Supervisor Suivi
Surveillez en temps réel tous les processus gérés par Supervisor : état (`RUNNING`/`FATAL`), durée de fonctionnement, arrêts inattendus, boucles de redémarrage et codes de sortie. Solution basée sur un agent via `supervisorctl`, avec une alerte dès qu’un processus passe à l’état `FATAL`.
Pourquoi surveiller ? Supervisor?
Supervisor (`supervisord`) maintient vos processus en arrière-plan actifs : les workers Celery et Sidekiq, les serveurs d’applications Gunicorn et uWSGI, les consommateurs de files d’attente et les démons à exécution longue. Mais après `startretries` tentatives de redémarrage infructueuses, il abandonne et place le processus dans l’état `FATAL`, où il reste inactif sans avertissement. La surveillance par processus fait toute la différence entre une alerte en une ligne et une file d’attente saturée que personne n’a remarquée pendant des heures.
Suivi par le responsable, expliqué
La surveillance par Supervisor consiste à suivre en permanence l'état de chaque programme géré par supervisord, ainsi qu'à déclencher une alerte lorsqu'un processus quitte l'état RUNNING. Supervisor est très efficace pour redémarrer un processus qui plante — mais uniquement startretries fois au cours de startsecs. Une fois cette limite dépassée, le processus passe à