CoreDNS Seguimiento
Supervisa en tiempo real las tasas de consultas de CoreDNS, los índices de aciertos en caché, la latencia de resolución y las tasas de error sin necesidad de configuración.
¿Por qué realizar un seguimiento? CoreDNS?
CoreDNS es el servidor DNS predeterminado para Kubernetes y entornos nativos de la nube. La supervisión de CoreDNS garantiza una resolución DNS rápida, un rendimiento óptimo de la caché y una detección de servicios fiable para tu infraestructura.
Monitoreo de CoreDNS, explicado
El monitoreo de CoreDNS detecta picos de SERVFAIL, caídas en la tasa de aciertos de caché, latencia del plugin forward y reinicios por panic antes de que se conviertan en fallos de resolución DNS en todo el clúster. Como cada microservicio depende del DNS para el descubrimiento de servicios, un CoreDNS sin monitorear es un modo de fallo sin monitorear para todo su clúster de Kubernetes: los problemas de DNS aparecen como "connection refused aleatorios" en todas partes. Xitoring detecta automáticamente su CoreDNS, raspa :9153/metrics y envía las alertas a Slack, PagerDuty, Telegram o su sistema de guardias existente.
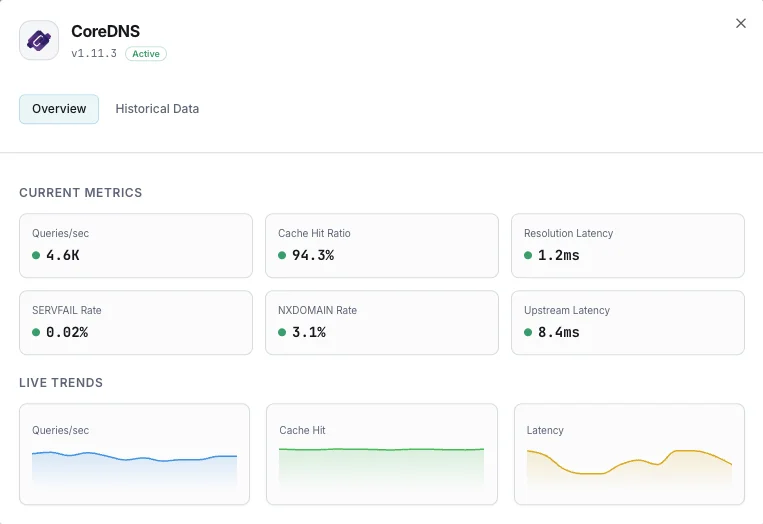
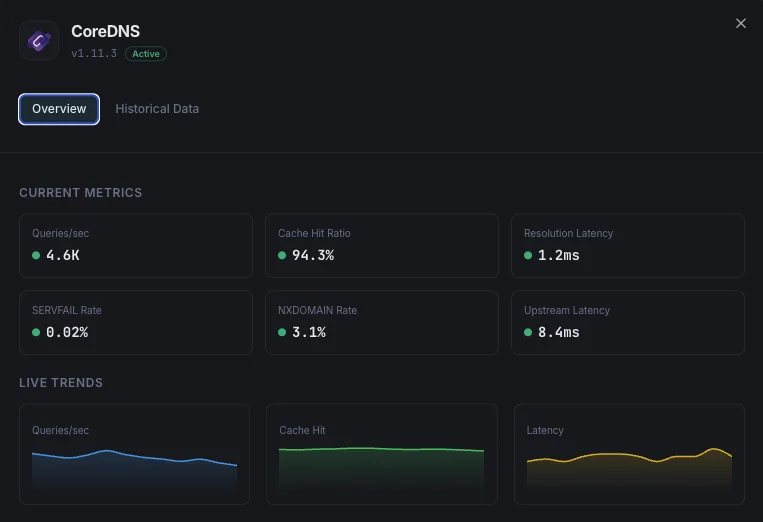
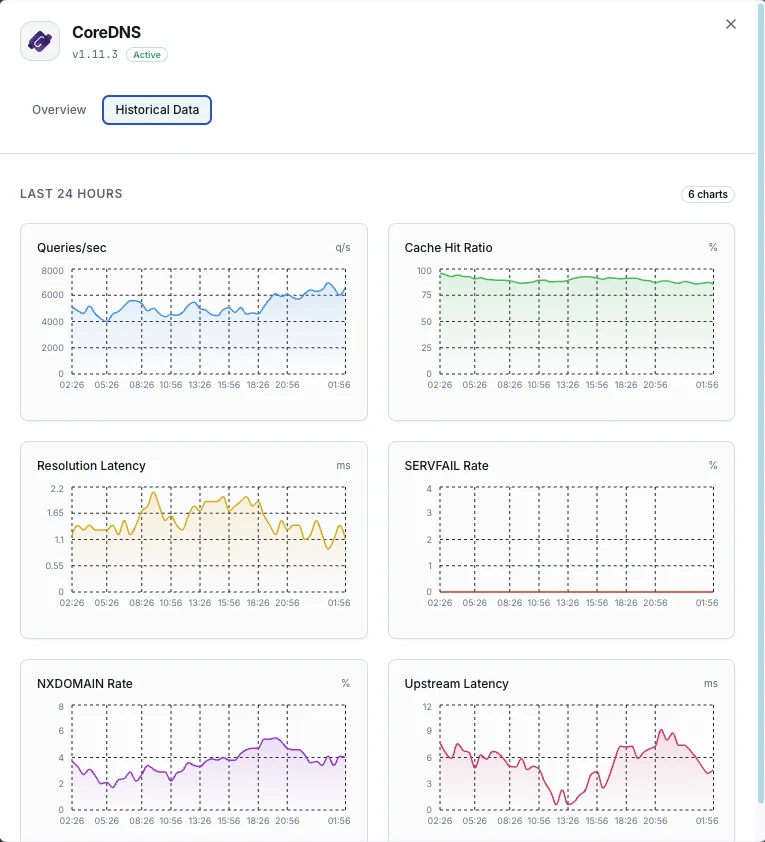
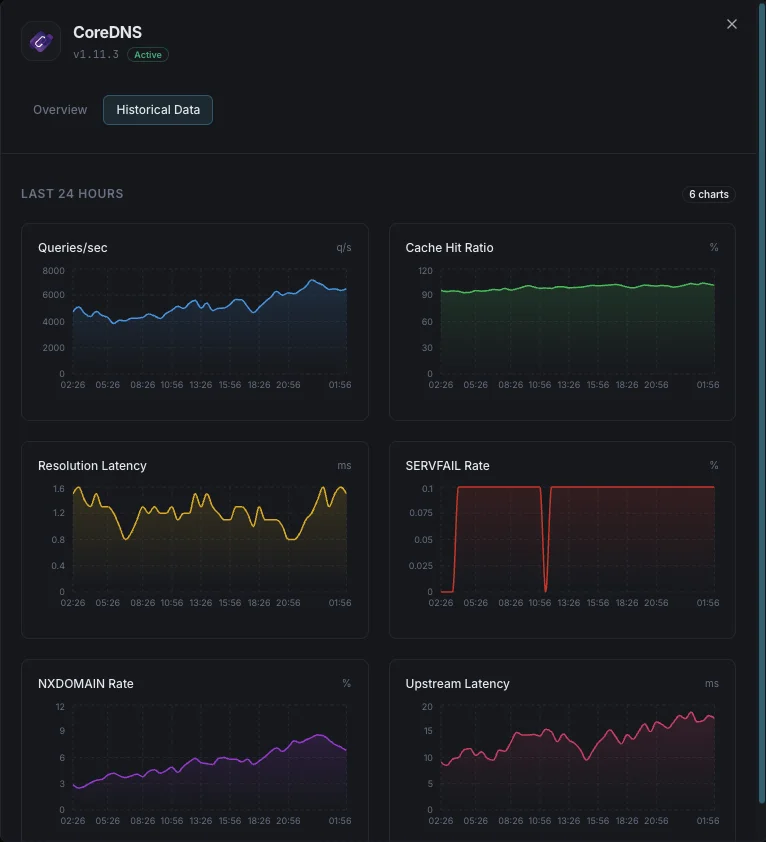
Lo que monitorizamos
Consultas/s
Tasa de consultas DNS.
