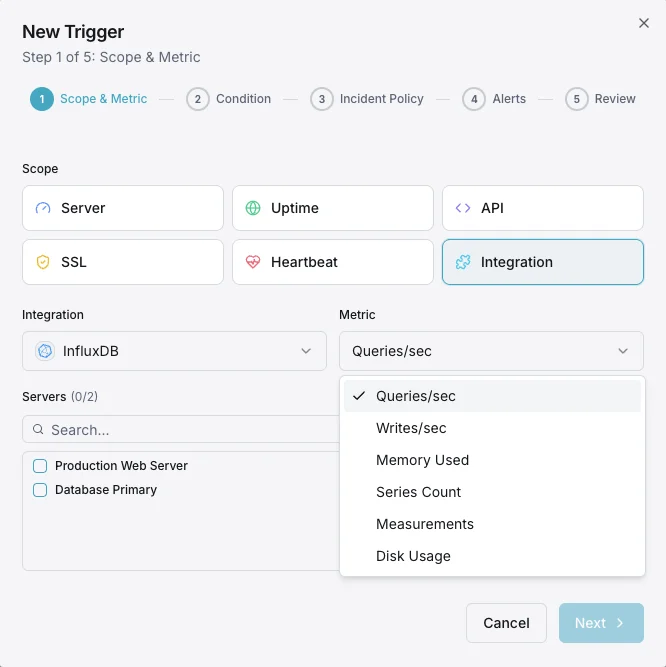
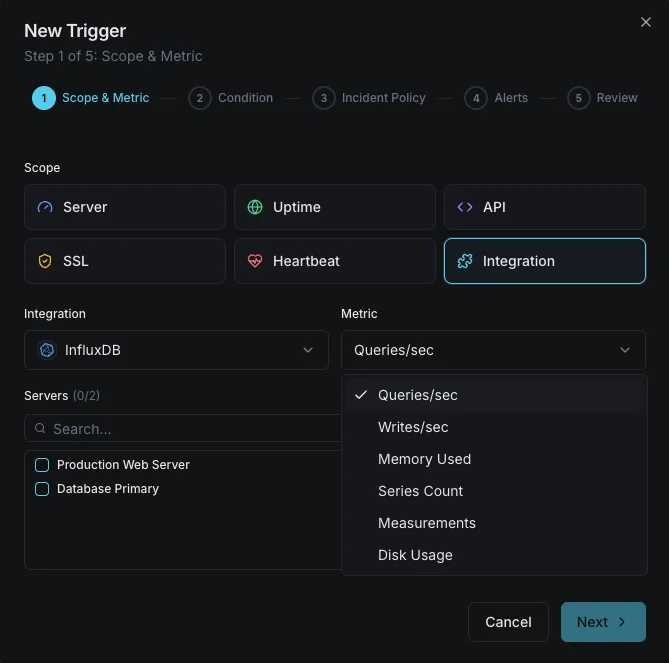
InfluxDB Monitorização
Monitorize o débito de gravação do InfluxDB, o desempenho das consultas, as métricas do motor de armazenamento e o estado das políticas de retenção em tempo real, sem necessidade de configuração.
Por que monitorizar InfluxDB?
O InfluxDB é a principal base de dados de séries temporais para métricas, eventos e análises em tempo real. A monitorização do InfluxDB garante uma ingestão de dados em bom estado, um desempenho ideal das consultas e uma gestão adequada da retenção.
Monitorização do InfluxDB, explicada
A monitorização do InfluxDB deteta paragens no débito de escrita, cardinalidade descontrolada de séries (o clássico modo de falha do InfluxDB 1.x/2.x), atrasos na compactação TSM, lentidão de consultas e crescimento do WAL antes que causem perda de ingestão ou timeouts de consulta nos seus dashboards Grafana. Para pipelines de sensores IoT, backends de métricas de aplicações e qualquer implementação da stack TICK, a visibilidade por base de dados é o que separa um alerta em 60 segundos de um incidente de várias horas à procura de pontos de dados em falta. O Xitoring descobre automaticamente o seu InfluxDB, lê o endpoint Prometheus nativo /metrics, e encaminha alertas para Slack, PagerDuty, Telegram ou para a sua equipa de plantão existente.
