Apache Kafka Monitoraggio
Monitora in tempo reale lo stato dei broker Apache Kafka, il ritardo delle partizioni, i gruppi di consumer e la velocità di trasmissione senza alcuna configurazione.
Perché monitorare Apache Kafka?
Apache Kafka è la colonna portante delle pipeline di dati in tempo reale e dello streaming di eventi. Il monitoraggio di Kafka garantisce il corretto funzionamento dei cluster di broker, un ritardo minimo dei consumer, una distribuzione ottimale delle partizioni e una consegna affidabile dei messaggi.
Monitoraggio di Kafka, in breve
Il monitoraggio di Kafka intercetta partizioni sotto-replicate, partizioni offline, picchi di lag dei consumer group, restringimenti dell'ISR, fallimenti del controller e pressione sul disco prima che provochino perdita di dati, fallimenti di microservizi a valle o interruzioni complete dei broker. Per pipeline CDC, sistemi di event sourcing, eventistica tra microservizi e qualsiasi cluster Kafka in produzione, la visibilità per broker e per consumer group è ciò che separa un avviso di 60 secondi su un consumer in ritardo dal trovarsi un arretrato di 50 milioni di messaggi a fine giornata. Xitoring rileva automaticamente i suoi broker, legge le MBean JMX e gli offset dei consumer, e instrada gli avvisi verso Slack, PagerDuty, Telegram o il suo on-call esistente.
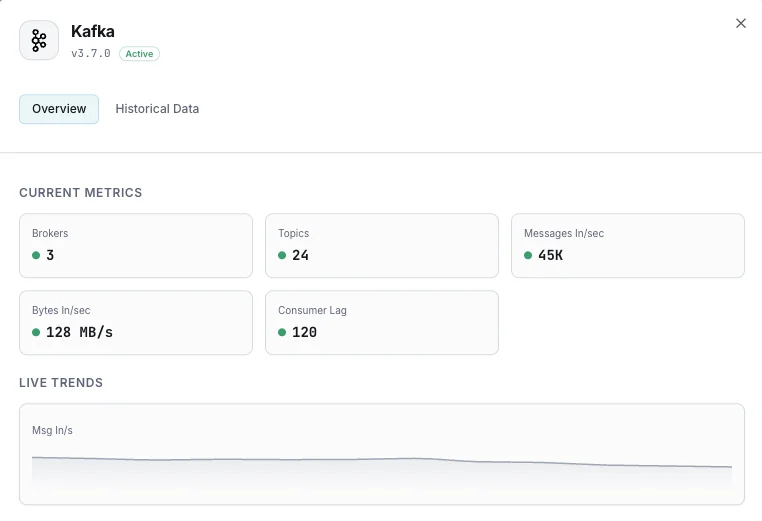
Ciò che monitoriamo
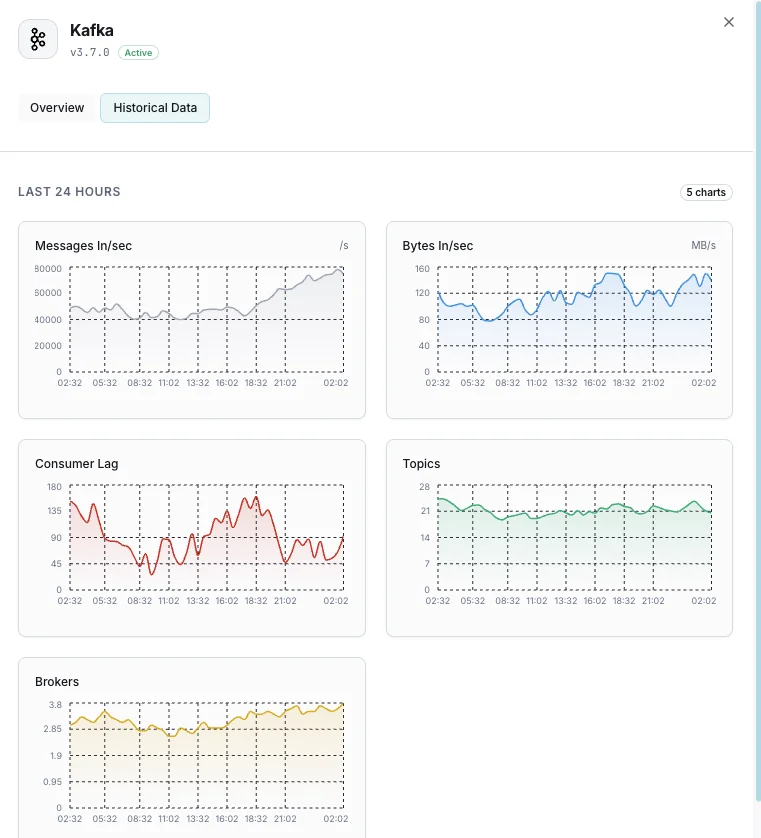
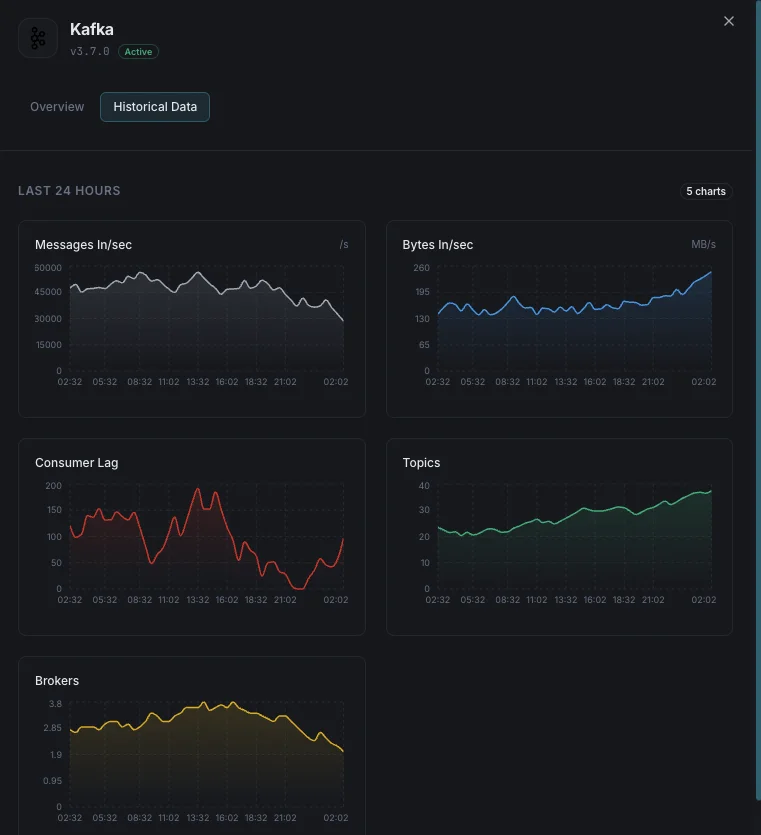
Numero di broker
Broker attivi nel cluster.
Lag dei consumer
Messaggi in ritardo per ogni consumer group.
Messaggi in ingresso/sec
Tasso di ingestione dei messaggi.
Byte in entrata/uscita
