Disk Health Suivi
Surveillez en temps réel les attributs SMART des disques, leur température, les secteurs réaffectés et les indicateurs de défaillance prédictive sur les SSD et les disques durs.
Pourquoi surveiller ? Disk Health?
Les pannes de disque dur constituent l'une des principales causes de perte de données et d'arrêts imprévus. La solution de surveillance de l'état des disques de Xitoring s'appuie sur la technologie SMART (Self-Monitoring, Analysis, and Reporting Technology) pour vous alerter à temps avant que les disques ne tombent en panne. Elle prend en charge les SSD, les disques durs et les configurations RAID, tant sous Linux que sous Windows.
Le monitoring de la santé des disques, expliqué
Le monitoring de la santé des disques détecte la croissance des secteurs réalloués, l'usure NVMe, les pics de température et les indicateurs de défaillance imminente des jours, voire des semaines, avant que les disques ne lâchent — assez longtemps pour migrer les données et remplacer le disque sans interruption. Pour les serveurs de base de données, les hôtes de sauvegarde et toute charge où une défaillance disque signifie perte de données, le monitoring SMART est l'alerte au plus haut ROI que vous puissiez mettre en place. Xitoring exécute localement smartctl + nvme-cli et achemine les alertes vers Slack, PagerDuty, Telegram ou votre astreinte existante.
Ce que nous surveillons
État de santé SMART
Indicateur global de santé du disque (succès/échec).
Température
Température actuelle du disque en degrés Celsius.
Secteurs réalloués
Nombre de secteurs défectueux remappés.
Heures de mise sous tension
Heures de fonctionnement totales du disque.
Taux d'erreurs de lecture
Taux d'erreurs de lecture rencontrées.
Secteurs en attente
Secteurs en attente de remappage.
Temperature_Celsius (SMART 194)
Température actuelle du disque. Les HDD se dégradent au-delà de 50 °C ; les SSD grand public limitent leurs performances au-delà de 70 °C. Alertez à la température max constructeur moins 10 °C pour un avertissement précoce.
UDMA_CRC_Error_Count (SMART 199)
Erreurs CRC liées au câble sur l'interface SATA/SAS. Des valeurs en hausse signalent un mauvais câble ou une connexion mal serrée — un correctif facile souvent diagnostiqué à tort comme défaillance de disque.
Usure SSD (Wear_Leveling_Count + Total_LBAs_Written)
Suivi d'endurance SSD. `Wear_Leveling_Count` normalise la durée de vie restante ; `Total_LBAs_Written` combiné au TBW nominal du disque donne le pourcentage d'usure actuel. Alertez à 80 % utilisé.
NVMe percentage_used
Depuis `nvme smart-log` — estimation constructeur de la durée de vie consommée (0–100 %, peut dépasser 100 % sur les disques usés). Avertissement au-dessus de 80 % ; critique au-dessus de 95 %.
NVMe available_spare
Pourcentage de capacité de réserve restante pour le remplacement de blocs défectueux. Avertissement sous 10 % ; critique sous 5 % (`available_spare_threshold` est typiquement défini à cette valeur).
NVMe critical_warning
Bitfield depuis `nvme smart-log` signalant : spare sous le seuil, température au-dessus du seuil, fiabilité du dispositif dégradée, mode lecture seule, échec de sauvegarde mémoire volatile. Toute valeur non nulle = alerte immédiate.
Configurables déclencheurs d'alerte
Configurez des déclencheurs personnalisés dans votre tableau de bord pour être averti dès que les indicateurs d{name}s dépassent les seuils que vous avez définis.
