Apache Kafka 監視
設定不要で、Apache Kafka ブローカーの健全性、パーティションの遅延、コンシューマーグループ、およびスループットをリアルタイムで監視します。
なぜ監視するのか Apache Kafka?
Apache Kafkaは、リアルタイムデータパイプラインおよびイベントストリーミングの中核をなすものです。Kafkaを監視することで、ブローカークラスタの健全性を確保し、コンシューマーの遅延を最小限に抑え、パーティションの最適な分散を実現し、メッセージの確実な配信を保証します。
Kafka 監視を 解説
Kafka 監視は、レプリケーション不足のパーティション、オフラインのパーティション、コンシューマーグループのラグ急増、ISR の縮小、コントローラ障害、ディスク圧迫を、データ損失、ダウンストリームのマイクロサービス障害、ブローカー全体の停止を引き起こす前に検出します。CDC パイプライン、イベントソーシングシステム、マイクロサービスイベンティング、あらゆる本番 Kafka クラスタにおいて、ブローカーごと + コンシューマーグループごとの可視性が、遅延しているコンシューマーへの 60 秒のアラートと、終業時に 5,000 万件のメッセージバックログを発見することの違いを生みます。Xitoring はブローカーを自動検出し、JMX MBean + コンシューマーオフセットを読み取り、Slack、PagerDuty、Telegram、または既存のオンコールにアラートをルーティングします。
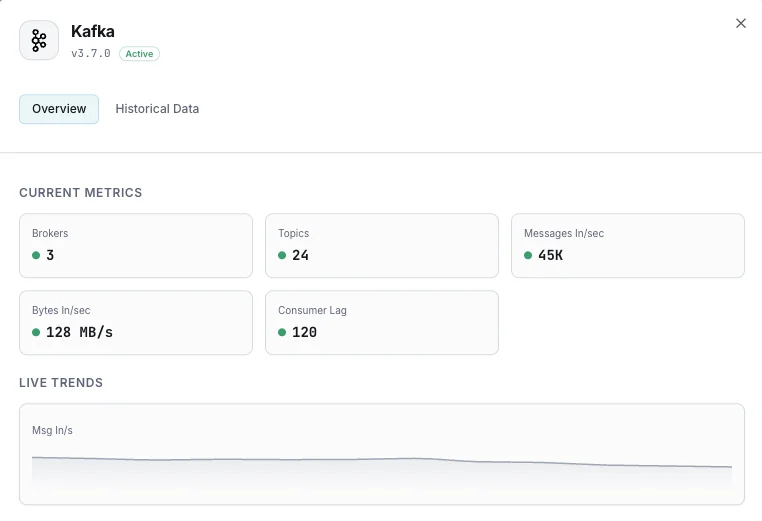
私たちが 監視するもの
