Apache Kafka Monitorização
Monitorize o estado dos brokers do Apache Kafka, o atraso nas partições, os grupos de consumidores e o débito em tempo real, sem necessidade de configuração.
Por que monitorizar Apache Kafka?
O Apache Kafka é a espinha dorsal dos fluxos de dados em tempo real e da transmissão de eventos. A monitorização do Kafka garante o bom funcionamento dos clusters de brokers, um atraso mínimo nos consumidores, uma distribuição ideal das partições e uma entrega fiável das mensagens.
Monitorização do Kafka, explicada
A monitorização do Kafka deteta partições sub-replicadas, partições offline, picos de lag em consumer groups, contrações de ISR, falhas de controlador e pressão de disco antes que causem perda de dados, falhas em microsserviços a jusante ou falhas totais de brokers. Para pipelines de CDC, sistemas de event sourcing, eventing de microsserviços e qualquer cluster Kafka em produção, a visibilidade por broker + por consumer group é o que separa um alerta em 60 segundos sobre um consumidor atrasado de encontrar um backlog de 50 milhões de mensagens ao fim do dia. O Xitoring descobre automaticamente os seus brokers, lê MBeans JMX + offsets de consumidores, e encaminha alertas para Slack, PagerDuty, Telegram ou para a sua equipa de plantão existente.
O que monitorizamos
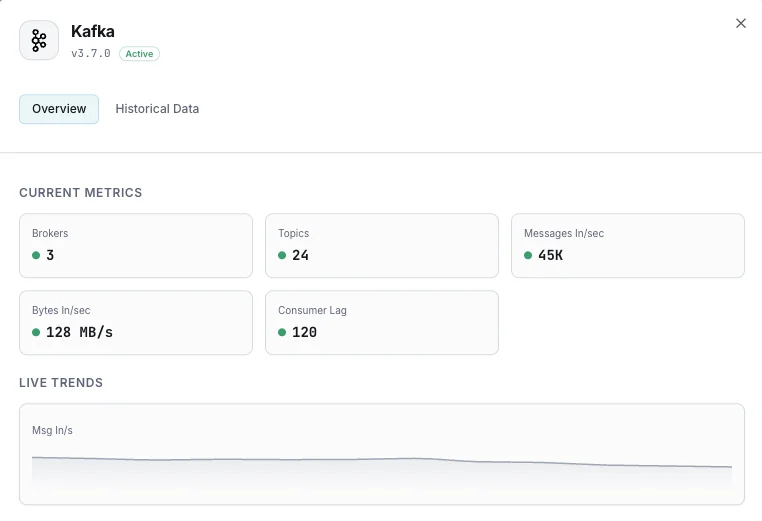
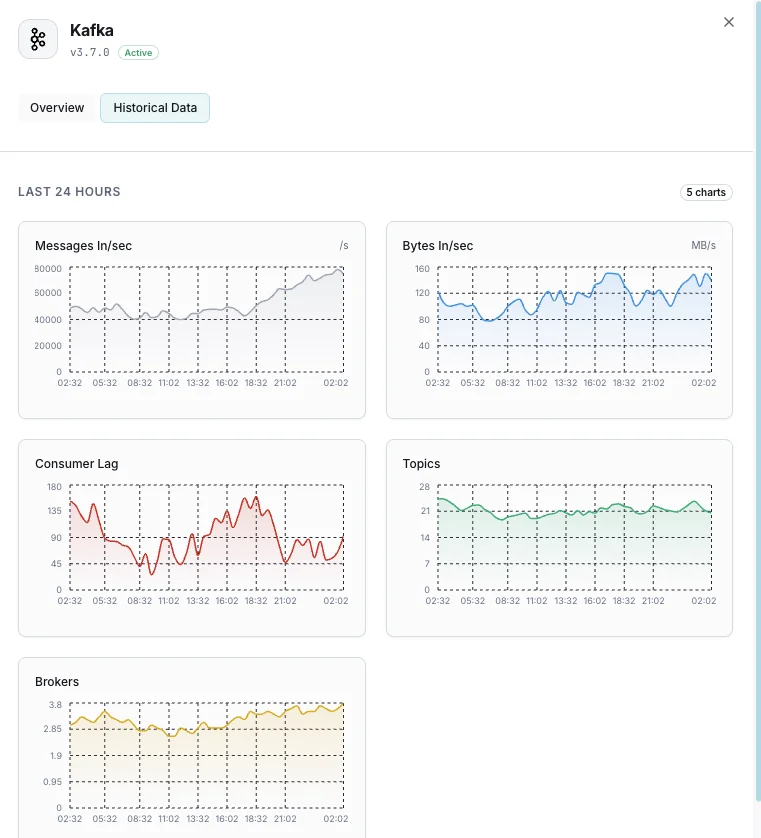
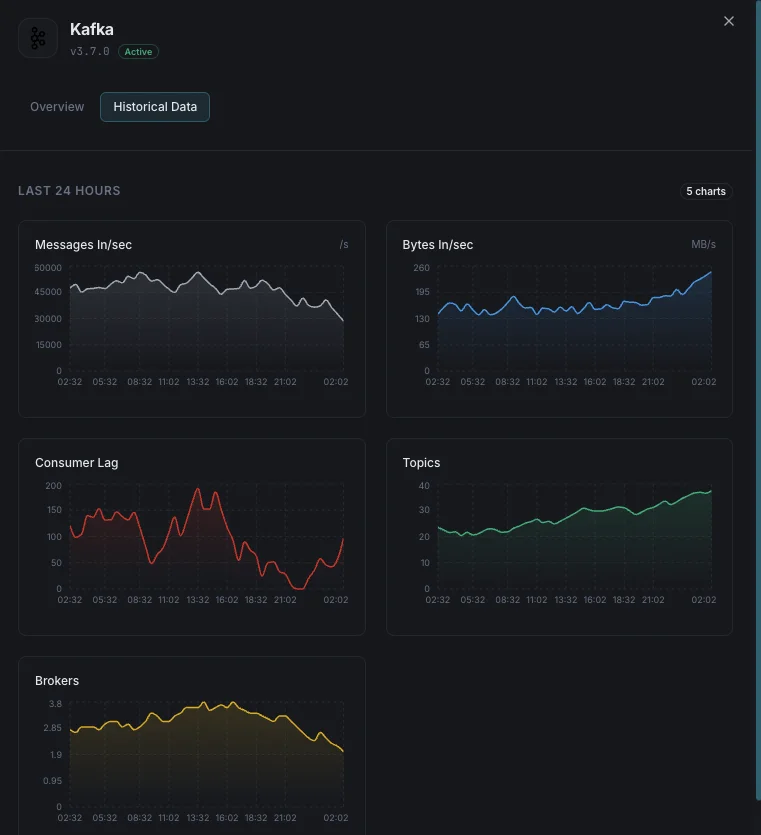
Número de brokers
Brokers ativos no cluster.
Lag dos consumidores
Mensagens em atraso para cada consumer group.
Mensagens recebidas/s
Taxa de ingestão de mensagens.
Bytes recebidos/enviados