l’état FATAL et Supervisor cesse toute tentative de redémarrage. Rien d’autre ne s’en rend compte : l’hôte est opérationnel, le démon est opérationnel, mais la file d’attente cesse simplement de se vider. Xitoring lit la table des processus en temps réel via supervisorctl, suit chaque programme indépendamment et envoie une alerte à votre équipe de permanence dès qu’un worker passe à l’état FATAL, entre dans une boucle BACKOFF ou se termine avec un code de sortie inattendu.
Ce que nous surveillons
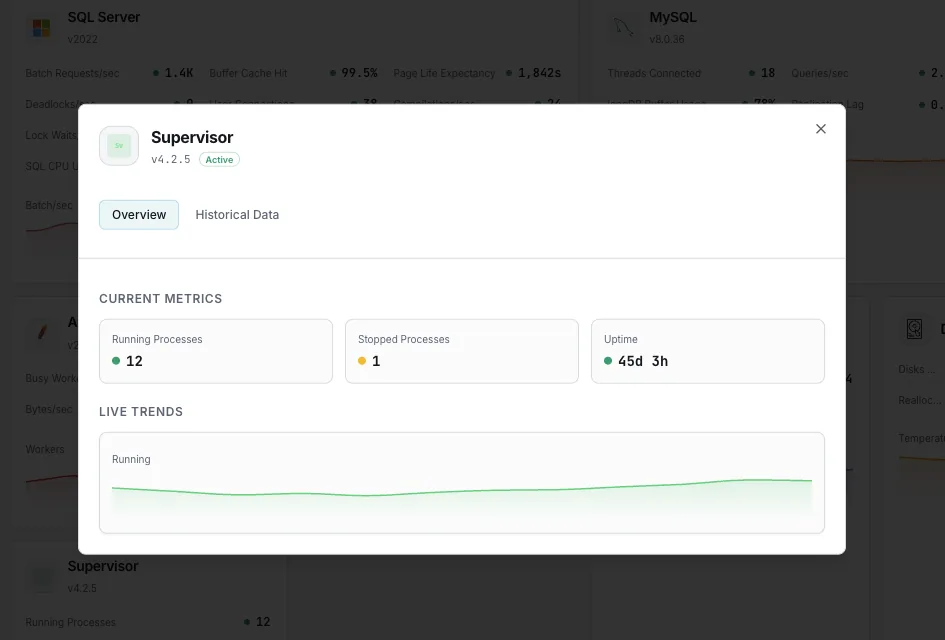
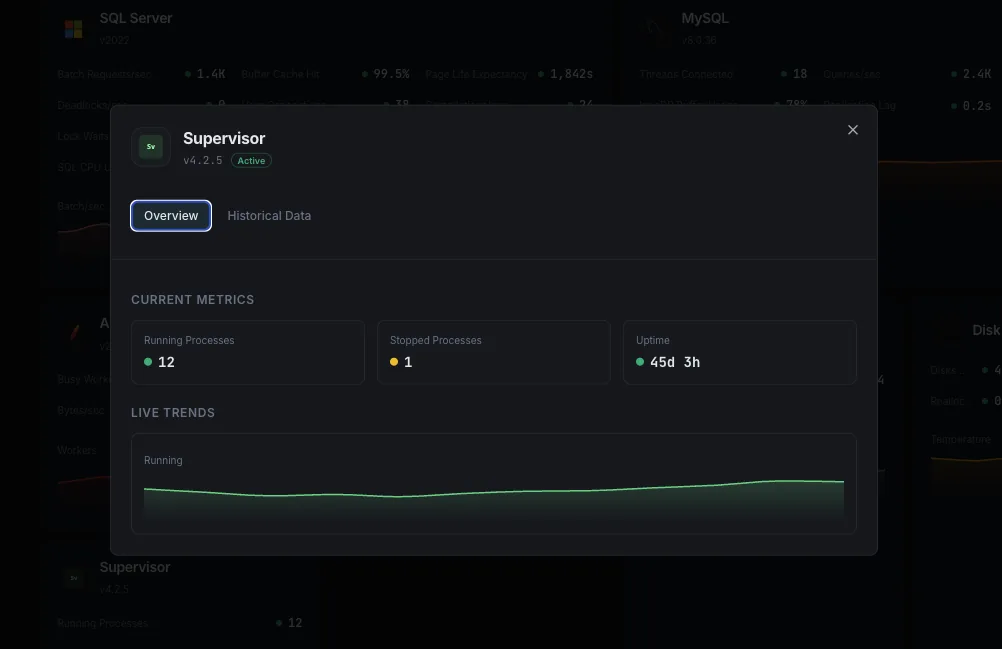
État du processus
L'état actuel de chaque programme (`RUNNING`, `STARTING`, `BACKOFF`, `EXITED`, `FATAL`, `STOPPED`, `STOPPING`, `UNKNOWN`). Le signal le plus important du superviseur : tout état autre que `RUNNING` pour un worker s'exécutant depuis longtemps constitue un problème.
État FATAL
Un processus qui a dépassé la limite `startretries` et qui a été interrompu par Supervisor. Il ne redémarrera pas de lui-même. Tout programme se trouvant dans `FATAL` génère un signal grave, justifiant la création d'une page.
BACKOFF / Redémarrer la boucle
Un processus qui s'arrête sans cesse avant `startsecs` et qui fait l'objet d'une nouvelle tentative. Un `BACKOFF` prolongé signifie qu'un worker instable consomme des ressources CPU lors des redémarrages et ne traite jamais le trafic.