Throughput di rete per broker.
Partizioni sottoreplicate
Partizioni al di sotto del fattore di replica.
Riduzioni ISR
Eventi di shrink delle repliche in sincronia.
UncleanLeaderElectionsPerSec
Tasso di repliche fuori sincronia promosse a leader (con perdita di dati). Dovrebbe essere 0: un valore diverso da zero significa che `unclean.leader.election.enable=true` E si è verificato un evento di fallimento reale.
MessagesInPerSec / BytesIn / BytesOut
Throughput per broker e per topic. Cali improvvisi con numero di producer stabile = problema di ingest; picchi improvvisi = tempesta di retry o producer fuori controllo.
Latenza delle richieste (p99)
p99 del tempo di gestione delle richieste Produce, Fetch e Metadata da `kafka.network:type=RequestMetrics`. Intercetta il sovraccarico del broker prima che provochi timeout lato client.
LeaderCount per broker
Leader di partizione per broker. Distribuzione disomogenea (un broker che detiene il 60%+ dei leader) = cluster sbilanciato, da correggere con `kafka-reassign-partitions.sh` o.
Dimensione del log per topic
Dimensione aggregata del log su disco per topic da `kafka.log:type=Log,name=Size`. Guida gli avvisi sullo spazio su disco e informa le policy di tiered storage in Kafka 3.8+.
RemoteLogManager (tiered storage)
Metriche di tiered storage di Kafka 3.8+: byte caricati nel tier remoto, segmenti remoti vs locali, latenza di fetch dal remoto. Intercetta problemi di connettività S3 / IAM che rompono i fetch tiered.
Configurabile condizioni di attivazione
Imposta dei trigger personalizzati nella tua dashboard per ricevere una notifica non appena le metriche dell{name}e superano le soglie da te definite.
