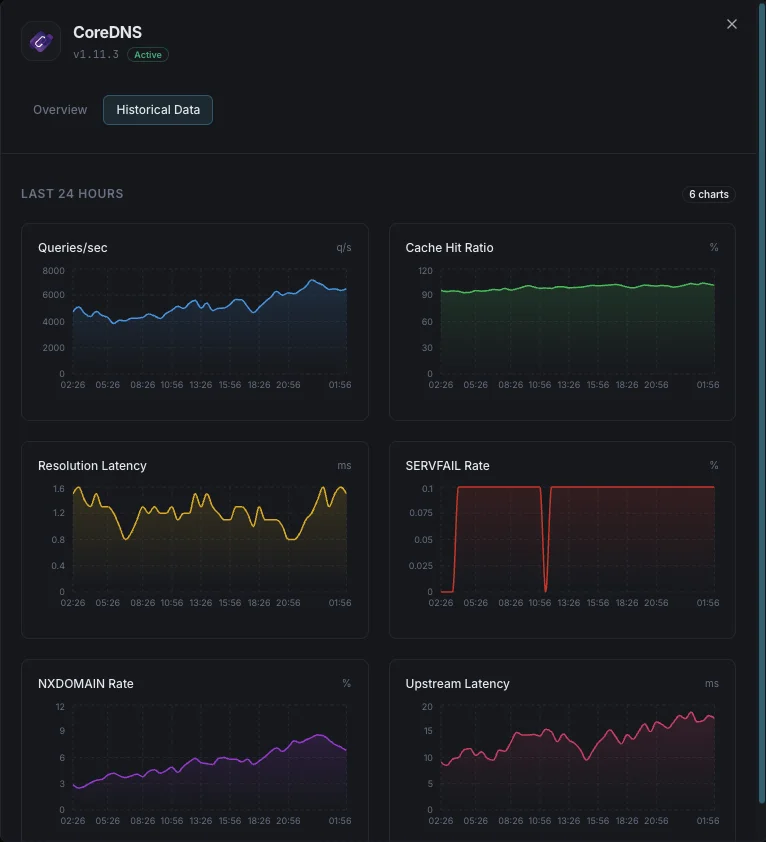
Porquê escolher Xitoring
Monitorização CoreDNS sem configuração.
- Instalação num único comando
- Nós globais
- Dashboard unificado
- Alertas multicanal