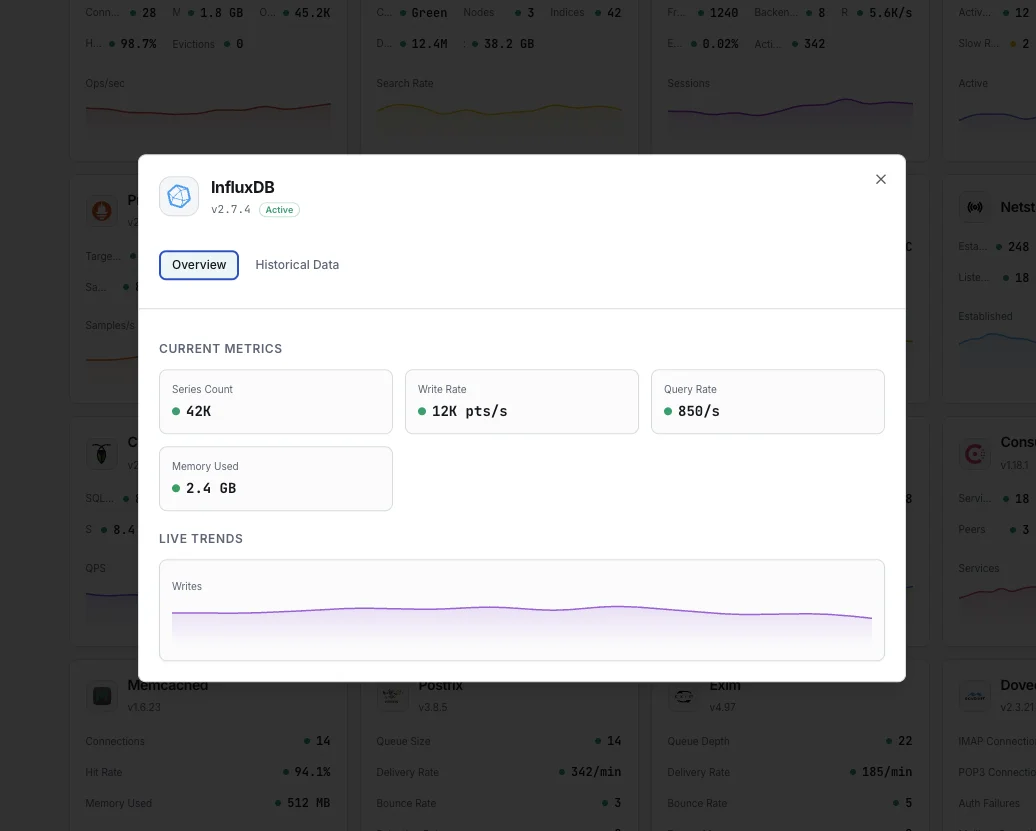
O que monitorizamos
Pontos escritos/s
Taxa de escrita de pontos de dados.
Duração das consultas
Tempo médio de execução das consultas.
Cardinalidade das séries
Total de séries temporais únicas.
Tamanho do armazenamento
Armazenamento TSM em disco.
Taxa de compactação
Throughput de compactação TSM.
Tamanho da cache
Utilização da cache de escrita em memória.
WAL Disk Bytes
`storage.tsm1.wal.currentSegmentDiskBytes` + `oldSegmentsDiskBytes`. O crescimento do WAL sem consolidação TSM significa que o tempo de recuperação irá disparar no arranque.
Tamanho de armazenamento em disco
`storage.tsm1.filestore.diskBytes` + numFiles por shard. Acompanhe em relação à sua política de retenção — contagens elevadas de ficheiros com o mesmo tamanho de dados indicam fragmentação.
Taxa de HTTP 4xx / 5xx
`httpd.clientError` + `httpd.serverError` (ou Prometheus `http_api_request_errors_total`). Picos de 4xx assinalam erros de esquema/autenticação do cliente; 5xx assinalam falhas do lado do servidor.
Ligações / Falhas de autenticação
`httpd.req` (total de pedidos HTTP), `httpd.authFail` (tentativas de autenticação falhadas), `httpd.pingReq`. Picos de falhas de autenticação sinalizam Telegraf mal configurado ou uma rotação de credenciais mal feita.
