CoreDNS Suivi
Surveillez en temps réel le nombre de requêtes CoreDNS, les taux de réussite du cache, le temps de résolution et les taux d'erreur, sans aucune configuration.
Pourquoi surveiller ? CoreDNS?
CoreDNS est le serveur DNS par défaut pour Kubernetes et les environnements cloud natifs. La surveillance de CoreDNS garantit une résolution DNS rapide, des performances de cache optimales et une découverte de services fiable pour votre infrastructure.
Le monitoring CoreDNS, expliqué
Le monitoring CoreDNS détecte les pics de SERVFAIL, les baisses du taux de hit du cache, la latence du plugin forward et les redémarrages liés à des panics avant qu'ils ne se transforment en cascade de défaillances de résolution DNS à l'échelle du cluster. Comme chaque microservice dépend du DNS pour la découverte de service, un CoreDNS non surveillé est un mode de défaillance non surveillé pour tout votre cluster Kubernetes — les problèmes de DNS apparaissent comme des « connection refused aléatoires » partout. Xitoring découvre automatiquement votre CoreDNS, scrape :9153/metrics et achemine les alertes vers Slack, PagerDuty, Telegram ou votre astreinte existante.
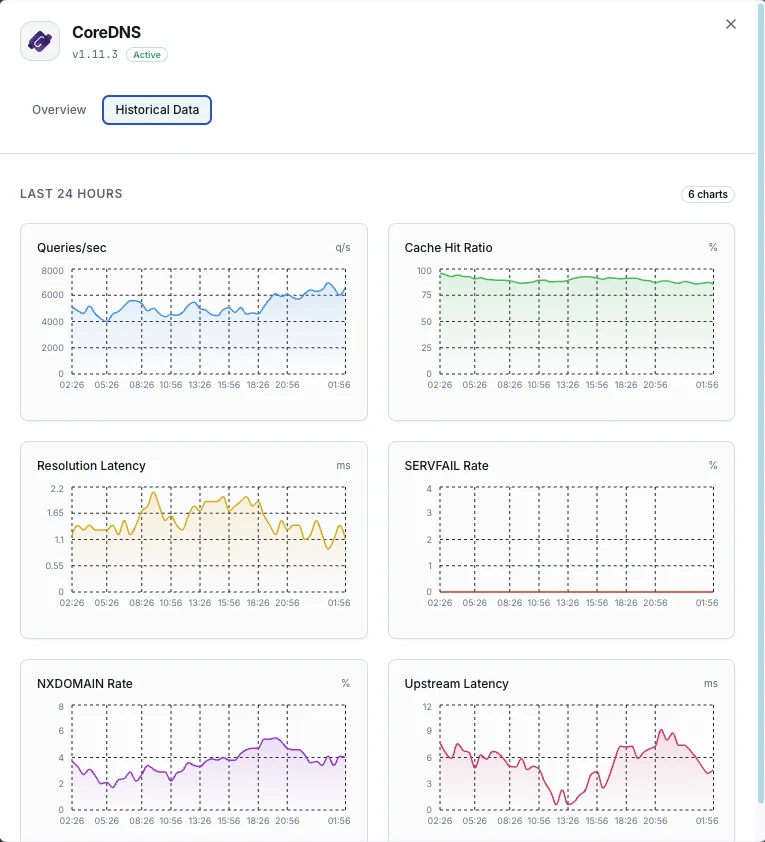
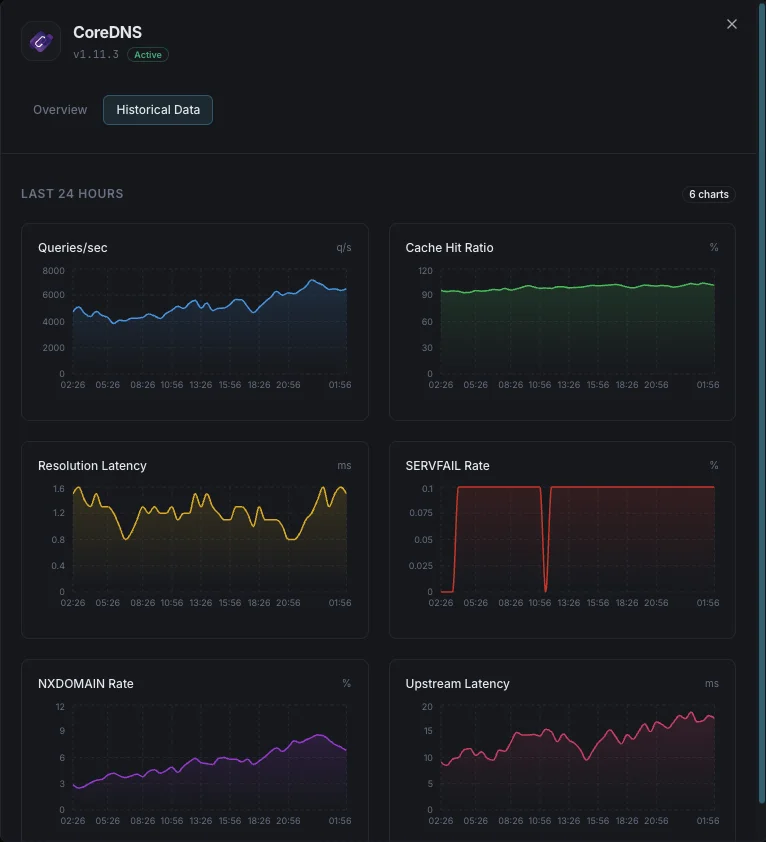
Ce que nous surveillons
