InfluxDB Suivi
Surveillez en temps réel le débit d'écriture d'InfluxDB, les performances des requêtes, les indicateurs du moteur de stockage et l'état des politiques de conservation, sans aucune configuration.
Pourquoi surveiller ? InfluxDB?
InfluxDB est la principale base de données de séries chronologiques dédiée aux métriques, aux événements et à l'analyse en temps réel. La surveillance d'InfluxDB garantit une ingestion des données en écriture sans faille, des performances de requête optimales et une gestion adéquate de la conservation des données.
Le monitoring InfluxDB, expliqué
Le monitoring InfluxDB détecte les blocages de débit en écriture, l'explosion de cardinalité des séries (le mode de défaillance classique d'InfluxDB 1.x/2.x), l'accumulation de compactions TSM, les ralentissements de requêtes et la croissance du WAL avant qu'ils ne provoquent une perte d'ingestion ou des timeouts de requêtes sur vos dashboards Grafana. Pour les pipelines de capteurs IoT, les backends de métriques applicatives et tout déploiement TICK-stack, la visibilité par base de données fait la différence entre une alerte à 60 secondes et un incident multi-heures à chercher des points de données manquants. Xitoring découvre automatiquement votre InfluxDB, lit l'endpoint Prometheus natif /metrics et achemine les alertes vers Slack, PagerDuty, Telegram ou votre astreinte existante.
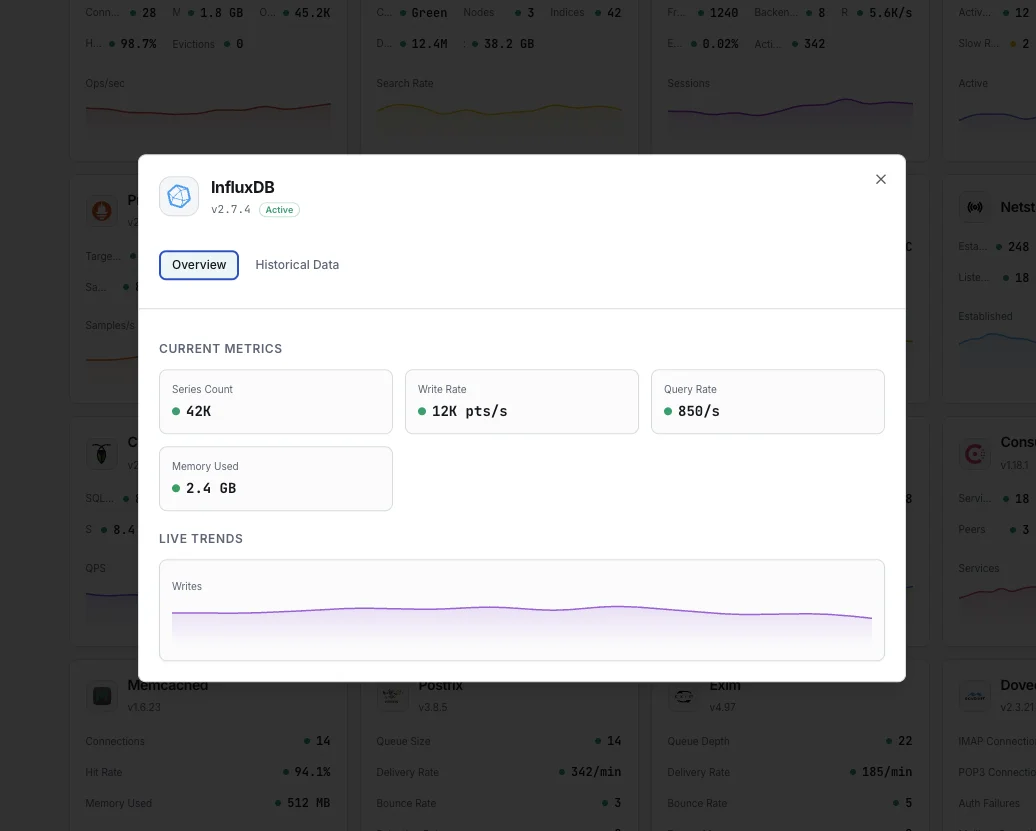
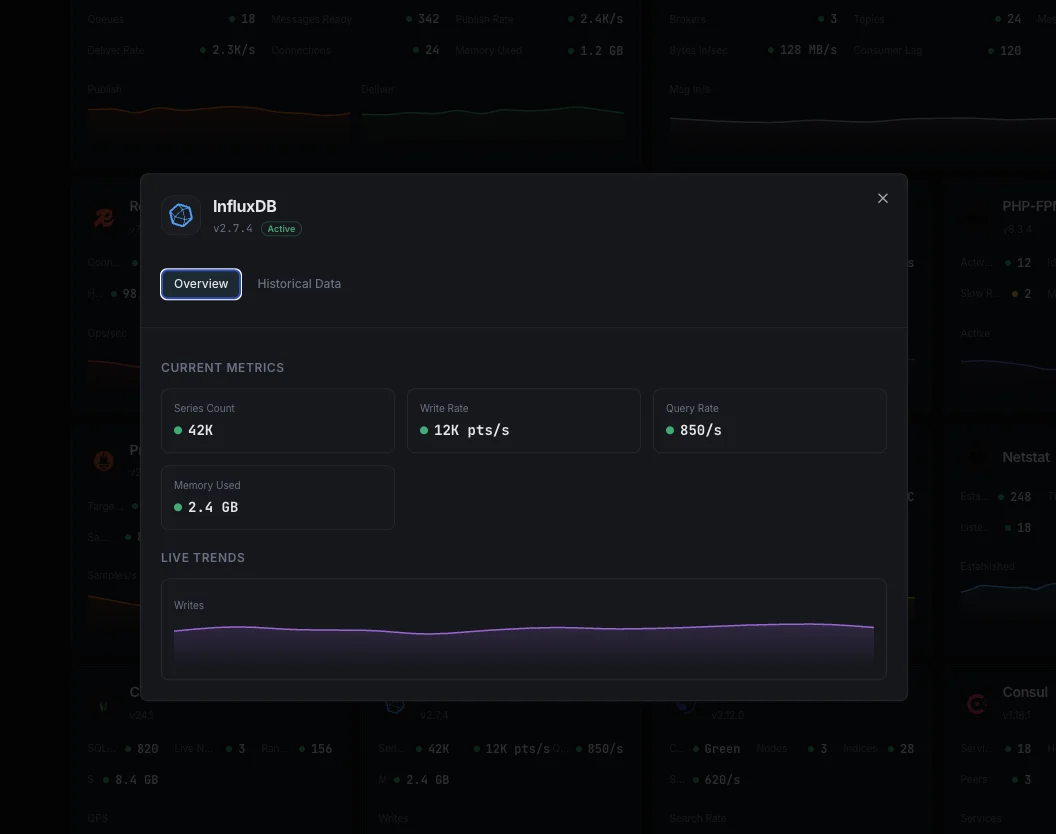
Ce que nous surveillons
Points écrits/sec
Taux d'écriture des points de données.
Durée des requêtes
Temps moyen d'exécution des requêtes.
Cardinalité des séries
Total des séries temporelles uniques.
Taille du stockage
Stockage TSM sur disque.
Taux de compaction
Débit de compaction TSM.
Taille du cache
Utilisation du cache d'écriture en mémoire.
Octets disque du WAL
`storage.tsm1.wal.currentSegmentDiskBytes` + `oldSegmentsDiskBytes`. La croissance du WAL sans consolidation TSM signifie que le temps de récupération explosera au redémarrage.
Taille de stockage sur disque
`storage.tsm1.filestore.diskBytes` + numFiles par shard. À suivre par rapport à votre politique de rétention — des nombres élevés de fichiers à taille de données identique signalent la fragmentation.