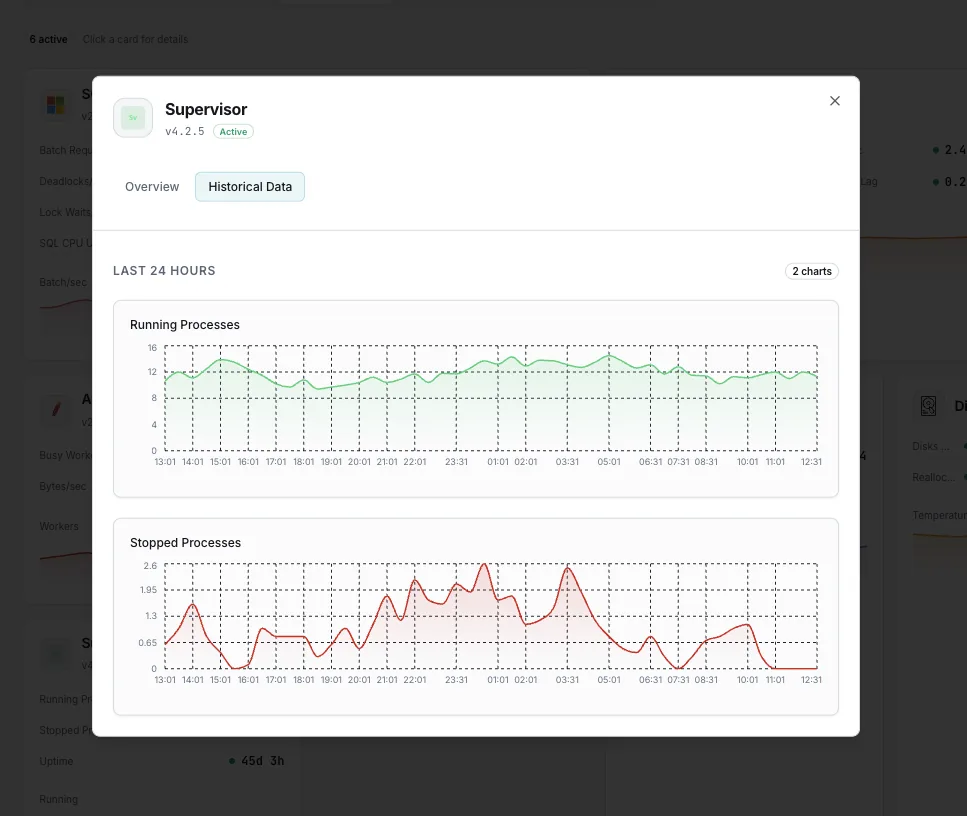
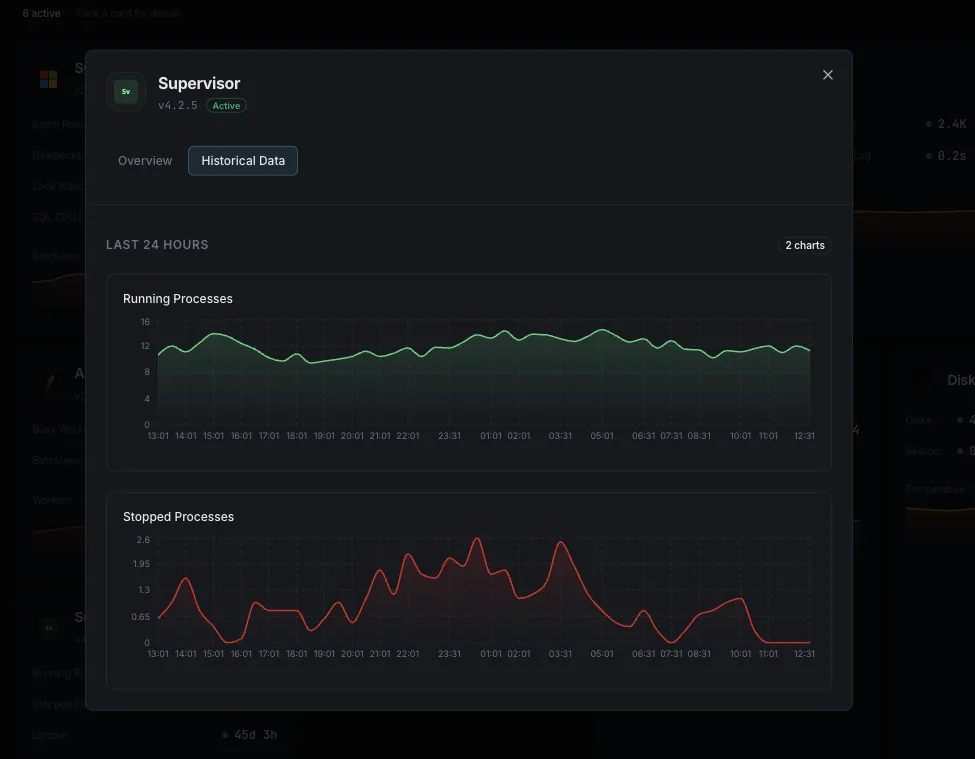
Temps de fonctionnement (depuis le démarrage)
Depuis combien de temps chaque processus détient son PID actuel. Un worker dont le temps de fonctionnement est constamment réinitialisé est en boucle de plantage silencieuse, même s’il affiche brièvement « RUNNING » entre deux redémarrages.
PID du processus
La valeur PID en temps réel par programme, telle qu'indiquée par la commande `supervisorctl status`. Sa présence confirme que le processus est bel et bien en cours d'exécution, et pas seulement configuré.
Code de la dernière sortie
Le code de sortie de la dernière exécution. Comparez-le aux `exitcodes` du programme pour distinguer un arrêt normal d'un plantage inattendu.
En cours d'exécution ou configuré
Nombre de processus effectivement en état `RUNNING` par rapport au nombre déclaré (y compris `numprocs`). Permet de repérer d'un seul coup d'œil les travailleurs manquants dans un groupe.
Départs inattendus
Génère une sortie avec un code ne figurant pas dans `exitcodes` lorsque `autorestart=unexpected`. Il s'agit de plantages qui n'auraient jamais dû se produire ; une augmentation de leur nombre indique une régression.