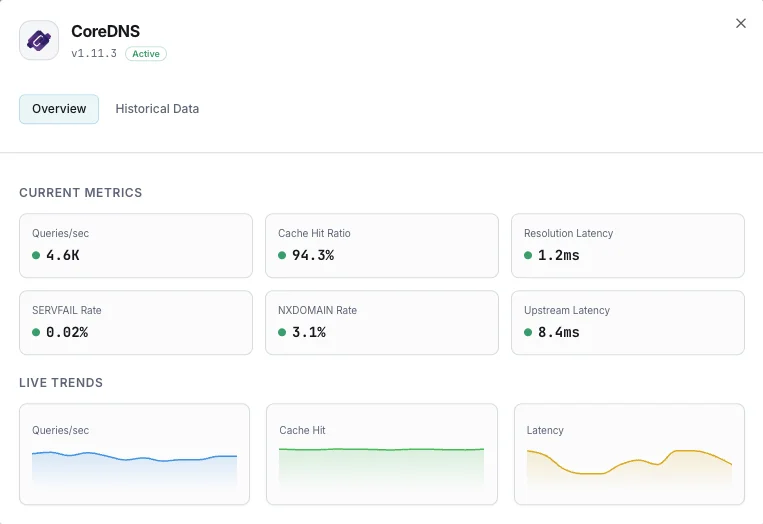
Requêtes/sec
Taux de requêtes DNS.
Ratio de hits du cache
Pourcentage de requêtes servies depuis le cache.
Latence de résolution
Temps moyen de résolution DNS.
Taux SERVFAIL
Pourcentage de résolutions en échec.
Taux NXDOMAIN
Taux de requêtes pour domaines inexistants.
Latence en amont
Temps de réponse des requêtes transférées.
Latence du plugin Forward
`coredns_forward_request_duration_seconds` par résolveur amont. Sépare la latence interne à CoreDNS de la latence du résolveur amont — essentiel pour diagnostiquer une lenteur côté 8.8.8.8 vs une lenteur côté CoreDNS lui-même.
Taux de requêtes Forward
`coredns_forward_request_count_total` par amont. Combiné au ratio de hit du cache, montre quelle part du trafic quitte effectivement CoreDNS pour la résolution amont.
Cache des connexions Proxy
`coredns_proxy_conn_cache_hits_total` / `_misses_total`. Suit la réutilisation des connexions TCP vers les résolveurs amont — un faible taux de hit signifie un churn de connexions, augmentant la latence amont.
Échecs du plugin Health
`coredns_health_request_failures_total` — le nombre d'échecs propre au plugin `health:8080`. Une valeur non nulle signifie que la liveness probe échoue par intermittence.
