Apache Kafka Suivi
Surveillez en temps réel l'état des brokers Apache Kafka, le décalage des partitions, les groupes de consommateurs et le débit, sans aucune configuration.
Pourquoi surveiller ? Apache Kafka?
Apache Kafka est la colonne vertébrale des pipelines de données en temps réel et du streaming d'événements. La surveillance de Kafka garantit le bon fonctionnement des clusters de brokers, un décalage minimal chez les consommateurs, une répartition optimale des partitions et une transmission fiable des messages.
Le monitoring Kafka, expliqué
Le monitoring Kafka détecte les partitions sous-répliquées, les partitions hors ligne, les pics de lag des consumer groups, les rétrécissements d'ISR, les défaillances de controller et la pression disque avant qu'ils ne provoquent une perte de données, des défaillances de microservices en aval ou des pannes complètes de broker. Pour les pipelines CDC, les systèmes d'event sourcing, l'eventing microservices et tout cluster Kafka en production, la visibilité par broker + par consumer group fait la différence entre une alerte à 60 secondes sur un consommateur en retard et la découverte d'un arriéré de 50 millions de messages en fin de journée. Xitoring découvre automatiquement vos brokers, lit les MBeans JMX + les offsets des consommateurs, et achemine les alertes vers Slack, PagerDuty, Telegram ou votre astreinte existante.
Ce que nous surveillons
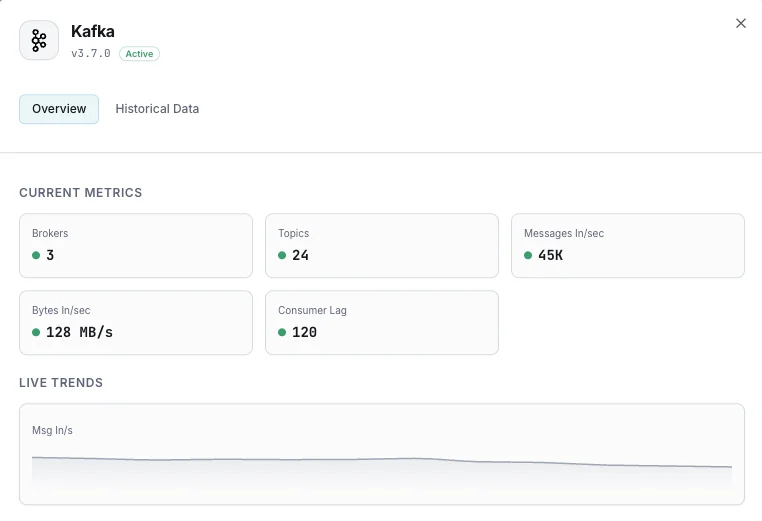
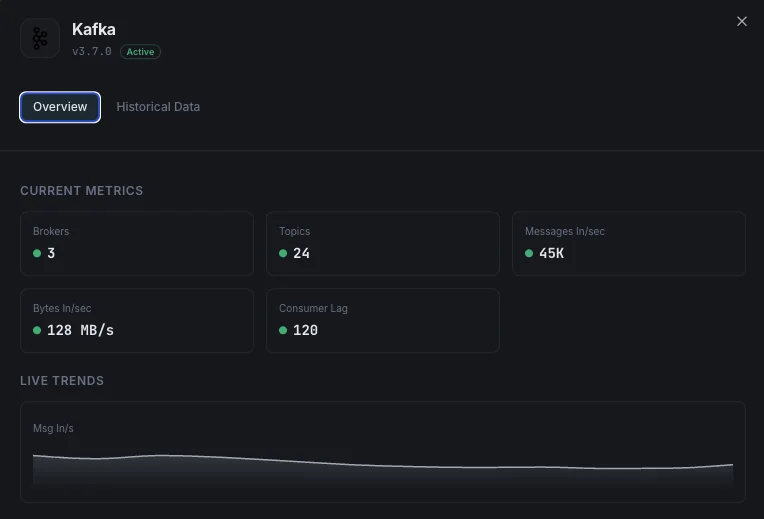
Nombre de brokers
Brokers actifs dans le cluster.
Lag des consommateurs
Messages en retard pour chaque consumer group.