Nombre de redémarrages
Nombre de redémarrages de chaque processus au fil du temps. Un redémarrage fréquent d’un processus censé fonctionner en continu constitue un signe avant-coureur d’instabilité ou d’une fuite de mémoire.
Processus arrêtés
Programmes dont le statut est « `STOPPED` » ou « `EXITED` » et qui devraient être en cours d'exécution. Détecte un processus qu'un utilisateur a arrêté manuellement et qu'il a oublié, ou un processus qui s'est arrêté sans se redémarrer automatiquement.
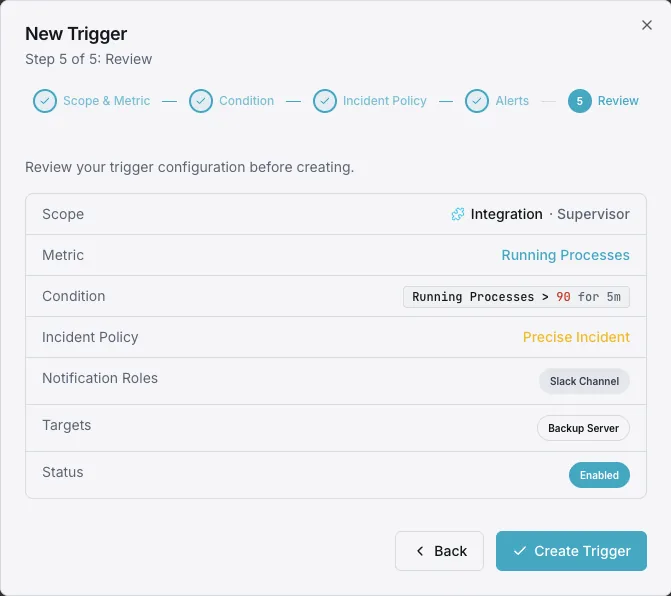
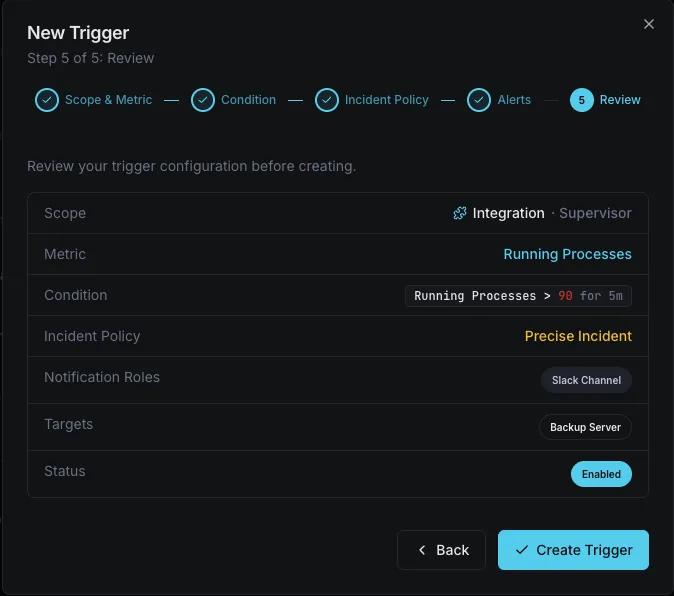
Configurables déclencheurs d'alerte
Configurez des déclencheurs personnalisés dans votre tableau de bord pour être averti dès que les indicateurs d{name}s dépassent les seuils que vous avez définis.
