CoreDNS Überwachung
Überwachen Sie CoreDNS-Abfragefrequenzen, Cache-Trefferquoten, Auflösungslatenzzeiten und Fehlerquoten in Echtzeit – ganz ohne Konfiguration.
Warum überwachen Sie CoreDNS?
CoreDNS ist der Standard-DNS-Server für Kubernetes und Cloud-native Umgebungen. Durch die Überwachung von CoreDNS werden eine schnelle DNS-Auflösung, eine einwandfreie Cache-Leistung und eine zuverlässige Dienstermittlung für Ihre Infrastruktur gewährleistet.
CoreDNS-Monitoring, erklärt
CoreDNS-Monitoring erkennt SERVFAIL-Spitzen, sinkende Cache-Trefferraten, Latenz im Forward-Plugin und panikbedingte Neustarts, bevor sie zu clusterweiten DNS-Auflösungsfehlern eskalieren. Da jeder Microservice für die Service-Discovery von DNS abhängt, ist ein nicht überwachter CoreDNS ein unüberwachter Ausfallmodus für Ihren gesamten Kubernetes-Cluster — DNS-Probleme tauchen überall als „zufällige Connection-refused-Fehler“ auf. Xitoring erkennt Ihr CoreDNS automatisch, scrapt :9153/metrics und leitet Alerts an Slack, PagerDuty, Telegram oder Ihre bestehende Rufbereitschaft weiter.
