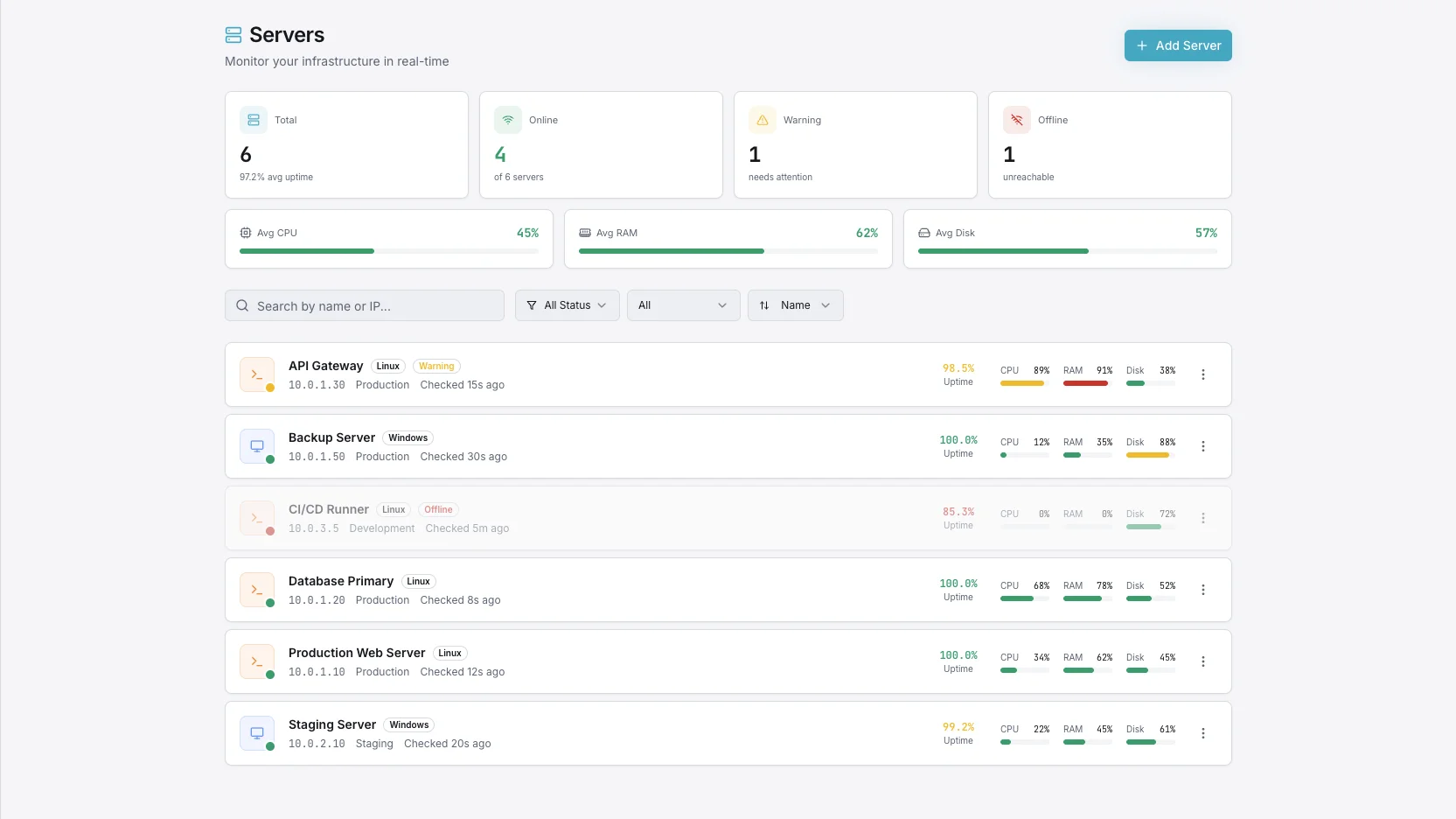
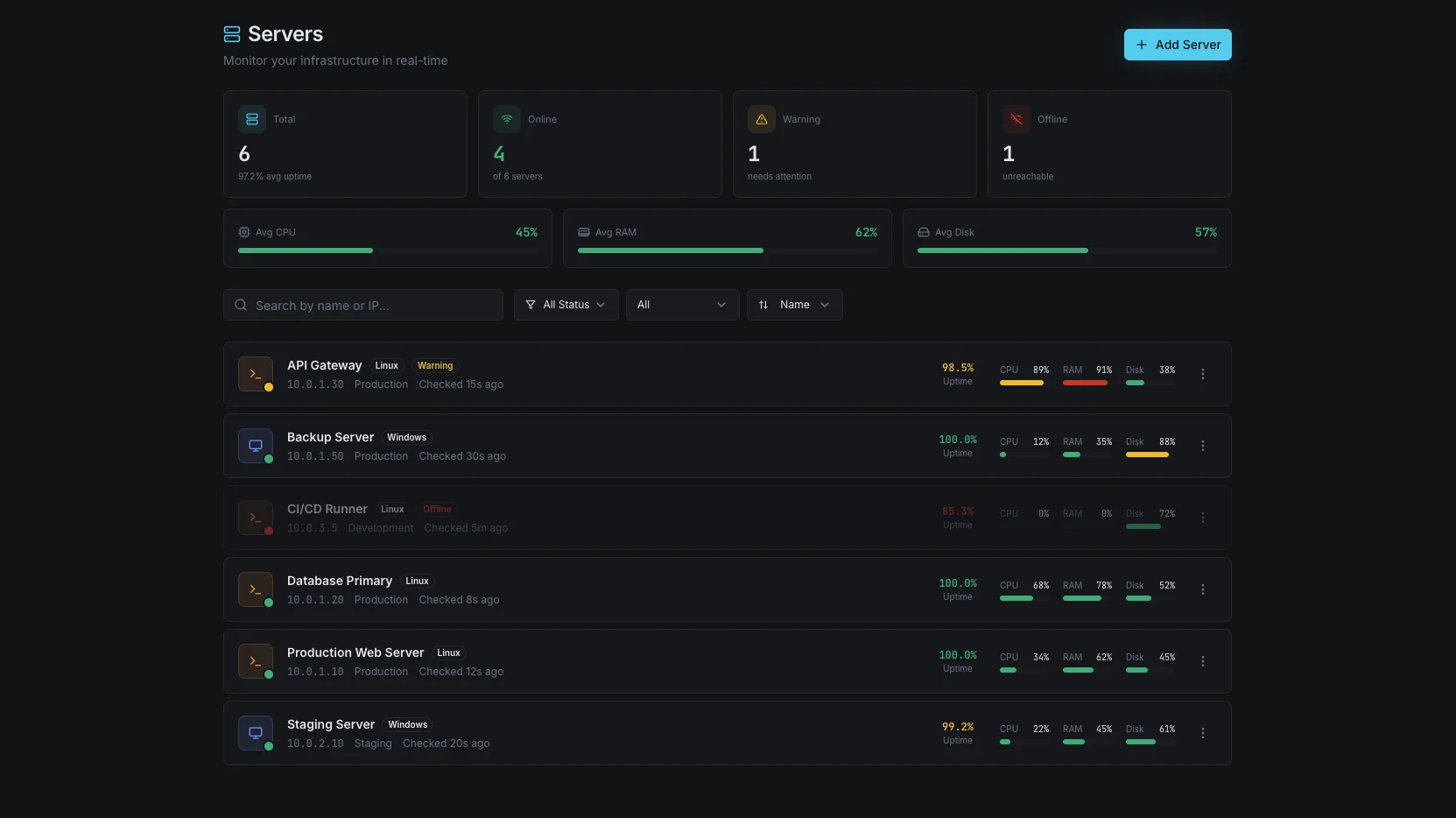
異常検知 &
根本原因分析
Xitoringは、すべてのホストとメトリックで「正常」がどのようなものかを学習し、静的閾値がトリガーされる前に、動作がドリフトした瞬間に警告します。インシデントが発生した際には、AIアシストによる根本原因分析が直接原因を特定します。
お客様の声
数千社から信頼されています — で評価されています
世界トップクラスのレビュープラットフォームで、Xitoringの実際のユーザーの声をご覧ください。
異常検知とは何ですか?
