Supervisor Monitoraggio
Monitora in tempo reale ogni processo gestito da Supervisor: stato (`RUNNING`/`FATAL`), tempo di attività, chiusure impreviste, cicli di riavvio e codici di uscita. Funziona tramite agente con `supervisorctl` e invia un avviso non appena un processo passa allo stato `FATAL`.
Perché monitorare Supervisor?
Supervisor (`supervisord`) mantiene attivi i processi in background: i worker di Celery e Sidekiq, i server applicativi Gunicorn e uWSGI, i consumatori di code e i daemon a esecuzione prolungata. Tuttavia, dopo `startretries` tentativi falliti di riavvio, rinuncia e mette il processo in stato `FATAL`, dove rimane inattivo senza dare alcun segnale. Il monitoraggio per singolo processo fa la differenza tra un avviso di una sola riga e una coda intasata che nessuno ha notato per ore.
Monitoraggio da parte del supervisore, spiegato
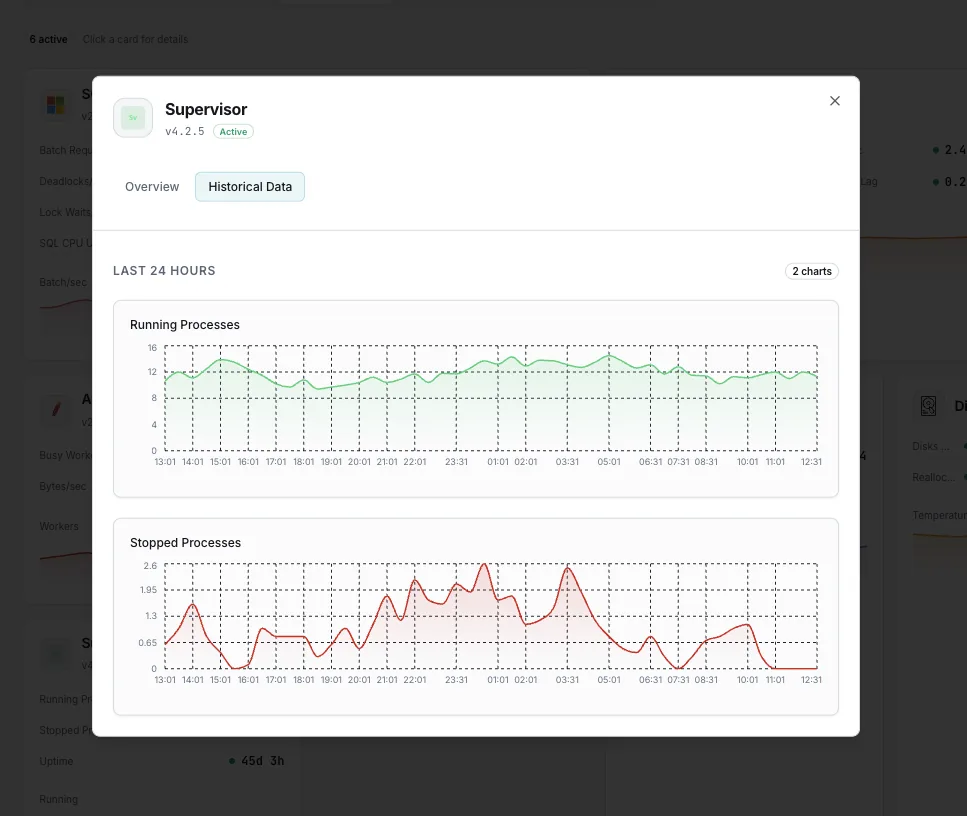
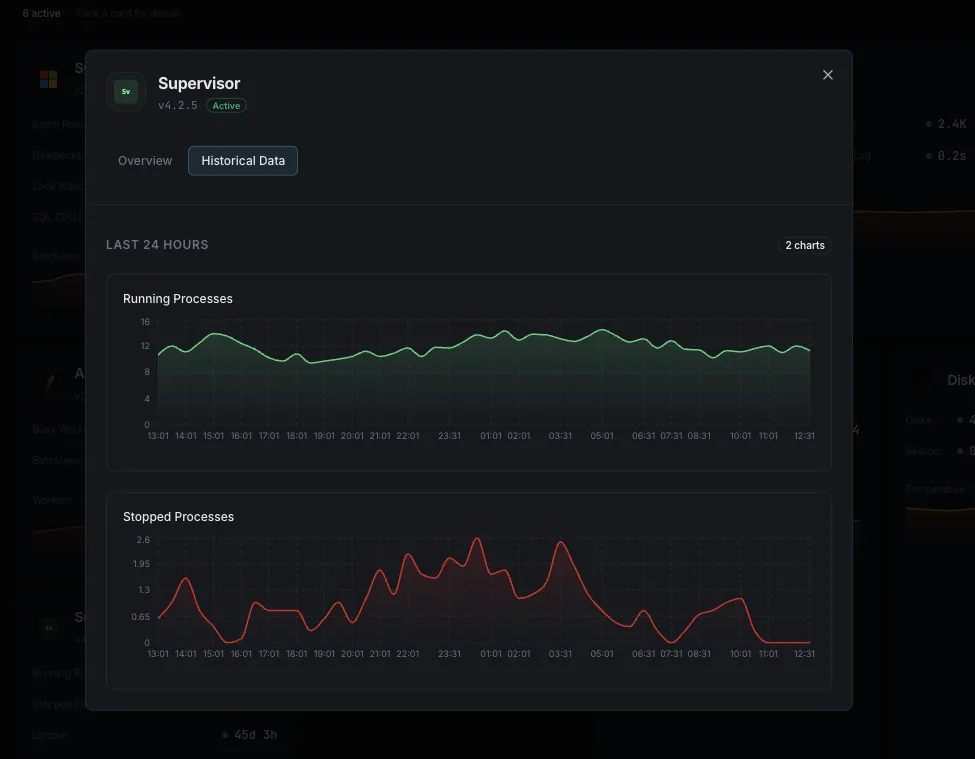
Il monitoraggio di Supervisor consiste nel controllo continuo dello stato di ogni programma gestito da supervisord, oltre all’invio di un avviso quando un processo esce dallo stato RUNNING. Supervisor è ottimo nel riavviare