CoreDNS 監視
設定不要で、CoreDNSのクエリ発生率、キャッシュヒット率、解決遅延、およびエラー率をリアルタイムで監視できます。
なぜ監視するのか CoreDNS?
CoreDNSは、Kubernetesおよびクラウドネイティブ環境におけるデフォルトのDNSサーバーです。CoreDNSを監視することで、インフラストラクチャにおける高速なDNS解決、健全なキャッシュパフォーマンス、そして信頼性の高いサービスディスカバリを確保できます。
CoreDNS 監視を 解説
CoreDNS 監視は、SERVFAIL の急増、キャッシュヒット率の低下、forward プラグインのレイテンシー、パニック関連の再起動を、クラスター全体の DNS 解決失敗へとカスケードする前に検出します。すべてのマイクロサービスがサービスディスカバリーで DNS に依存しているため、監視されていない CoreDNS は Kubernetes クラスター全体の監視されていない障害モードを意味します。DNS の問題は至る所で「ランダムな connection refused」として現れます。Xitoring は CoreDNS を自動検出し、:9153/metrics をスクレイプし、Slack、PagerDuty、Telegram、既存のオンコールへアラートを配信します。
私たちが 監視するもの
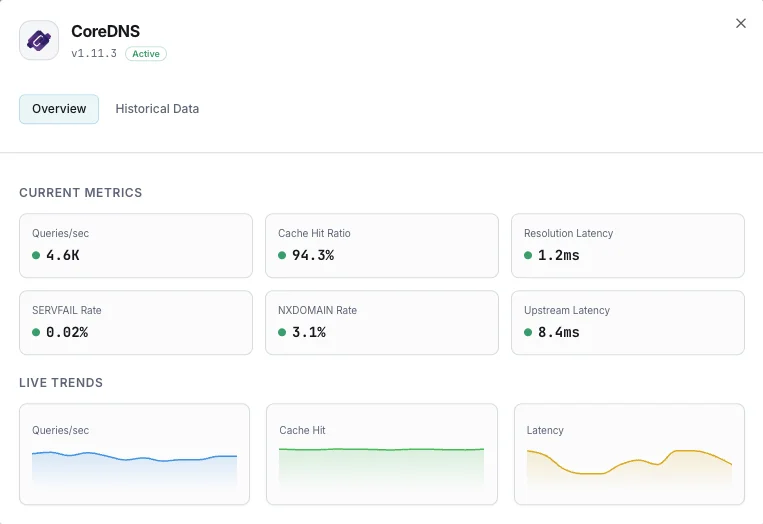
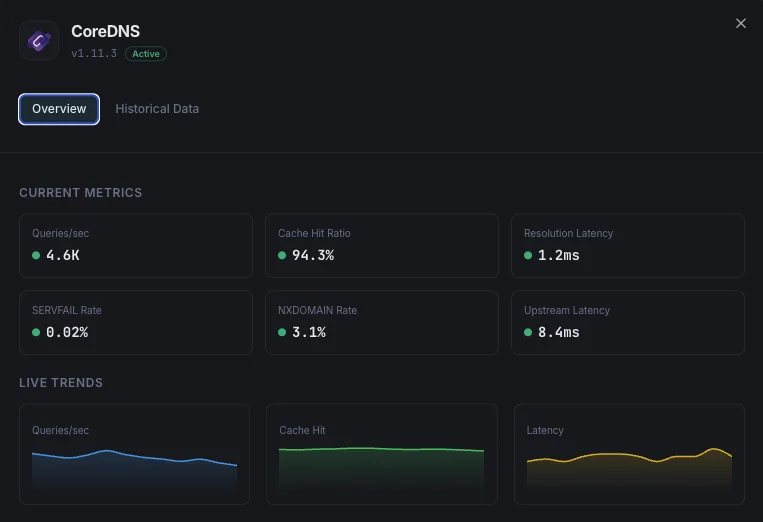
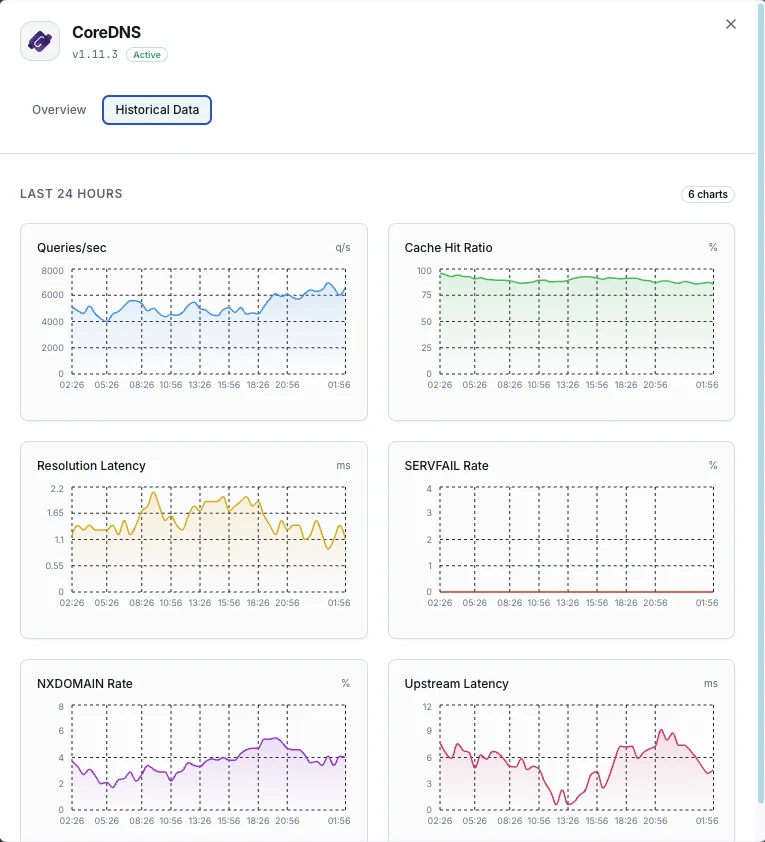
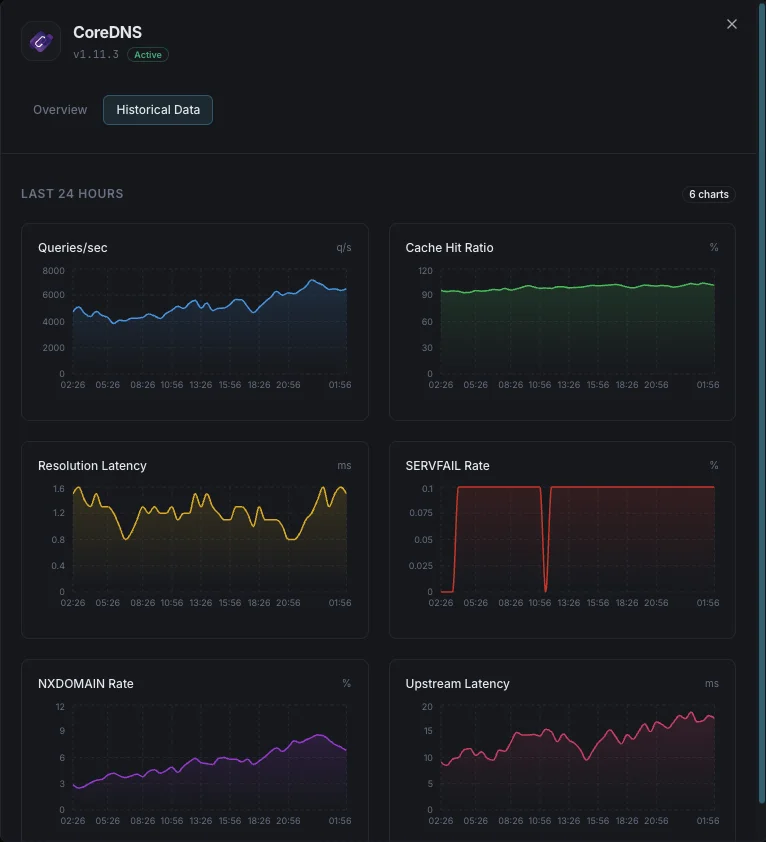
クエリ/秒
DNSクエリレート。
キャッシュヒット率
キャッシュから提供されたクエリの割合。
解決レイテンシ
DNS解決の平均時間。
SERVFAIL率
解決失敗の割合。
NXDOMAIN率
存在しないドメインへのクエリレート。
アップストリームレイテンシ
転送クエリの応答時間。
Forward プラグインレイテンシー
アップストリームリゾルバーごとの `coredns_forward_request_duration_seconds`。CoreDNS 内部のレイテンシーとアップストリームリゾルバーのレイテンシーを分離します — 遅い 8.8.8.8 か遅い CoreDNS そのものかを診断する上で不可欠です。
Forward リクエストレート
アップストリームごとの `coredns_forward_request_count_total`。キャッシュヒット比と組み合わせることで、アップストリーム解決のために実際にどれだけのトラフィックが CoreDNS を離れているかを示します。