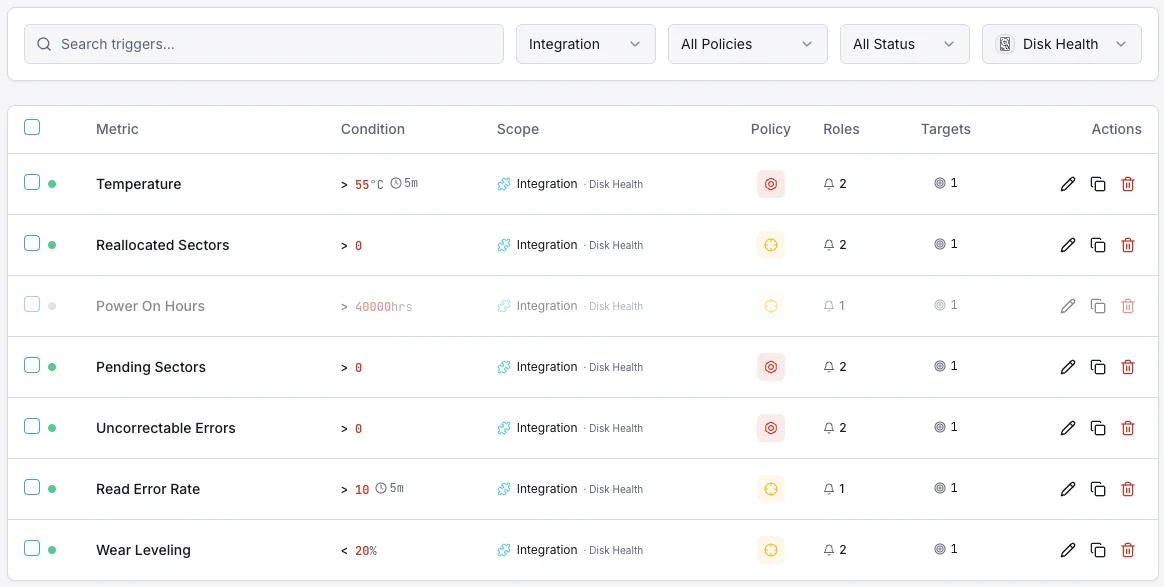
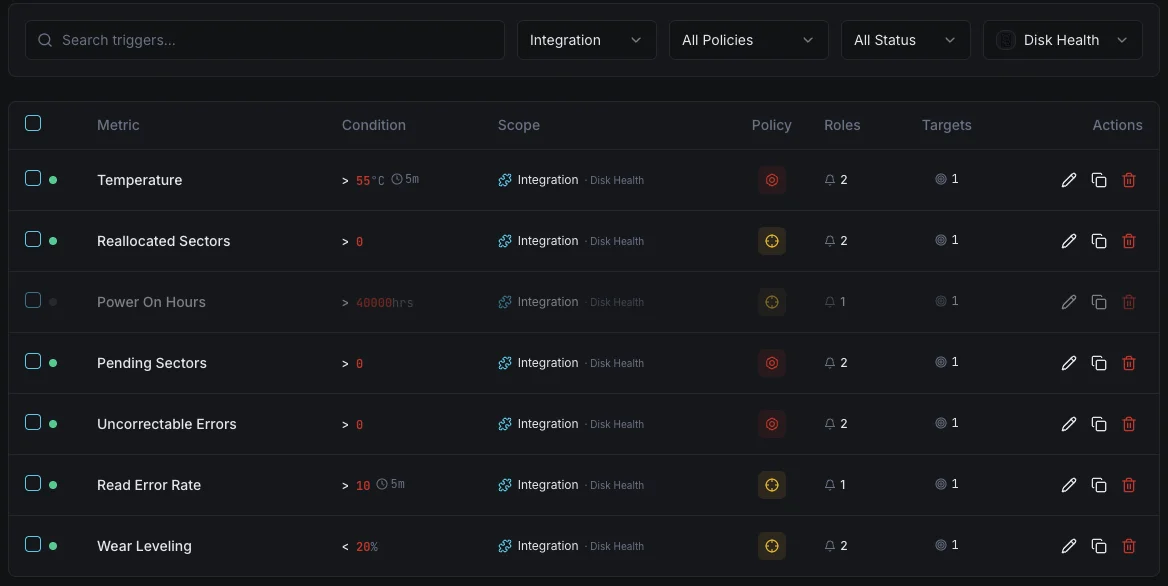
État de santé SMART
crucialSe déclenche lorsque SMART signale un état de santé en échec.
Secteurs réalloués
crucialAlerte lorsque le nombre de secteurs réalloués dépasse le seuil.