異常検知とは、統計的および機械学習技術を使用して、メトリックストリーム内で期待されるものから意味のある逸脱を示すデータポイント、イベント、またはトレンドを特定することです。インフラストラクチャ監視では、脆弱な静的閾値を、各システムの通常のリズム(ピーク時間、週末の閑散期、バッチ処理時間)を学習し、動作が変化する瞬間をフラグ付けする適応モデルに置き換えます。これにより、オペレーターは固定閾値がトリガーされるずっと前に、緩やかな変化やパターンシフトを調査する機会を得ることができます。
キー 特長
『異常検知 &』に必要なものはすべてこちら:根本原因分析。
予測AI検知
機械学習は、すべてのメトリックを監視し、異常なパターン(緩やかなドリフト、突然の変化、周期的なグリッチ)を検知し、閾値ベースのアラートが発動する前にソフトアラートを発生させます。
根本原因管理
インシデントが発生すると、AIはメトリック、デプロイ、アラート、ホストイベントを関連付け、可能性のある原因を特定します。トリガーを探すための45分間の緊急会議はもう必要ありません。
自動学習ベースライン
すべてのホストに閾値を設定する必要はありません。Xitoringは、日次、週次、季節のパターンを自動的に考慮した、ホストごと、メトリックごとのベースラインを構築します。