プロキシ接続キャッシュ
`coredns_proxy_conn_cache_hits_total` / `_misses_total`。アップストリームリゾルバーへの TCP 接続再利用を追跡します — ヒット率が低いと接続のチャーンを意味し、アップストリームレイテンシーが上昇します。
Health プラグインの失敗
`coredns_health_request_failures_total` — `health:8080` プラグイン自身の失敗数。ゼロでない場合は liveness プローブが断続的に失敗していることを意味します。
パニック
`coredns_panics_total` — ゼロでない値はすべて、ゴルーチンパニックを引き起こした CoreDNS のバグまたはプラグインクラッシュです。完全なポストモーテムコンテキストのため、再起動カウントと組み合わせてください。
Go ランタイム
`process_resident_memory_bytes`(RSS)、`go_goroutines`(ゴルーチン数 — リーク検知)、`go_gc_duration_seconds`(GC ポーズ時間)。再起動なしのメモリ増加 = リーク;ゴルーチン数の増加 = ブロックされたプラグインまたはアップストリーム。
設定可能 アラートのトリガー
ダッシュボードでカスタムトリガーを設定し、CoreDNSのメトリクスが定義した閾値を超えた瞬間に通知を受け取れるようにします。
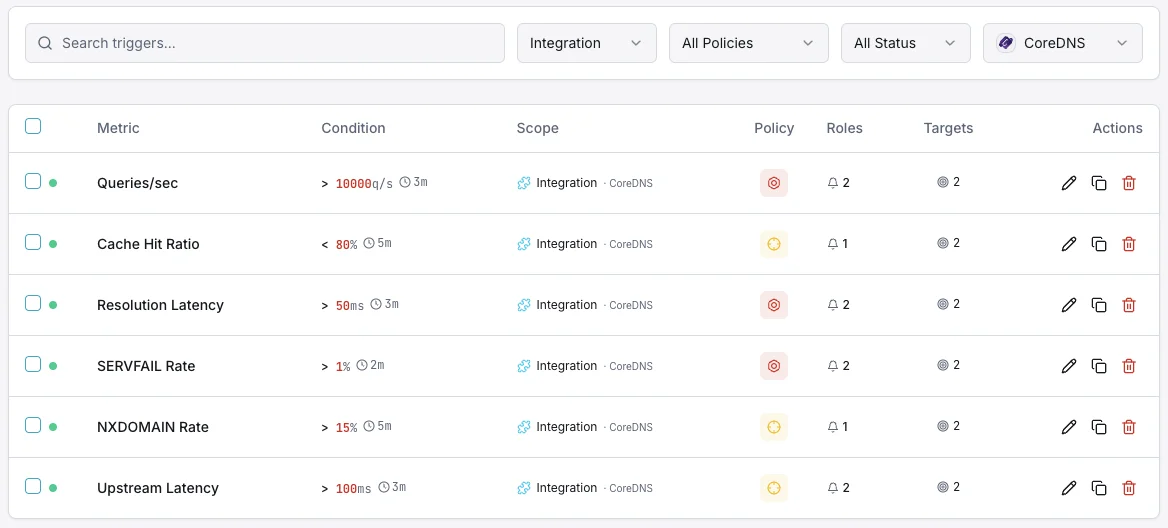
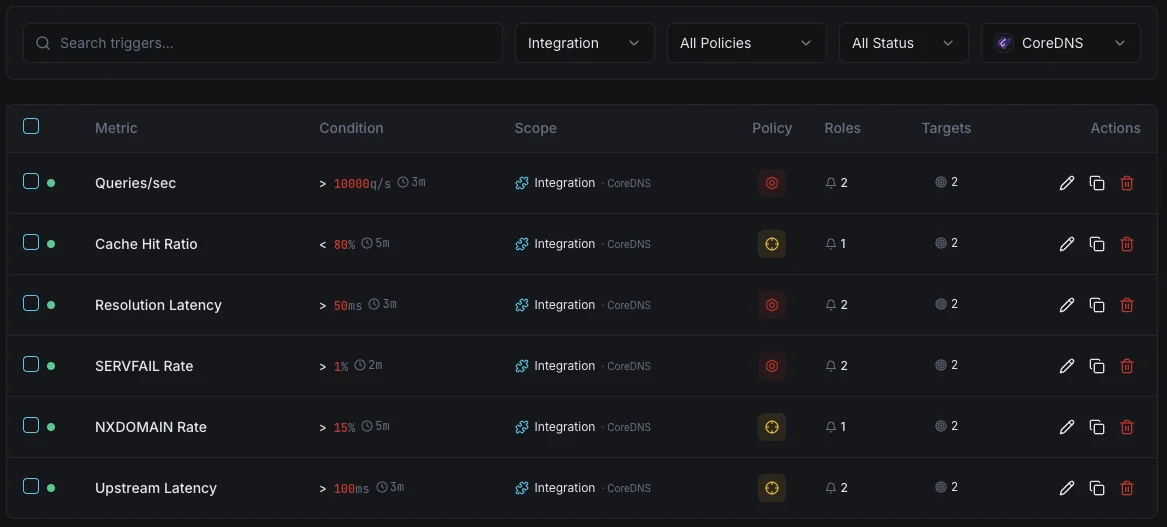
SERVFAIL率
重要な解決失敗率が高いときに発動。
キャッシュヒット率
警告キャッシュ効率が低下したときにアラート。
解決レイテンシ
警告DNS解決が遅いときに発動。
クエリレート
警告異常なクエリ量で発動。
の重要性: CoreDNS監視
DNSはネットワーク接続の基盤です。DNS解決の遅延や失敗はインフラ内のすべてのサービスに影響します。
- 高速なDNS解決を確保
- SERVFAILの急増を即座に検出
- 最適なパフォーマンスのためにキャッシュを監視
- アップストリームリゾルバの健全性を追跡
なぜ選ぶべきか: Xitoring
ゼロコンフィグのCoreDNS監視。
- ワンコマンドインストール
- グローバルノード
- 統合ダッシュボード
- マルチチャネルアラート
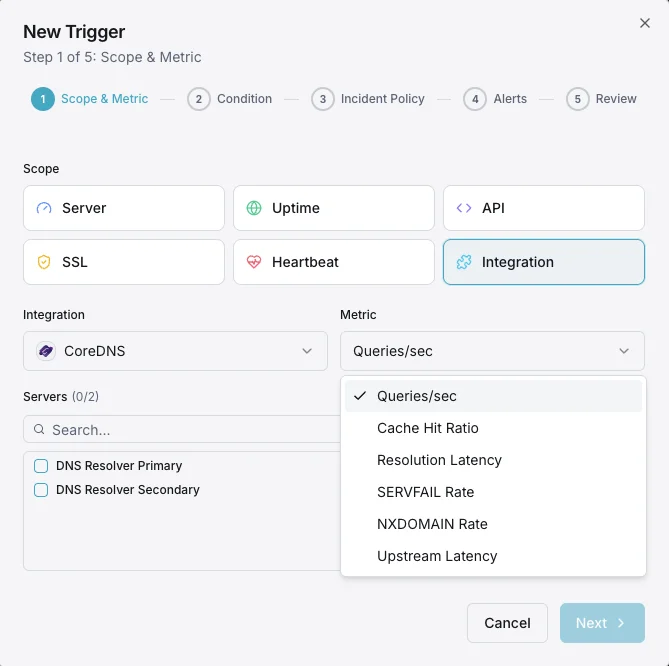