Runtime — Goroutines e GC
Estatísticas do runtime Go: `runtime.NumGoroutine` (deteção de fugas de goroutines), `runtime.HeapAlloc` (heap ativa), `runtime.NumGC`/`PauseTotalNs` (pressão de GC). Apanhe fugas e regressões no tempo de pausa antes de OOM.
Escritas de subscrições
`subscriber.pointsWritten` e `subscriber.writeFailures` — quando o Kapacitor ou pipelines a jusante consomem via subscrições, é assim que apanha a contrapressão.
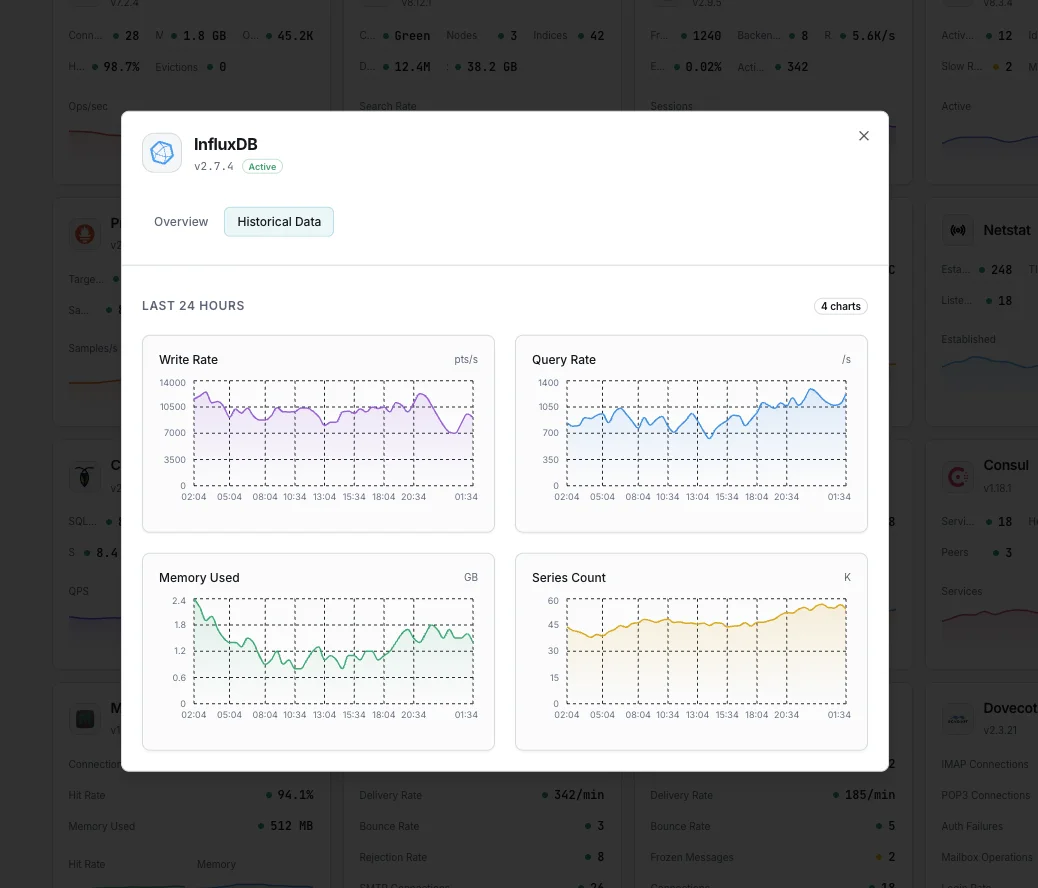
Configurável condições de alerta
Configure alertas personalizados no seu painel para ser notificado assim que as métricas dInfluxDB ultrapassarem os limites que definiu.