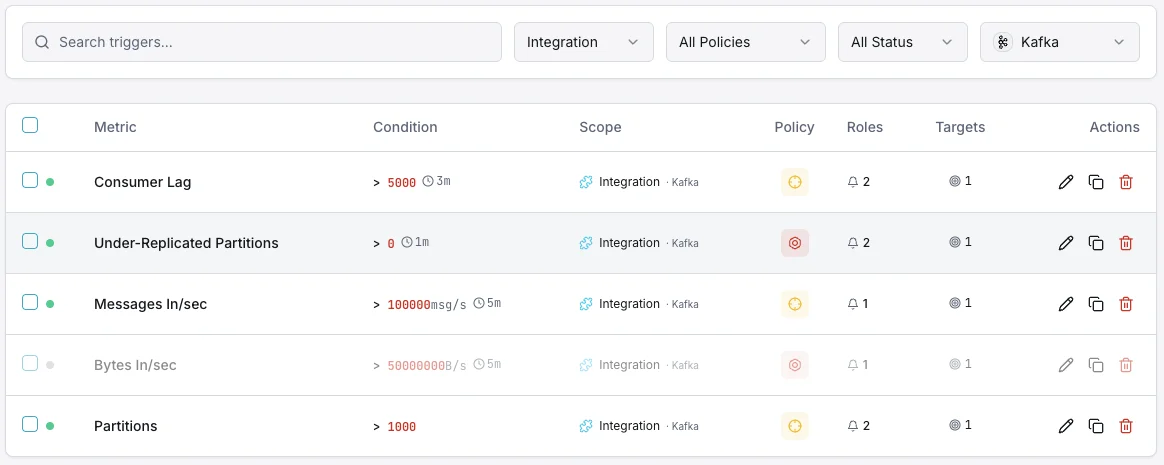
Lag dei consumer
criticoSi attiva quando un consumer resta indietro.
Partizioni sottoreplicate
criticoAvvisa su problemi di replica.
Broker offline
criticoSi attiva quando un broker lascia il cluster.
Utilizzo disco
avvisoSi attiva quando il disco del broker si sta riempiendo.
Importanza del monitoraggio Kafka
Kafka elabora migliaia di miliardi di messaggi al giorno. Lag dei consumer, guasti