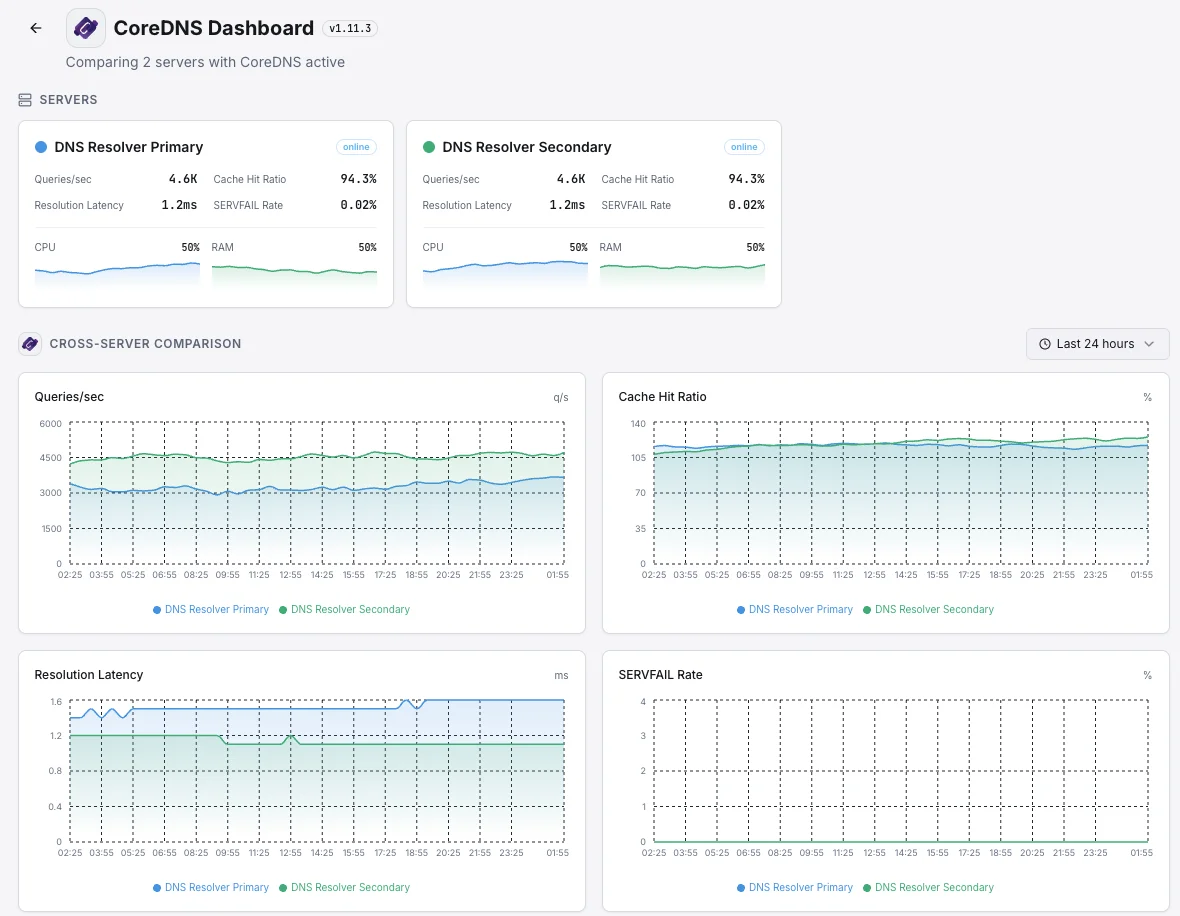
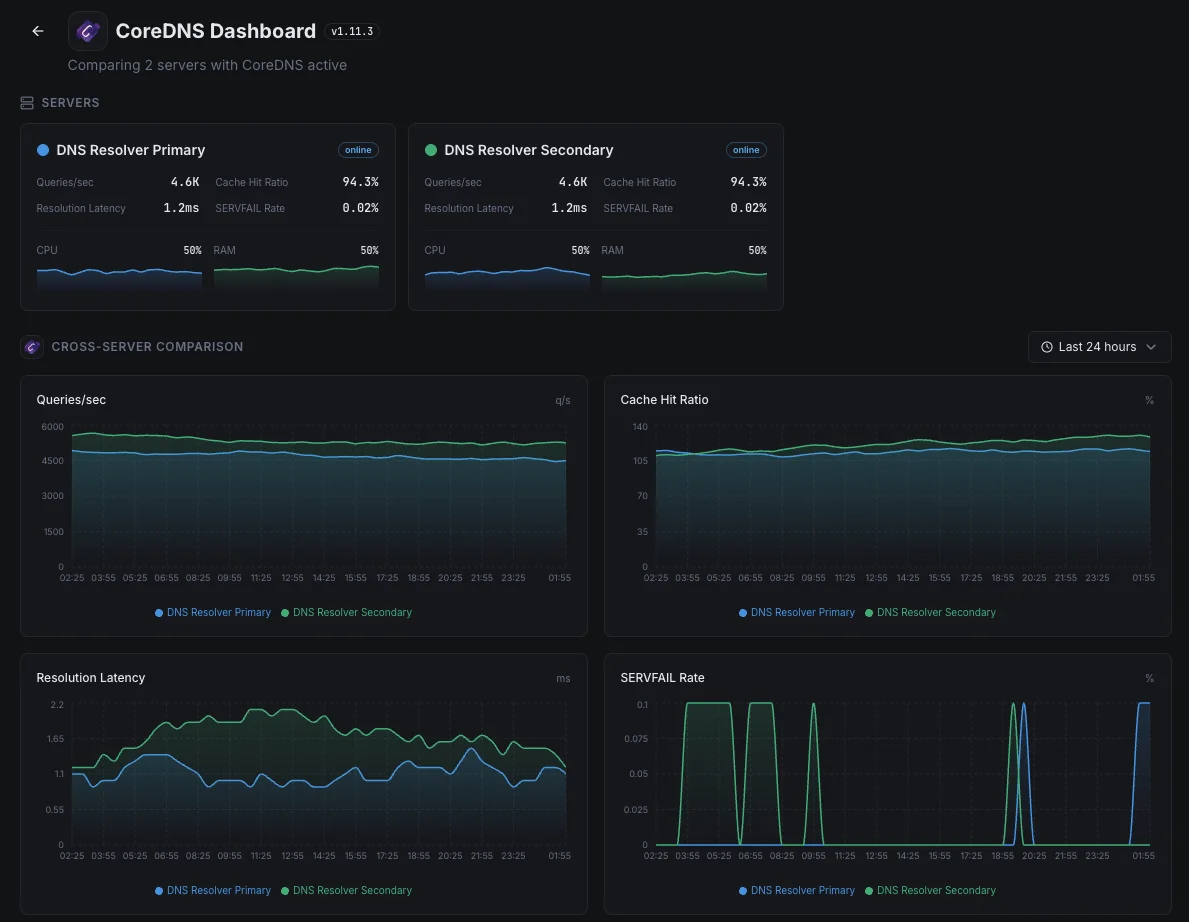
Cenários comuns de monitorização do CoreDNS
Onde o CoreDNS normalmente é executado hoje — e o que poderia correr mal se ninguém estivesse a monitorizar.