Messages entrants/sec
Taux d'ingestion des messages.
Octets entrants/sortants
Débit réseau par broker.
Partitions sous-répliquées
Partitions sous le facteur de réplication.
Réductions ISR
Événements de réduction de répliques en synchronisation.
UncleanLeaderElectionsPerSec
Taux de réplicas hors synchronisation promus en leaders (avec perte de données). Doit être 0 — une valeur non nulle signifie `unclean.leader.election.enable=true` ET qu'un événement de défaillance réel s'est produit.
MessagesInPerSec / BytesIn / BytesOut
Débit par broker et par topic. Des chutes soudaines avec un nombre de producteurs stable = problème d'ingestion ; des pics soudains = tempête de retries ou producteur emballé.
Latence de requête (p99)
p99 du temps de traitement des requêtes Produce, Fetch, Metadata depuis `kafka.network:type=RequestMetrics`. Capte la surcharge du broker avant qu'elle ne cause des timeouts côté clients.
LeaderCount par broker
Leaders de partitions par broker. Distribution inégale (un broker détenant 60 %+ des leaders) = cluster déséquilibré, à corriger avec `kafka-reassign-partitions.sh` ou.
Taille de log par topic
Taille agrégée des logs sur disque par topic depuis `kafka.log:type=Log,name=Size`. Pilote les alertes d'espace disque et informe les politiques de tiered storage en Kafka 3.8+.