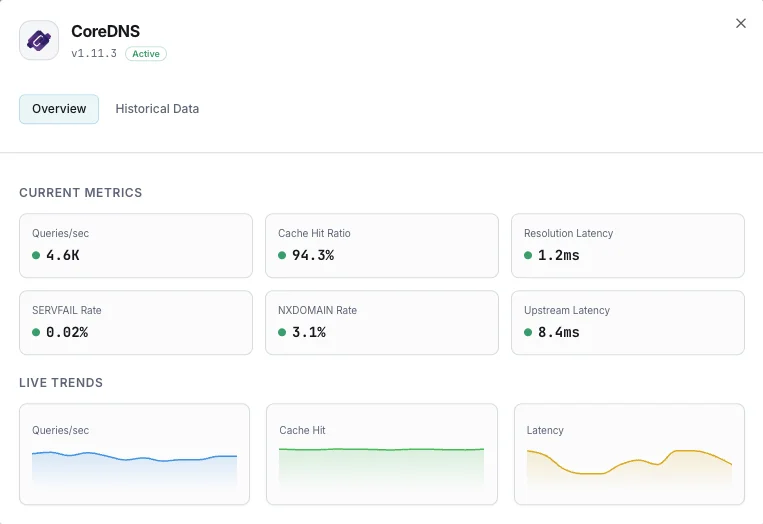
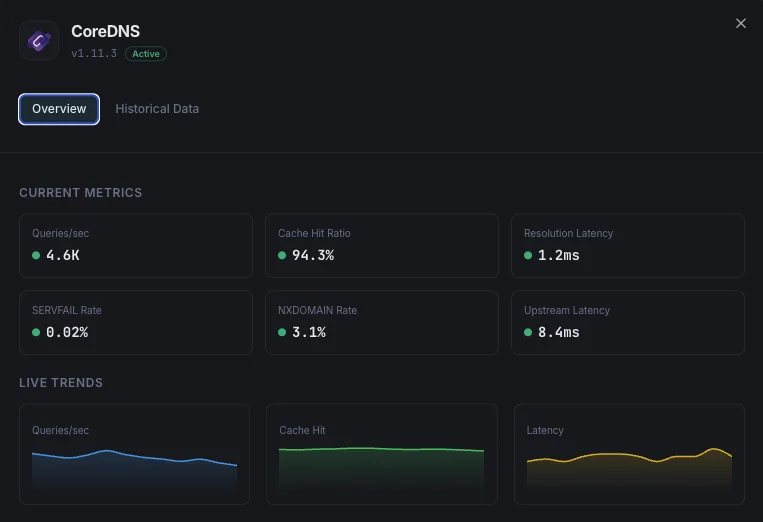
Was wir überwachen
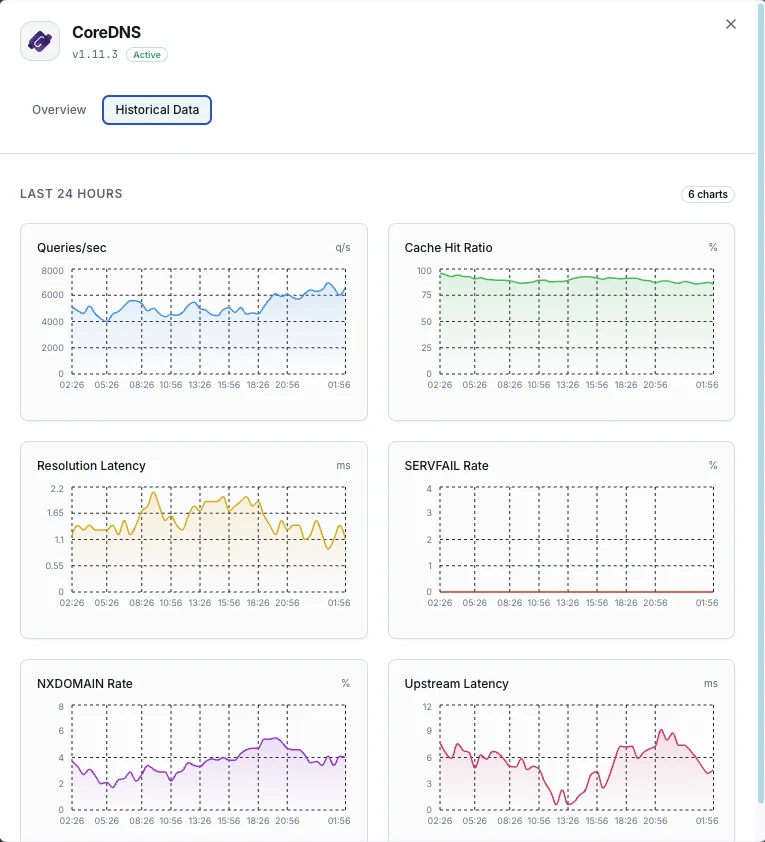
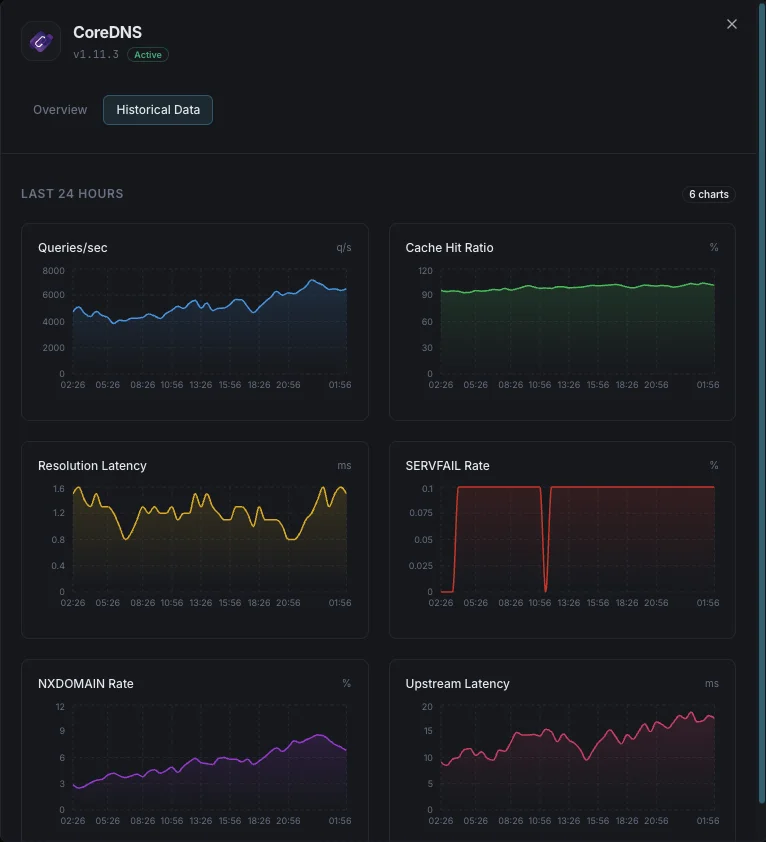
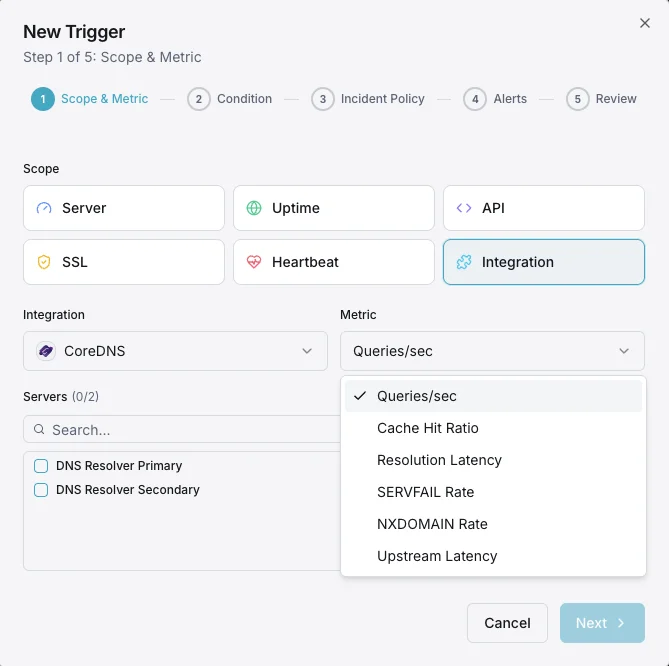
Abfragen/Sek.
DNS-Abfragefrequenz.
Cache-Trefferquote
Prozentsatz der aus dem Cache bedienten Abfragen.
Auflösungslatenz
Durchschnittliche DNS-Auflösungszeit.
SERVFAIL-Rate
Prozentsatz der nicht gelösten Fälle.
NXDOMAIN-Rate
Anzahl der Abfragen für nicht existierende Domains.
Upstream-Latenz
Antwortzeit bei weitergeleiteten Anfragen.
Latenz des Forward-Plugins
`coredns_forward_request_duration_seconds` pro Upstream-Resolver. Trennt CoreDNS-interne Latenz von der Latenz des Upstream-Resolvers — entscheidend für die Diagnose, ob 8.8.8.8 langsam ist oder CoreDNS selbst.
Forward-Request-Rate
`coredns_forward_request_count_total` pro Upstream. Kombiniert mit der Cache-Trefferquote zeigt es, wie viel Traffic tatsächlich CoreDNS Richtung Upstream verlässt.
Proxy-Verbindungs-Cache