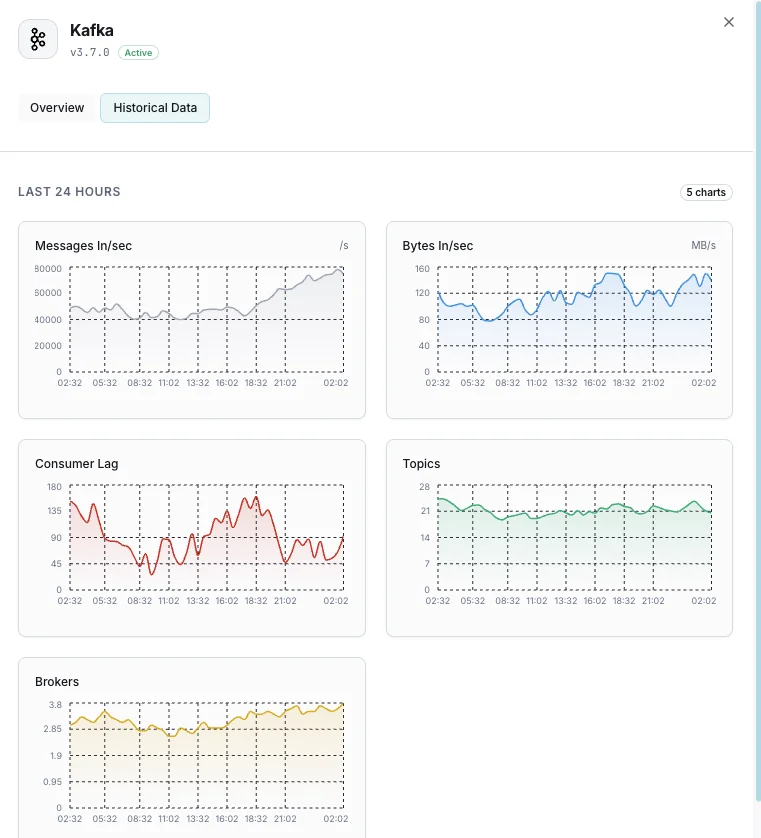
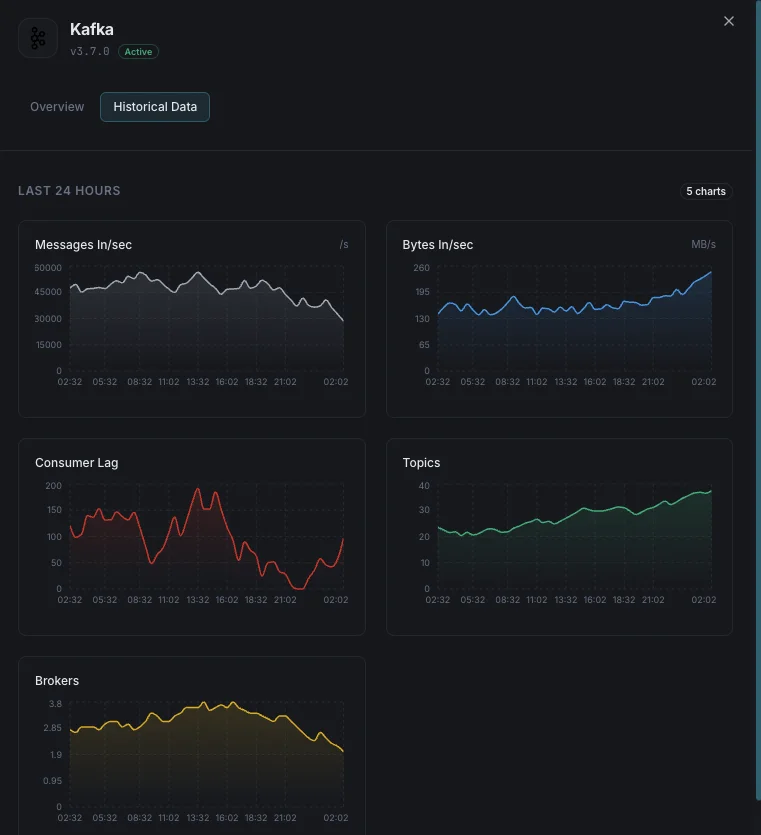
ブローカー数
クラスタ内のアクティブブローカー。
コンシューマラグ
各コンシューマグループの遅延メッセージ数。
受信メッセージ/秒
メッセージ取り込みレート。
送受信バイト
ブローカーごとのネットワークスループット。
レプリケーション不足のパーティション
レプリケーションファクター未満のパーティション。
ISR縮小
同期レプリカの縮小イベント。
UncleanLeaderElectionsPerSec
非同期レプリカがリーダーに昇格するレート(データ損失を伴う)。0 であるべき — ゼロ以外は `unclean.leader.election.enable=true` かつ実際の障害イベントが発生したことを意味します。
MessagesInPerSec / BytesIn / BytesOut
ブローカーごとおよびトピックごとのスループット。プロデューサー数が安定しているのに突然の低下 = 取り込み問題、突然の急増 = リトライ嵐または暴走プロデューサー。
リクエストレイテンシ (p99)
`kafka.network:type=RequestMetrics` からの Produce、Fetch、Metadata リクエストハンドラ時間の p99。クライアントでタイムアウトする前にブローカー過負荷を検出します。
ブローカーごとの LeaderCount
ブローカーごとのパーティションリーダー数。不均一な分布(1 つのブローカーがリーダーの 60% 以上を保持)= 不均衡なクラスタ。`kafka-reassign-partitions.sh` で修正します。
