Supervisor Monitorização
Monitorize todos os processos geridos pelo Supervisor — estado (`RUNNING`/`FATAL`), tempo de atividade, encerramentos inesperados, ciclos de reinício e códigos de saída — em tempo real. Funciona com base no agente através do `supervisorctl`, com um alerta assim que um processo passa para o estado `FATAL`.
Por que monitorizar Supervisor?
O Supervisor (`supervisord`) mantém ativos os seus processos em segundo plano — workers do Celery e do Sidekiq, servidores de aplicações Gunicorn e uWSGI, consumidores de filas e daemons de longa duração. No entanto, após `startretries` tentativas falhadas de reinício, desiste e coloca o processo no estado `FATAL`, onde permanece inativo sem qualquer aviso. A monitorização por processo é a diferença entre um alerta de uma linha e uma fila entupida que ninguém reparou durante horas.
Monitorização por parte do supervisor, explicado
A monitorização do Supervisor consiste no acompanhamento contínuo do estado de todos os programas geridos pelo supervisord, além de emitir alertas quando um processo sai do estado RUNNING. O Supervisor é excelente a reiniciar um processo que falha — mas apenas startretries vezes dentro de startsecs. Se esse limite for ultrapassado, o processo passa para o estado FATAL e o Supervisor deixa de tentar. Nada mais repara nisso: o anfitrião está ativo, o daemon está ativo, a fila simplesmente deixa de ser esvaziada. Xitoring lê a tabela de processos em tempo real através do supervisorctl, acompanha cada programa de forma independente e envia um alerta para a sua rotação de plantão no instante em que um processo entra no estado FATAL, fica a oscilar num ciclo BACKOFF ou termina com um código de erro inesperado.
O que monitorizamos
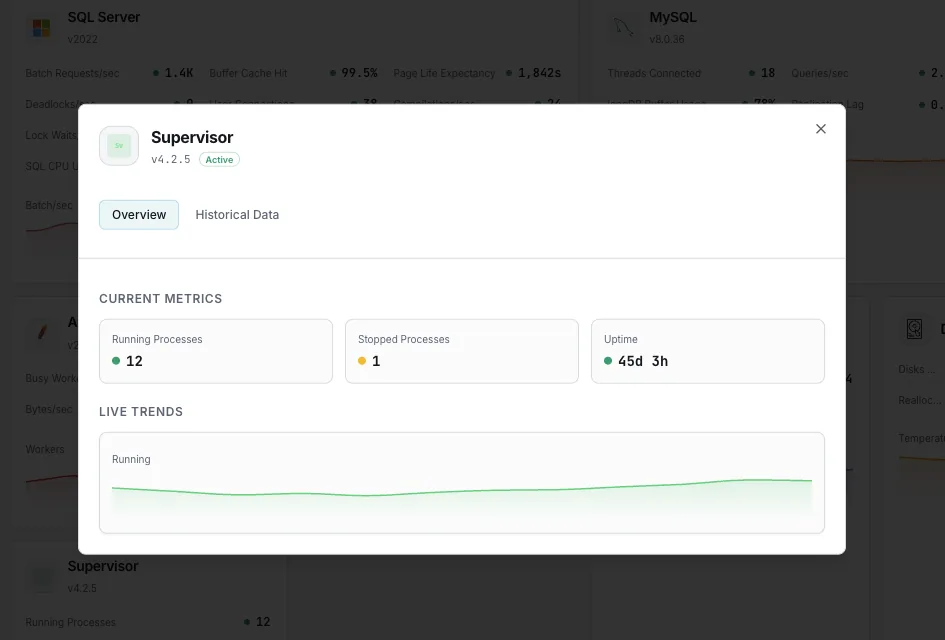
Estado do processo
O estado atual de cada programa (`RUNNING`, `STARTING`, `BACKOFF`, `EXITED`, `FATAL`, `STOPPED`, `STOPPING`, `UNKNOWN`). O sinal mais importante do Supervisor — qualquer coisa que não seja `RUNNING` para um trabalhador de execução prolongada constitui um problema.