RemoteLogManager (tiered storage)
Métriques de tiered storage Kafka 3.8+ : octets uploadés vers le niveau distant, segments en distant vs local, latence de fetch depuis le distant. Détecte les problèmes de connectivité S3 / IAM qui cassent les fetches du niveau distant.
Configurables déclencheurs d'alerte
Configurez des déclencheurs personnalisés dans votre tableau de bord pour être averti dès que les indicateurs d{name}s dépassent les seuils que vous avez définis.
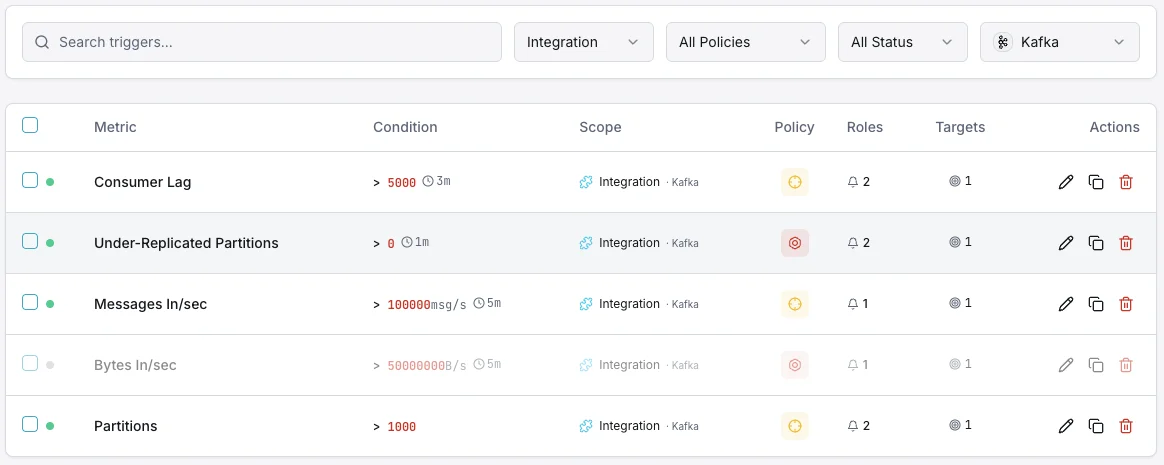
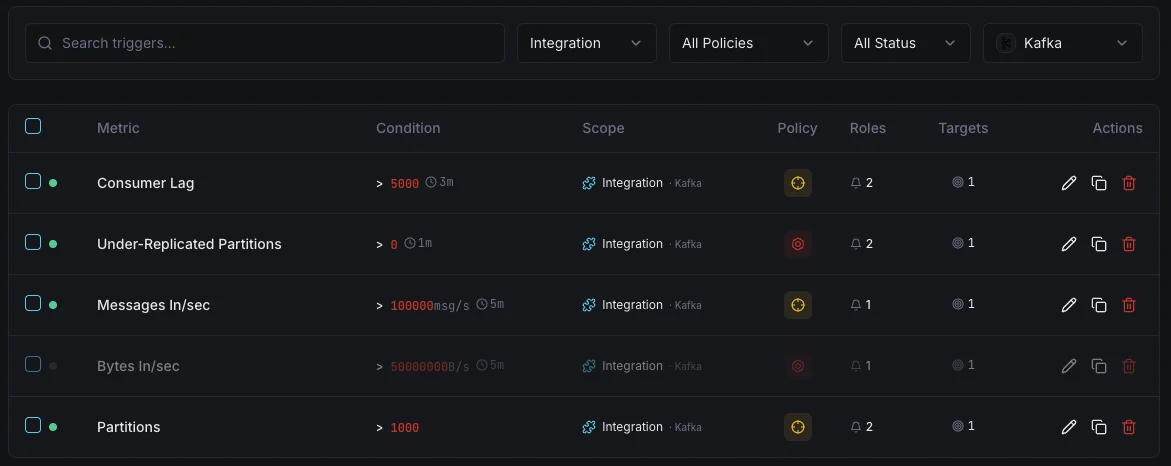
Lag des consommateurs