Ratio de aciertos de caché
Porcentaje de consultas servidas desde caché.
Latencia de resolución
Tiempo medio de resolución DNS.
Tasa de SERVFAIL
Porcentaje de resoluciones fallidas.
Tasa NXDOMAIN
Tasa de consultas a dominios inexistentes.
Latencia upstream
Tiempo de respuesta de consultas reenviadas.
Latencia del plugin forward
`coredns_forward_request_duration_seconds` por resolver upstream. Separa la latencia interna de CoreDNS de la latencia del resolver upstream, fundamental para diagnosticar un 8.8.8.8 lento frente a un CoreDNS lento en sí mismo.
Tasa de solicitudes forward
`coredns_forward_request_count_total` por upstream. Combinada con la tasa de aciertos de caché, muestra cuánto tráfico abandona realmente CoreDNS para la resolución upstream.
Caché de conexiones proxy
`coredns_proxy_conn_cache_hits_total` / `_misses_total`. Rastrea la reutilización de conexiones TCP a los resolvers upstream: una tasa baja de aciertos significa rotación de conexiones, lo que aumenta la latencia upstream.
Fallos del plugin health
`coredns_health_request_failures_total`: el propio recuento de fallos del plugin `health:8080`. Un valor distinto de cero significa que la sonda de actividad está fallando de forma intermitente.
Panics
`coredns_panics_total`: cualquier valor distinto de cero es un bug de CoreDNS o un fallo de plugin que provocó un panic de goroutine. Combínelo con el recuento de reinicios para obtener el contexto post-mortem completo.
Runtime de Go
`process_resident_memory_bytes` (RSS), `go_goroutines` (recuento de goroutines, detecta fugas), `go_gc_duration_seconds` (tiempo de pausa del GC). Crecimiento de memoria sin reinicios = fuga; crecimiento del recuento de goroutines = plugin bloqueado o upstream lento.