Panics
`coredns_panics_total` — toute valeur non nulle est un bug CoreDNS ou un crash de plugin ayant déclenché une panic de goroutine. À combiner avec le compteur de redémarrages pour un contexte post-mortem complet.
Runtime Go
`process_resident_memory_bytes` (RSS), `go_goroutines` (nombre de goroutines — détecte les fuites), `go_gc_duration_seconds` (temps de pause GC). Croissance mémoire sans redémarrages = fuite ; croissance du nombre de goroutines = plugin ou amont bloqué.
Configurables déclencheurs d'alerte
Configurez des déclencheurs personnalisés dans votre tableau de bord pour être averti dès que les indicateurs d{name}s dépassent les seuils que vous avez définis.
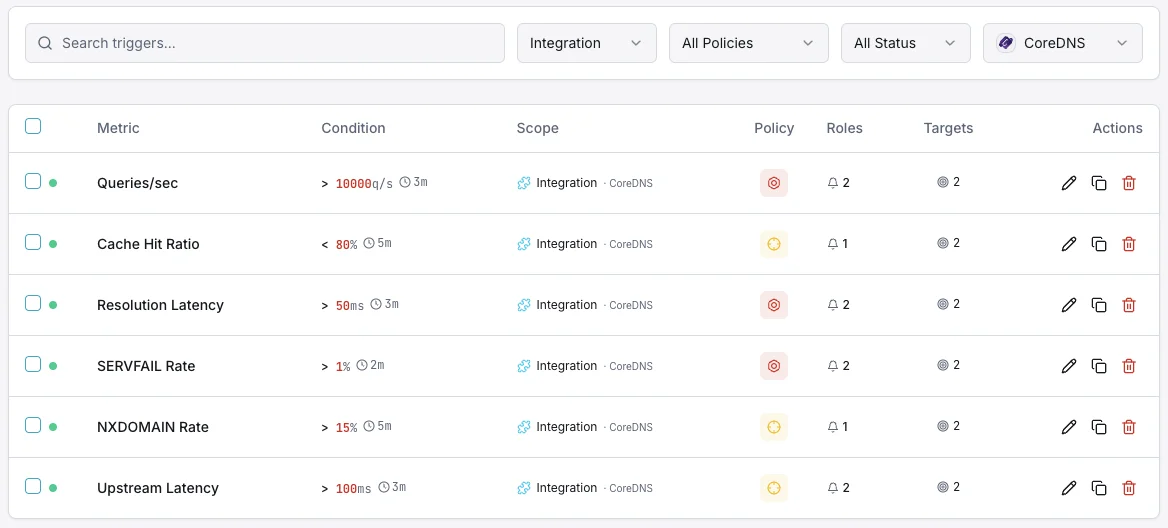
Taux SERVFAIL
crucialSe déclenche en cas de taux élevé d'échecs de résolution.
Ratio de hits du cache
avertissementAlerte lorsque l'efficacité du cache chute.
Latence de résolution
avertissementSe déclenche en cas de résolution DNS lente.
Taux de requêtes
avertissementSe déclenche sur un volume de requêtes inhabituel.
Importance de la surveillance CoreDNS
Le DNS est la base de la connectivité réseau. Une résolution DNS lente ou défaillante impacte chaque service de votre infrastructure.
- Garantir une résolution DNS rapide
- Détecter immédiatement les pics de SERVFAIL
- Surveiller le cache pour des performances optimales
- Suivre la santé des résolveurs en amont
Pourquoi choisir Xitoring
Surveillance CoreDNS sans configuration.