crucialSe déclenche lorsqu'un consommateur prend du retard.
Partitions sous-répliquées
crucialAlerte sur les problèmes de réplication.
Broker hors ligne
crucialSe déclenche lorsqu'un broker quitte le cluster.
Utilisation disque
avertissementSe déclenche lorsque le disque du broker se remplit.
Importance de la surveillance Kafka
Kafka traite des billions de messages quotidiennement. Le lag des consommateurs, les pannes de brokers et le déséquilibre des partitions peuvent provoquer des défaillances de pipeline de données.
- Détectez le lag des consommateurs avant la perte de données
- Surveillez l'ISR pour la durabilité des données
- Suivez la santé des brokers entre les clusters
- Garantissez l'équilibre des partitions
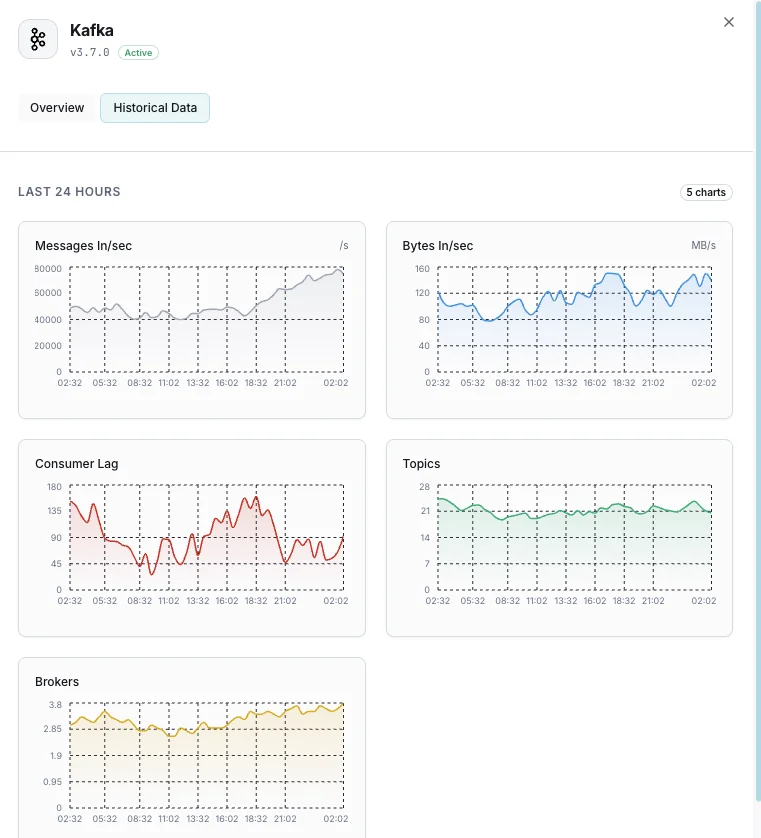
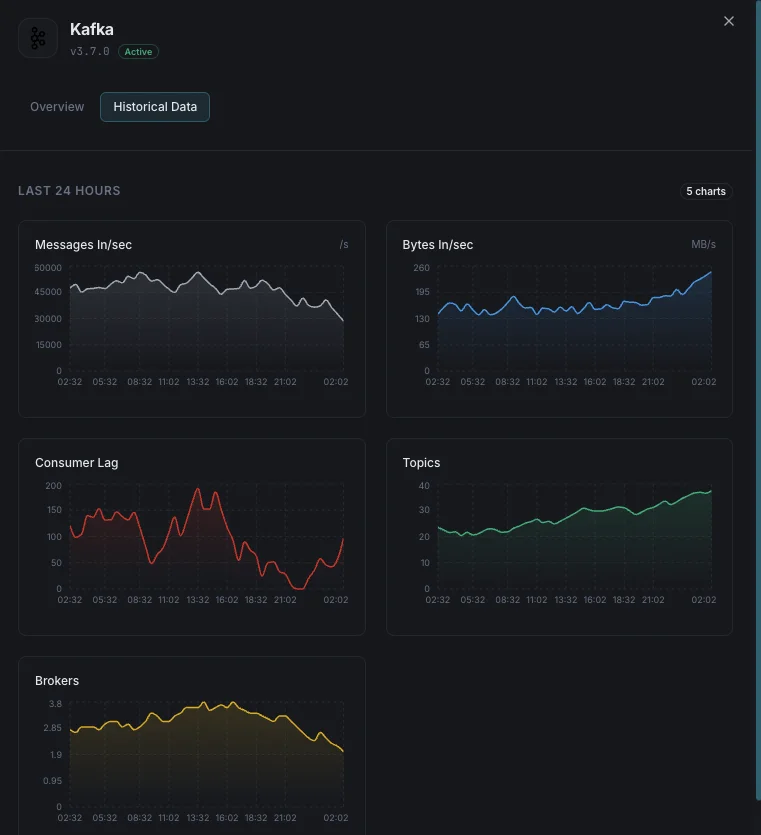
Pourquoi choisir Xitoring
Surveillance Kafka de qualité entreprise.
- Configuration zéro-config
- Nœuds mondiaux
- Tableau de bord unifié
- Alertes multicanaux
- Conservation historique
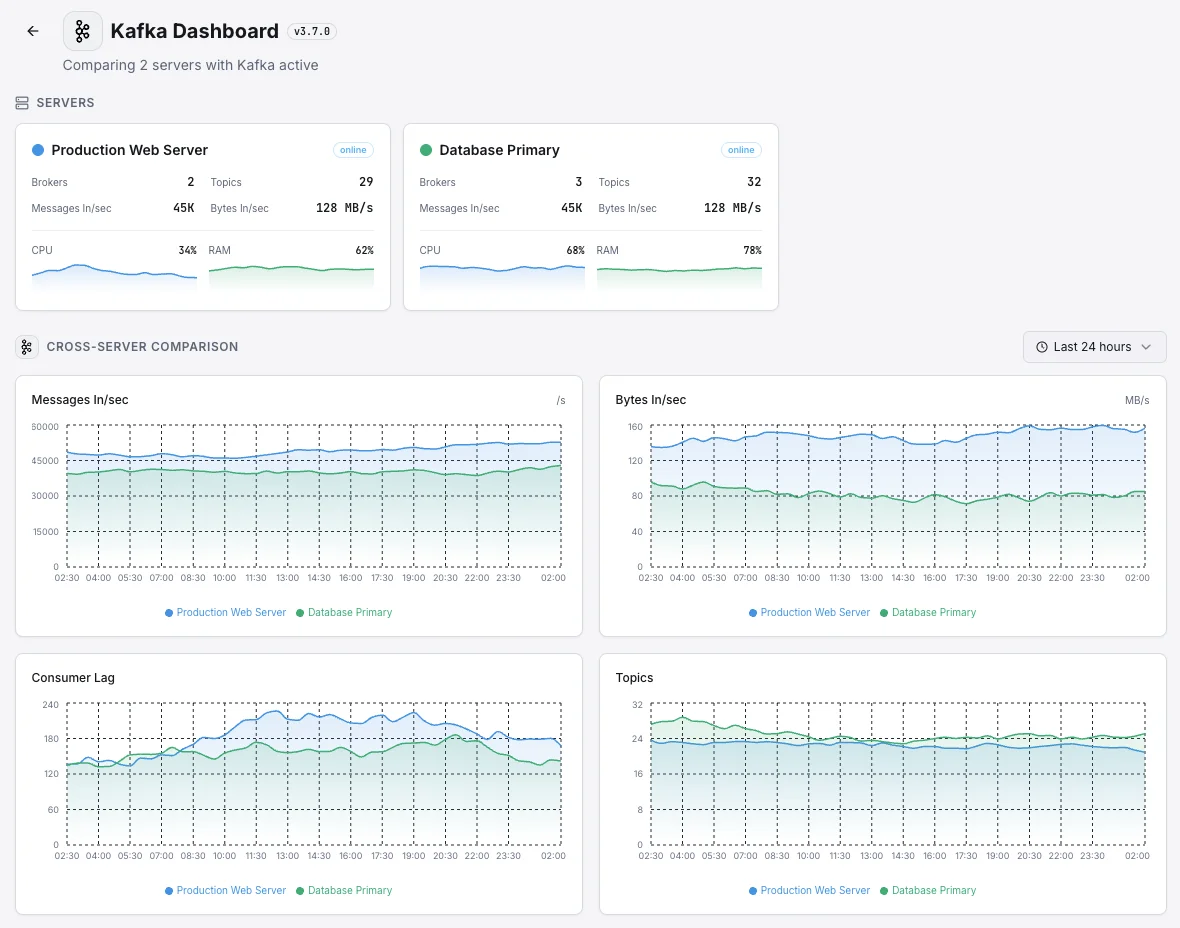
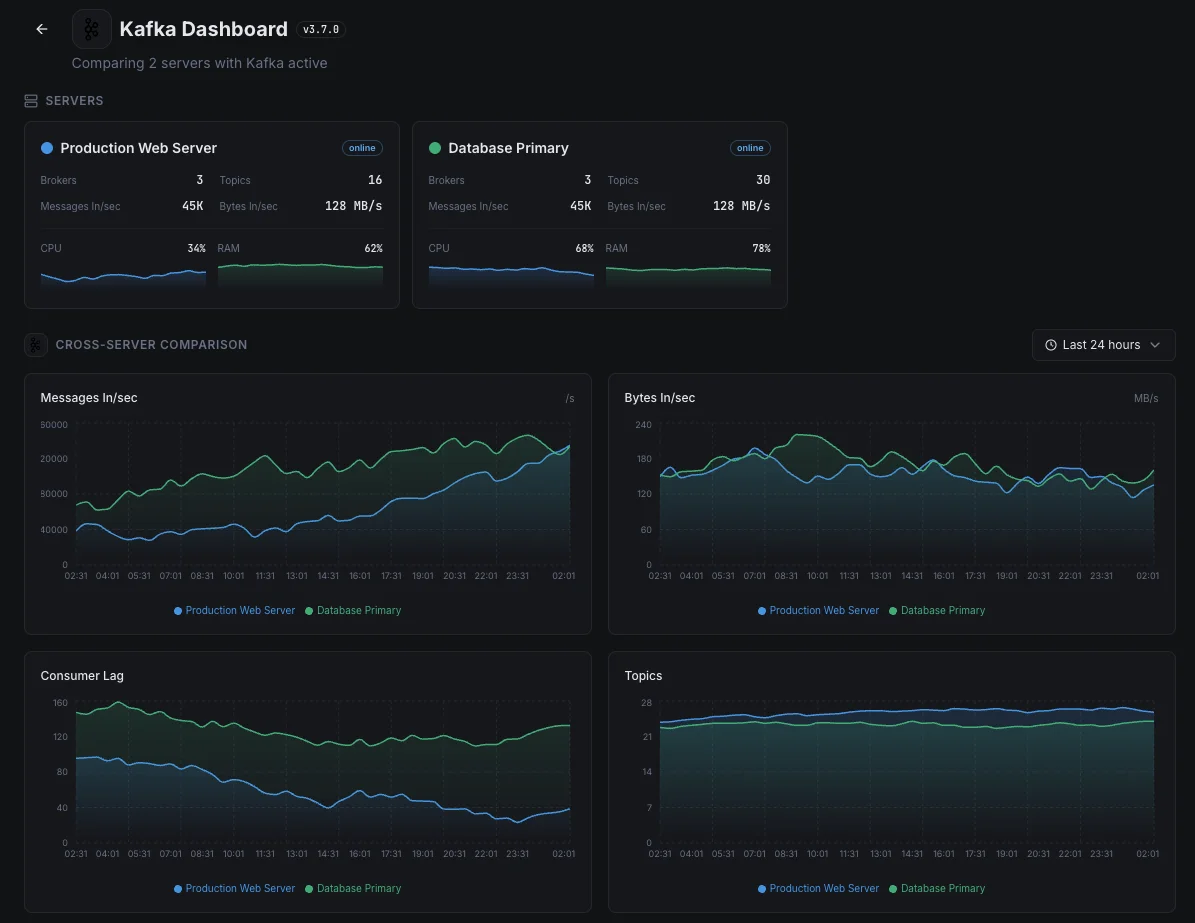
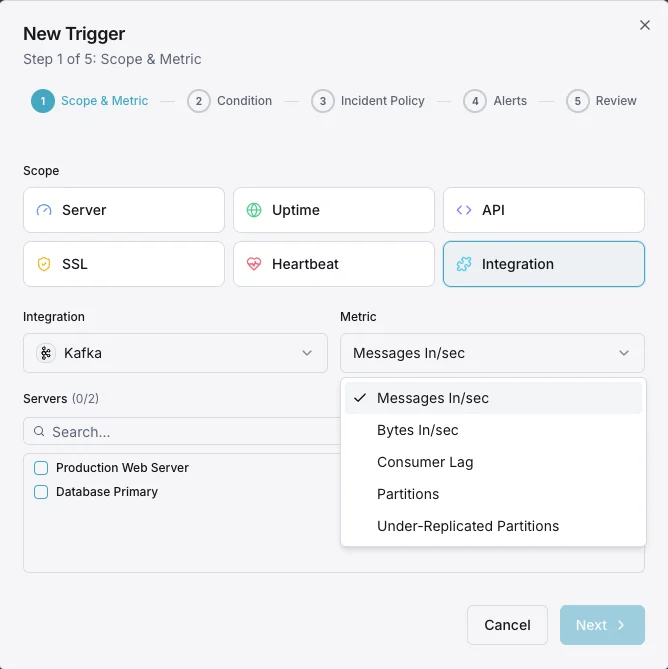
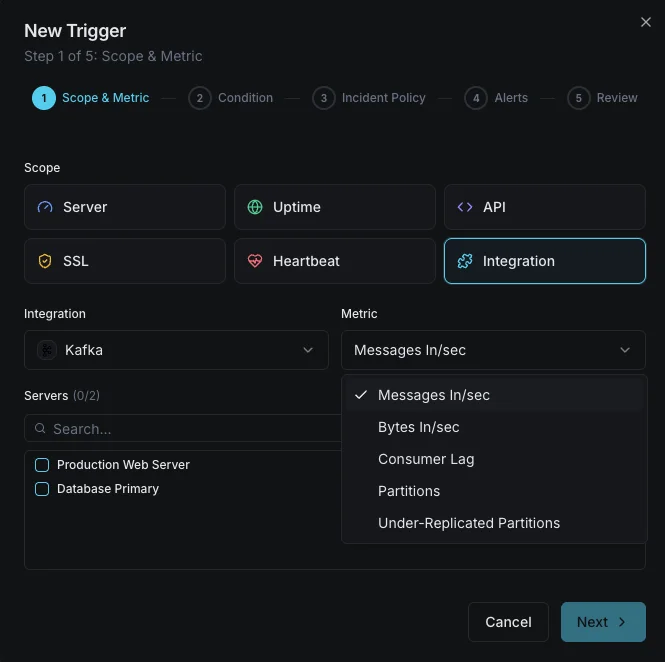
Scénarios courants de monitoring Kafka
Où Kafka fonctionne généralement aujourd'hui — et ce qui pourrait mal tourner si personne ne surveille.