Estado FATAL
Um processo que ultrapassou o limite `startretries` e foi abandonado pelo Supervisor. Não irá reiniciar por si próprio. Qualquer programa em `FATAL` constitui um sinal grave, digno de ser destacado.
BACKOFF / Reiniciar o ciclo
Um processo que continua a falhar antes do `startsecs` e está a ser reiniciado. Um `BACKOFF` prolongado significa que um worker instável está a consumir recursos da CPU nas reinicializações e nunca chega a processar o tráfego.
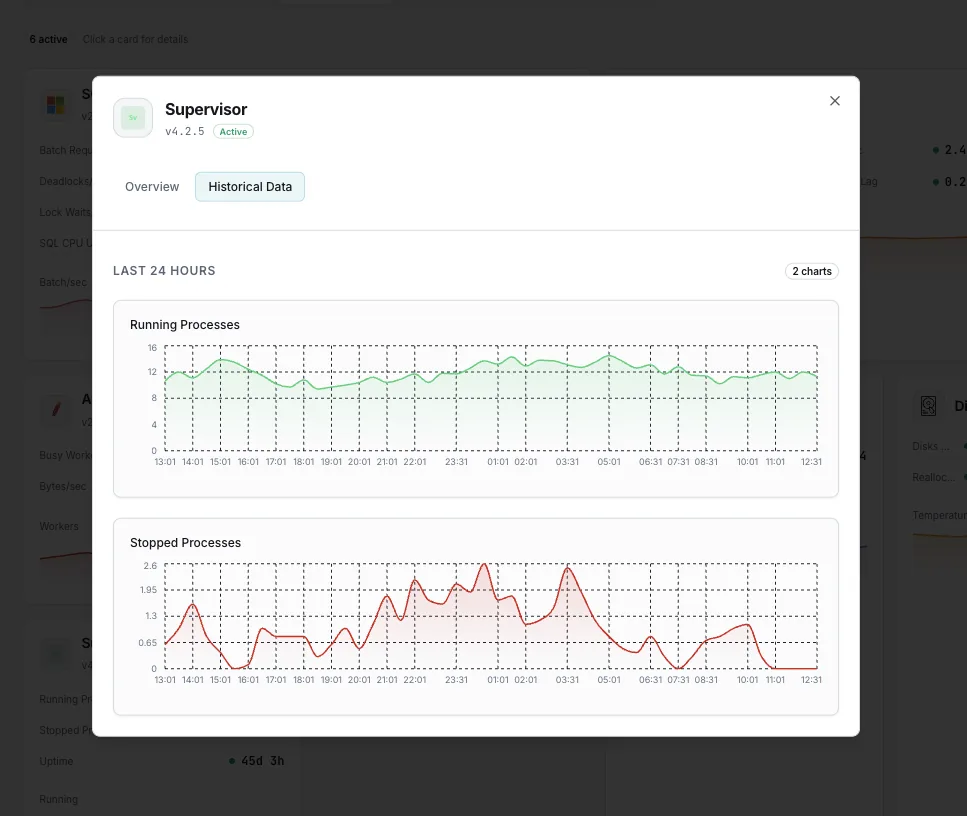
Tempo de funcionamento (desde o arranque)
Há quanto tempo cada processo mantém o seu PID atual. Um worker cujo tempo de atividade está constantemente a ser reiniciado está, silenciosamente, a entrar num ciclo de falhas, mesmo que apresente brevemente o estado `RUNNING` entre os reinícios.
PID do processo
O PID em tempo real de cada programa, obtido através do comando `supervisorctl status`. A sua presença confirma que o processo está efetivamente a ser executado, e não apenas configurado.
Código da Última Saída
O código de saída da execução mais recente. Compare-o com os `códigos de saída` do programa para distinguir um encerramento esperado de uma falha inesperada.