dei broker e squilibrio delle partizioni possono causare guasti nelle pipeline dati.
- Rileva il lag dei consumer prima della perdita di dati
- Monitora l'ISR per la durabilità dei dati
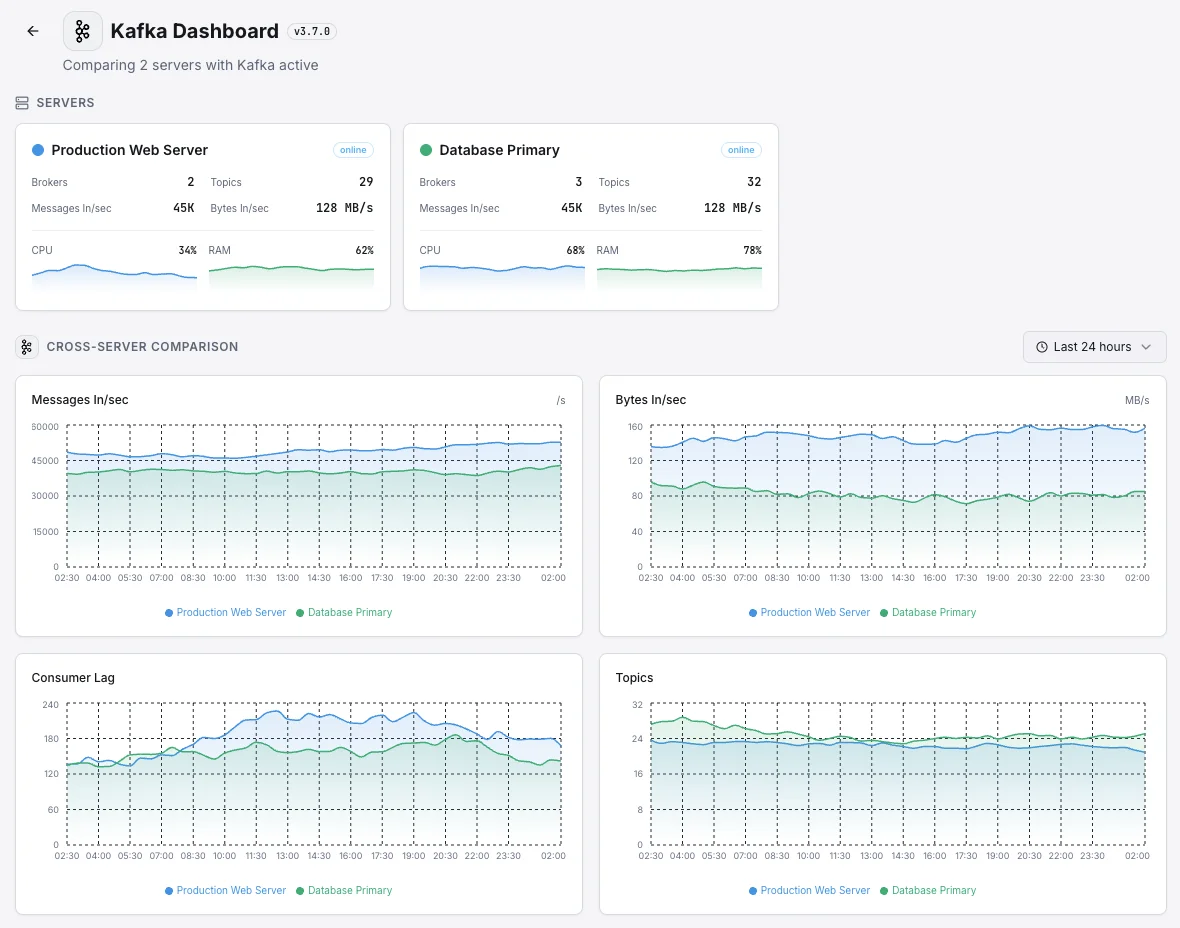
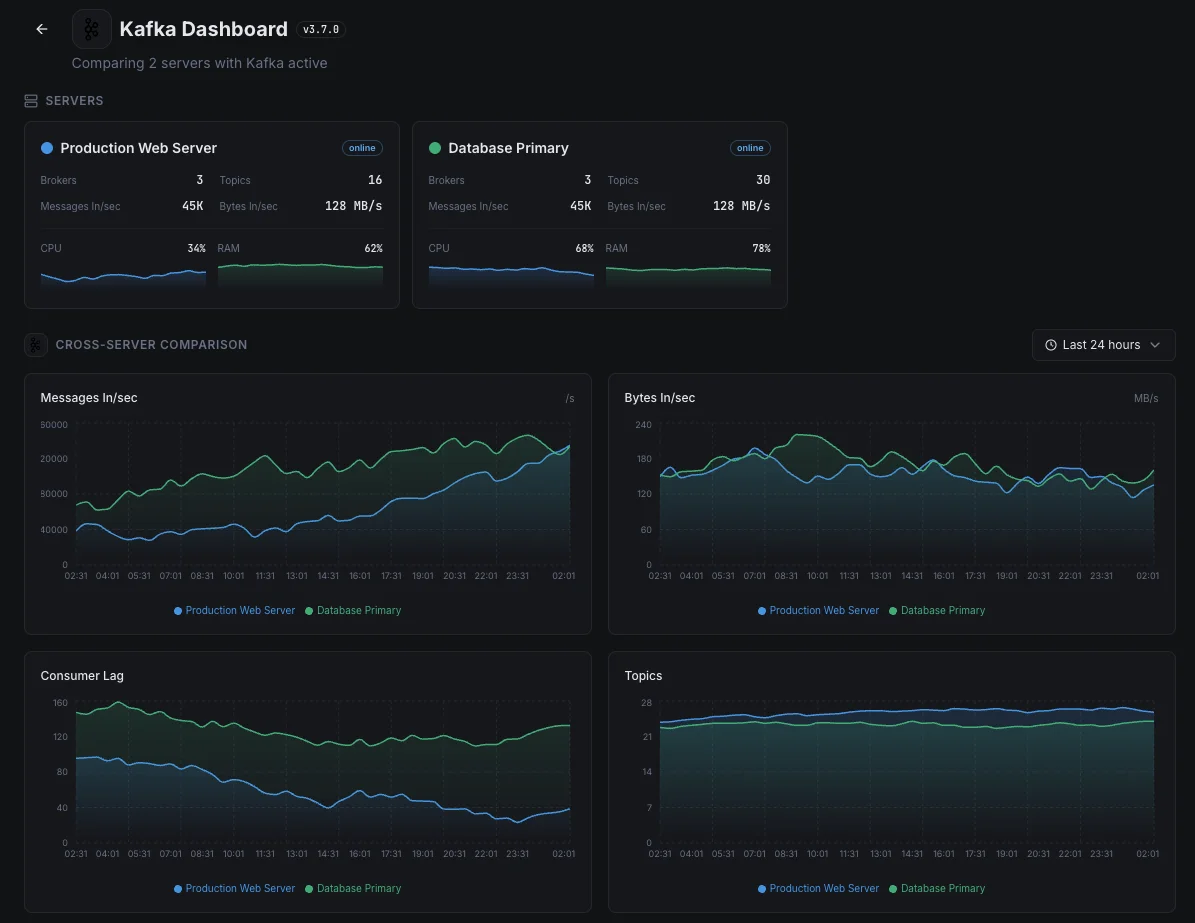
- Tieni traccia dello stato dei broker tra cluster
- Garantisci il bilanciamento delle partizioni
Perché scegliere Xitoring
Monitoraggio Kafka di livello enterprise.