- Installation en une commande
- Nœuds mondiaux
- Tableau de bord unifié
- Alertes multicanaux
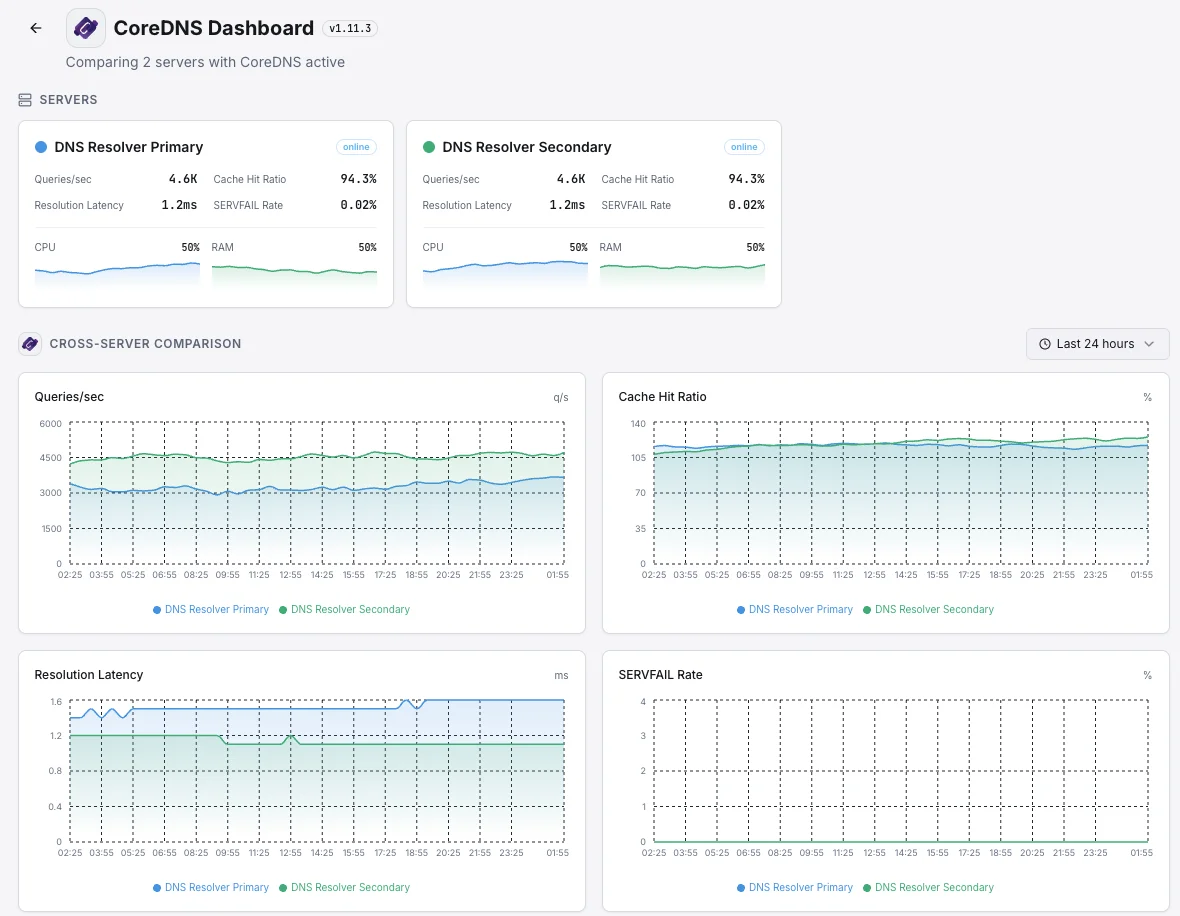
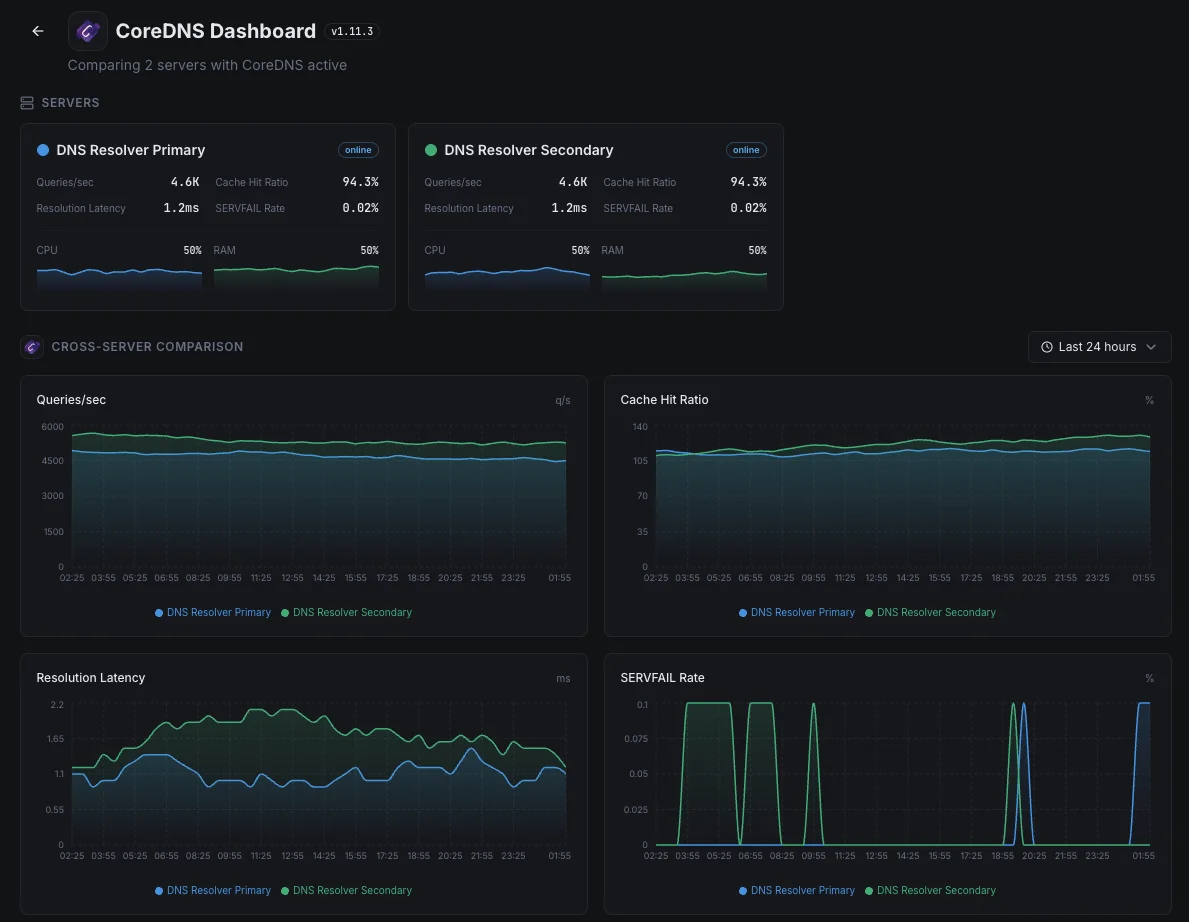