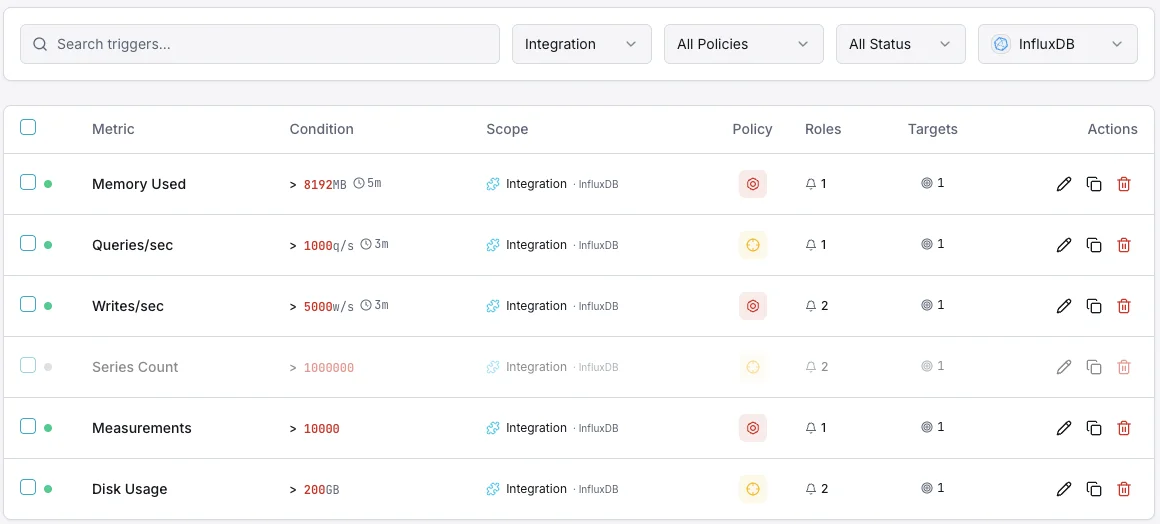
Throughput de escrita
avisoDispara em anomalias da taxa de escrita.
Duração das consultas
avisoAlerta sobre consultas lentas.
Cardinalidade das séries
críticoDispara quando a cardinalidade é demasiado elevada.
Tamanho do armazenamento
críticoDispara quando o armazenamento excede o limite.
Importância da monitorização do InfluxDB
