Disk Health 監視
SSDおよびHDDのSMART属性、温度、再割り当てセクタ、および予兆故障指標をリアルタイムで監視します。
なぜ監視するのか Disk Health?
ディスクの故障は、データ損失や予期せぬダウンタイムの主な原因の一つです。Xitoringのディスクヘルス監視機能は、SMART(自己監視・分析・報告技術)を活用し、ドライブが故障する前に早期警告を発します。この機能は、LinuxおよびWindows環境におけるSSD、HDD、RAID構成を幅広くカバーしています。
ディスクヘルス監視を 解説
ディスクヘルス監視は、再割り当てセクタの増加、NVMe の摩耗、温度の急上昇、差し迫った障害の指標を、ドライブが死ぬ数日から数週間前に検出します — データを移行してダウンタイムなしでドライブを交換するのに十分な時間です。データベースサーバー、バックアップホスト、ドライブ障害がデータ損失を意味するあらゆるワークロードにおいて、SMART 監視は設定できる単一の最高 ROI アラートです。Xitoring はローカルで smartctl + nvme-cli を実行し、Slack、PagerDuty、Telegram、既存のオンコールへアラートを配信します。
私たちが 監視するもの
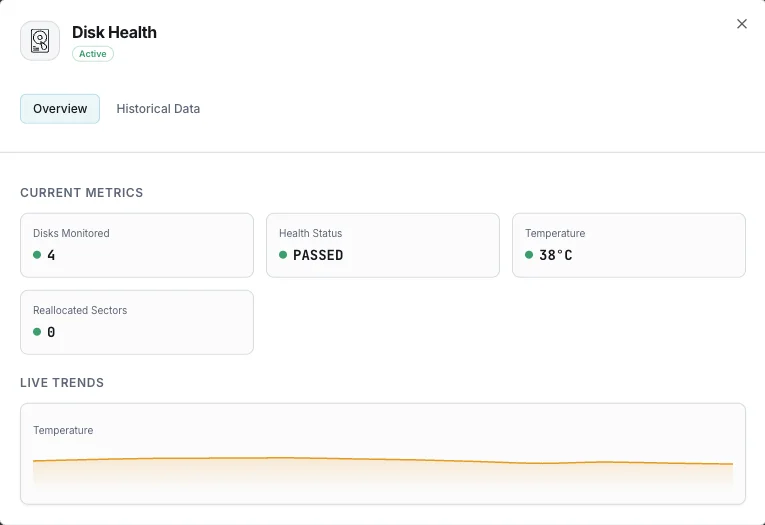
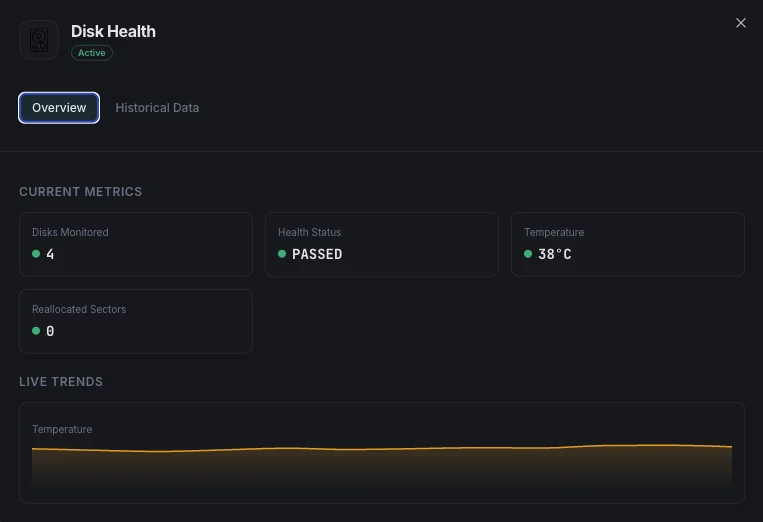
SMARTヘルスステータス
ディスクの総合健全性インジケーター(合格/不合格)。
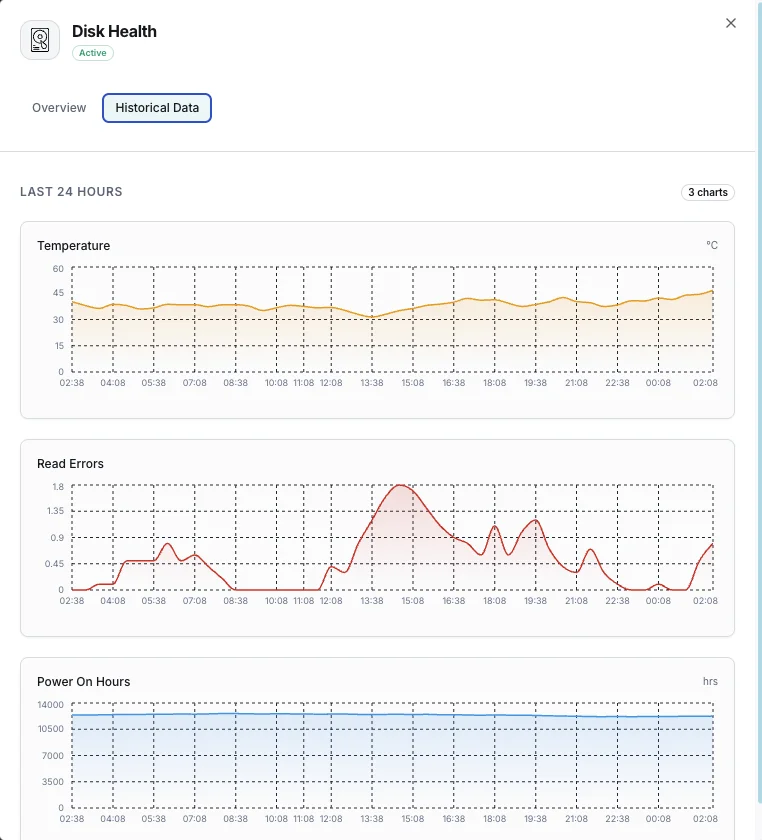
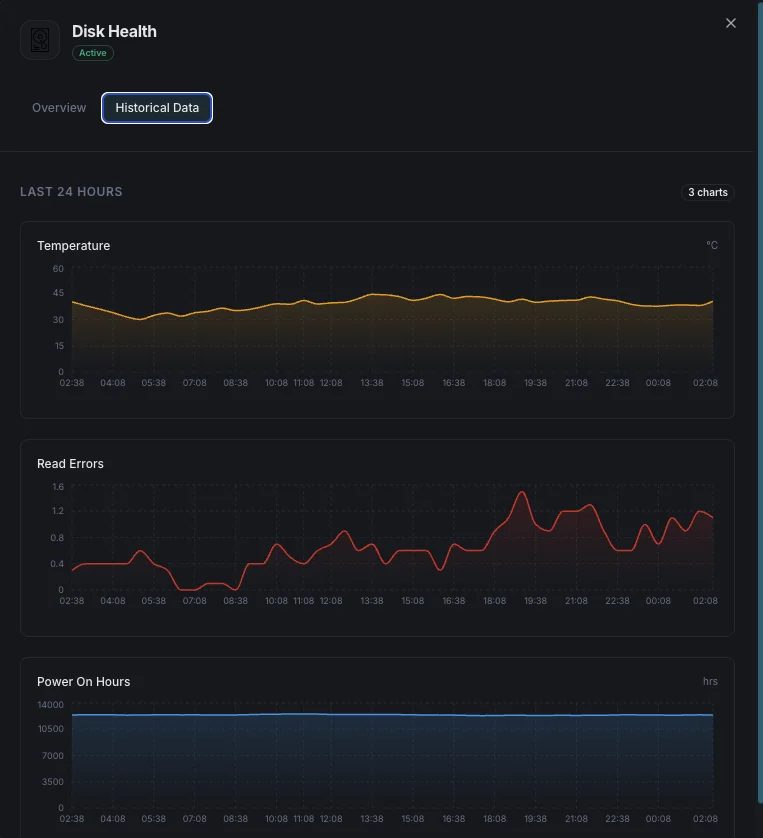
温度
現在のディスク温度(摂氏)。
再割り当てセクタ
再マッピングされた不良セクタ数。
電源投入時間
ディスクの総稼働時間。
読み取りエラー率
発生した読み取りエラーの割合。
保留中のセクタ
再マッピング待ちのセクタ。
Temperature_Celsius(SMART 194)
現在のドライブ温度。HDD は 50°C を超えると劣化します。コンシューマー SSD は 70°C を超えるとスロットリングします。早期警告のため、ベンダー定格最大値から 10°C 引いた値でアラートを設定してください。
UDMA_CRC_Error_Count(SMART 199)
SATA/SAS インターフェース上のケーブル関連 CRC エラー。値の上昇は不良ケーブルまたは緩んだ接続をフラグします — ドライブ障害と誤診されがちな簡単な修正です。