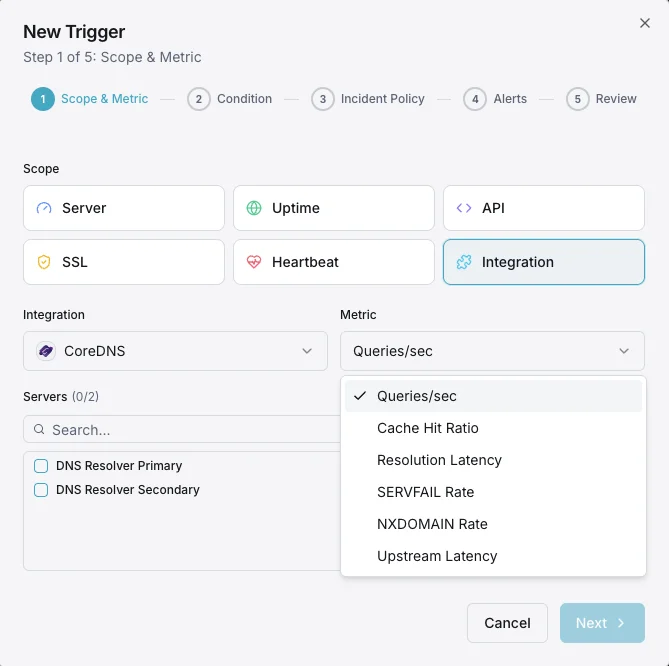
Scénarios courants de monitoring CoreDNS
Où CoreDNS fonctionne généralement aujourd'hui — et ce qui pourrait mal tourner si personne ne surveille.