Throughput de rede por broker.
Partições sub-replicadas
Partições abaixo do fator de replicação.
Reduções de ISR
Eventos de shrink de réplicas em sincronia.
UncleanLeaderElectionsPerSec
Taxa de réplicas fora de sincronia a serem promovidas a líder (com perda de dados). Deve ser 0 — diferente de zero significa que `unclean.leader.election.enable=true` E ocorreu um evento de falha real.
MessagesInPerSec / BytesIn / BytesOut
Débito por broker e por tópico. Quedas súbitas com contagem de produtores estável = problema de ingestão; picos súbitos = tempestade de retries ou produtor descontrolado.
Latência de pedidos (p99)
p99 do tempo de processamento de pedidos Produce, Fetch, Metadata em `kafka.network:type=RequestMetrics`. Apanha sobrecarga do broker antes que cause timeouts nos clientes.
LeaderCount por broker
Líderes de partição por broker. Distribuição desigual (um broker a deter 60%+ dos líderes) = cluster desequilibrado, corrija com `kafka-reassign-partitions.sh` ou.
Tamanho do log por tópico
Tamanho agregado do log em disco por tópico a partir de `kafka.log:type=Log,name=Size`. Alimenta alertas de espaço em disco e informa políticas de tiered storage no Kafka 3.8+.
RemoteLogManager (tiered storage)
Métricas de tiered storage do Kafka 3.8+: bytes carregados para o tier remoto, segmentos em remoto vs local, latência de fetch a partir do remoto. Apanha problemas de conectividade S3 / IAM que quebram fetches em tier remoto.
Configurável condições de alerta
Configure alertas personalizados no seu painel para ser notificado assim que as métricas dApache Kafka ultrapassarem os limites que definiu.