マルチシグナル相関
異常はめったに一箇所に現れません。AIはCPU、メモリ、ディスク、ネットワーク、応答時間、サービスイベントを相互に関連付け、真の状況を特定します。
アラート疲労の軽減
静的閾値は、過剰に発動するか、実際の問題を見逃すかのどちらかです。適応型検知は、予期される動作を抑制し、実際の逸脱を表面化させることでノイズを削減します。
インシデント予測
メトリックが既知の障害モード(ディスクの満杯、メモリリーク、レイテンシの増加)に向かっている場合、AIは影響までの時間を予測し、早期に対処できるようにします。
問題を発見 前に インシデントになる
Xitoringの異常検知は、単なるスマートな閾値ではありません。それは、すべてのホストのすべてのメトリックで「正常」がどのようなものかを学習し、逸脱が始まったときにフラグを立て、インシデントが発生したときに根本原因まで追跡する継続的なAIループです。
- 閾値ベースのアラートが発動する前の予測アラート
- ホストごと、メトリックごとの自動学習ベースライン
- 日次、週次、季節のパターン認識
- すべてのインシデントに対するAIアシストによる根本原因分析
- CPU、メモリ、ディスク、ネットワークにわたるマルチシグナル相関
- アラート疲労を軽減するための重大度スコアリング
- 傾向のある障害に対する影響までの時間予測
- Slack、PagerDuty、Teams、Webhookなどと連携
- 手動での閾値調整は不要
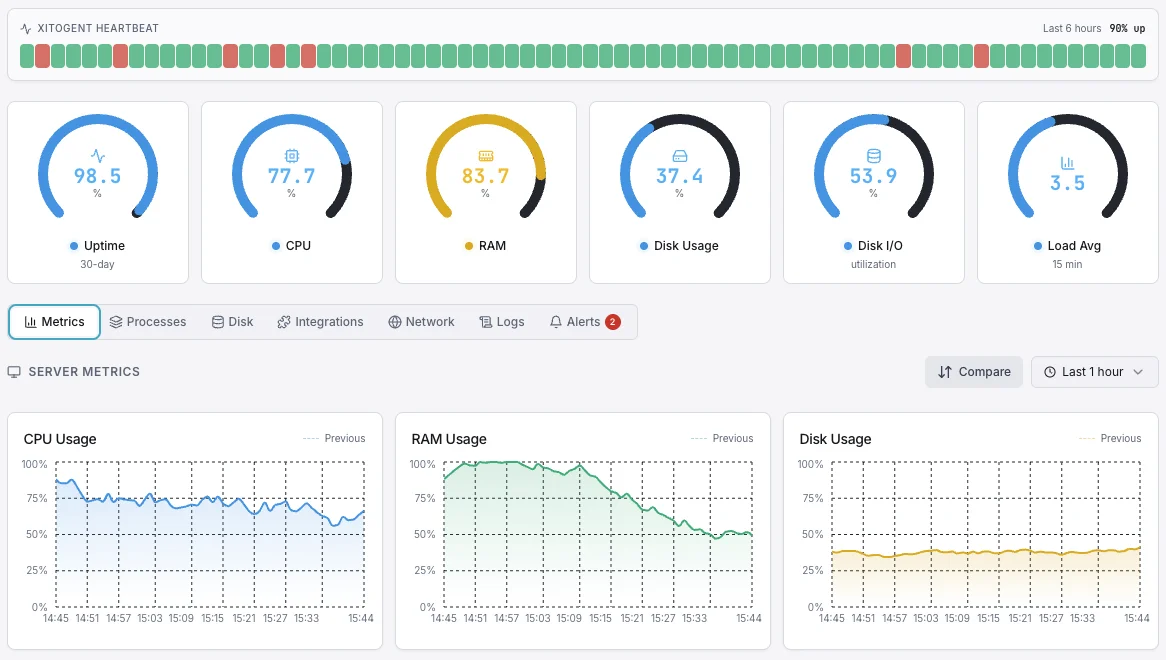
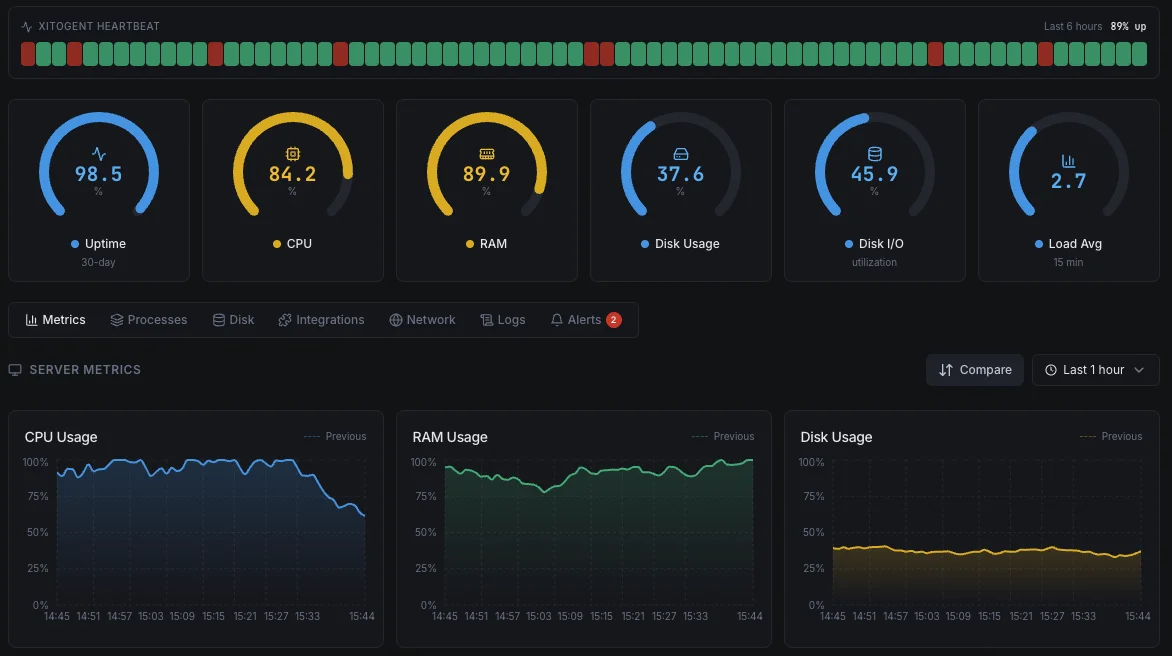
対象者
異常検知 ユースケース
さまざまな業界の企業が、Xitoringを活用してインフラの信頼性を維持している様子をご覧ください。
クラウドフリート
静的閾値は、異なるワークロードを持つ数百のAWS、Azure、GCPインスタンスにはスケールしません。適応型検知は各ホストのリズムを学習するため、VMごとのルールを作成する必要はありません。
データベース運用
パターンが変化するにつれて、遅いクエリの回帰、レプリケーションのドリフト、接続プールの枯渇を検知します。ダウンタイムメトリックが赤くなるずっと前に。
Eコマースの信頼性
チェックアウトの遅延、支払いレイテンシのドリフト、カート放棄のパターンが収益に影響を与える前に検知します。ダッシュボードが表示する前にAIが低下を認識します。
SaaSプラットフォーム