Taux HTTP 4xx / 5xx
`httpd.clientError` + `httpd.serverError` (ou `http_api_request_errors_total` côté Prometheus). Les pics de 4xx signalent des bugs de schéma/auth côté client ; les 5xx signalent des défaillances côté serveur.
Connexions / Échecs d'authentification
`httpd.req` (total des requêtes HTTP), `httpd.authFail` (tentatives d'auth échouées), `httpd.pingReq`. Les pics d'échecs d'auth signalent un Telegraf mal configuré ou une rotation d'identifiants ratée.
Runtime — Goroutines & GC
Statistiques runtime Go : `runtime.NumGoroutine` (détection de fuites de goroutines), `runtime.HeapAlloc` (heap vivant), `runtime.NumGC`/`PauseTotalNs` (pression GC). Détectez les fuites et les régressions de temps de pause avant l'OOM.
Écritures d'abonnement
`subscriber.pointsWritten` et `subscriber.writeFailures` — lorsque Kapacitor ou les pipelines en aval consomment via des abonnements, c'est ainsi que vous détectez leur backpressure.
Configurables déclencheurs d'alerte
Configurez des déclencheurs personnalisés dans votre tableau de bord pour être averti dès que les indicateurs d{name}s dépassent les seuils que vous avez définis.
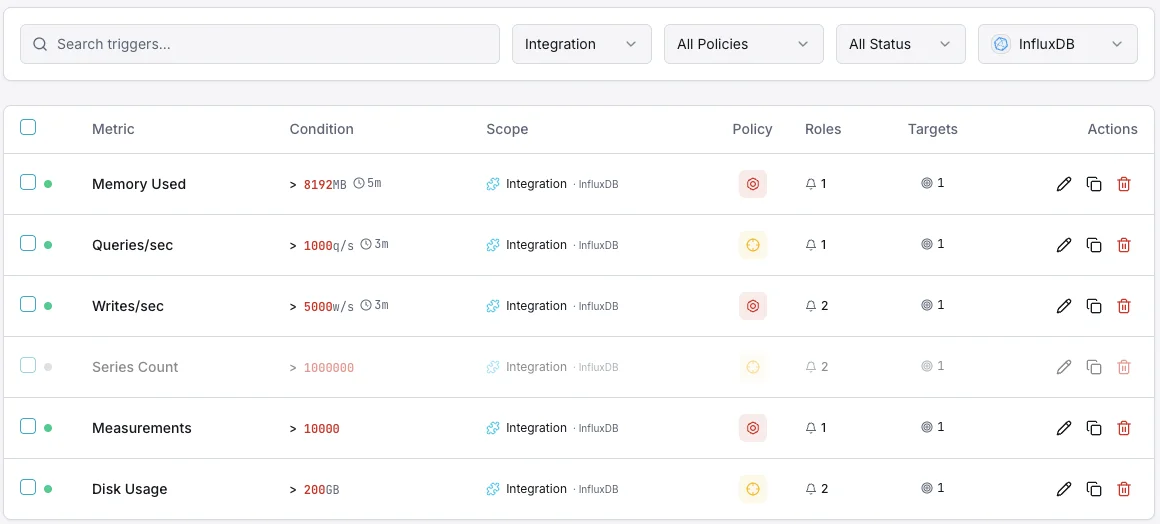
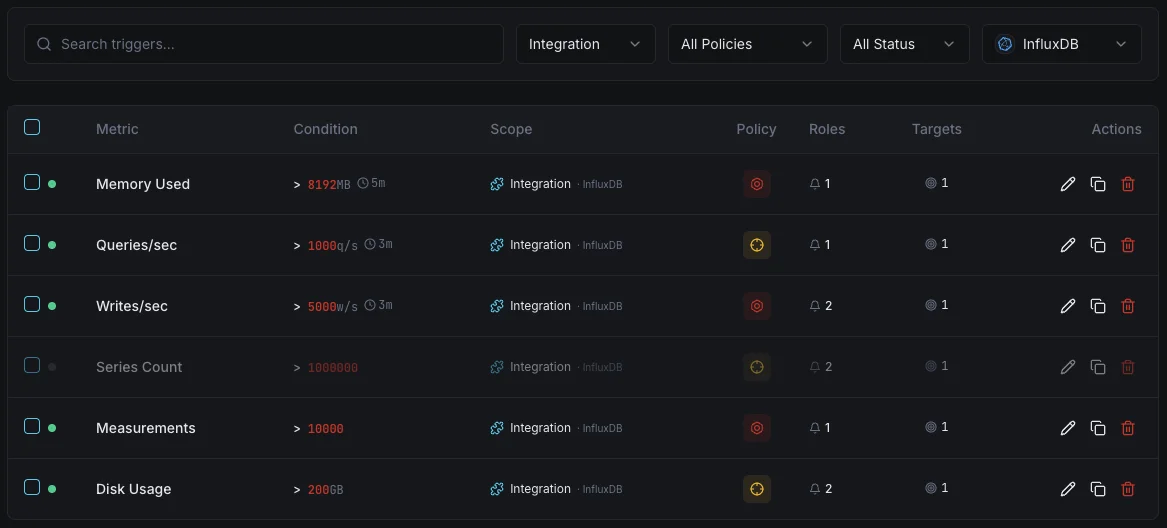
Débit d'écriture
avertissementSe déclenche sur des anomalies du taux d'écriture.
Durée des requêtes
avertissementAlerte sur les requêtes lentes.
Cardinalité des séries