Température du disque
avertissementSe déclenche lorsque la température du disque sort de la plage d'exploitation sûre.
Secteurs en attente
avertissementSe déclenche lorsque le nombre de secteurs en attente indique une défaillance potentielle.
Importance de la surveillance de la santé des disques
Les défaillances de disque peuvent entraîner des pertes de données et des temps d'arrêt coûteux. La surveillance SMART fournit des signes avant-coureurs précoces — de la hausse des températures à l'augmentation des secteurs réalloués en passant par les pics d'erreurs de lecture — afin que vous puissiez agir avant la panne d'un disque.
- Évitez la perte de données grâce à la détection précoce des défaillances
- Optimisez les performances en identifiant les goulets d'étranglement
- Planifiez la capacité avec une analyse historique des tendances
- Maintenez la conformité grâce à la surveillance de l'intégrité des données
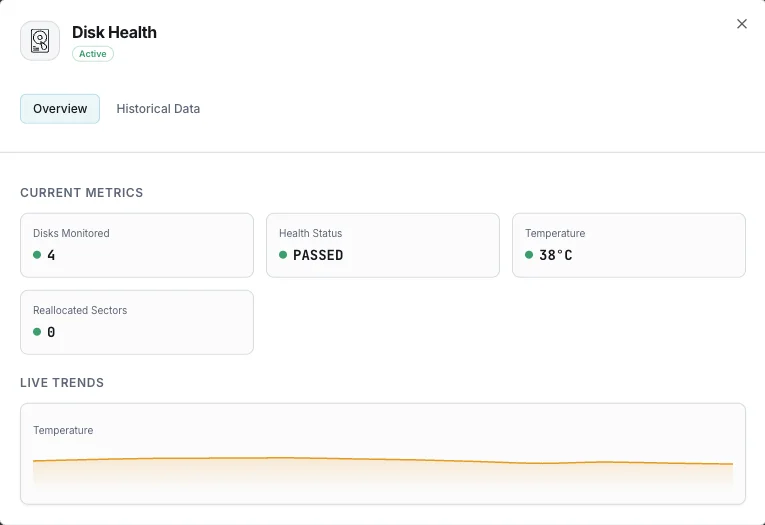
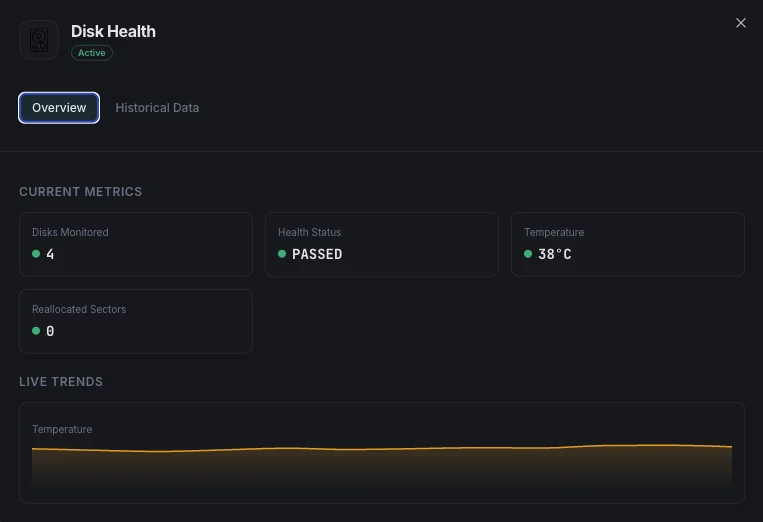
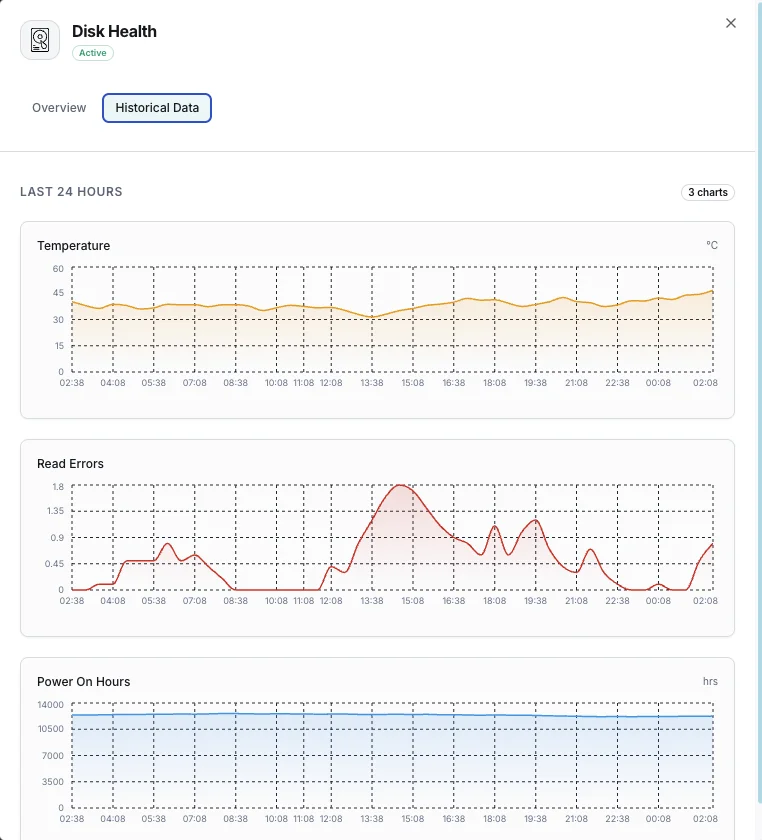
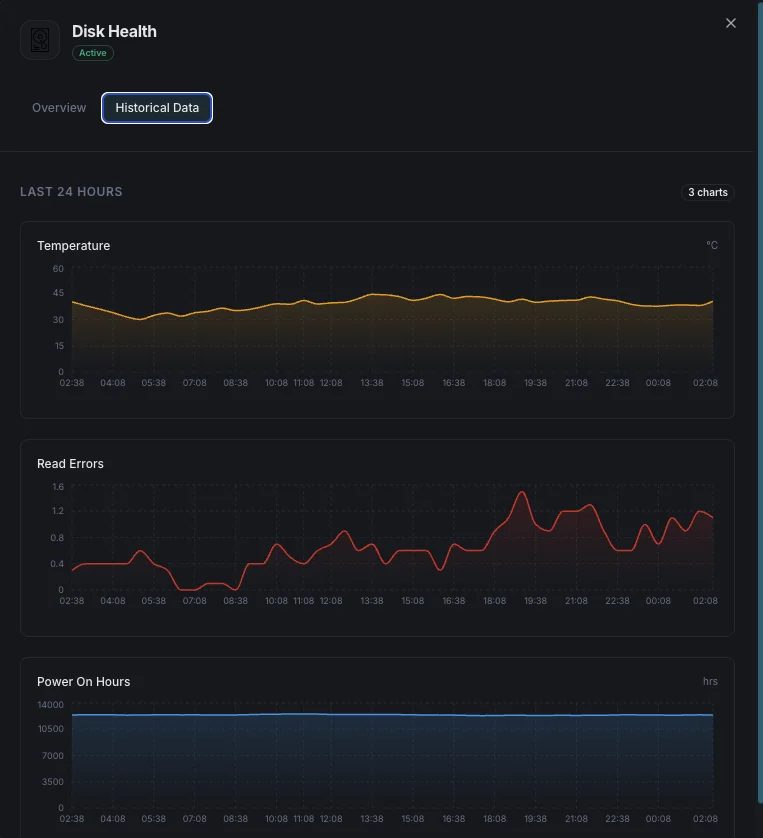
Pourquoi choisir Xitoring
Xitoring fournit une surveillance de la santé des disques sans configuration, avec intégration SMART pour tous les types de disques. Obtenez des alertes en temps réel, des tendances historiques et des indicateurs prédictifs de défaillance dans un tableau de bord unifié.