un processo che va in crash, ma solo per startretries volte entro startsecs. Superato tale limite, il processo passa allo stato FATAL e Supervisor interrompe i tentativi. Nessun altro se ne accorge: l’host è attivo, il daemon è attivo, ma la coda smette semplicemente di svuotarsi. Xitoring legge la tabella dei processi in tempo reale tramite supervisorctl, tiene traccia di ogni programma in modo indipendente e invia un avviso al turno di reperibilità nell’istante stesso in cui un worker passa allo stato FATAL, entra in un ciclo BACKOFF o termina con un codice di errore inatteso.
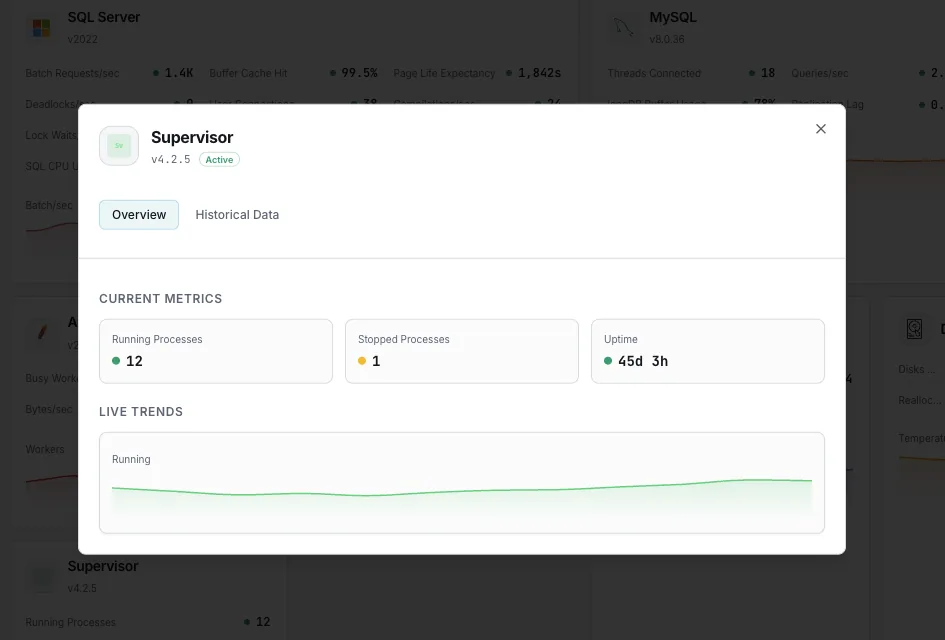
Ciò che monitoriamo
Stato del processo
Lo stato attuale di ciascun programma (`RUNNING`, `STARTING`, `BACKOFF`, `EXITED`, `FATAL`, `STOPPED`, `STOPPING`, `UNKNOWN`). Il segnale più importante del Supervisor: qualsiasi stato diverso da `RUNNING` per un worker a esecuzione prolungata rappresenta un problema.
Stato FATAL
Un processo che ha superato il limite `startretries` ed è stato interrotto da Supervisor. Non si riavvierà automaticamente. Qualsiasi programma presente in `FATAL` rappresenta un segnale grave, degno di essere segnalato.