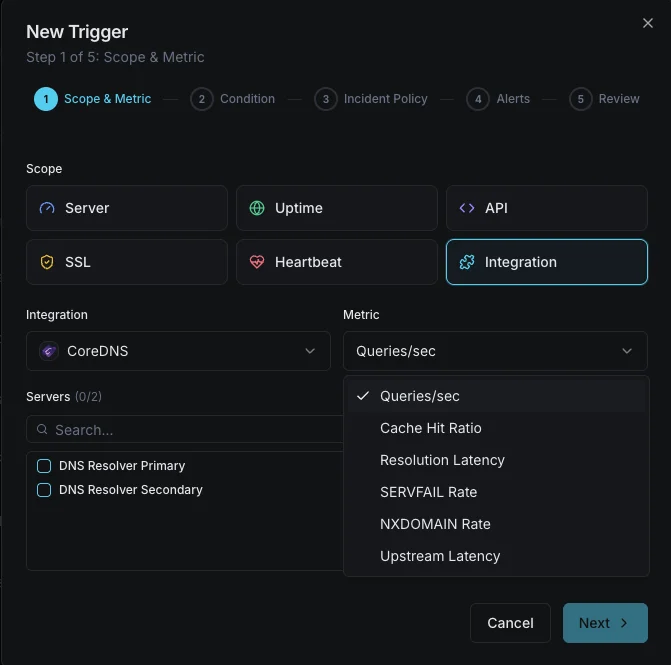
一般的な CoreDNS 監視の シナリオ
CoreDNSが今日一般的に稼働している場所 — そして誰も監視していない場合に何が問題になる可能性があるか。
Kubernetesアプリ内のDNS
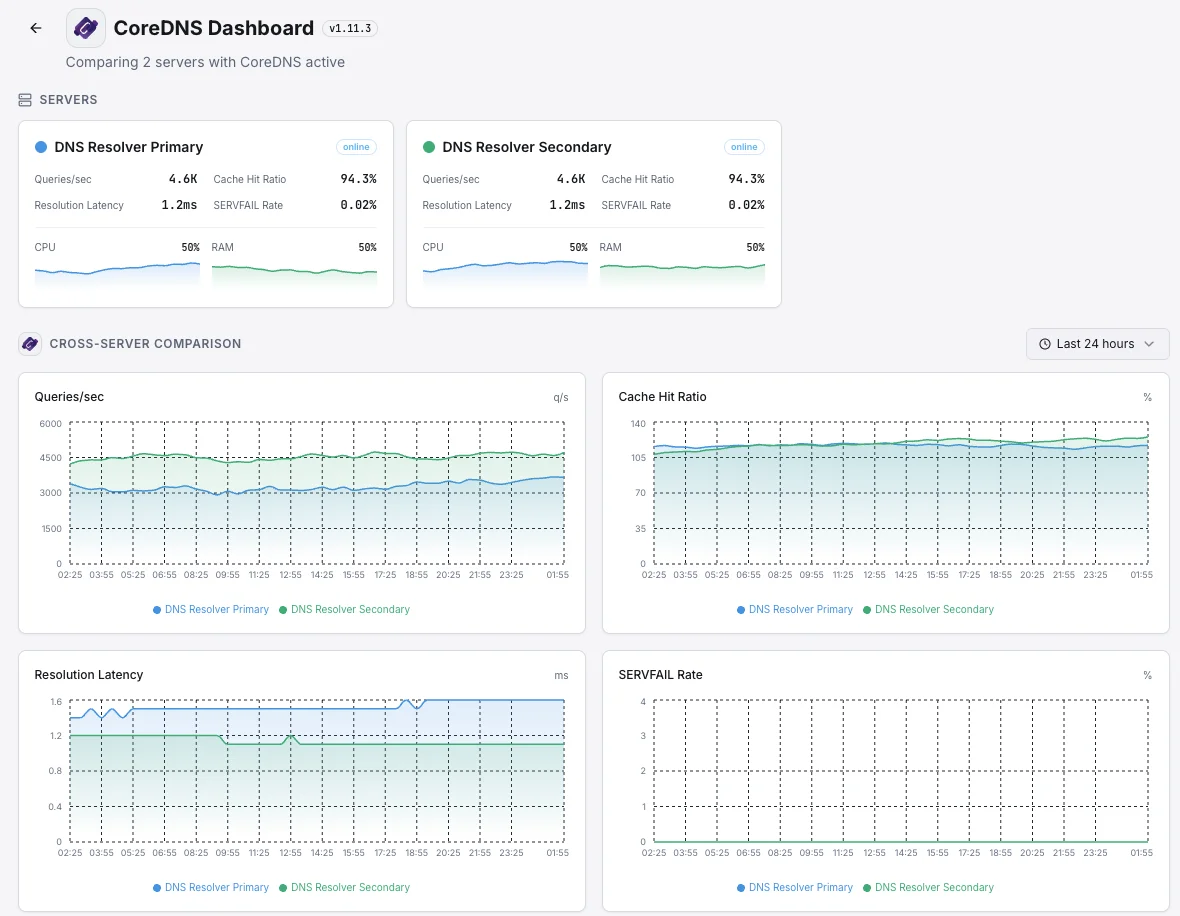
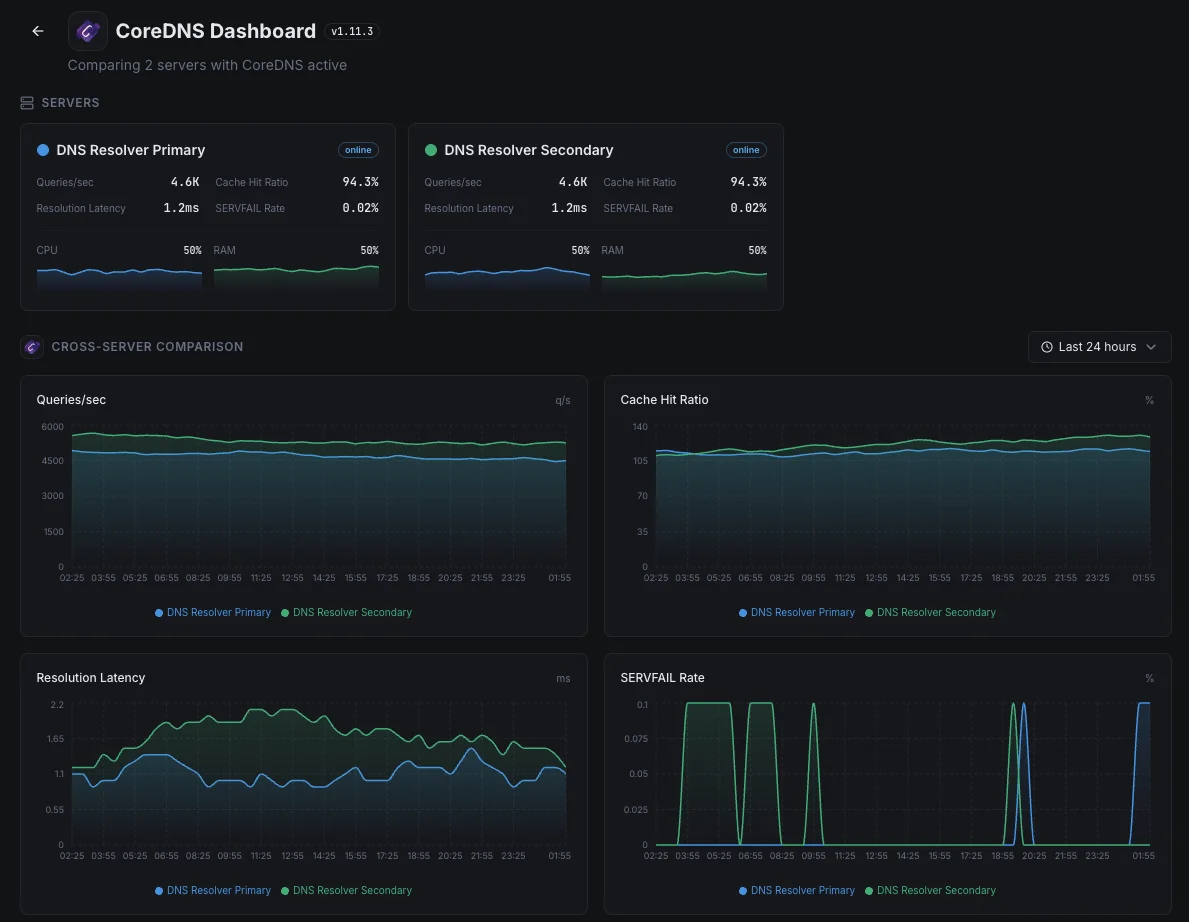
Kubernetesアプリのすべての部分は、CoreDNSを使用して他のすべての部分を見つけます。CoreDNSが遅くなったり、障害が発生し始めると、ユーザーはアプリ全体で奇妙な断続的なエラーを目にします。私たちは速度低下が始まった瞬間にそれを捉え、小さなDNSの不具合が顧客に謎の停止として現れないようにします。
ローカルDNSキャッシュを持つ大規模クラスター
大規模なKubernetes環境では、高速化のために各サーバーに小さなDNSキャッシュを配置します。これらのキャッシュの1つが異常な動作をすると、トラフィックの一部だけが中断され、発見が困難になります。私たちはそれぞれのキャッシュが適切に機能していることを確認し、単一の不良ノードがユーザーの一部を静かに劣化させないようにします。
ドメインの公開DNS