- Compatible avec SSD, HDD et matrices RAID
- Configuration en une commande sur Linux et Windows
- Seuils d'attributs SMART personnalisables
- Alerting multicanal pour les événements critiques de disque
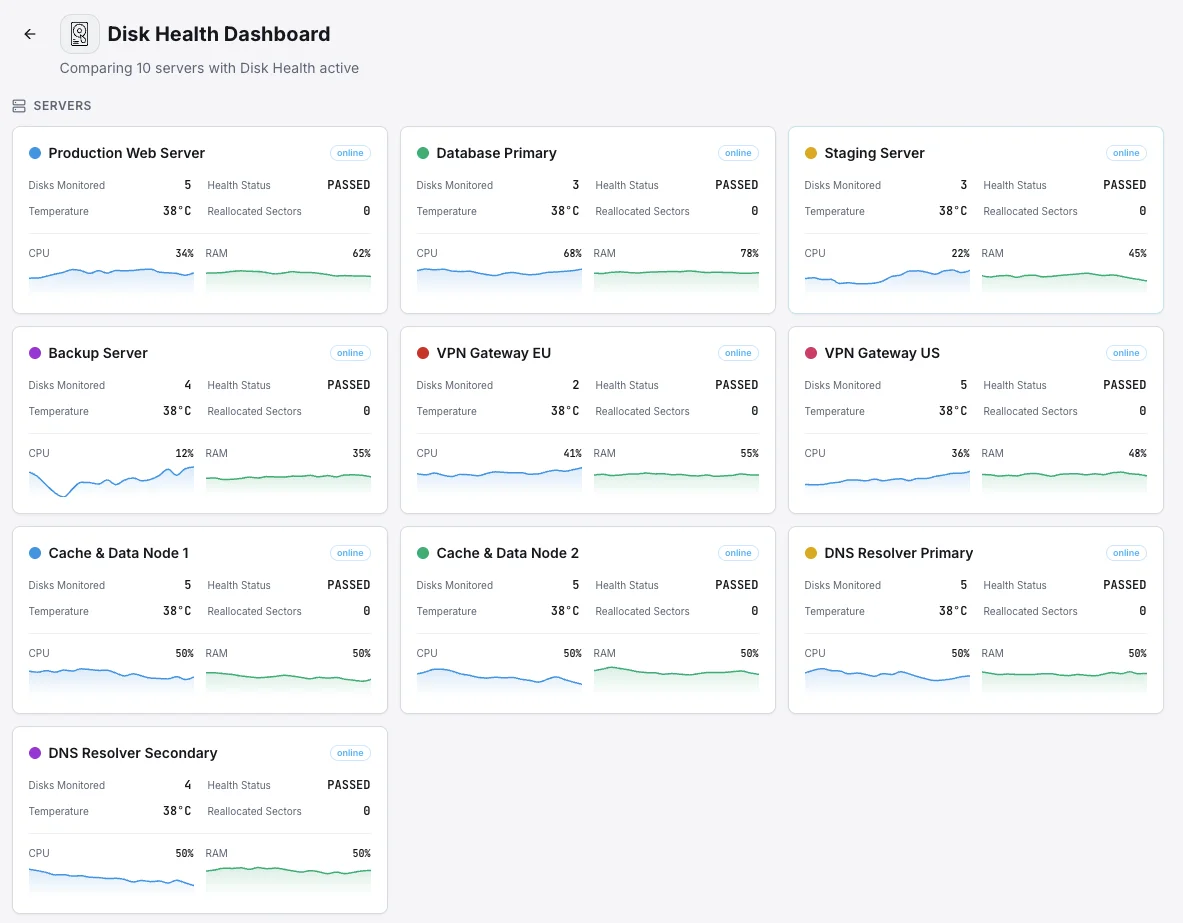