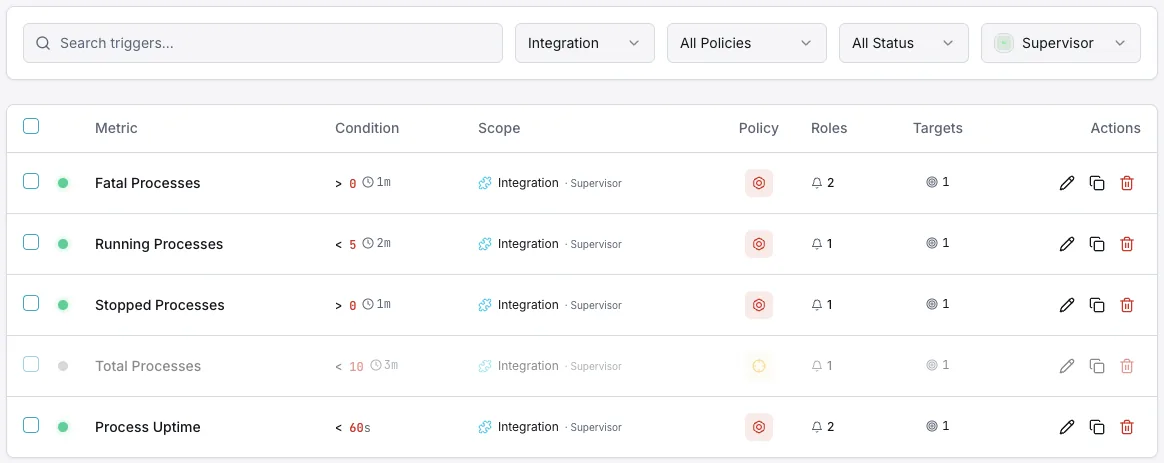
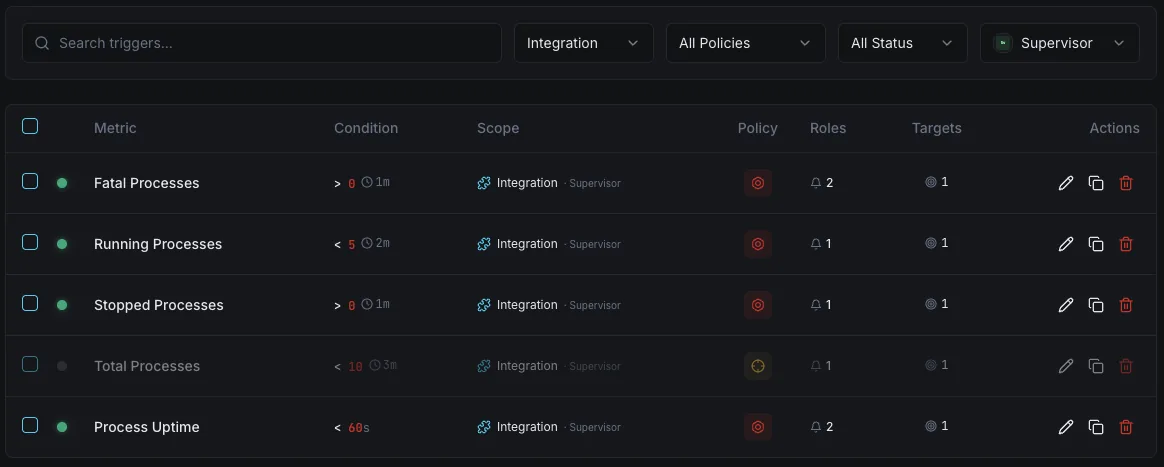
Processus FATAL
crucialSe déclenche lorsqu'un processus passe à l'état `FATAL` — le superviseur a renoncé à le redémarrer et celui-ci reste inactif jusqu'à ce que quelqu'un intervienne.
Le processus ne s'exécute pas
crucialSe déclenche lorsqu'un programme qui devrait être en état `RUNNING` est en état `STOPPED`, `EXITED` ou `UNKNOWN`.
Redémarrer la boucle
avertissementAlertes en cas de `BACKOFF` prolongé ou de redémarrages répétés — un worker qui plante sans cesse et ne parvient jamais à se stabiliser.
Code de sortie inattendu
avertissementSe déclenche lorsqu'un processus se termine avec un code ne figurant pas parmi les `exitcodes` configurés.
Importance de Suivi par le responsable
Le superviseur relancera un processus qui plante — jusqu'à ce qu'il n'y parvienne plus. Une fois le nombre de tentatives `startretries` atteint, le processus est mis en attente dans l'état `FATAL` et reste inactif, sans qu'aucun message ne s'affiche sur l'hôte pour vous en informer.
- Intercepter les processus qui rencontrent une erreur `FATAL` et empêcher leur redémarrage
- Détecter les processus bloqués dans des boucles « BACKOFF »
- Détecter les redémarrages silencieux en réinitialisant la durée de fonctionnement
- Savoir quand les employés quittent leur poste avec des codes inattendus
Pourquoi choisir Xitoring
Surveillance de « Supervisor » basée sur des agents, avec une configuration automatique et une visibilité au niveau de chaque processus pour tous les programmes gérés par « supervisord ».