BACKOFF / Riavvia ciclo
Un processo che continua a terminare prima di `startsecs` e viene riavviato. Un `BACKOFF` prolungato indica che un worker instabile consuma risorse della CPU durante i riavvii e non riesce mai a gestire il traffico.
Tempo di attività (da quando è stato avviato)
Da quanto tempo ogni processo mantiene il proprio PID attuale. Un worker il cui tempo di attività continua a azzerarsi è in realtà in un ciclo di crash silenzioso, anche se tra un riavvio e l'altro mostra brevemente lo stato `RUNNING`.
PID di processo
Il PID in tempo reale per ciascun programma, ricavato dal comando `supervisorctl status`. La presenza di tale valore conferma che il processo è effettivamente in esecuzione, e non solo configurato.
Codice "Ultima uscita"
Lo stato di uscita dell'ultima esecuzione. Confrontarlo con i `codici di uscita` del programma per distinguere un arresto previsto da un arresto imprevisto.
In esecuzione vs. Configurato
Conteggio dei processi effettivamente in stato `RUNNING` rispetto al numero dichiarato (incluso `numprocs`). Permette di individuare a colpo d'occhio eventuali worker mancanti in un gruppo.
Uscite inaspettate
Genera un'uscita con un codice non presente in `exitcodes` quando `autorestart=unexpected`. Si tratta di arresti anomali che non avrebbero mai dovuto verificarsi: un aumento della loro frequenza indica la presenza di una regressione.
Conteggio riavvii
La frequenza con cui ciascun processo è stato riavviato nel corso del tempo. Un riavvio costante di un processo che dovrebbe funzionare in modo continuo costituisce un segnale precoce di instabilità o di una perdita di memoria.
Processi arrestati
Programmi con stato `STOPPED` o `EXITED` che dovrebbero essere in esecuzione. Rileva un worker che qualcuno ha arrestato manualmente e di cui si è dimenticato, oppure uno che si è chiuso senza riavviarsi automaticamente.
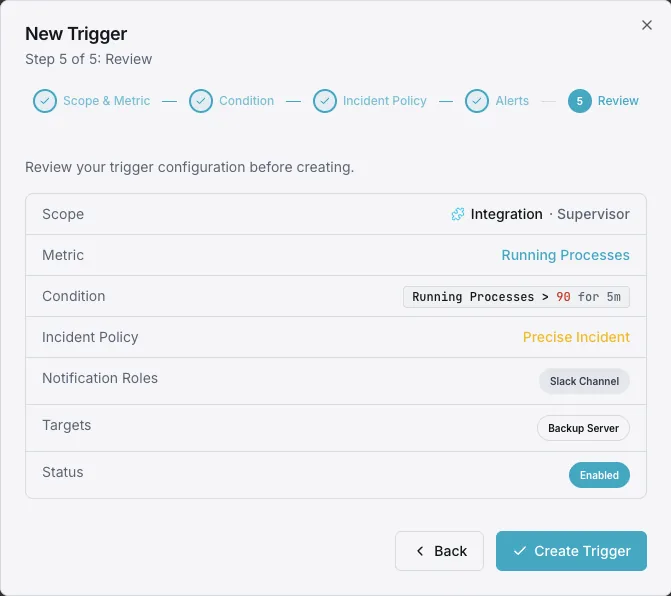
Configurabile condizioni di attivazione
Imposta dei trigger personalizzati nella tua dashboard per ricevere una notifica non appena le metriche dell{name}e superano le soglie da te definite.
Errore FATALE del processo
criticoSi attiva quando un processo entra in stato `FATAL`: il supervisore ha rinunciato a riavviarlo e il processo rimane inattivo finché qualcuno non interviene.
Il processo non è in esecuzione
criticoSi attiva quando un programma che dovrebbe essere in stato `RUNNING` risulta invece in stato `STOPPED`, `EXITED` o `UNKNOWN`.
Riavvia il ciclo
avvisoAvvisi in caso di `BACKOFF` prolungato o riavvii ripetuti — un worker che continua a bloccarsi e non si stabilizza mai.
Codice di uscita imprevisto
avvisoSi attiva quando un processo termina con un codice diverso da quelli specificati nei `exitcodes` configurati.
L'importanza di Monitoraggio da parte del supervisore
Il supervisore riavvierà un processo che si è bloccato — finché non sarà più possibile farlo. Dopo `startretries`, il processo viene messo in attesa nello stato `FATAL` e rimane inattivo, senza che l'host fornisca alcuna segnalazione.