テナント固有のアラートルールを作成することなく、特定のテナントの異常(ある顧客のワークロードの不具合、あるリージョンの劣化など)を特定します。
フィンテックとコンプライアンス
単純な閾値では見逃してしまう、異常なトランザクションパターン、認証スパイク、APIの異常を明らかにします。監査証跡のためにすべての検出を記録します。
DevOps & SREチーム
インシデント後の振り返りをより迅速なループに変えます。根本原因分析により、問題を引き起こした変更、デプロイ、またはアップストリームのシグナルを特定します。
なぜ異常検知なのか 検知
閾値ベースのアラートは、数ヶ月前に推測したラインをメトリックがすでに超えた後にのみ発動します。実際のインシデントは、小さな逸脱(遅いメモリリーク、50ミリ秒のレイテンシー増加、1時間に2%増加するチェックアウトキューなど)から始まります。異常検知は、これらの逸脱を最初の1分から検知し、対応する時間を与えます。
- ユーザーやダッシュボードが気づく前に問題をキャッチ
- 陳腐化するホストごとの閾値ルールの作成をやめる
- 閾値では決してトリガーされない緩やかな変化を検知
- モデル化していなかった季節性や週末のパターンを明らかにする
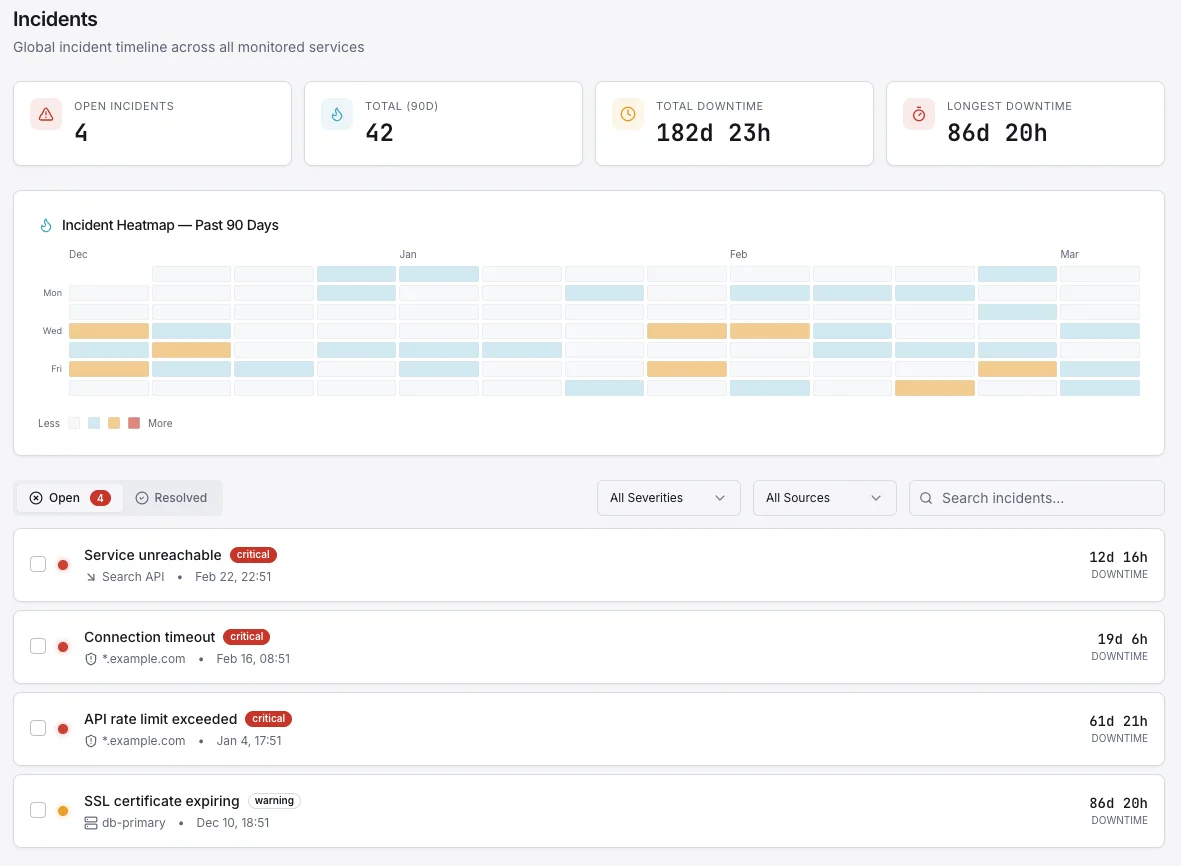