O InfluxDB lida com dados de séries temporais de alta velocidade. Cardinalidade elevada, pressão de escrita e atrasos de compactação podem degradar o desempenho.
- Acompanhe o throughput de escrita para a saúde da ingestão
- Monitorize a cardinalidade das séries para prevenir OOM
- Detete cedo as consultas lentas
- Garanta que a compactação acompanha o ritmo
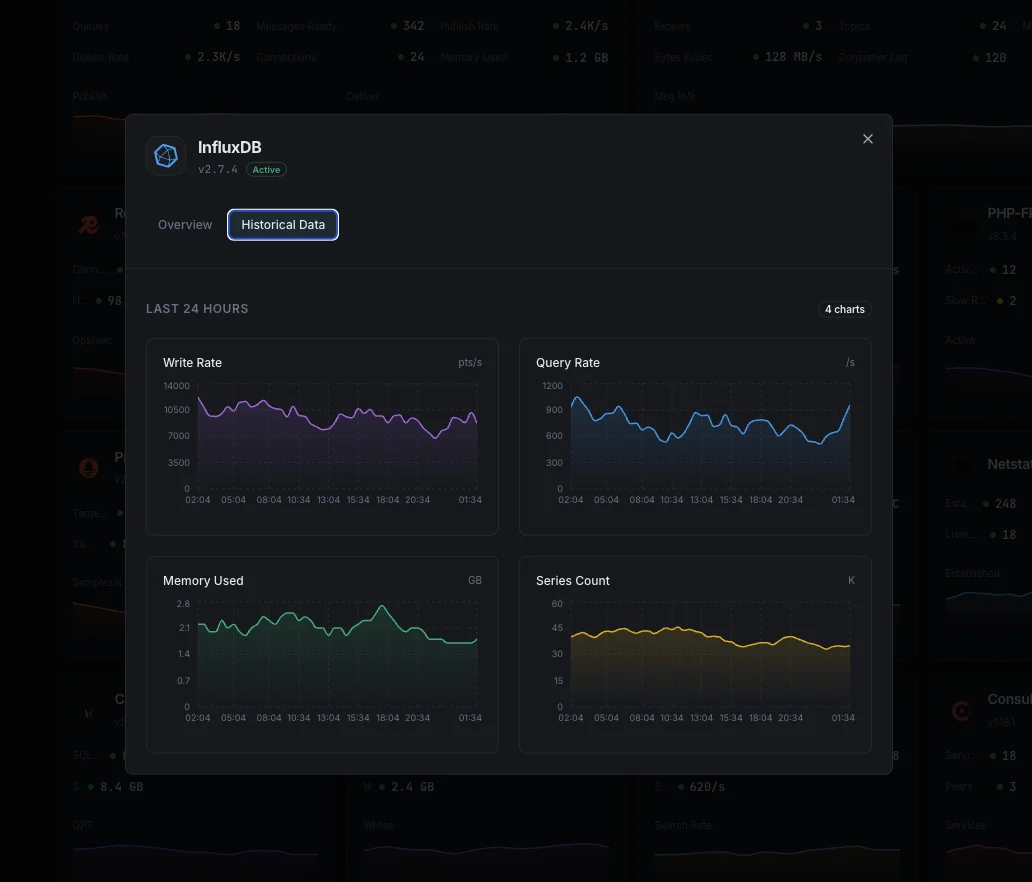
Porquê escolher Xitoring