`coredns_proxy_conn_cache_hits_total` / `_misses_total`. Erfasst die Wiederverwendung von TCP-Verbindungen zu Upstream-Resolvern — eine niedrige Trefferquote bedeutet Verbindungs-Churn und erhöht die Upstream-Latenz.
Health-Plugin-Fehler
`coredns_health_request_failures_total` — der eigene Fehlerzähler des `health:8080`-Plugins. Nicht-null bedeutet, dass die Liveness-Probe zeitweise fehlschlägt.
Panics
`coredns_panics_total` — jeder Wert ungleich null ist ein CoreDNS-Bug oder Plugin-Crash, der eine Goroutine-Panic ausgelöst hat. Kombinieren Sie ihn mit der Restart-Anzahl für vollständigen Post-Mortem-Kontext.
Go-Runtime
`process_resident_memory_bytes` (RSS), `go_goroutines` (Goroutine-Anzahl — erkennt Leaks), `go_gc_duration_seconds` (GC-Pause-Zeit). Speicherwachstum ohne Neustarts = Leak; wachsende Goroutine-Anzahl = blockiertes Plugin oder Upstream.
Konfigurierbare Alarmauslöser
Richten Sie benutzerdefinierte Trigger in Ihrem Dashboard ein, um benachrichtigt zu werden, sobald die Kennzahlen von „CoreDNS“ Ihre festgelegten Schwellenwerte überschreiten.