crucialSe déclenche lorsque la cardinalité est trop élevée.
Taille du stockage
crucialSe déclenche lorsque le stockage dépasse le seuil.
Importance de la surveillance InfluxDB
InfluxDB gère des données de séries temporelles à haute vélocité. Une cardinalité élevée, la pression d'écriture et les retards de compaction peuvent dégrader les performances.
- Suivez le débit d'écriture pour la santé d'ingestion
- Surveillez la cardinalité des séries pour prévenir les OOM
- Détectez tôt les requêtes lentes
- Assurez-vous que la compaction suit le rythme
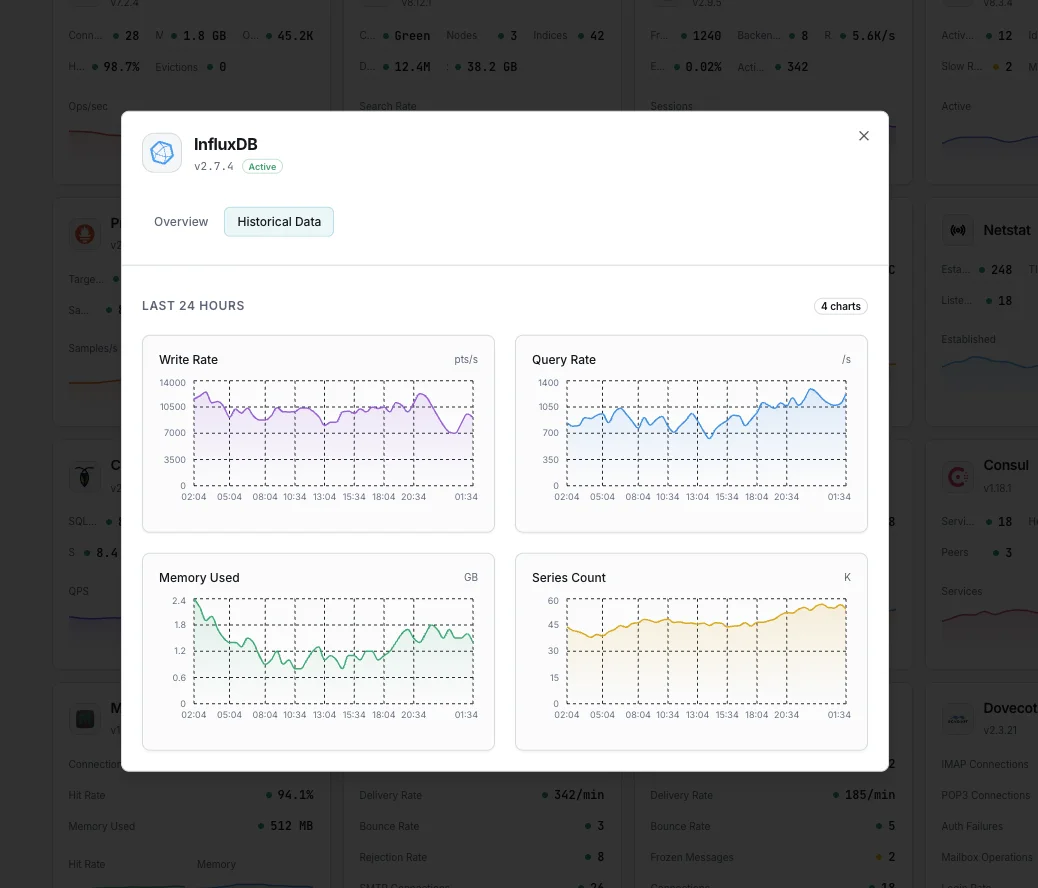
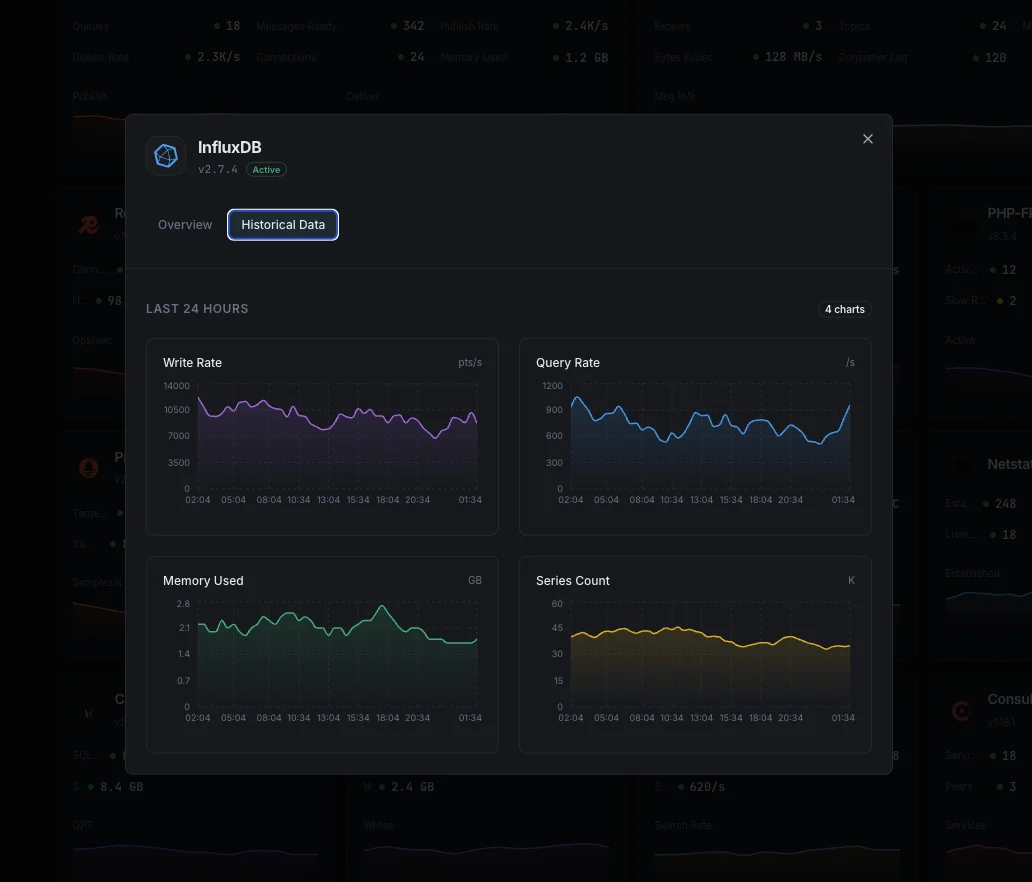
Pourquoi choisir Xitoring
Surveillance InfluxDB sans configuration.