トピックごとのログサイズ
`kafka.log:type=Log,name=Size` からのトピックごとの総ディスク上ログサイズ。ディスク容量アラートを駆動し、Kafka 3.8+ の階層型ストレージポリシーに情報を提供します。
RemoteLogManager(階層型ストレージ)
Kafka 3.8+ の階層型ストレージメトリクス: リモート層へのアップロードバイト、リモート vs ローカルのセグメント、リモートからのフェッチレイテンシ。階層型フェッチを妨げる S3 接続 / IAM 問題を検出します。
設定可能 アラートのトリガー
ダッシュボードでカスタムトリガーを設定し、Apache Kafkaのメトリクスが定義した閾値を超えた瞬間に通知を受け取れるようにします。
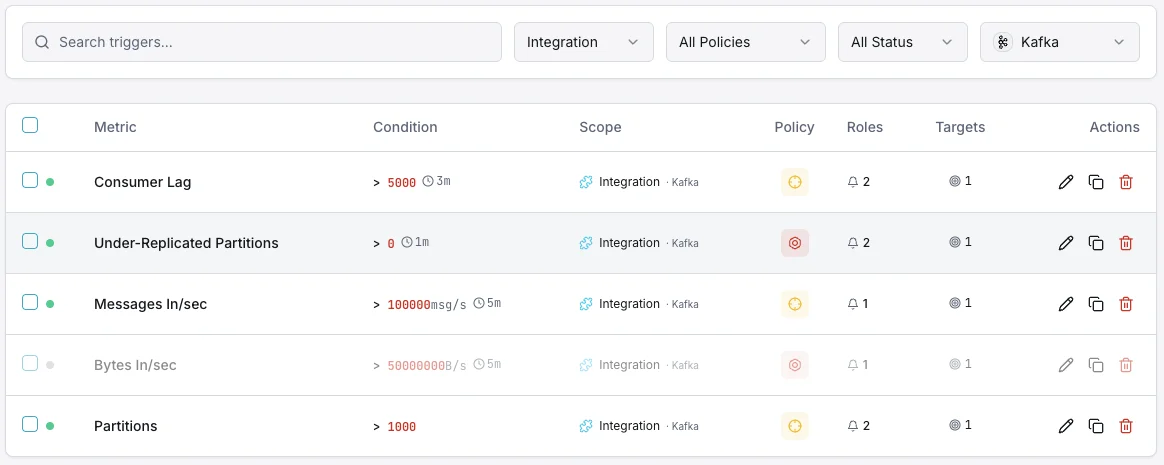
コンシューマラグ
重要なコンシューマが遅れたときに発動。
レプリケーション不足のパーティション
重要なレプリケーション問題でアラート。
ブローカーダウン
重要なブローカーがクラスタから離脱したときに発動。
ディスク使用量
警告ブローカーのディスクが満たされつつあるときに発動。
の重要性: Kafka監視
Kafkaは毎日数兆のメッセージを処理します。コンシューマラグ、ブローカー障害、パーティション不均衡はデータパイプラインの障害を引き起こします。
- データ損失前にコンシューマラグを検出
- データ耐久性のためにISRを監視
- クラスタ間でブローカーの健全性を追跡
- パーティションのバランスを確保