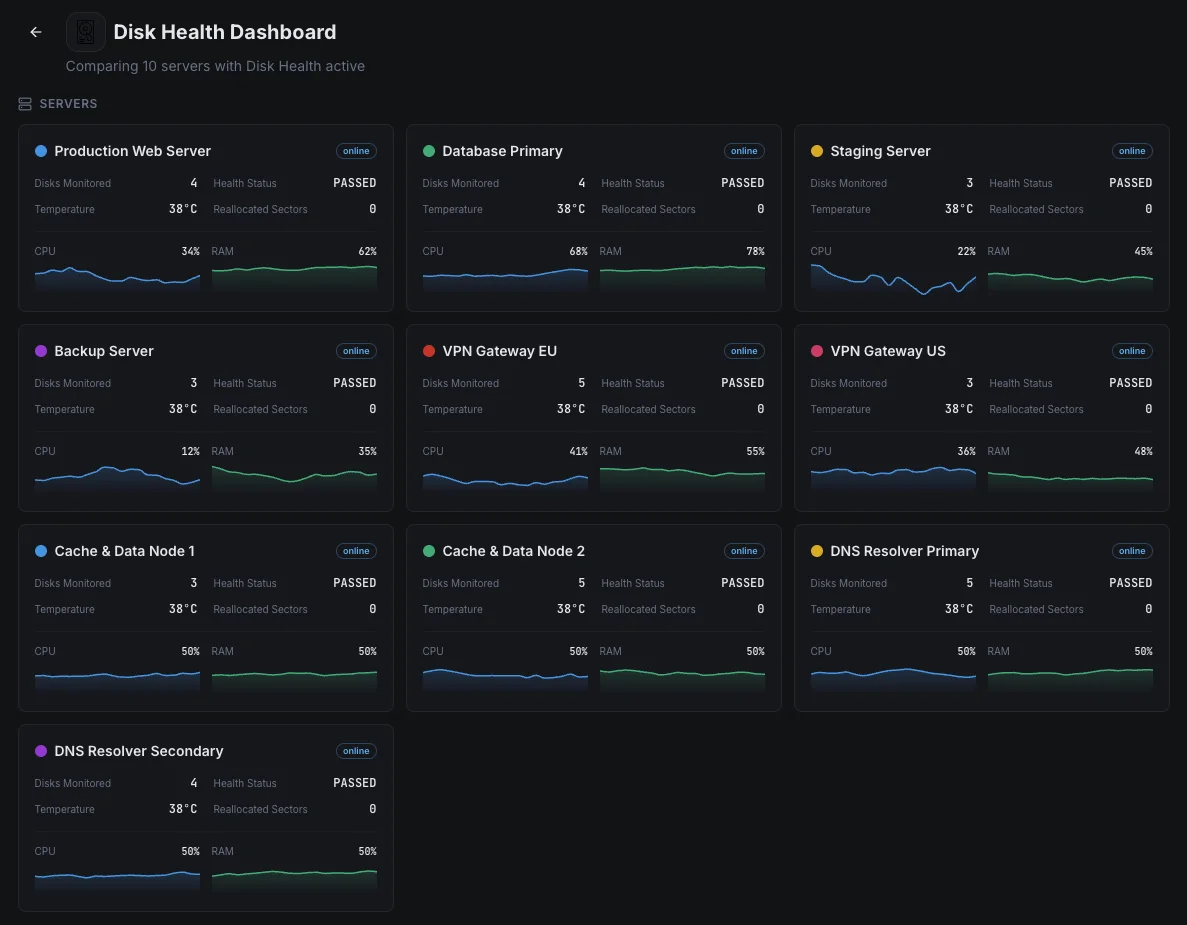
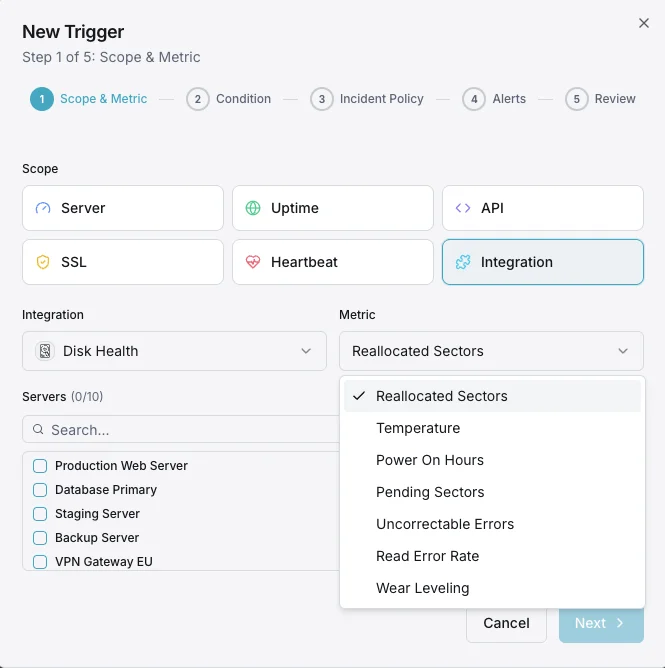
Scénarios courants de monitoring de la santé des disques
Où la surveillance des disques détecte le plus souvent les pannes de disque avant qu'elles ne causent de réels dommages.