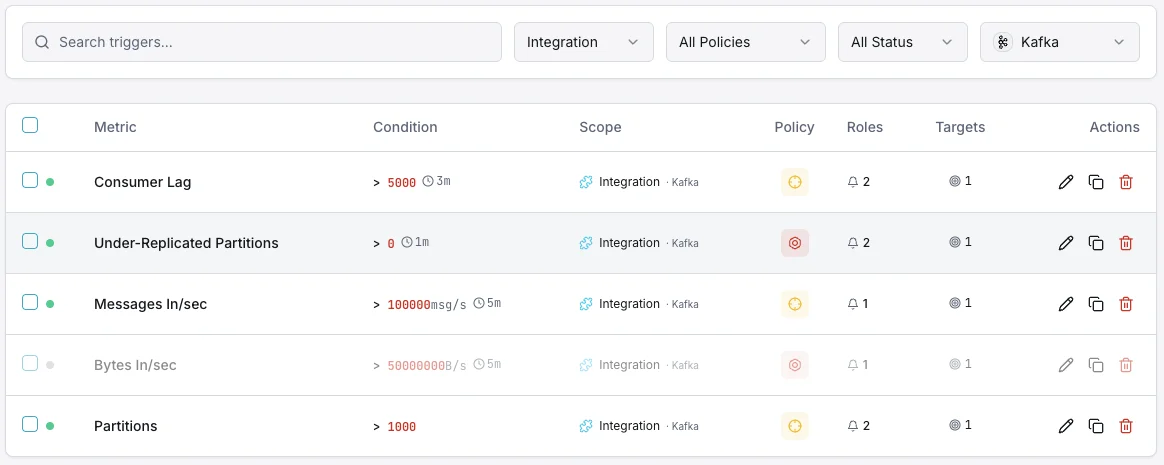
Lag dos consumidores
críticoDispara quando um consumidor fica para trás.
Partições sub-replicadas
críticoAlerta sobre problemas de replicação.
Broker em baixo
críticoDispara quando um broker abandona o cluster.
Utilização de disco
avisoDispara quando o disco do broker está a encher.
Importância da monitorização do Kafka
O Kafka processa biliões de mensagens diariamente. Lag dos