DNS dentro de uma aplicação Kubernetes
Cada parte de uma aplicação Kubernetes usa o CoreDNS para encontrar todas as outras partes. Quando ele desacelera ou começa a falhar, os utilizadores veem erros estranhos e intermitentes em toda a aplicação. Detetamos a desaceleração no momento em que começa, para que um pequeno soluço de DNS não apareça para os clientes como uma interrupção misteriosa.
Grandes clusters com caches DNS locais
Configurações maiores de Kubernetes colocam uma pequena cache DNS em cada servidor para manter as coisas rápidas. Quando uma dessas caches se comporta mal, apenas uma fatia do tráfego falha — tornando difícil de detetar. Garantimos que cada uma está a fazer o seu trabalho para que um único nó defeituoso não degrade silenciosamente uma fração dos seus utilizadores.
DNS público para o seu domínio
Quando o CoreDNS é o que responde às consultas DNS para o seu domínio na internet aberta, uma interrupção significa que as pessoas não conseguem aceder ao seu site de todo. Monitorizamos os sinais que provam que o serviço está saudável e a responder, para que a marca e a receita não estejam a sangrar silenciosamente enquanto o DNS falha em silêncio.
Pré-requisitos para CoreDNS
Certifique-se de que tem tudo isto pronto — depois disso, a maioria das instalações leva 60 segundos.
- CoreDNS 1.x em execução no servidor
- Plugin Prometheus ativado no seu Corefile (porta predefinida 9153)
- Acessibilidade de rede do Xitogent ao endpoint de metrics
Comece a minutos
Instalar o Xitogent no seu servidor
Se ainda não o fez, instale o leve agente de monitorização Xitogent no host que executa o CoreDNS.
curl -s https://xitoring.com/install.sh | sudo bash -s -- --key=YOUR_API_KEYAtivar o plugin prometheus no CoreDNS
O CoreDNS expõe métricas em formato Prometheus através do seu plugin prometheus (endpoint predefinido :9153/metrics). Adicione `prometheus :9153` ao seu Corefile, recarregue o CoreDNS e confirme que o endpoint de metrics é acessível a partir do host do agente.
sudo xitogent integrateAtivar a integração do CoreDNS
Use o painel do Xitoring ou a CLI para ativar a integração do CoreDNS. O Xitogent deteta automaticamente o endpoint de metrics e começa a recolher métricas de queries, cache e latência.
Configurar limiares de alerta (opcional)
Defina limiares personalizados para taxa de SERVFAIL, rácio de cache hit ou latência de resolução para ser notificado assim que a fiabilidade ou desempenho do DNS se degradar.
Confirme que está a funcionar
Execute este comando no servidor para confirmar que o Xitogent detetou a integração. Em cerca de 30 segundos começam a chegar novas métricas ao seu painel.
sudo xitogent statusEstá a considerar alternativas?
Veja como o Xitoring se compara às alternativas para a monitorização de CoreDNS — preços fixos, integrações mais profundas e um único agente que cobre toda a sua stack.



Frequentemente perguntas feitas
CoreDNS do Kubernetes?
Métricas do Prometheus?
O que faz o plugin kubernetes?
Como monitorizo o rácio de acertos da cache do CoreDNS?
O que significa NXDOMAIN nas métricas do CoreDNS?
Como faço debug ao CoreDNS no Kubernetes?
Como monitorizo a latência do plugin forward do CoreDNS?
Quando devo usar o NodeLocal DNSCache?
Que versões do CoreDNS são suportadas?
Comece a monitorizar CoreDNS hoje
Configure em menos de 60 segundos. Não é necessário cartão de crédito. Estatísticas completas desde o primeiro dia.
Iniciar período de avaliação gratuita