Monitorização InfluxDB sem configuração.
- Instalação num único comando
- Nós globais
- Dashboard unificado
- Alertas multicanal
- Retenção histórica
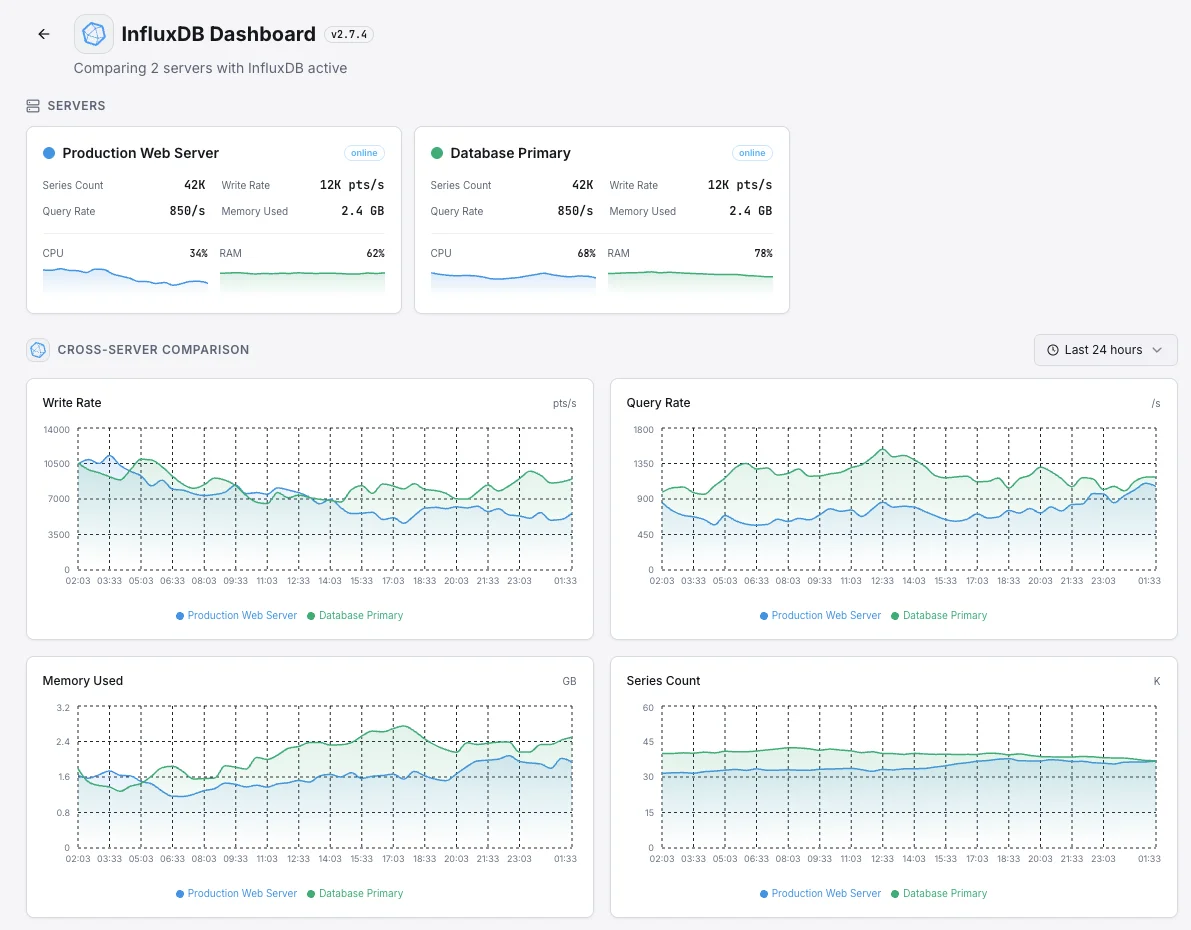
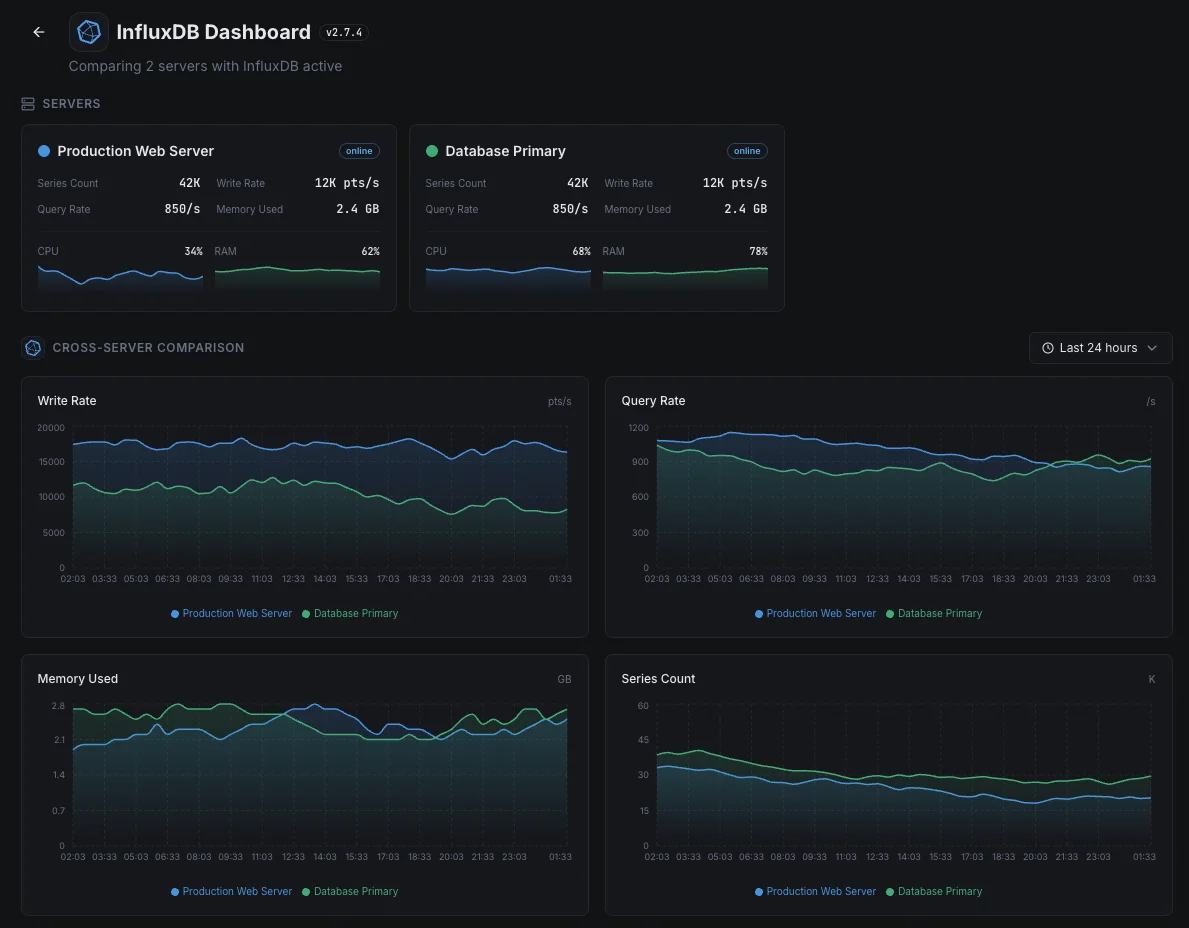
Cenários comuns de monitorização do InfluxDB
Onde o InfluxDB normalmente é executado hoje — e o que pode correr mal se ninguém estiver a monitorizar.