consumidores, falhas de brokers e desequilíbrio de partições podem causar falhas em pipelines de dados.
- Detete o lag dos consumidores antes da perda de dados
- Monitorize o ISR para a durabilidade dos dados
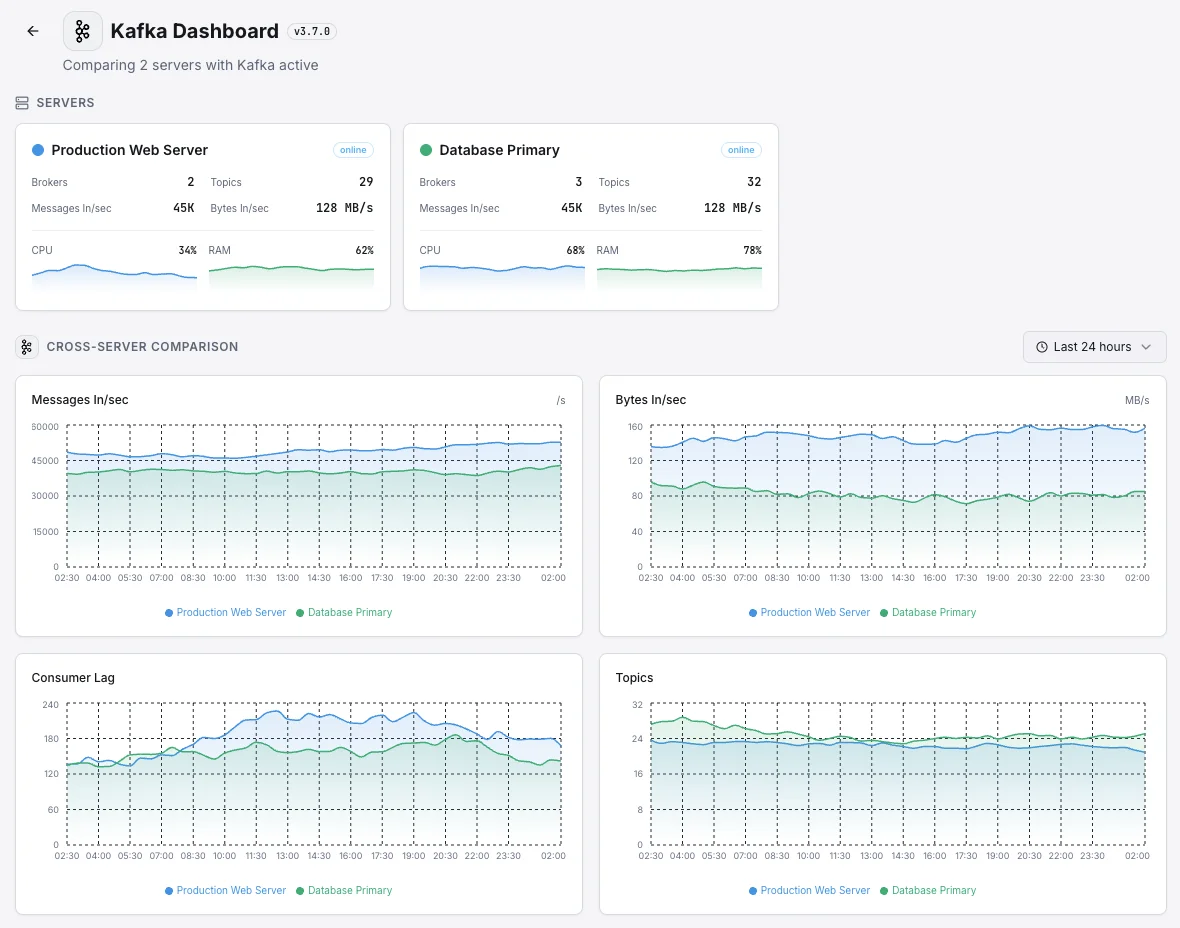
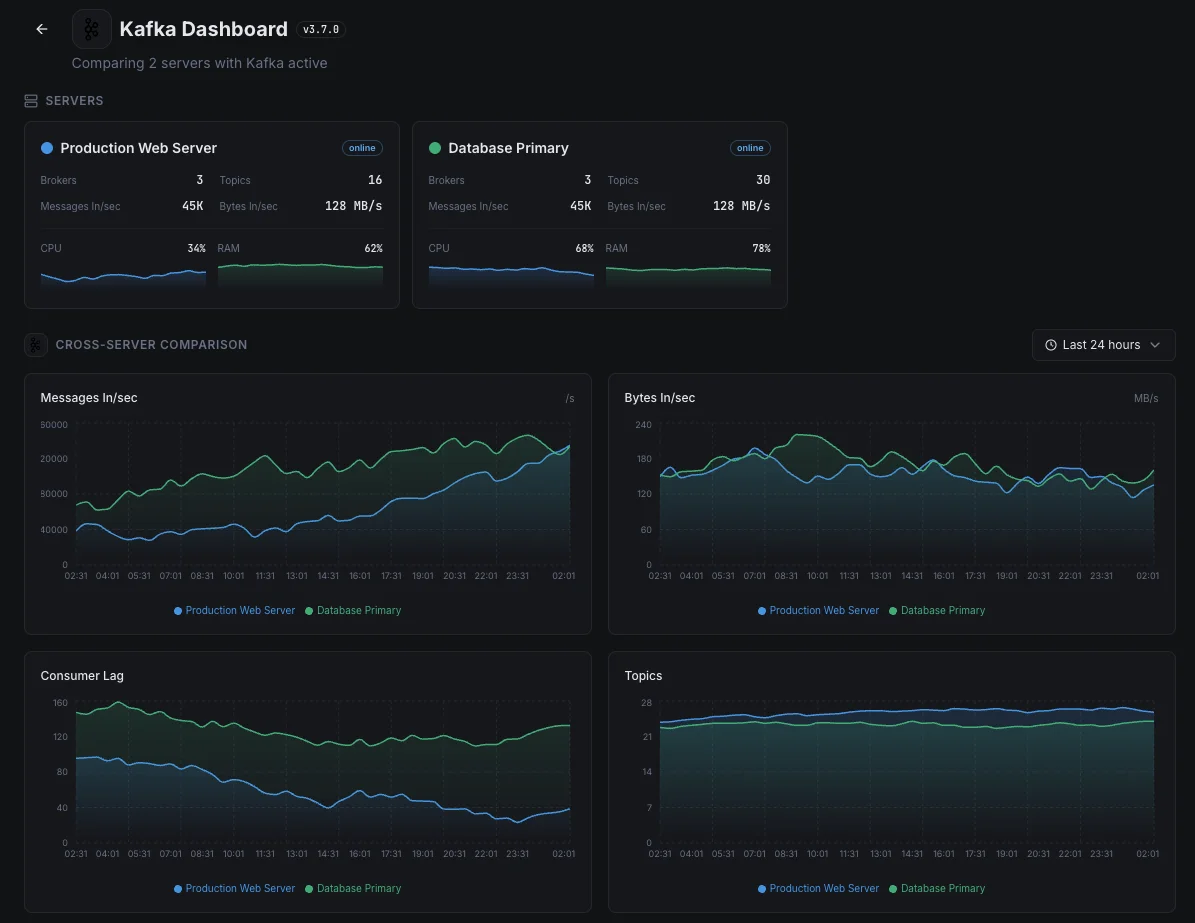
- Acompanhe a saúde dos brokers entre clusters
- Garanta o equilíbrio das partições
Porquê escolher Xitoring
Monitorização Kafka de nível empresarial.