DNS au sein d'une application Kubernetes
Chaque partie d'une application Kubernetes utilise CoreDNS pour trouver toutes les autres parties. Lorsqu'il ralentit ou commence à échouer, les utilisateurs voient des erreurs étranges et intermittentes sur l'ensemble de l'application. Nous détectons le ralentissement dès qu'il commence, afin qu'un petit hoquet DNS ne se manifeste pas aux clients comme une panne mystérieuse.
Grands clusters avec caches DNS locaux
Les grandes configurations Kubernetes placent un petit cache DNS sur chaque serveur pour accélérer les choses. Lorsqu'un de ces caches se comporte mal, seule une partie du trafic est interrompue — ce qui le rend difficile à repérer. Nous nous assurons que chacun fait son travail afin qu'un seul nœud défectueux ne puisse pas dégrader silencieusement une fraction de vos utilisateurs.
DNS public pour votre domaine
Lorsque CoreDNS est ce qui répond aux requêtes DNS pour votre domaine sur l'internet ouvert, une panne signifie que les gens ne peuvent pas du tout atteindre votre site. Nous surveillons les signaux qui prouvent que le service est sain et répond, afin que la marque et les revenus ne saignent pas silencieusement pendant que le DNS échoue en silence.
Prérequis pour CoreDNS
Assurez-vous d'avoir tout cela en place — la plupart des installations sont une affaire de 60 secondes une fois ces conditions réunies.
- CoreDNS 1.x tournant sur le serveur
- Plugin Prometheus activé dans votre Corefile (port par défaut 9153)
- Accessibilité réseau de Xitogent vers l'endpoint metrics
Commencez par procès-verbal
Installer Xitogent sur votre serveur
Si ce n'est pas déjà fait, installez l'agent de monitoring léger Xitogent sur l'hôte qui exécute CoreDNS.
curl -s https://xitoring.com/install.sh | sudo bash -s -- --key=YOUR_API_KEYActiver le plugin prometheus dans CoreDNS
CoreDNS expose des métriques au format Prometheus via son plugin prometheus (endpoint par défaut :9153/metrics). Ajoutez `prometheus :9153` à votre Corefile, rechargez CoreDNS, puis confirmez que l'endpoint metrics est accessible depuis l'hôte de l'agent.
sudo xitogent integrateActiver l'intégration CoreDNS
Utilisez le tableau de bord Xitoring ou la CLI pour activer l'intégration CoreDNS. Xitogent détecte automatiquement l'endpoint metrics et commence à collecter les métriques de requêtes, cache et latence.
Configurer les seuils d'alerte (facultatif)
Définissez des seuils personnalisés pour le taux de SERVFAIL, le taux de cache hit ou la latence de résolution pour être notifié dès que la fiabilité ou les performances DNS se dégradent.
Vérifier que tout fonctionne
Exécutez cette commande sur le serveur pour confirmer que Xitogent a bien détecté l'intégration. De nouvelles métriques apparaîtront sur votre tableau de bord dans environ 30 secondes.
sudo xitogent statusVous envisagez des alternatives ?
Découvrez comment Xitoring se positionne face aux alternatives pour la surveillance de CoreDNS — tarifs forfaitaires, intégrations plus poussées et un seul agent pour couvrir tout votre stack.



Souvent a posé des questions
CoreDNS de Kubernetes ?
Les indicateurs Prometheus ?
À quoi sert le plugin kubernetes ?
Comment surveiller le ratio de hit du cache CoreDNS ?
Que signifie NXDOMAIN dans les métriques CoreDNS ?
Comment déboguer CoreDNS dans Kubernetes ?
Comment surveiller la latence du plugin forward de CoreDNS ?
Quand faut-il utiliser NodeLocal DNSCache ?
Quelles versions de CoreDNS sont prises en charge ?
Commencer à surveiller CoreDNS aujourd'hui
Configuration en moins de 60 secondes. Aucune carte bancaire requise. Statistiques complètes dès le premier jour.
Commencer l'essai gratuit