CoreDNSがオープンインターネット上であなたのドメインのDNSクエリに応答している場合、停止は人々があなたのサイトに全くアクセスできないことを意味します。私たちはサービスが健全で応答していることを証明する信号を監視し、DNSが静かに失敗している間にブランドと収益が静かに失われることがないようにします。
CoreDNS の 前提条件
これらが揃っていることを確認してください — 揃っていれば、ほとんどの導入は 60 秒で完了します。
- CoreDNS 1.x がサーバー上で稼働していること
- Corefile で Prometheus プラグインが有効化されていること(デフォルトポート 9153)
- Xitogent からメトリクスエンドポイントへのネットワーク到達性
はじめに 議事録
Xitogent をサーバーにインストール
まだの場合は、CoreDNS が稼働しているホストに軽量な Xitogent 監視エージェントをインストールしてください。
curl -s https://xitoring.com/install.sh | sudo bash -s -- --key=YOUR_API_KEYCoreDNS で prometheus プラグインを有効化
CoreDNS は prometheus プラグインを通じて Prometheus 形式のメトリクスを公開します(デフォルトエンドポイント :9153/metrics)。Corefile に `prometheus :9153` を追加して CoreDNS を再読み込みし、メトリクスエンドポイントがエージェントホストから到達可能であることを確認してください。
sudo xitogent integrateCoreDNS 連携を有効化
Xitoring ダッシュボードまたは CLI から CoreDNS 連携を有効化してください。Xitogent がメトリクスエンドポイントを自動検出し、クエリ、キャッシュ、レイテンシのメトリクス収集を開始します。
アラートしきい値を設定(オプション)
SERVFAIL レート、キャッシュヒット率、解決レイテンシなどにカスタムしきい値を設定し、DNS の信頼性や性能が低下した瞬間に通知を受け取れるようにします。
動作確認
サーバー上でこのコマンドを実行して、Xitogent が連携を認識していることを確認してください。約 30 秒以内に新しいメトリクスがダッシュボードに流れ始めます。
sudo xitogent status代替ツールを 検討中ですか?
CoreDNS 監視の代替ツールと比べて Xitoring がどう優れているかをご覧ください — 定額料金、より深い統合、そしてスタック全体をカバーする 1 つのエージェント。