SSD 摩耗(Wear_Leveling_Count + Total_LBAs_Written)
SSD 耐久性の追跡。`Wear_Leveling_Count` は正規化された残存寿命。`Total_LBAs_Written` とドライブの定格 TBW から現在の摩耗率を算出します。80% 使用時にアラートを設定してください。
NVMe percentage_used
`nvme smart-log` から — ベンダーの寿命消費見積もり(0–100%、摩耗したドライブでは 100% を超える場合あり)。80% 超で警告、95% 超で重大。
NVMe available_spare
不良ブロック置換用の残りスペア容量の割合。10% 未満で警告、5% 未満で重大(`available_spare_threshold` は通常そこに設定されます)。
NVMe critical_warning
`nvme smart-log` からのビットフィールド。しきい値未満のスペア、しきい値超の温度、デバイス信頼性の劣化、読み取り専用モード、揮発性メモリバックアップ失敗をフラグします。ゼロでない値はすべて即時アラートです。
設定可能 アラートのトリガー
ダッシュボードでカスタムトリガーを設定し、Disk Healthのメトリクスが定義した閾値を超えた瞬間に通知を受け取れるようにします。
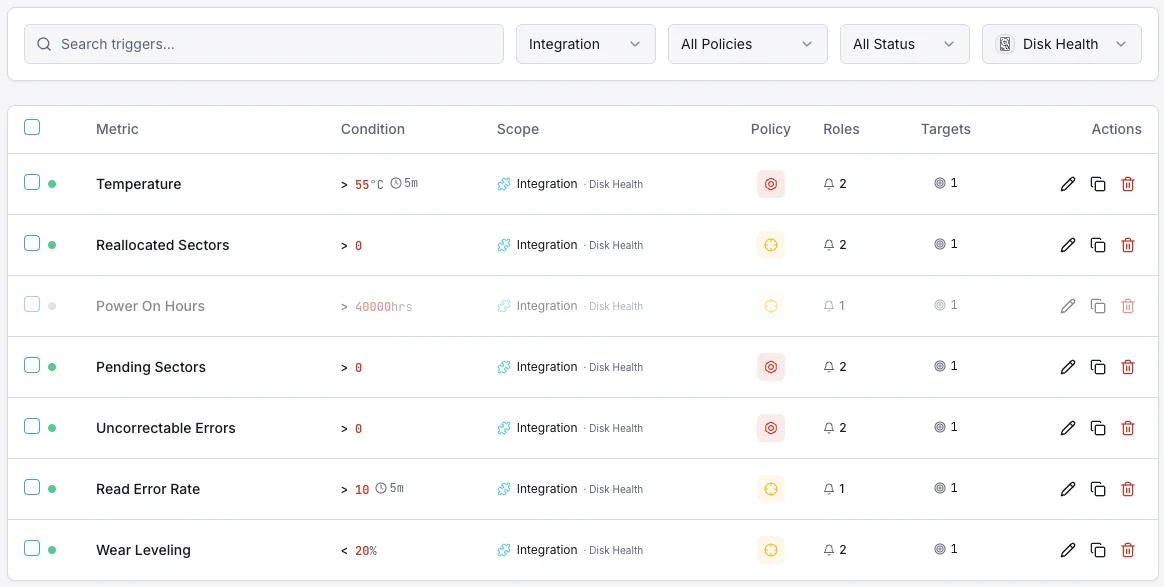
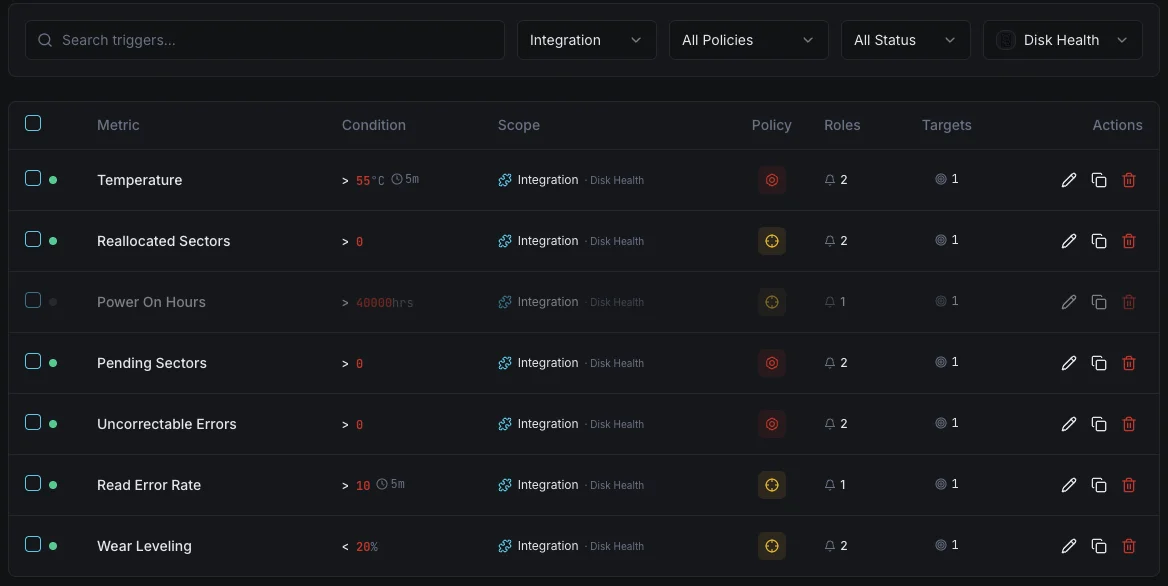
SMARTヘルスステータス
重要なSMARTが健全性失敗を報告したときに発動。
再割り当てセクタ
重要な再割り当てセクタ数が閾値を超えたときにアラート。
ディスク温度
警告ディスク温度が安全動作範囲を超えたときに発動。
保留中のセクタ
警告保留中のセクタ数が潜在的な障害を示すときに発動。
の重要性: ディスクヘルス監視
ディスク障害はデータ損失と高額なダウンタイムを引き起こします。SMART監視は、温度上昇、再割り当てセクタの増加、読み取りエラーの急増などの早期警告を提供し、ドライブが故障する前に対処できるようにします。
- 早期障害検出でデータ損失を防止
- ボトルネックを特定してパフォーマンスを最適化
- 履歴トレンド分析によるキャパシティ計画
- データ整合性監視でコンプライアンスを維持
なぜ選ぶべきか: Xitoring