Configurables condiciones de activación de alertas
Configura alertas personalizadas en tu panel de control para recibir una notificación en cuanto las métricas de «CoreDNS» superen los umbrales que hayas definido.
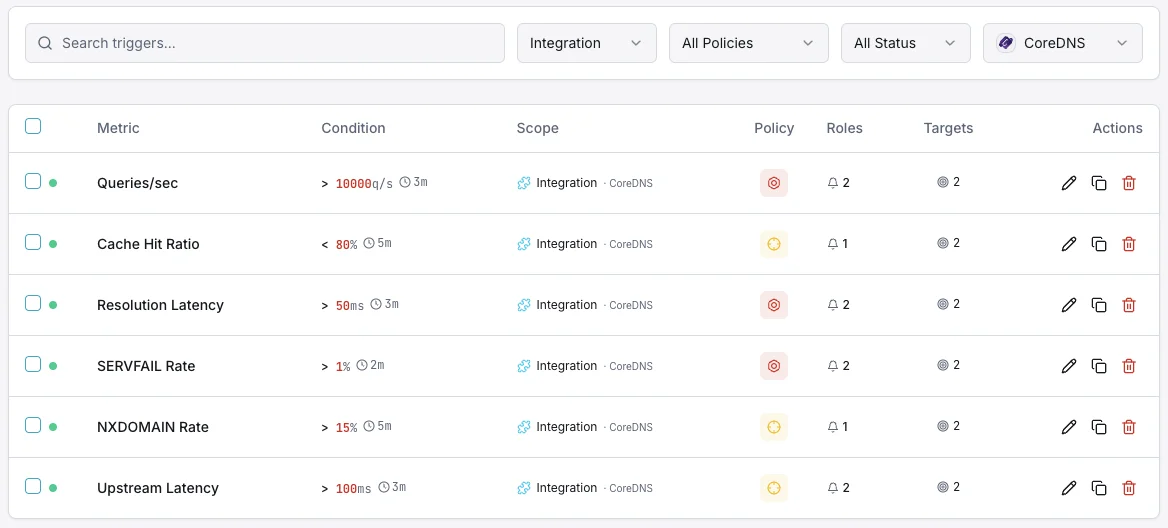
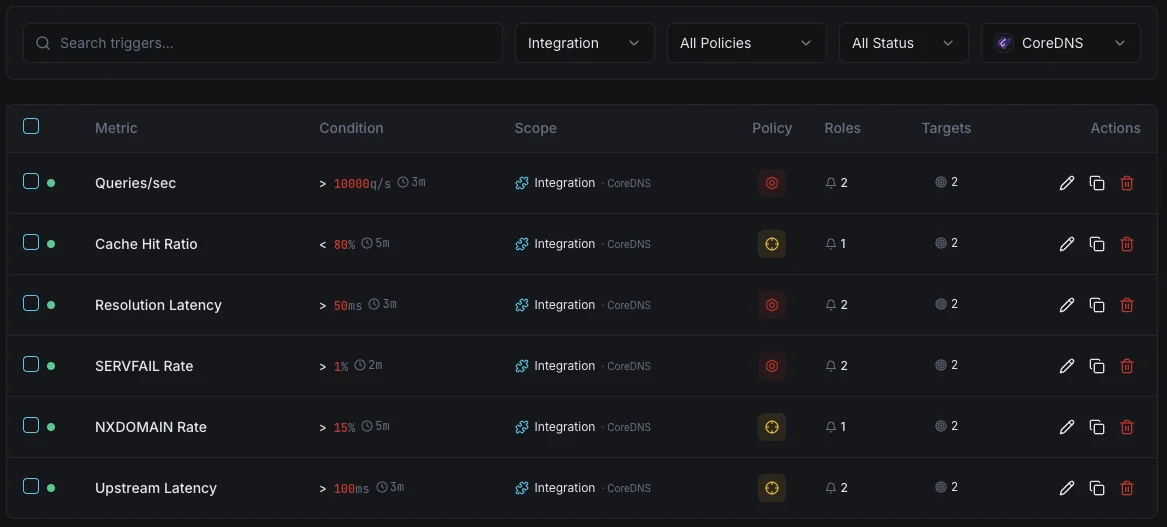
Tasa de SERVFAIL
críticoSe dispara ante una alta tasa de fallos de resolución.
Ratio de aciertos de caché
advertenciaAlerta cuando la efectividad de la caché cae.
Latencia de resolución
advertenciaSe activa en caso de resolución DNS lenta.
Tasa de consultas
advertenciaSe dispara ante un volumen de consultas inusual.
Importancia de monitorización de CoreDNS
El DNS es la base de la conectividad de red. Una resolución DNS lenta o fallida afecta a todos los servicios de su infraestructura.
- Garantizar una resolución DNS rápida
- Detectar picos de SERVFAIL al instante
- Monitorizar la caché para un rendimiento óptimo
- Seguir el estado de los resolvers upstream
Por qué elegir Xitoring
Monitorización CoreDNS sin configuración.
- Instalación con un solo comando
- Nodos globales
- Panel unificado
- Alertas multicanal
Escenarios habituales de monitoreo de CoreDNS
Dónde suele ejecutarse CoreDNS hoy en día — y qué podría salir mal si nadie está vigilando.
DNS dentro de una aplicación de Kubernetes
Cada parte de una aplicación de Kubernetes utiliza CoreDNS para encontrar todas las demás partes. Cuando se ralentiza o empieza a fallar, los usuarios ven errores extraños e intermitentes en toda la aplicación. Detectamos la ralentización en el momento en que comienza, para que un pequeño problema de DNS no se manifieste a los clientes como una interrupción misteriosa.