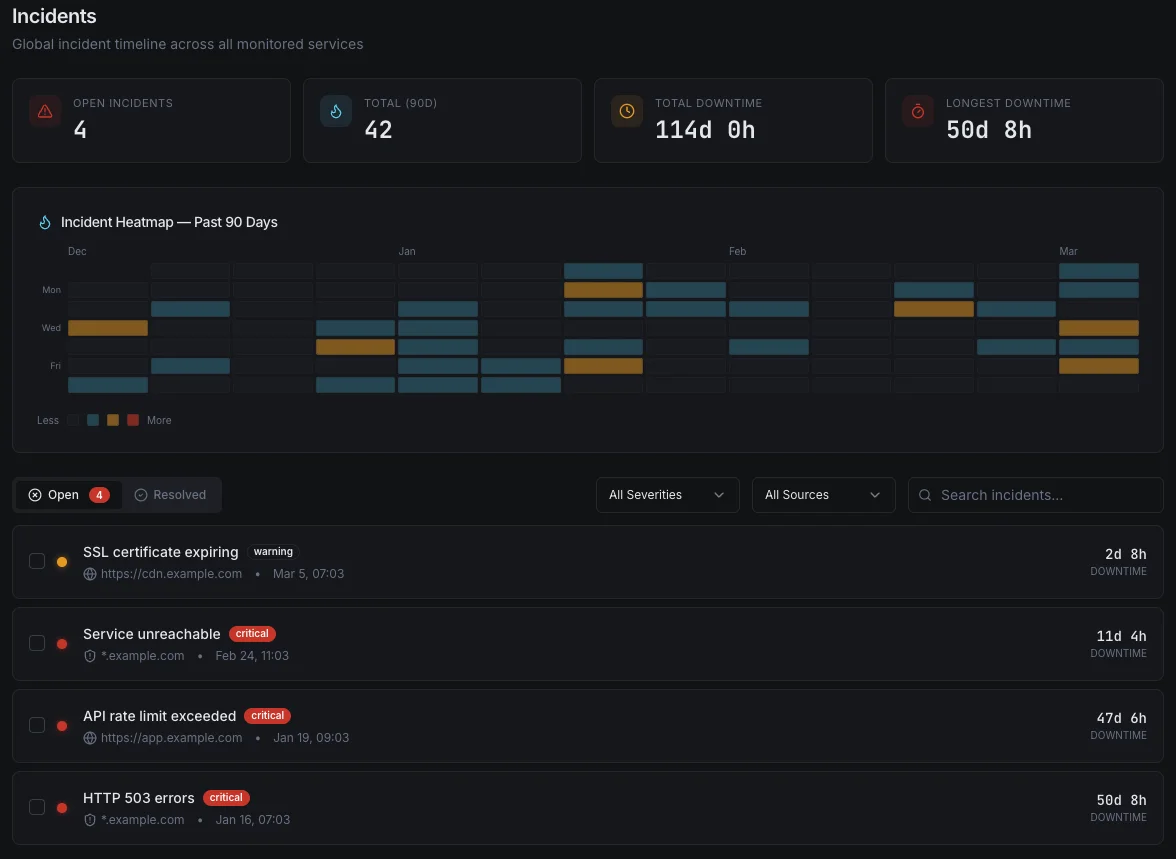
根本原因分析、 自動化
インシデントが発生した際、ダッシュボードを調べて費やす1秒1秒が、顧客が苦痛を感じる時間となります。XitoringのAIは、オンコール担当者が通話に参加し終える前に、メトリックの異常、最近のデプロイ、サービスイベント、過去のインシデントを関連付け、証拠とともに可能性のある原因を特定します。
- CPU、メモリ、ディスク、ネットワーク、アプリのメトリックを数秒で関連付け
- インシデント付近の最近のデプロイと設定変更を明らかにする
- 類似のフィンガープリントを持つ過去のインシデントと照合
- 事後分析のために平易な英語でインシデント概要を生成
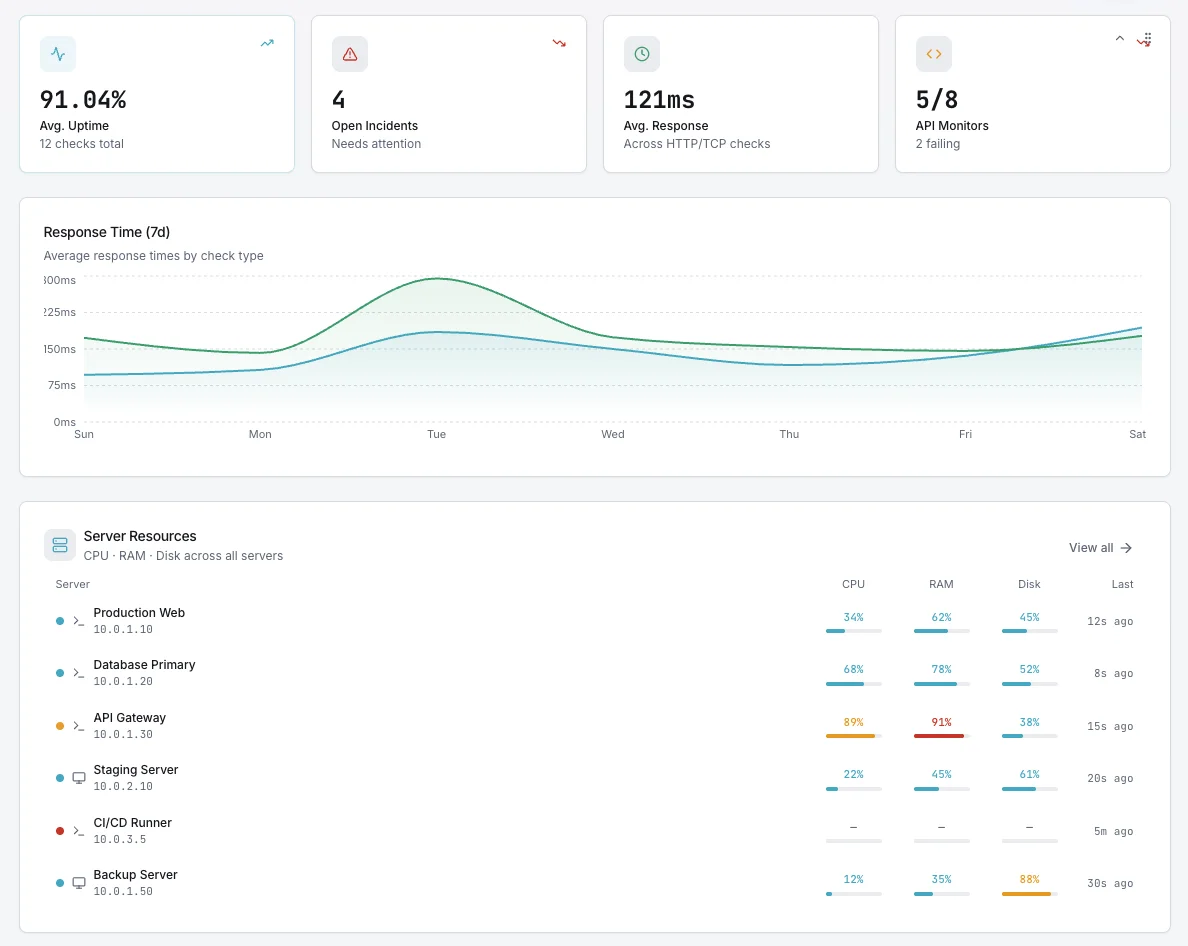
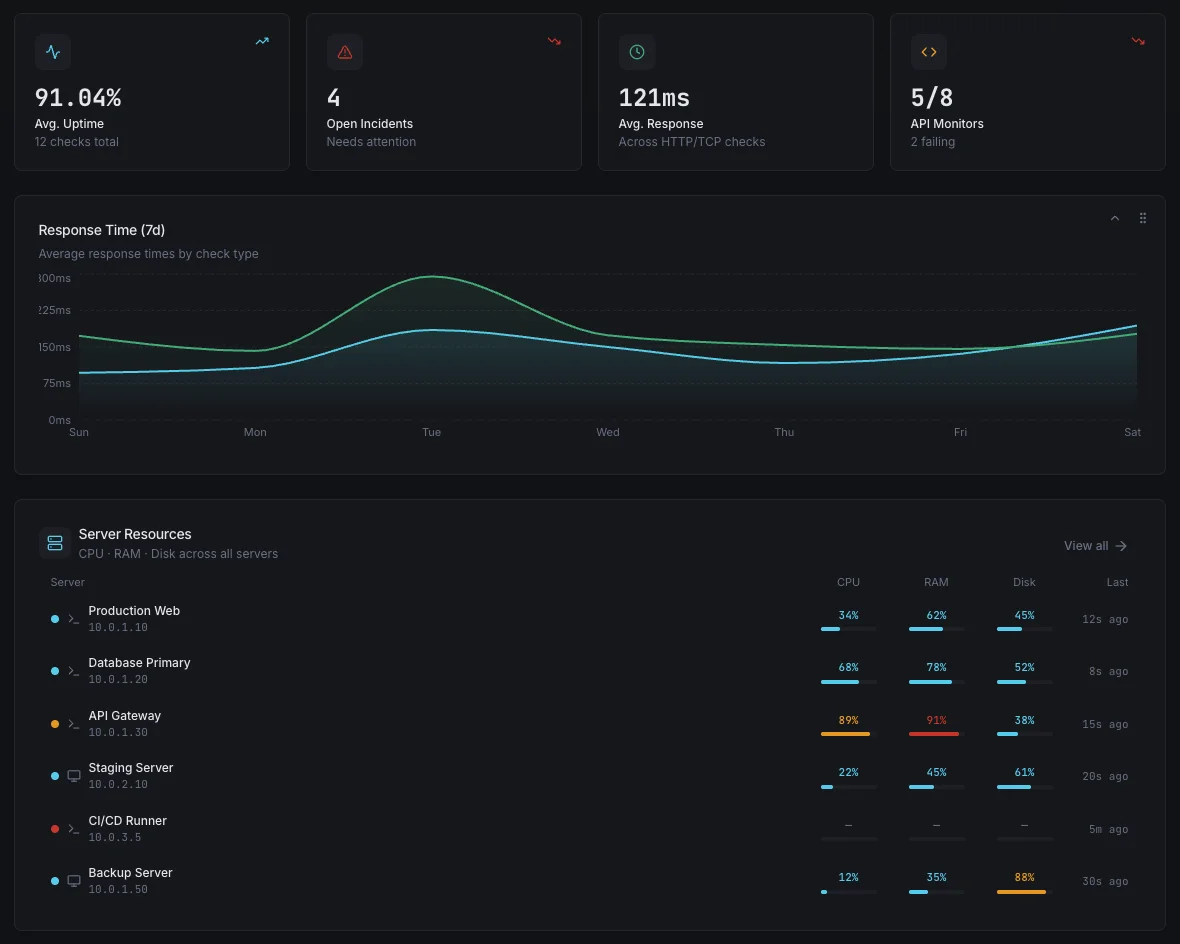
仕組み 動作
手動調整不要
ホストごと、またはフリート全体で有効にします。ベースラインは学習期間中に自己調整されるため、インフラストラクチャの成長に合わせて閾値を細かく調整したり、ルールを維持したりする必要はありません。
重大度認識
すべての異常がインシデントであるとは限りません。検知は重大度、影響範囲、過去の影響に基づいてスコアリングされるため、オンコール担当者は実際のシグナルに対してのみ呼び出されます。
お使いのチャネルと連携
異常アラートは、静的チェックと同じ通知チャネル(Slack、メール、SMS、PagerDuty、Teams、Webhook、その他15以上)を通じて流れます。
頻繁に 質問をした
異常検知 &に関するよくある質問 根本原因分析.
Xitoringの異常検知はどのように機能しますか?
これは単なるスマートな閾値ですか?
根本原因分析とは何ですか?
静的閾値はまだ必要ですか?
学習期間はどのくらいかかりますか?
これによりアラート量が増加しますか?
どのメトリックが異常検知をサポートしていますか?
これには追加の設定や新しいエージェントが必要ですか?
異常検知と根本原因分析を組み合わせることで、インシデント対応はどのように短縮されるのでしょうか?
反応するのをやめましょう。予測を始めましょう。
静的閾値は問題が発生した後にしか検知できません。XitoringのAIは、すべてのホストのリズムを学習し、ユーザーが気づく前に異常な動作を表面化させます。一度オンにするだけで、アラートはそこから賢くなります。
無料トライアルを開始
探検を続けよう