Em execução vs. Configurado
Contagem do número de processos efetivamente em `RUNNING` em relação ao número declarado (incluindo `numprocs`). Permite identificar rapidamente a falta de trabalhadores num grupo.
Saídas inesperadas
Encerra com um código fora do intervalo `exitcodes` quando `autorestart=unexpected`. Estas são as falhas que nunca deveriam ter ocorrido — uma tendência de aumento aponta para uma regressão.
Contagem de reinícios
A frequência com que cada processo foi reiniciado ao longo do tempo. A reinicialização constante de um processo que deveria funcionar de forma contínua constitui um sinal precoce de instabilidade ou de uma fuga de memória.
Processos interrompidos
Programas com o estado `STOPPED` ou `EXITED` que deveriam estar a ser executados. Deteta um processo que alguém parou manualmente e se esqueceu, ou que terminou sem reiniciar automaticamente.
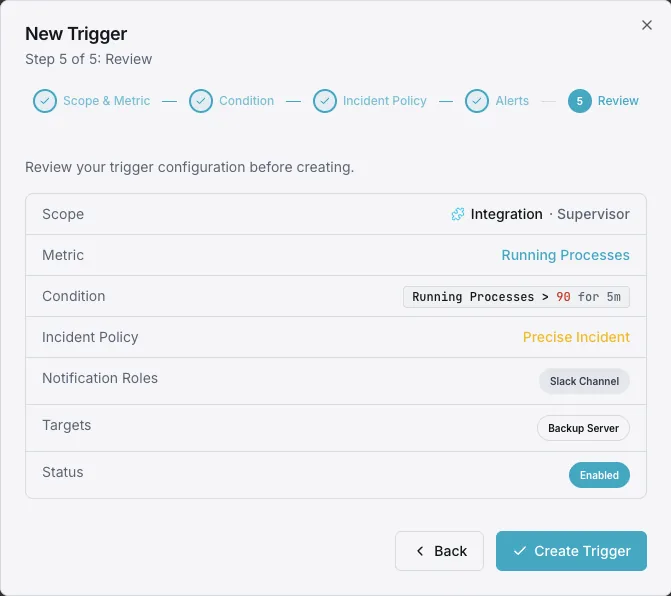
Configurável condições de alerta
Configure alertas personalizados no seu painel para ser notificado assim que as métricas dSupervisor ultrapassarem os limites que definiu.
Processo FATAL
críticoÉ acionado quando um processo entra no estado `FATAL` — o Supervisor desistiu de o reiniciar e o processo fica inativo até que alguém intervenha.
O processo não está a ser executado
críticoÉ acionado quando um programa que deveria estar em `RUNNING` está em `STOPPED`, `EXITED` ou `UNKNOWN`.
Reiniciar o ciclo
avisoAlertas em caso de `BACKOFF` prolongado ou reinícios repetidos — um worker que continua a falhar e nunca se estabiliza.
Código de saída inesperado
avisoÉ disparado quando um processo termina com um código que não se encontra entre os `exitcodes` configurados.
Importância de Monitorização do supervisor
O Supervisor irá reiniciar um processo que tenha entrado em falha — até que isso deixe de ser possível. Após o `startretries`, o processo fica em estado `FATAL` e permanece inativo, sem que haja qualquer indicação no anfitrião a alertar-te para isso.
- Detetar processos que atingem o estado `FATAL` e impedir que sejam reiniciados
- Detetar trabalhadores que ficam presos em loops `BACKOFF`
- Detetar reinícios silenciosos através da reinicialização do tempo de atividade
- Saiba quando os trabalhadores saem com códigos inesperados
Por que escolher Xitoring
Monitorização do Supervisor baseada em agentes, com configuração automática e visibilidade por processo em todos os programas geridos pelo supervisord.
- Instalação e integração com um único comando
- Acompanhamento por processo e por grupo
- Não há nenhuma interface XML-RPC ou HTTP a disponibilizar
- Alertas multicanal para a sua escala de plantão
- Estado histórico e histórico de reinícios
Monitorização do Supervisor Comum cenários
Onde o Supervisor costuma ser executado — e o que falha silenciosamente quando ninguém está a ver.