なぜ選ぶべきか: Xitoring
エンタープライズグレードのKafka監視。
- ゼロコンフィグセットアップ
- グローバルノード
- 統合ダッシュボード
- マルチチャネルアラート
- 履歴保持
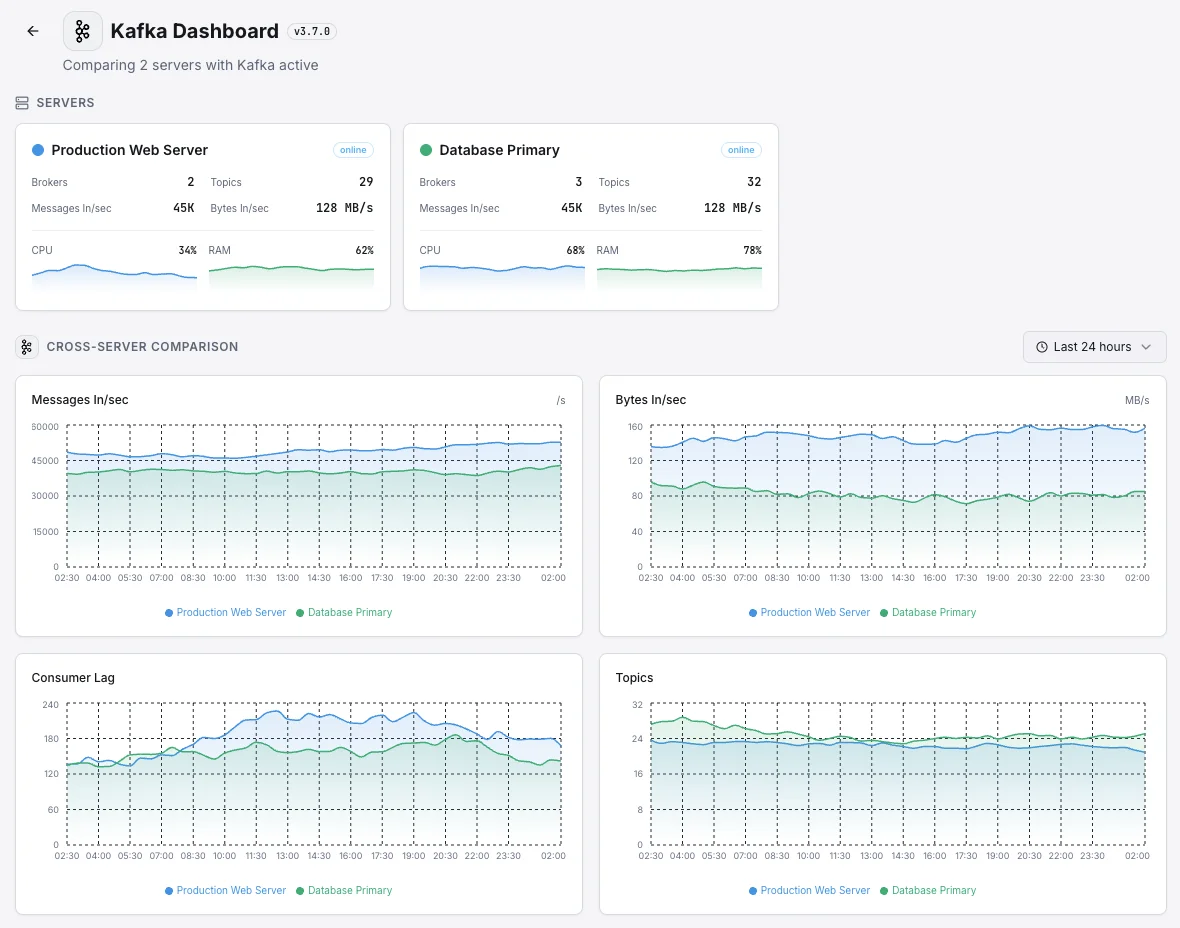
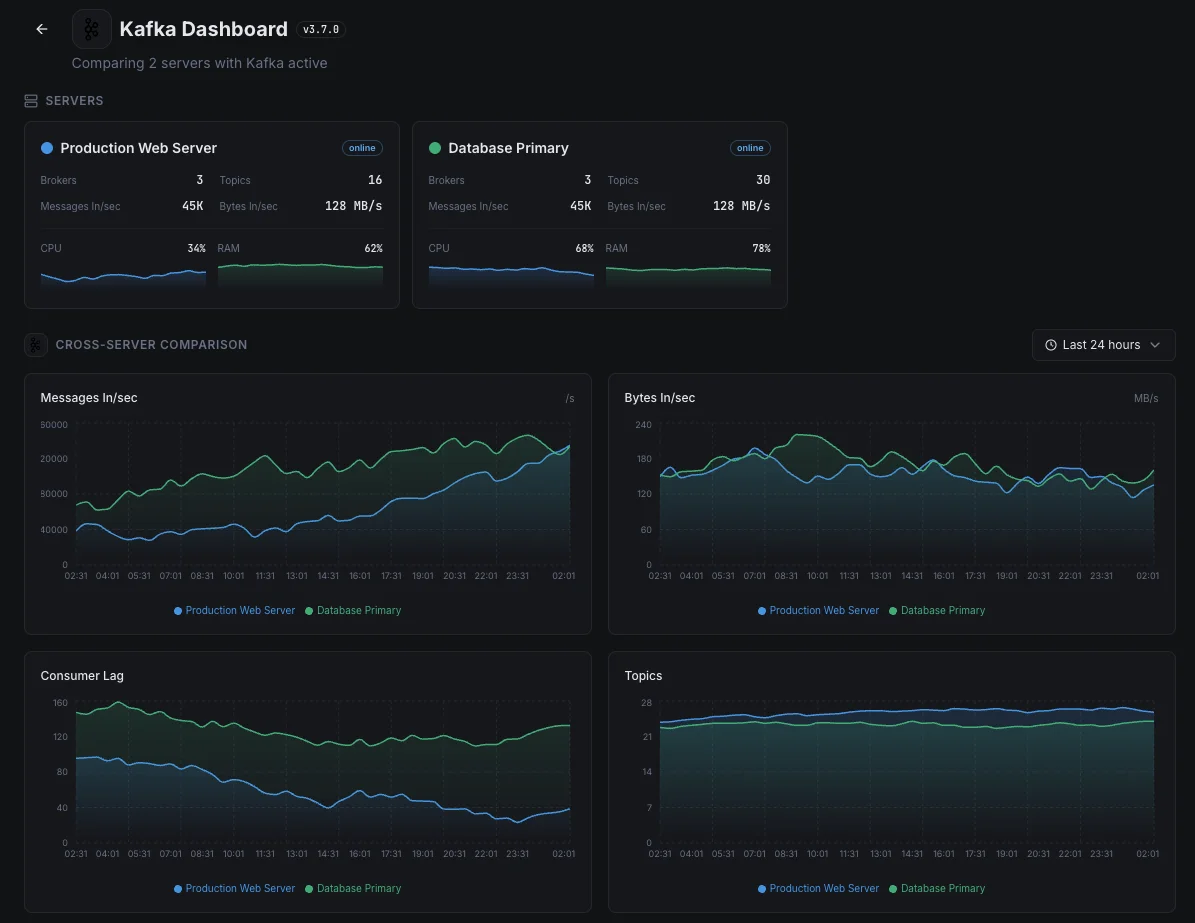
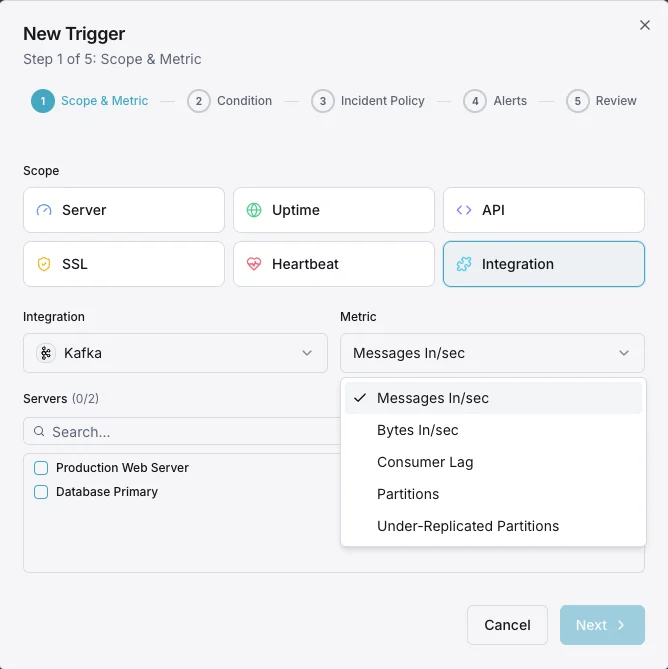
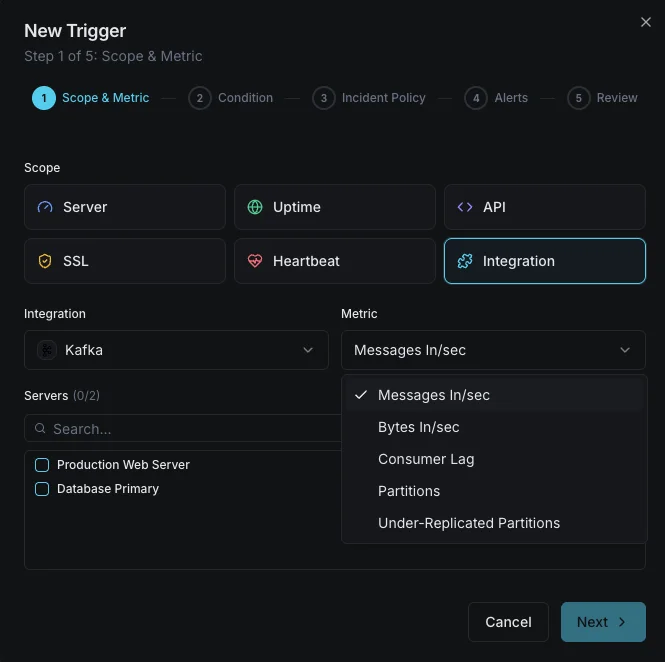
Kafka 監視の一般的な シナリオ
Kafkaが今日一般的に稼働している場所 — そして誰も監視していない場合に何が問題になる可能性があるか。
アプリケーションを接続するメッセージングバックボーン
Kafkaがアプリケーション間でデータを移動するメッセージを運ぶとき、どんな速度低下も、あるアプリケーションが静かに遅れていることを意味します。そしてその結果(更新の遅延、古いデータ、壊れたワークフロー)は後になって初めて現れます。私たちは遅延が始まった瞬間にそれを検知し、顧客に見える問題にならないようにします。
Kubernetes内で稼働するKafka
KafkaがKubernetesで稼働している場合、プラットフォームは常にそれを移動させます。そして、ルーチンな再起動は、データを保護するセーフティネットを一時的に弱める可能性があります。私たちはすべての再起動とリバランスを監視し、通常の更新が静かにシステムをデータ損失から一歩手前の状態にしないようにします。
大量データ向けのセルフマネージドKafka