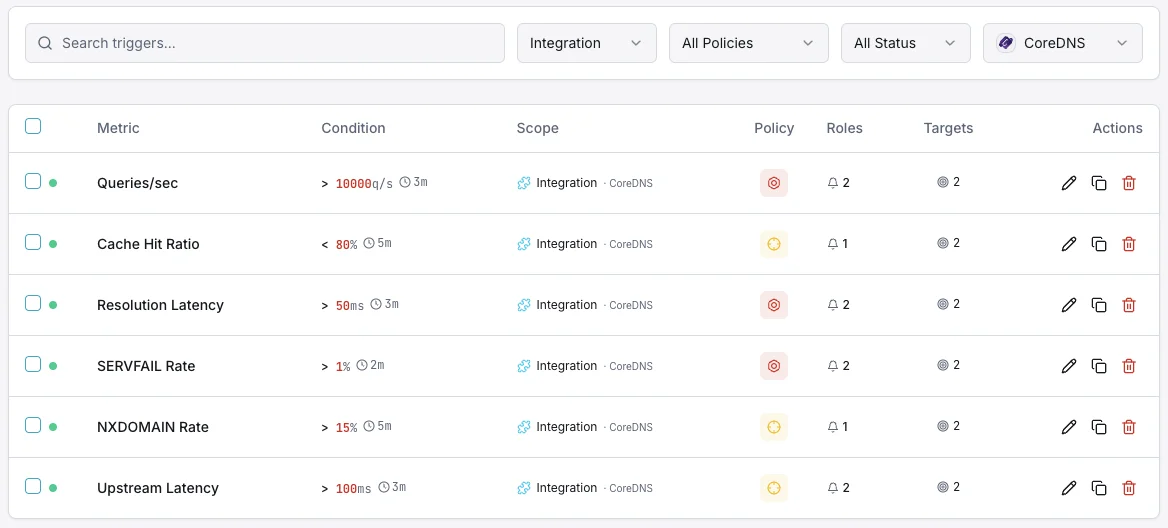
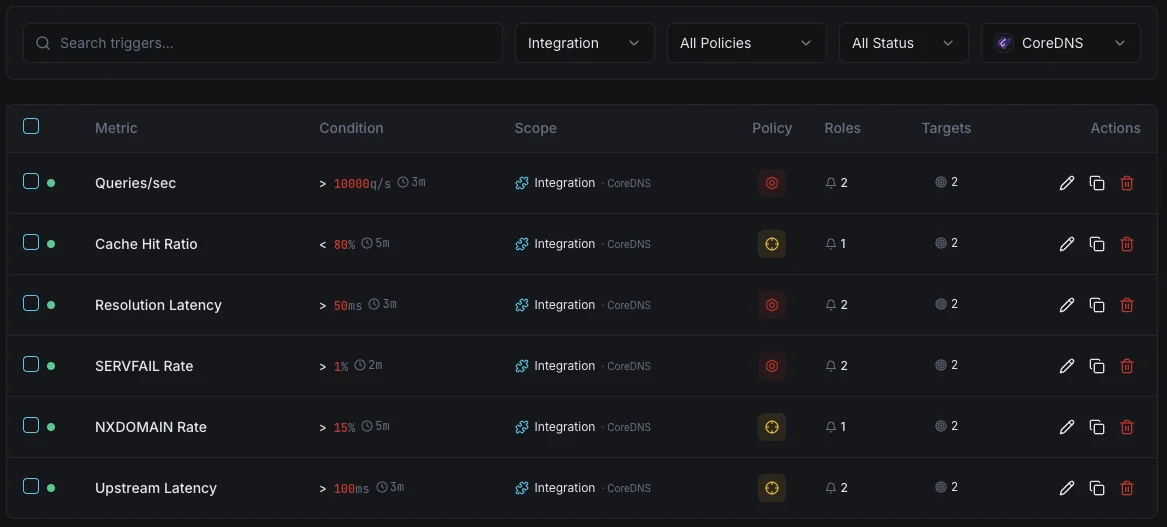
SERVFAIL-Rate
entscheidendFehlerschritte bei hoher Auflösung.
Cache-Trefferquote
WarnungWarnmeldungen, wenn die Cache-Effizienz nachlässt.
Auflösungslatenz
WarnungAuslöser bei langsamer DNS-Auflösung.
Abfragehäufigkeit
WarnungLöst bei ungewöhnlich hohem Abfrageaufkommen einen Alarm aus.