Processos em segundo plano (Celery, Sidekiq, RQ, Resque)
Os trabalhadores da fila são precisamente os processos que terminam silenciosamente — uma implementação mal sucedida ou uma mensagem inválida leva-os a entrar num ciclo de reinício, seguido de FATAL. Emitimos um alerta assim que um trabalhador deixa de funcionar, antes que a fila fique congestionada e as tarefas comecem a atingir o tempo limite.
Servidores de aplicações e daemons (Gunicorn, uWSGI, Daphne, Node)
Quando o Supervisor gere o seu servidor de aplicações, um processo que não arranca após uma implementação significa que o site está em baixo, embora o estado do servidor continue a indicar «verde». Detetamos os erros FATAL e BACKOFF instantaneamente, para que, em caso de falha na implementação, seja enviado um aviso a alguém, em vez de ficarmos à espera de uma notificação do cliente.
Processos em contentores e em hosts antigos
Muitos contentores e servidores mais antigos utilizam o Supervisor em vez do systemd para manter vários processos ativos num único local. Monitorizamos cada um deles de forma independente, para que um único processo que tenha falhado num contentor com muita atividade não passe despercebido por entre os outros.
Pré-requisitos para Supervisor
Certifique-se de que tem tudo isto pronto — depois disso, a maioria das instalações leva 60 segundos.
- Um servidor Linux com o Supervisor (
supervisord) instalado e a gerir, pelo menos, um programa - O Xitogent está instalado no mesmo anfitrião e é possível executar o comando
supervisorctl status - Aceda para executar o comando
sudo xitogent integratee selecione a integração com o Supervisor
Comece a minutos
Instale o Xitogent no seu servidor
Instale o agente de monitorização leve da Xitogent no anfitrião onde está a ser executado o Supervisor.
curl -s https://xitoring.com/install.sh | sudo bash -s -- --key=YOUR_API_KEYAtivar a integração com o Supervisor
Execute `sudo xitogent integrate` e selecione o Supervisor. O Xitogent cria o ficheiro `/etc/xitogent/integrations/supervisor_integration.conf`, lê a tabela de processos através do `supervisorctl` e deteta automaticamente todos os programas e grupos sob o `supervisord` — não é necessário alterar a configuração do Supervisor.
sudo xitogent integrateConfigurar gatilhos (opcional)
Defina gatilhos e níveis de gravidade por processo no painel do Xitoring — por exemplo, envie uma notificação sempre que um processo entrar no estado `FATAL` e emita um aviso em caso de estado `BACKOFF` prolongado ou de um código de saída inesperado — para que as falhas cheguem à equipa de plantão antes que a fila fique congestionada.
Confirme que está a funcionar
Execute este comando no servidor para confirmar que o Xitogent detetou a integração. Em cerca de 30 segundos começam a chegar novas métricas ao seu painel.
sudo xitogent statusEstá a considerar alternativas?
Veja como o Xitoring se compara às alternativas para a monitorização de Supervisor — preços fixos, integrações mais profundas e um único agente que cobre toda a sua stack.



Frequentemente perguntas feitas
O que é a monitorização do Supervisor?
Como é que a Xitoring recolhe os dados dos supervisores?
Como posso configurar a integração com o Supervisor?
O que significam os estados do processo «Supervisor»?
O que significa o estado FATAL e por que é que isso é importante?
Como posso detetar um ciclo de reinício do Supervisor?
Qual é a diferença entre «autorestart» «true», «false» e «unexpected»?
Posso monitorizar vários processos e grupos de processos?
Supervisor vs. systemd — por que monitorizar especificamente o Supervisor?
Comece a monitorizar Supervisor hoje
Configure em menos de 60 segundos. Não é necessário cartão de crédito. Estatísticas completas desde o primeiro dia.
Iniciar período de avaliação gratuitaContinue a explorar