大規模に独自のKafkaを運用する企業は、それが非常に堅牢であることを必要とします。通常、彼らが持つ最も価値のあるデータを運んでいるからです。私たちはそれを健全に保つシグナルを監視し、チームがメッセージングレイヤーの火消しに追われるのではなく、製品構築に集中できるようにします。
Apache Kafka の 前提条件
これらが揃っていることを確認してください — 揃っていれば、ほとんどの導入は 60 秒で完了します。
- JMX が有効な Kafka ブローカー(デフォルトポート 9999)
- Xitogent から各ブローカーの JMX ポートへのネットワーク到達性
- セキュリティが設定されている場合、JMX 認証情報
はじめに 議事録
各ブローカーに Xitogent をインストール
監視対象のすべての Kafka ブローカーに軽量な Xitogent 監視エージェントをインストールしてください。
curl -s https://xitoring.com/install.sh | sudo bash -s -- --key=YOUR_API_KEY各ブローカーで JMX を有効化
Kafka は JMX を通じてブローカーメトリクスを公開します。各ブローカーで `KAFKA_JMX_OPTS` を設定して JMX リスナー(通常ポート 9999)を有効化し、サービスを再読み込みして、エージェントホストから JMX ポートに接続できることを確認してください。
sudo xitogent integrateKafka 連携を有効化
Xitoring ダッシュボードまたは CLI から Kafka 連携を有効化してください。Xitogent がクラスタ全体のブローカー ID、トピック、コンシューマグループを自動検出します。