- Installation en une commande
- Nœuds mondiaux
- Tableau de bord unifié
- Alertes multicanaux
- Conservation historique
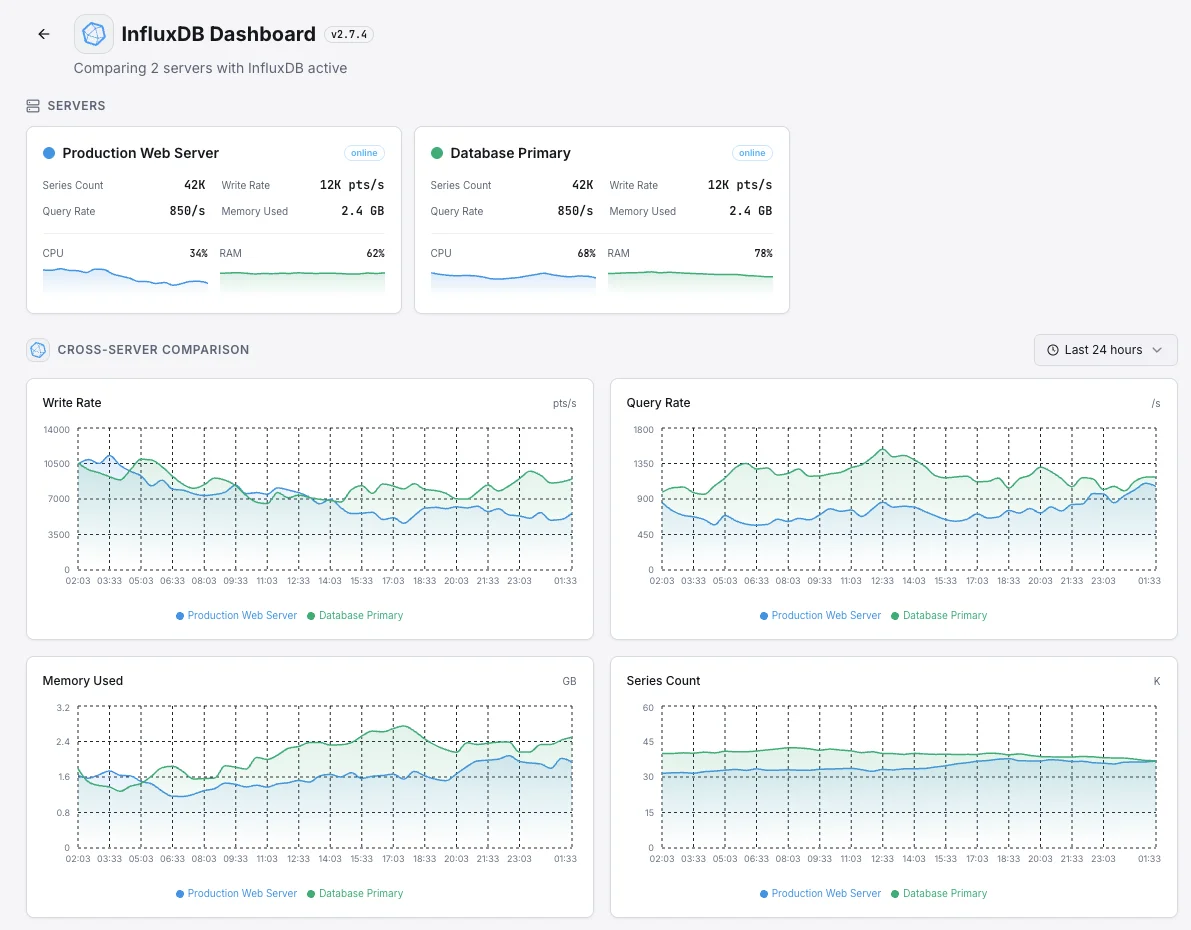