Xitoringは、すべてのディスクタイプに対するSMART統合付きのゼロコンフィグディスクヘルス監視を提供します。リアルタイムアラート、履歴トレンド、予測障害インジケーターを統合ダッシュボードで取得できます。
- SSD、HDD、RAIDアレイをサポート
- LinuxとWindowsでワンコマンドセットアップ
- カスタマイズ可能なSMART属性の閾値
- 重要ディスクイベントのマルチチャネルアラート
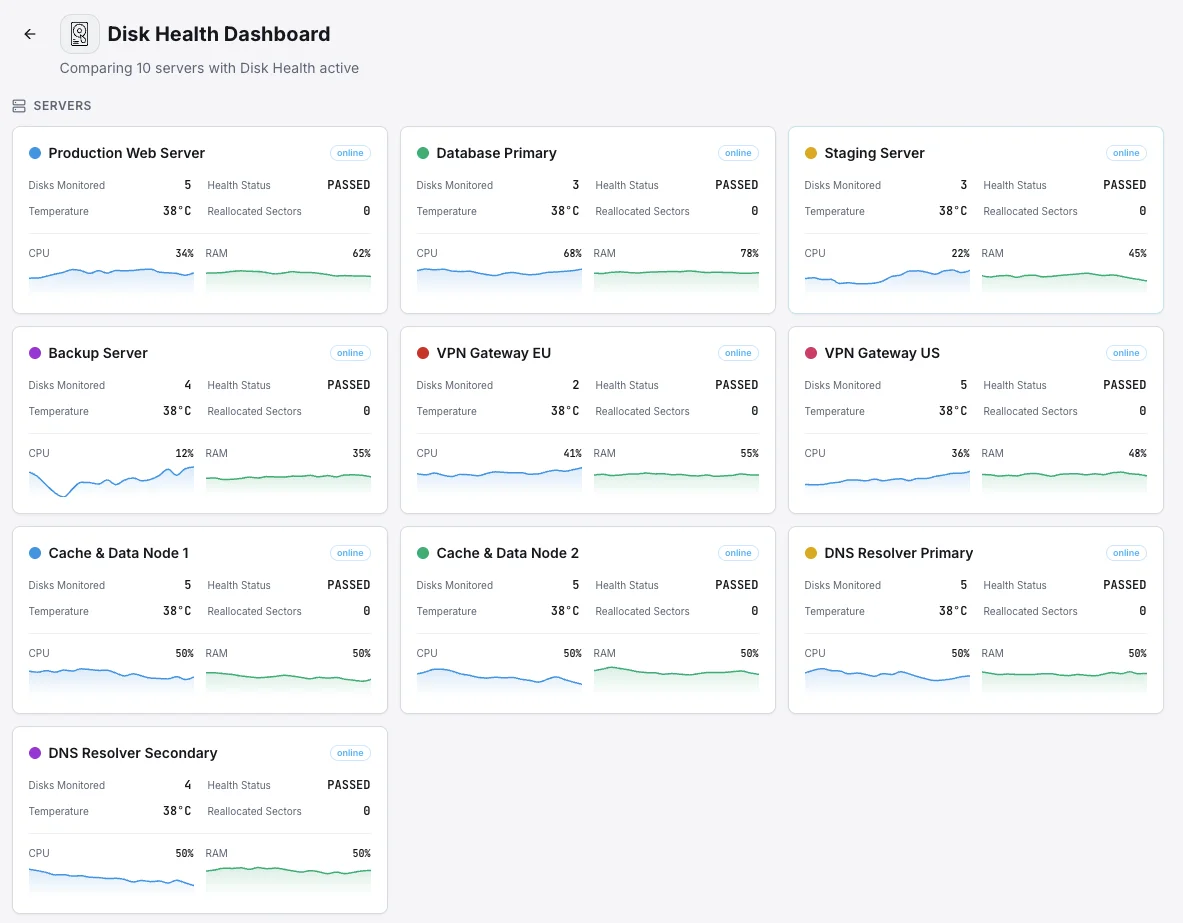
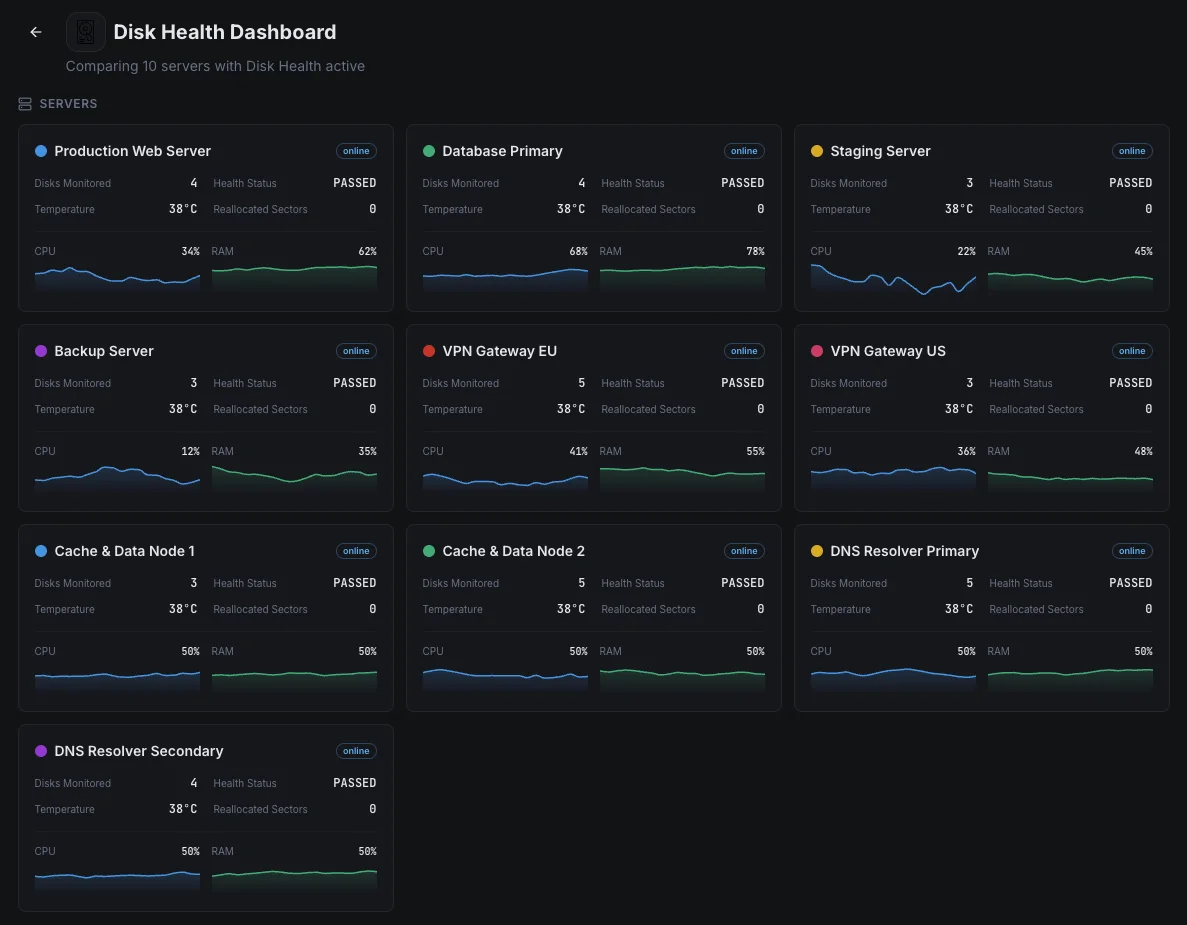
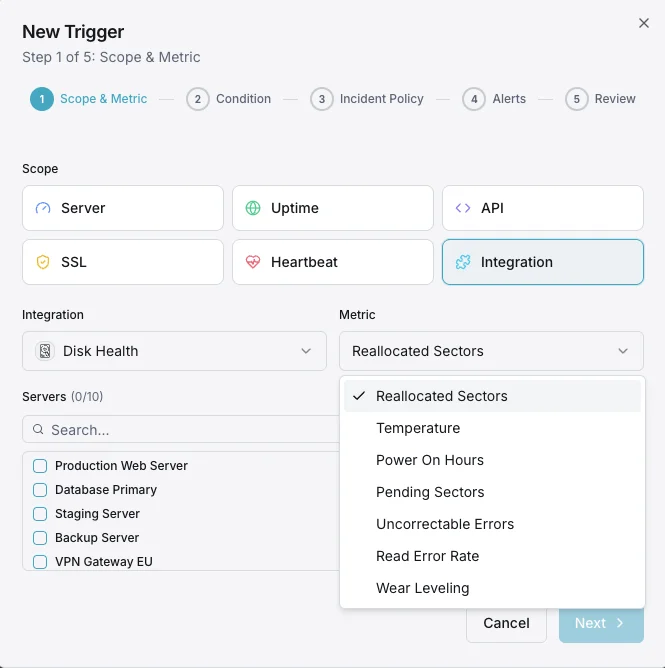
一般的なディスクヘルス監視の シナリオ
ディスク監視が実際に損害を引き起こす前にドライブ障害を最も頻繁に検出する場所。
データベースサーバー
データベース内のドライブ障害は、ダウンタイム、注文の損失、最悪の場合、データ破損を意味する可能性があります。私たちはすべてのドライブの初期の障害兆候を監視し、チームが午前3時の停止中にではなく、自分たちのスケジュールで問題のあるディスクを交換できるようにします。
バックアップおよびアーカイブサーバー