アラートしきい値を設定(オプション)
Consumer Lag、レプリケーション不足のパーティション、Broker Down イベントにカスタムしきい値を設定し、コンシューマが追いつけなくなる前にレプリケーション問題やバックプレッシャーを検知できるようにします。
動作確認
サーバー上でこのコマンドを実行して、Xitogent が連携を認識していることを確認してください。約 30 秒以内に新しいメトリクスがダッシュボードに流れ始めます。
sudo xitogent status代替ツールを 検討中ですか?
Apache Kafka 監視の代替ツールと比べて Xitoring がどう優れているかをご覧ください — 定額料金、より深い統合、そしてスタック全体をカバーする 1 つのエージェント。



頻繁に 質問をした
カフカのバージョン?
ZooKeeperか、それともKRaftか?
レプリケーション不足のパーティションとは何で、どう修正すればよいですか?
Prometheus で Kafka ブローカーの JMX メトリクスを監視するにはどうすればよいですか?
KRaft モードとは何で、ZooKeeper なしで監視はどう変わりますか?
Kafka オフラインパーティションを検出するにはどうすればよいですか?
Kubernetes(Strimzi)上の Kafka クラスタを監視するにはどうすればよいですか?
Kafka と Redpanda の監視の違いは何ですか?
サポートされている Kafka のバージョンは何ですか?
探検を続けよう