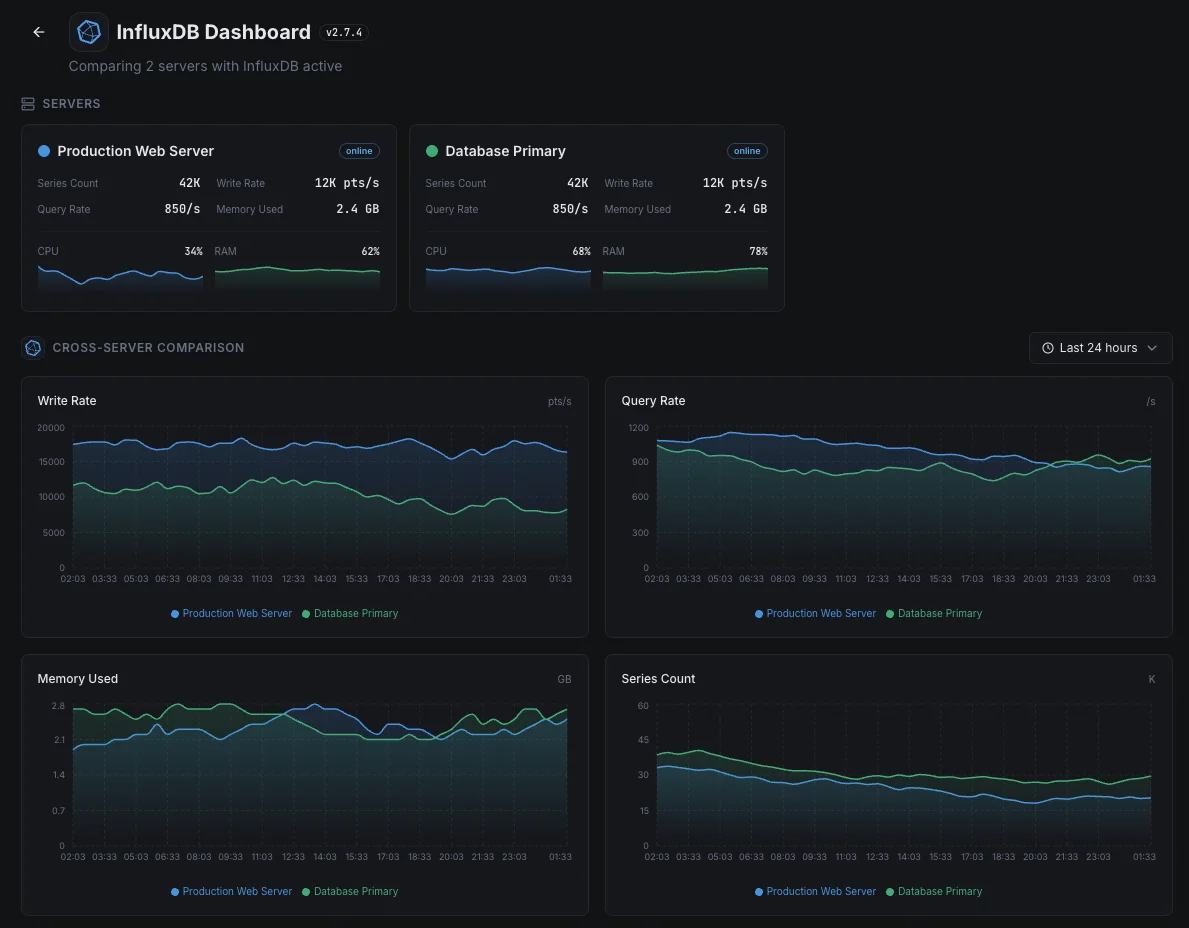
Scénarios courants de monitoring InfluxDB
Où InfluxDB fonctionne généralement aujourd'hui — et ce qui pourrait mal tourner si personne ne surveille.