Bedeutung von CoreDNS-Überwachung
DNS ist die Grundlage der Netzwerkkonnektivität. Eine langsame oder fehlerhafte DNS-Auflösung wirkt sich auf jeden Dienst in Ihrer Infrastruktur aus.
- Sorgen Sie für eine schnelle DNS-Auflösung
- SERVFAIL-Spitzen sofort erkennen
- Cache überwachen, um eine optimale Leistung zu erzielen
- Zustand des Upstream-Resolvers überwachen
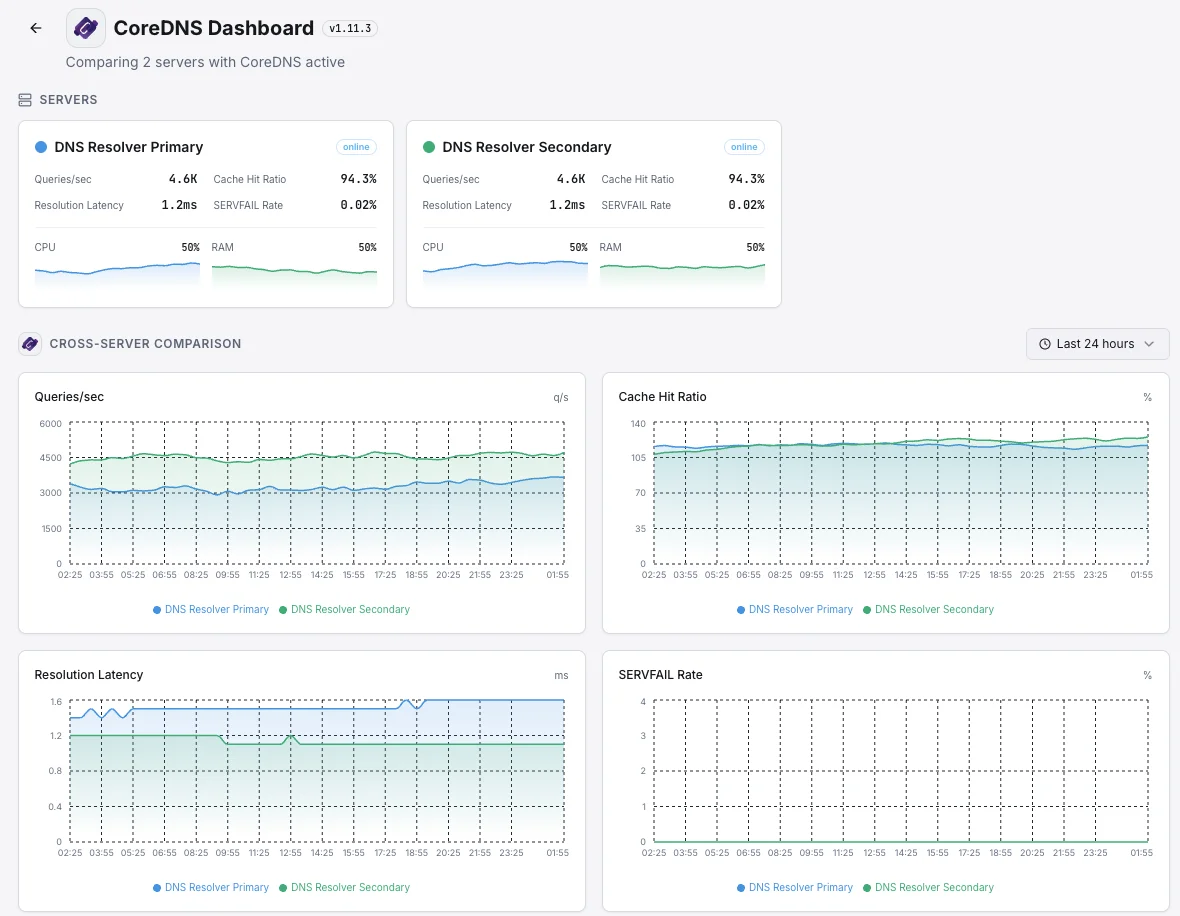
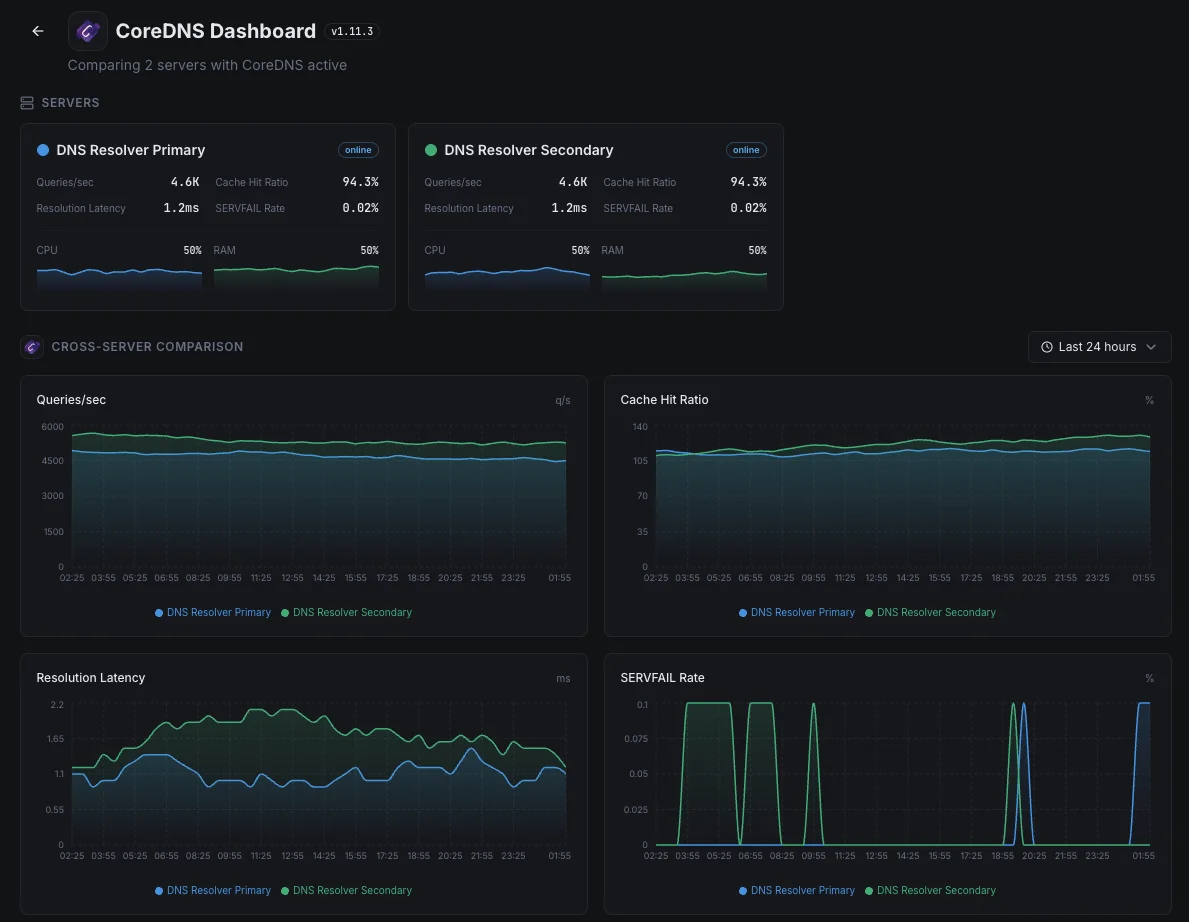
Warum sich für uns entscheiden? Xitoring
CoreDNS-Überwachung ohne Konfiguration.
- Installation mit einem einzigen Befehl
- Globale Knoten
- Zentrales Dashboard
- Benachrichtigungen über mehrere Kanäle
Häufige CoreDNS-Monitoring- Szenarien
Wo CoreDNS heute typischerweise läuft – und was schiefgehen könnte, wenn niemand hinsieht.
DNS innerhalb einer Kubernetes-Anwendung
Jeder Teil einer Kubernetes-Anwendung verwendet CoreDNS, um jeden anderen Teil zu finden. Wenn es sich verlangsamt oder ausfällt, sehen Benutzer seltsame, intermittierende Fehler in der gesamten Anwendung. Wir erkennen die Verlangsamung in dem Moment, in dem sie beginnt, damit ein kleiner DNS-Schluckauf nicht als mysteriöser Ausfall bei den Kunden ankommt.