- Individua i processi che generano un errore `FATAL` e impedisci che vengano riavviati
- Individuare i worker che si bloccano in cicli `BACKOFF`
- Individuare i riavvii silenziosi tramite il ripristino del tempo di attività
- Rilevare quando i lavoratori escono utilizzando codici imprevisti
Perché scegliere Xitoring
Monitoraggio di Supervisor basato su agenti, con configurazione automatica e visibilità per singolo processo su tutti i programmi gestiti da supervisord.
- Installazione e integrazione con un solo comando
- Monitoraggio per processo e per gruppo
- Nessuna interfaccia XML-RPC o HTTP da rendere accessibile
- Avvisi multicanale relativi al tuo turno di reperibilità
- Stato storico e cronologia dei riavvii
Monitoraggio del supervisore comune scenari
Dove viene solitamente eseguito Supervisor — e cosa fallisce in modo silenzioso quando nessuno sta guardando.
Processi in background (Celery, Sidekiq, RQ, Resque)
I worker della coda sono proprio quei processi che si arrestano silenziosamente: un’implementazione errata o un messaggio dannoso li fa entrare in un ciclo di riavvio, per poi generare un errore FATAL. Inviamo un avviso nel momento stesso in cui un worker smette di funzionare, prima che la coda si intasi e i lavori inizino a scadere.
Server di applicazioni e daemon (Gunicorn, uWSGI, Daphne, Node)
Quando Supervisor gestisce il server delle applicazioni, se un processo non si avvia dopo una distribuzione, significa che il sito è inattivo anche se lo stato dell’host risulta ancora “verde”. Rileviamo immediatamente gli errori FATAL e BACKOFF, in modo che, in caso di rilascio fallito, venga immediatamente avvisato qualcuno, invece di dover attendere una segnalazione da parte del cliente.
Processi nei container e su host legacy
Molti container e server meno recenti utilizzano Supervisor al posto di systemd per mantenere attivi diversi processi in un unico punto. Monitoriamo ciascuno di essi in modo indipendente, in modo che un singolo processo in crash all’interno di un container molto trafficato non passi inosservato tra gli altri.
Prerequisiti per Supervisor
Assicurati di avere tutto questo in posizione — la maggior parte delle installazioni dura 60 secondi una volta soddisfatte le condizioni.
- Un server Linux su cui è installato Supervisor (
supervisord) e che gestisce almeno un programma - Xitogent installato sullo stesso host, in grado di eseguire
supervisorctl status - Accedi per eseguire il comando
sudo xitogent integratee seleziona l'integrazione Supervisor
Inizia con verbali
Installa Xitogent sul tuo server
Installare l'agente di monitoraggio leggero Xitogent sull'host su cui è in esecuzione Supervisor.
curl -s https://xitoring.com/install.sh | sudo bash -s -- --key=YOUR_API_KEYAbilita l'integrazione con Supervisor
Esegui `sudo xitogent integrate` e seleziona Supervisor. Xitogent crea il file `/etc/xitogent/integrations/supervisor_integration.conf`, legge la tabella dei processi tramite `supervisorctl` e rileva automaticamente tutti i programmi e i gruppi presenti sotto `supervisord` — non è necessario modificare la configurazione di Supervisor.
sudo xitogent integrateConfigurare i trigger (facoltativo)
Imposta i trigger e i livelli di gravità per ciascun processo nella dashboard di Xitoring — ad esempio, invia una notifica ogni volta che un processo entra nello stato `FATAL` e avvisa in caso di stato `BACKOFF` prolungato o di un codice di uscita imprevisto — in modo che i guasti vengano segnalati al personale di reperibilità prima che la coda si intasi.
Verifica che funzioni
Esegui questo comando sul server per confermare che Xitogent ha rilevato l'integrazione. In circa 30 secondi nuove metriche cominceranno a comparire sulla tua dashboard.
sudo xitogent statusStai valutando alternative?
Scopri come Xitoring si confronta con le alternative per il monitoraggio di Supervisor — prezzi fissi, integrazioni più approfondite e un unico agente che copre l'intero stack.



Spesso domande poste
Che cos’è il monitoraggio da parte del supervisore?
In che modo Xitoring raccoglie i dati relativi ai supervisori?
Come si configura l'integrazione con Supervisor?
Cosa significano gli stati del processo “Supervisor”?
Cosa significa lo stato FATAL e perché è importante?
Come faccio a individuare un ciclo infinito di riavvio del Supervisor?
Qual è la differenza tra "autorestart true", "false" e "unexpected"?
È possibile monitorare più processi e gruppi di processi?
Supervisor vs. systemd — perché monitorare proprio Supervisor?
Inizia a monitorare Supervisor oggi
Configurazione in meno di 60 secondi. Non è richiesta alcuna carta di credito. Statistiche complete fin dal primo giorno.
Inizia la prova gratuitaContinua a esplorare