La base de données derrière les tableaux de bord de votre équipe
Lorsque les tableaux de bord dans Grafana ou un autre outil semblent lents, la cause est souvent la base de données sous-jacente — et non le tableau de bord lui-même. Nous mettons en évidence l'origine réelle de la lenteur afin que l'équipe corrige le bon élément au lieu de courir après le symptôme.
Données provenant de capteurs et d'appareils
Les appareils connectés, les équipements d'usine et les capteurs IoT envoient des mesures chaque seconde de chaque jour. Une sauvegarde silencieuse dans le pipeline signifie des données perdues — et les données perdues sont perdues à jamais. Nous surveillons le flux de bout en bout afin qu'une seule lecture manquée déclenche l'alarme.
Métriques d'application et d'infrastructure en un seul endroit
Lorsque la même base de données contient à la fois les métriques d'application et les métriques de serveur, un problème avec la base de données masque tous les signaux à la fois. Nous surveillons la base de données elle-même afin que la propre surveillance de l'équipe ne s'interrompe jamais pendant un incident.
Prérequis pour InfluxDB
Assurez-vous d'avoir tout cela en place — la plupart des installations sont une affaire de 60 secondes une fois ces conditions réunies.
- InfluxDB 1.x ou 2.x tournant sur le serveur
- Port HTTP InfluxDB accessible depuis Xitogent (par défaut 8086)
- Facultatif : un token en lecture seule si l'authentification InfluxDB 2.x est activée
Commencez par procès-verbal
Installer Xitogent sur votre hôte InfluxDB
Installez l'agent de monitoring léger Xitogent sur l'hôte qui exécute InfluxDB.
curl -s https://xitoring.com/install.sh | sudo bash -s -- --key=YOUR_API_KEYConfirmer qu'InfluxDB est accessible
Vérifiez qu'InfluxDB écoute sur son port HTTP (par défaut 8086) et est accessible depuis l'hôte qui exécute Xitogent. Xitogent demandera l'hôte et le port lors de l'integrate — aucune modification de configuration ou exposition d'endpoint supplémentaire n'est requise.
sudo xitogent integrateActiver l'intégration InfluxDB
Utilisez le tableau de bord Xitoring ou la CLI pour activer l'intégration InfluxDB. Xitogent détecte automatiquement votre version d'InfluxDB et commence à collecter les métriques d'écriture, de requête et de stockage.
Configurer les seuils d'alerte (facultatif)
Définissez des seuils personnalisés pour le débit d'écriture, la durée des requêtes ou la cardinalité des séries afin de détecter la pression d'ingestion et la croissance incontrôlée des tags avant que les requêtes ne ralentissent.
Vérifier que tout fonctionne
Exécutez cette commande sur le serveur pour confirmer que Xitogent a bien détecté l'intégration. De nouvelles métriques apparaîtront sur votre tableau de bord dans environ 30 secondes.
sudo xitogent statusVous envisagez des alternatives ?
Découvrez comment Xitoring se positionne face aux alternatives pour la surveillance de InfluxDB — tarifs forfaitaires, intégrations plus poussées et un seul agent pour couvrir tout votre stack.



Souvent a posé des questions
InfluxDB 1.x et 2.x ?
Conséquences ?
Comment détecter les problèmes de cardinalité InfluxDB ?
Qu'est-ce que la base _internal dans InfluxDB ?
Comment monitorer les compactions InfluxDB ?
Quelle est la différence entre le monitoring InfluxDB 1.x, 2.x et 3.0 ?
Comment détecter la lenteur des requêtes InfluxDB ?
Comment monitorer le stockage TSM d'InfluxDB ?
Cette intégration affectera-t-elle les performances d'InfluxDB ?
Commencer à surveiller InfluxDB aujourd'hui
Configuration en moins de 60 secondes. Aucune carte bancaire requise. Statistiques complètes dès le premier jour.
Commencer l'essai gratuitContinuez à explorer