- Configurazione zero-config
- Nodi globali
- Dashboard unificata
- Avvisi multicanale
- Conservazione storica
Scenari comuni di monitoraggio di Kafka
Dove Kafka viene tipicamente eseguito oggi — e cosa potrebbe andare storto se nessuno lo monitora.
La dorsale di messaggistica che collega le tue app
Quando Kafka trasporta i messaggi che spostano i dati tra le tue app, qualsiasi rallentamento significa che un'app sta silenziosamente rimanendo indietro — e le conseguenze (aggiornamenti ritardati, dati obsoleti, flussi di lavoro interrotti) si manifestano solo in seguito. Rileviamo il ritardo nel momento in cui inizia in modo che non diventi mai un problema visibile al cliente.
Kafka in esecuzione all'interno di Kubernetes
Quando Kafka viene eseguito in Kubernetes, la piattaforma lo sposta costantemente — e un riavvio di routine può indebolire brevemente la rete di sicurezza che protegge i tuoi dati. Monitoriamo ogni riavvio e ribilanciamento in modo che un normale aggiornamento non possa silenziosamente lasciare il sistema a un solo guasto dalla perdita di dati.
Kafka autogestito per dati ad alto volume
Le aziende che gestiscono il proprio Kafka su larga scala hanno bisogno che sia estremamente solido — di solito trasporta i dati più preziosi che possiedono. Monitoriamo i segnali che lo mantengono in salute in modo che il team possa concentrarsi sulla creazione di prodotti invece di risolvere problemi sullo strato di messaggistica.
Prerequisiti per Apache Kafka
Assicurati di avere tutto questo in posizione — la maggior parte delle installazioni dura 60 secondi una volta soddisfatte le condizioni.
- Broker Kafka con JMX abilitato (porta predefinita 9999)
- Raggiungibilità di rete da Xitogent verso la porta JMX di ciascun broker
- Credenziali di autenticazione JMX se la sicurezza è configurata
Inizia con verbali
Installa Xitogent su ogni broker
Installa il leggero agente di monitoraggio Xitogent su ogni broker Kafka che vuoi monitorare.
curl -s https://xitoring.com/install.sh | sudo bash -s -- --key=YOUR_API_KEYAbilita JMX su ogni broker
Kafka espone le metriche broker via JMX. Imposta `KAFKA_JMX_OPTS` per abilitare un listener JMX (tipicamente porta 9999) su ogni broker, ricarica il servizio e conferma che l'host dell'agente possa connettersi alla porta JMX.
sudo xitogent integrateAbilita l'integrazione Kafka
Usa la dashboard di Xitoring o la CLI per abilitare l'integrazione Kafka. Xitogent scopre automaticamente ID dei broker, topic e consumer group nel cluster.
Configura le soglie di allerta (opzionale)
Imposta soglie personalizzate per Consumer Lag, partizioni sotto-replicate o eventi Broker Down per intercettare problemi di replicazione e back-pressure prima che i consumer rimangano indietro.
Verifica che funzioni
Esegui questo comando sul server per confermare che Xitogent ha rilevato l'integrazione. In circa 30 secondi nuove metriche cominceranno a comparire sulla tua dashboard.
sudo xitogent statusStai valutando alternative?
Scopri come Xitoring si confronta con le alternative per il monitoraggio di Apache Kafka — prezzi fissi, integrazioni più approfondite e un unico agente che copre l'intero stack.



Spesso domande poste
Versioni di Kafka?
ZooKeeper o KRaft?
Cosa sono le partizioni sotto-replicate e come le risolvo?
Come monitoro le metriche JMX dei broker Kafka con Prometheus?
Cos'è la modalità KRaft e come cambia il monitoraggio senza ZooKeeper?
Come rilevo le partizioni offline in Kafka?
Come monitoro un cluster Kafka su Kubernetes (Strimzi)?
Monitoraggio Kafka vs Redpanda: cosa cambia?
Quali versioni di Kafka sono supportate?
Inizia a monitorare Apache Kafka oggi
Configurazione in meno di 60 secondi. Non è richiesta alcuna carta di credito. Statistiche complete fin dal primo giorno.
Inizia la prova gratuitaContinua a esplorare