- Configuração zero-config
- Nós globais
- Dashboard unificado
- Alertas multicanal
- Retenção histórica
Cenários comuns de monitorização do Kafka
Onde o Kafka normalmente é executado hoje — e o que pode correr mal se ninguém estiver a monitorizar.
A espinha dorsal de mensagens que conecta as suas aplicações
Quando o Kafka transporta as mensagens que movem dados entre as suas aplicações, qualquer lentidão significa que uma aplicação está silenciosamente a ficar para trás — e as consequências (atualizações atrasadas, dados desatualizados, fluxos de trabalho quebrados) só aparecem mais tarde. Detetamos o atraso no momento em que começa para que nunca se torne um problema visível para o cliente.
Kafka a correr dentro do Kubernetes
Quando o Kafka corre no Kubernetes, a plataforma move-o constantemente — e um reinício de rotina pode enfraquecer brevemente a rede de segurança que mantém os seus dados protegidos. Monitorizamos cada reinício e reequilíbrio para que uma atualização normal não possa silenciosamente deixar o sistema a uma falha de distância da perda de dados.
Kafka autogerido para dados de alto volume
Empresas que executam o seu próprio Kafka em escala precisam que ele seja sólido como uma rocha — geralmente está a transportar os dados mais valiosos que possuem. Monitorizamos os sinais que o mantêm saudável para que a equipa possa focar-se na construção de produtos em vez de combater incêndios na camada de mensagens.
Pré-requisitos para Apache Kafka
Certifique-se de que tem tudo isto pronto — depois disso, a maioria das instalações leva 60 segundos.
- Brokers Kafka com JMX ativado (porta predefinida 9999)
- Acessibilidade de rede do Xitogent à porta JMX de cada broker
- Credenciais de autenticação JMX se a segurança estiver configurada
Comece a minutos
Instalar o Xitogent em cada broker
Instale o leve agente de monitorização Xitogent em cada broker Kafka que pretende monitorizar.
curl -s https://xitoring.com/install.sh | sudo bash -s -- --key=YOUR_API_KEYAtivar JMX em cada broker
O Kafka expõe métricas de broker através de JMX. Defina `KAFKA_JMX_OPTS` para ativar um listener JMX (tipicamente porta 9999) em cada broker, recarregue o serviço e confirme que o host do agente consegue ligar-se à porta JMX.
sudo xitogent integrateAtivar a integração do Kafka
Use o painel do Xitoring ou a CLI para ativar a integração do Kafka. O Xitogent descobre automaticamente os IDs dos brokers, tópicos e consumer groups no cluster.
Configurar limiares de alerta (opcional)
Defina limiares personalizados para Consumer Lag, partições sub-replicadas ou eventos Broker Down para apanhar problemas de replicação e back-pressure antes que os consumers fiquem atrasados.
Confirme que está a funcionar
Execute este comando no servidor para confirmar que o Xitogent detetou a integração. Em cerca de 30 segundos começam a chegar novas métricas ao seu painel.
sudo xitogent statusEstá a considerar alternativas?
Veja como o Xitoring se compara às alternativas para a monitorização de Apache Kafka — preços fixos, integrações mais profundas e um único agente que cobre toda a sua stack.



Frequentemente perguntas feitas
Versões de Kafka?
ZooKeeper ou KRaft?
O que são partições sub-replicadas e como as corrijo?
Como monitorizo as métricas JMX dos brokers Kafka com Prometheus?
O que é o modo KRaft e como muda a monitorização sem ZooKeeper?
Como deteto partições offline no Kafka?
Como monitorizo um cluster Kafka em Kubernetes (Strimzi)?
Monitorização de Kafka vs Redpanda — quais são as diferenças?
Que versões do Kafka são suportadas?
Comece a monitorizar Apache Kafka hoje
Configure em menos de 60 segundos. Não é necessário cartão de crédito. Estatísticas completas desde o primeiro dia.
Iniciar período de avaliação gratuitaContinue a explorar