- Installation et intégration en une seule commande
- Suivi par processus et par groupe
- Aucune interface XML-RPC ou HTTP à exposer
- Alertes multicanaux pour votre planning de permanence
- État historique et historique des redémarrages
Surveillance par le superviseur commun scénarios
Où Supervisor s'exécute généralement — et ce qui échoue en silence quand personne ne regarde.
Tâches en arrière-plan (Celery, Sidekiq, RQ, Resque)
Les workers de file d’attente sont précisément ces processus qui s’arrêtent sans crier gare : un déploiement raté ou un message corrompu les plonge dans une boucle de redémarrage, puis provoque une erreur FATAL. Nous envoyons une alerte dès qu’un worker cesse de fonctionner, avant que la file d’attente ne s’engorge et que les tâches ne commencent à expirer.
Serveurs d'applications et démons (Gunicorn, uWSGI, Daphne, Node)
Lorsque Supervisor gère votre serveur d'applications, un processus qui ne démarre pas après un déploiement signifie que le site est hors service alors que l'hôte est toujours en état « vert ». Nous détectons instantanément les codes FATAL et BACKOFF, ce qui permet d'alerter immédiatement un responsable en cas d'échec de déploiement, plutôt que d'attendre qu'un client signale le problème.
Processus dans des conteneurs et sur des hôtes existants
De nombreux conteneurs et serveurs plus anciens utilisent Supervisor à la place de systemd pour maintenir plusieurs processus actifs au même endroit. Nous surveillons chacun d'entre eux de manière indépendante, afin qu'un processus qui plante dans un conteneur très sollicité ne passe pas inaperçu parmi les autres.
Prérequis pour Supervisor
Assurez-vous d'avoir tout cela en place — la plupart des installations sont une affaire de 60 secondes une fois ces conditions réunies.
- Un serveur Linux sur lequel Supervisor (
supervisord) est installé et qui gère au moins un programme - Xitogent est installé sur le même hôte et permet d'exécuter la commande
supervisorctl status - Accédez à la commande
sudo xitogent integrateet sélectionnez l'intégration « Supervisor ».
Commencez par procès-verbal
Installez Xitogent sur votre serveur
Installez l'agent de surveillance léger Xitogent sur l'hôte exécutant Supervisor.
curl -s https://xitoring.com/install.sh | sudo bash -s -- --key=YOUR_API_KEYActiver l'intégration de Supervisor
Exécutez la commande `sudo xitogent integrate` et sélectionnez « Supervisor ». Xitogent crée le fichier `/etc/xitogent/integrations/supervisor_integration.conf`, lit la table des processus via `supervisorctl` et détecte automatiquement tous les programmes et groupes gérés par `supervisord` — aucune modification de la configuration de Supervisor n'est nécessaire.
sudo xitogent integrateConfigurer les déclencheurs (facultatif)
Définissez des déclencheurs et des niveaux de gravité par processus dans le tableau de bord Xitoring — par exemple, envoyez une alerte par page dès qu’un processus passe à l’état `FATAL`, et un avertissement en cas de `BACKOFF` prolongé ou de code de sortie inattendu — afin que les défaillances soient signalées à la personne de garde avant que la file d’attente ne s’engorge.
Vérifier que tout fonctionne
Exécutez cette commande sur le serveur pour confirmer que Xitogent a bien détecté l'intégration. De nouvelles métriques apparaîtront sur votre tableau de bord dans environ 30 secondes.
sudo xitogent statusVous envisagez des alternatives ?
Découvrez comment Xitoring se positionne face aux alternatives pour la surveillance de Supervisor — tarifs forfaitaires, intégrations plus poussées et un seul agent pour couvrir tout votre stack.



Souvent a posé des questions
Qu'est-ce que la surveillance par un superviseur ?
Comment Xitoring collecte-t-il les données relatives aux superviseurs ?
Comment configurer l'intégration de Supervisor ?
Que signifient les états du processus « Supervisor » ?
Que signifie l'état « FATAL » et pourquoi est-ce important ?
Comment détecter une boucle de redémarrage du superviseur ?
Quelle est la différence entre « autorestart true », « false » et « unexpected » ?
Puis-je surveiller plusieurs processus et groupes de processus ?
Supervisor ou systemd ? — Pourquoi surveiller spécifiquement Supervisor ?
Commencer à surveiller Supervisor aujourd'hui
Configuration en moins de 60 secondes. Aucune carte bancaire requise. Statistiques complètes dès le premier jour.
Commencer l'essai gratuitContinuez à explorer