A base de dados por trás dos dashboards da sua equipa
Quando os dashboards no Grafana ou noutra ferramenta parecem lentos, a causa é frequentemente a base de dados subjacente — e não o próprio dashboard. Mostramos onde a lentidão realmente reside para que a equipa corrija a coisa certa em vez de perseguir o sintoma.
Dados a fluir de sensores e dispositivos
Dispositivos conectados, equipamentos de fábrica e sensores IoT enviam medições a cada segundo de cada dia. Um backup silencioso no pipeline significa perda de dados — e dados perdidos desaparecem para sempre. Monitorizamos o fluxo de ponta a ponta para que uma única leitura perdida levante o alarme.
Métricas de aplicação e infraestrutura num só lugar
Quando a mesma base de dados contém métricas de aplicação e métricas de servidor, um problema com a base de dados oculta todos os sinais de uma só vez. Monitorizamos a própria base de dados para que o próprio monitoramento da equipa nunca fique às escuras durante um incidente.
Pré-requisitos para InfluxDB
Certifique-se de que tem tudo isto pronto — depois disso, a maioria das instalações leva 60 segundos.
- InfluxDB 1.x ou 2.x em execução no servidor
- Porta HTTP do InfluxDB acessível a partir do Xitogent (predefinida 8086)
- Opcional: um token só de leitura se a autenticação do InfluxDB 2.x estiver ativada
Comece a minutos
Instalar o Xitogent no seu host InfluxDB
Instale o leve agente de monitorização Xitogent no host que executa o InfluxDB.
curl -s https://xitoring.com/install.sh | sudo bash -s -- --key=YOUR_API_KEYConfirmar que o InfluxDB é acessível
Verifique se o InfluxDB está a escutar na sua porta HTTP (predefinida 8086) e é acessível a partir do host que executa o Xitogent. O Xitogent vai pedir o host e a porta durante o integrate — não são necessárias edições de configuração ou exposição de endpoints adicionais.
sudo xitogent integrateAtivar a integração do InfluxDB
Use o painel do Xitoring ou a CLI para ativar a integração do InfluxDB. O Xitogent deteta automaticamente a sua versão de InfluxDB e começa a recolher métricas de escrita, query e armazenamento.
Configurar limiares de alerta (opcional)
Defina limiares personalizados para throughput de escrita, duração de queries ou cardinalidade de séries para apanhar pressão de ingestão e crescimento descontrolado de tags antes que as queries fiquem lentas.
Confirme que está a funcionar
Execute este comando no servidor para confirmar que o Xitogent detetou a integração. Em cerca de 30 segundos começam a chegar novas métricas ao seu painel.
sudo xitogent statusEstá a considerar alternativas?
Veja como o Xitoring se compara às alternativas para a monitorização de InfluxDB — preços fixos, integrações mais profundas e um único agente que cobre toda a sua stack.



Frequentemente perguntas feitas
InfluxDB 1.x e 2.x?
Impacto?
Como deteto problemas de cardinalidade no InfluxDB?
O que é a base de dados _internal no InfluxDB?
Como monitorizo as compactações do InfluxDB?
Qual a diferença entre a monitorização do InfluxDB 1.x, 2.x e 3.0?
Como deteto lentidão de consultas no InfluxDB?
Como monitorizo o armazenamento TSM do InfluxDB?
Esta integração afetará o desempenho do InfluxDB?
Comece a monitorizar InfluxDB hoje
Configure em menos de 60 segundos. Não é necessário cartão de crédito. Estatísticas completas desde o primeiro dia.
Iniciar período de avaliação gratuitaContinue a explorar