Serveurs de base de données
Un disque défectueux dans une base de données peut signifier des temps d'arrêt, des commandes perdues ou, dans le pire des cas, des données corrompues. Nous surveillons chaque disque pour détecter les signes avant-coureurs de défaillance afin que l'équipe puisse remplacer un disque en difficulté selon son propre calendrier — et non au milieu d'une panne à 3 heures du matin.
Serveurs de sauvegarde et d'archivage
Le problème unique des disques de sauvegarde est qu'une défaillance reste invisible jusqu'au jour où vous avez réellement besoin de la sauvegarde — il est alors trop tard. Nous testons chaque disque selon un calendrier et détectons l'usure tôt afin que vous ne cherchiez jamais une sauvegarde qui n'est pas là.
Serveurs qui écrivent beaucoup de données (SSD)
Les SSD ont un nombre limité d'écritures avant de s'user, et les bases de données très sollicitées et les applications gourmandes en données les épuisent plus rapidement que la plupart des équipes ne le réalisent. Nous suivons l'usure en pourcentages clairs afin que les disques soient remplacés à temps — et non après une défaillance soudaine et irrécupérable.
Prérequis pour Disk Health
Assurez-vous d'avoir tout cela en place — la plupart des installations sont une affaire de 60 secondes une fois ces conditions réunies.
- Serveur Linux (Debian/Ubuntu, RHEL/CentOS, ou distribution compatible)
- Paquet smartmontools installé (smartctl) et lsblk disponible
- Accès sudo / root — les données SMART nécessitent des permissions élevées
Commencez par procès-verbal
Installer les prérequis (Linux)
Installez smartmontools pour activer la collecte des données SMART. Vérifiez que lsblk est disponible sur votre système.
# Ubuntu/Debian
sudo apt-get install smartmontools
# CentOS/RHEL
sudo yum install smartmontoolsActiver l'intégration Disk Health
Exécutez la commande integrate et sélectionnez Disk Health. Xitogent détecte automatiquement vos disques et commence à collecter les données SMART. Aucun prérequis sous Windows.
xitogent integrateVérifier que tout fonctionne
Exécutez cette commande sur le serveur pour confirmer que Xitogent a bien détecté l'intégration. De nouvelles métriques apparaîtront sur votre tableau de bord dans environ 30 secondes.
sudo xitogent statusVous envisagez des alternatives ?
Découvrez comment Xitoring se positionne face aux alternatives pour la surveillance de Disk Health — tarifs forfaitaires, intégrations plus poussées et un seul agent pour couvrir tout votre stack.



Souvent a posé des questions
Quels types de disques sont pris en charge ?
Dois-je installer un logiciel supplémentaire ?
Puis-je surveiller les disques NVMe ?
À quelle fréquence les indicateurs sont-ils collectés ?
Quels attributs SMART prédisent une défaillance de disque ?
Comment surveiller la santé d'un disque NVMe ?
Comment surveiller la santé disque sous Windows ?
À quelle fréquence faut-il exécuter les self-tests smartctl ?
Est-ce que cela fonctionne avec les baies RAID ?
Commencer à surveiller Disk Health aujourd'hui
Configuration en moins de 60 secondes. Aucune carte bancaire requise. Statistiques complètes dès le premier jour.
Commencer l'essai gratuit