バックアップドライブの特有の問題は、実際にバックアップが必要になる日まで障害が目に見えないままであり、その時には手遅れになっていることです。私たちは各ドライブを定期的にテストし、早期に摩耗を表面化させることで、存在しないバックアップに手を伸ばすことがないようにします。
大量のデータを書き込むサーバー(SSD)
SSDは摩耗するまでに書き込み回数に制限があり、ビジーなデータベースやデータ量の多いアプリは、ほとんどのチームが認識しているよりも速くそれらを使い果たします。私たちは摩耗を明確なパーセンテージで追跡し、突然の回復不能な障害の後ではなく、ドライブが時間通りに交換されるようにします。
Disk Health の 前提条件
これらが揃っていることを確認してください — 揃っていれば、ほとんどの導入は 60 秒で完了します。
- Linux サーバー(Debian/Ubuntu、RHEL/CentOS、または互換ディストリビューション)
- smartmontools パッケージがインストール済み(smartctl)かつ lsblk が利用可能であること
- sudo / root アクセス — SMART データには昇格された権限が必要です
はじめに 議事録
前提パッケージをインストール(Linux)
smartmontools をインストールして SMART データ収集を有効化します。lsblk がシステム上で利用可能であることを確認してください。
# Ubuntu/Debian
sudo apt-get install smartmontools
# CentOS/RHEL
sudo yum install smartmontoolsDisk Health 連携を有効化
integrate コマンドを実行して Disk Health を選択します。Xitogent がディスクを自動検出し、SMART データの収集を開始します。Windows では前提条件は不要です。
xitogent integrate動作確認
サーバー上でこのコマンドを実行して、Xitogent が連携を認識していることを確認してください。約 30 秒以内に新しいメトリクスがダッシュボードに流れ始めます。
sudo xitogent status代替ツールを 検討中ですか?
Disk Health 監視の代替ツールと比べて Xitoring がどう優れているかをご覧ください — 定額料金、より深い統合、そしてスタック全体をカバーする 1 つのエージェント。