Große Cluster mit lokalen DNS-Caches
Größere Kubernetes-Setups platzieren einen kleinen DNS-Cache auf jedem Server, um die Geschwindigkeit zu gewährleisten. Wenn einer dieser Caches sich fehlerhaft verhält, bricht nur ein Teil des Traffics zusammen – was es schwer erkennbar macht. Wir stellen sicher, dass jeder seine Aufgabe erfüllt, damit ein einzelner fehlerhafter Knoten nicht unbemerkt einen Teil Ihrer Benutzer beeinträchtigen kann.
Öffentlich zugängliches DNS für Ihre Domain
Wenn CoreDNS die DNS-Anfragen für Ihre Domain im offenen Internet beantwortet, bedeutet ein Ausfall, dass Personen Ihre Website überhaupt nicht erreichen können. Wir überwachen die Signale, die beweisen, dass der Dienst fehlerfrei ist und reagiert, damit Marke und Umsatz nicht unbemerkt leiden, während DNS stillschweigend ausfällt.
Voraussetzungen für CoreDNS
Stellen Sie sicher, dass diese Punkte erfüllt sind — danach ist die Installation eine Sache von 60 Sekunden.
- CoreDNS 1.x läuft auf dem Server
- Prometheus-Plugin in Ihrer Corefile aktiviert (Standardport 9153)
- Netzwerkerreichbarkeit von Xitogent zum Metrics-Endpunkt
Erste Schritte in Minuten
Xitogent auf Ihrem Server installieren
Falls noch nicht geschehen, installieren Sie den ressourcenschonenden Xitogent-Monitoring-Agenten auf dem Host, auf dem CoreDNS läuft.
curl -s https://xitoring.com/install.sh | sudo bash -s -- --key=YOUR_API_KEYPrometheus-Plugin in CoreDNS aktivieren
CoreDNS stellt Metriken im Prometheus-Format über sein prometheus-Plugin bereit (Standard-Endpunkt :9153/metrics). Fügen Sie `prometheus :9153` zu Ihrer Corefile hinzu, laden Sie CoreDNS neu und prüfen Sie, dass der Metrics-Endpunkt vom Agent-Host aus erreichbar ist.
sudo xitogent integrateCoreDNS-Integration aktivieren
Aktivieren Sie die CoreDNS-Integration über das Xitoring-Dashboard oder die CLI. Xitogent erkennt den Metrics-Endpunkt automatisch und beginnt mit der Erfassung von Query-, Cache- und Latenz-Metriken.
Alarmschwellen konfigurieren (optional)
Legen Sie eigene Schwellenwerte für SERVFAIL-Rate, Cache-Trefferquote oder Auflösungslatenz fest, um benachrichtigt zu werden, sobald DNS-Zuverlässigkeit oder -Performance nachlässt.
Funktion überprüfen
Führen Sie diesen Befehl auf dem Server aus, um zu bestätigen, dass Xitogent die Integration erkannt hat. Innerhalb von etwa 30 Sekunden werden frische Metriken in Ihr Dashboard gestreamt.
sudo xitogent statusErwägen Sie Alternativen?
Sehen Sie, wie sich Xitoring gegen die Alternativen für CoreDNS-Monitoring schlägt — Pauschalpreise, tiefere Integrationen und ein Agent, der Ihren gesamten Stack abdeckt.



Häufig gestellte Fragen
Kubernetes CoreDNS?
Prometheus-Metriken?
Was macht das kubernetes-Plugin?
Wie überwache ich die Cache-Trefferquote von CoreDNS?
Was bedeutet NXDOMAIN in CoreDNS-Metriken?
Wie debugge ich CoreDNS in Kubernetes?
Wie überwache ich die Latenz des Forward-Plugins in CoreDNS?
Wann sollte ich NodeLocal DNSCache einsetzen?
Welche CoreDNS-Versionen werden unterstützt?
CoreDNS überwachen heute
In weniger als 60 Sekunden eingerichtet. Keine Kreditkarte erforderlich. Umfassende Kennzahlen vom ersten Tag an.
Kostenlose Testversion starten