La dorsale de messagerie connectant vos applications
Lorsque Kafka transporte les messages qui déplacent les données entre vos applications, tout ralentissement signifie qu'une application prend discrètement du retard — et les conséquences (mises à jour retardées, données obsolètes, flux de travail interrompus) n'apparaissent que plus tard. Nous détectons le décalage dès qu'il commence afin qu'il ne devienne jamais un problème visible pour le client.
Kafka fonctionnant dans Kubernetes
Lorsque Kafka fonctionne dans Kubernetes, la plateforme le déplace constamment — et un redémarrage de routine peut brièvement affaiblir le filet de sécurité qui protège vos données. Nous surveillons chaque redémarrage et rééquilibrage afin qu'une mise à jour normale ne puisse pas laisser discrètement le système à une seule défaillance de la perte de données.
Kafka autogéré pour les données à grand volume
Les entreprises qui gèrent leur propre Kafka à grande échelle ont besoin qu'il soit d'une solidité à toute épreuve — il transporte généralement les données les plus précieuses qu'elles possèdent. Nous surveillons les signaux qui le maintiennent en bonne santé afin que l'équipe puisse se concentrer sur la création de produits au lieu de gérer les problèmes de la couche de messagerie.
Prérequis pour Apache Kafka
Assurez-vous d'avoir tout cela en place — la plupart des installations sont une affaire de 60 secondes une fois ces conditions réunies.
- Brokers Kafka avec JMX activé (port par défaut 9999)
- Accessibilité réseau de Xitogent vers le port JMX de chaque broker
- Identifiants d'authentification JMX si la sécurité est configurée
Commencez par procès-verbal
Installer Xitogent sur chaque broker
Installez l'agent de monitoring léger Xitogent sur chaque broker Kafka que vous souhaitez surveiller.
curl -s https://xitoring.com/install.sh | sudo bash -s -- --key=YOUR_API_KEYActiver JMX sur chaque broker
Kafka expose les métriques des brokers via JMX. Définissez `KAFKA_JMX_OPTS` pour activer un listener JMX (typiquement port 9999) sur chaque broker, rechargez le service et confirmez que l'hôte de l'agent peut se connecter au port JMX.
sudo xitogent integrateActiver l'intégration Kafka
Utilisez le tableau de bord Xitoring ou la CLI pour activer l'intégration Kafka. Xitogent découvre automatiquement les IDs de brokers, topics et consumer groups dans le cluster.
Configurer les seuils d'alerte (facultatif)
Définissez des seuils personnalisés pour le consumer lag, les partitions sous-répliquées ou les événements Broker Down afin de détecter les problèmes de réplication et de back-pressure avant que les consumers ne prennent du retard.
Vérifier que tout fonctionne
Exécutez cette commande sur le serveur pour confirmer que Xitogent a bien détecté l'intégration. De nouvelles métriques apparaîtront sur votre tableau de bord dans environ 30 secondes.
sudo xitogent statusVous envisagez des alternatives ?
Découvrez comment Xitoring se positionne face aux alternatives pour la surveillance de Apache Kafka — tarifs forfaitaires, intégrations plus poussées et un seul agent pour couvrir tout votre stack.



Souvent a posé des questions
Les versions de Kafka ?
ZooKeeper ou KRaft ?
Que sont les partitions sous-répliquées et comment les corriger ?
Comment monitorer les métriques JMX des brokers Kafka avec Prometheus ?
Qu'est-ce que le mode KRaft et comment le monitoring change-t-il sans ZooKeeper ?
Comment détecter les partitions Kafka hors ligne ?
Comment monitorer un cluster Kafka sur Kubernetes (Strimzi) ?
Monitoring Kafka vs Redpanda — quelle est la différence ?
Quelles versions de Kafka sont prises en charge ?
Commencer à surveiller Apache Kafka aujourd'hui
Configuration en moins de 60 secondes. Aucune carte bancaire requise. Statistiques complètes dès le premier jour.
Commencer l'essai gratuitContinuez à explorer