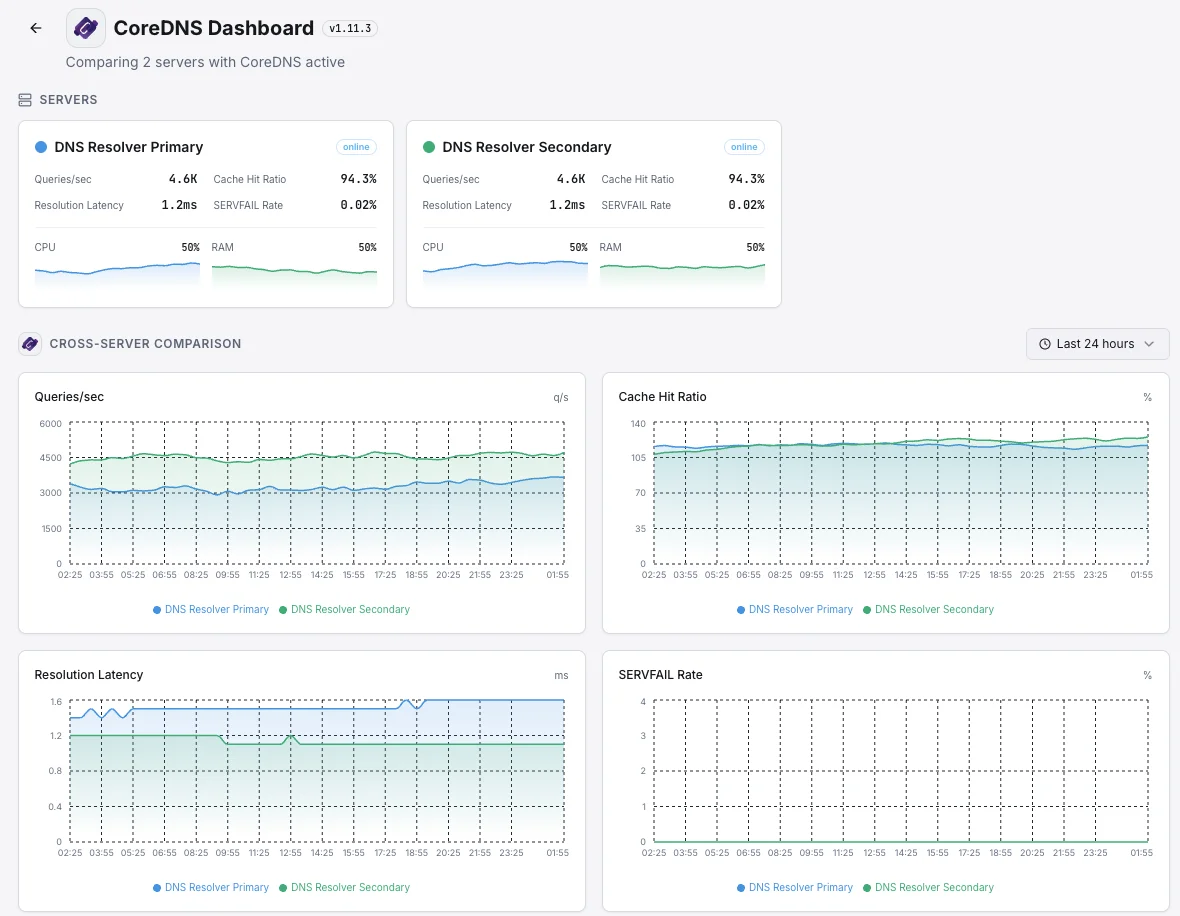
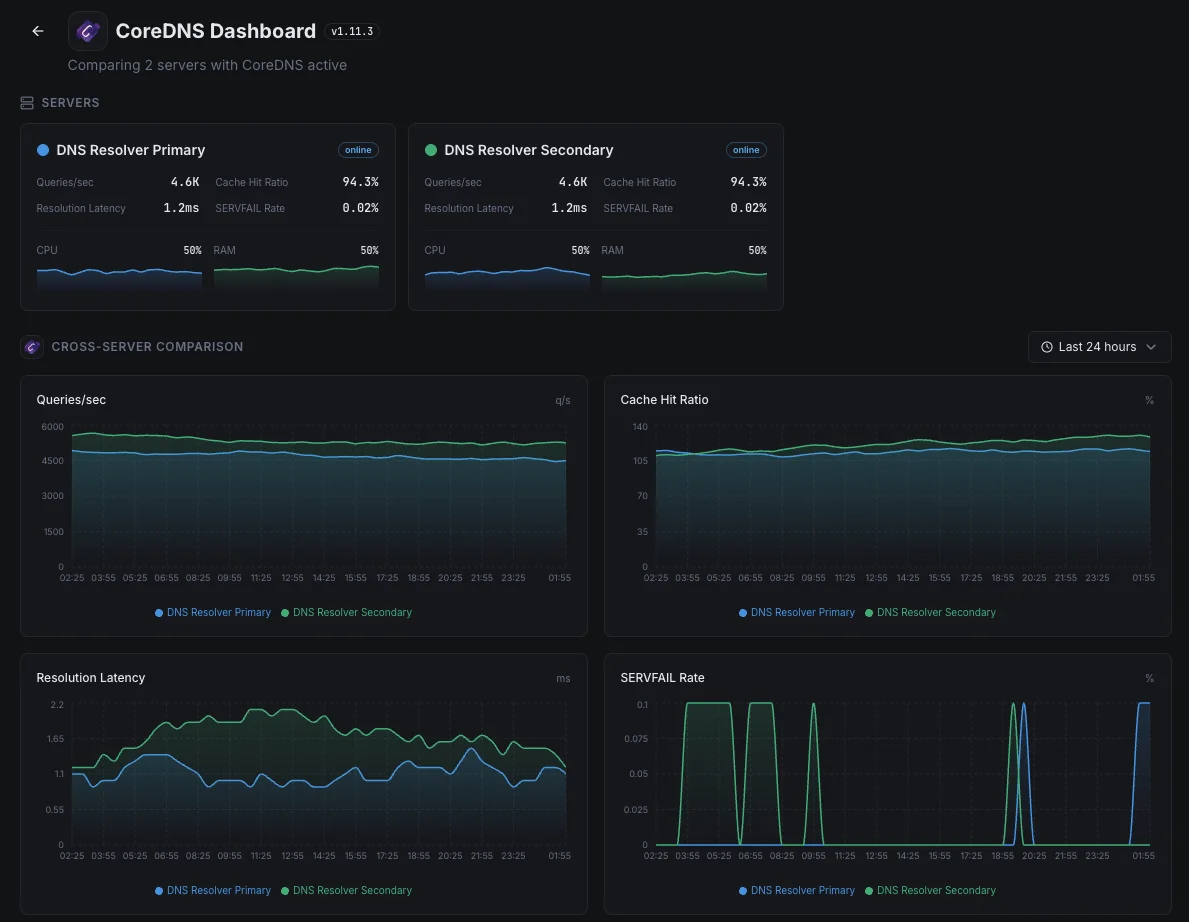
Clusters grandes con cachés DNS locales
Las configuraciones de Kubernetes más grandes colocan una pequeña caché DNS en cada servidor para mantener la velocidad. Cuando una de esas cachés funciona mal, solo una parte del tráfico se interrumpe — lo que dificulta su detección. Nos aseguramos de que cada una cumpla su función para que un solo nodo defectuoso no degrade silenciosamente a una fracción de tus usuarios.
DNS público para tu dominio
Cuando CoreDNS es el que responde a las consultas DNS de tu dominio en internet, una interrupción significa que la gente no puede acceder a tu sitio en absoluto. Vigilamos las señales que demuestran que el servicio está saludable y respondiendo, para que la marca y los ingresos no se vean afectados silenciosamente mientras el DNS falla en silencio.
Requisitos previos para CoreDNS
Asegúrate de tener todo esto en su sitio — la mayoría de las instalaciones tardan 60 segundos una vez listo.
- CoreDNS 1.x ejecutándose en el servidor
- Plugin Prometheus habilitado en tu Corefile (puerto predeterminado 9153)
- Conectividad de red desde Xitogent hacia el endpoint de metrics
Empieza con minutos
Instalar Xitogent en tu servidor
Si aún no lo has hecho, instala el agente de monitorización ligero Xitogent en el host que ejecuta CoreDNS.
curl -s https://xitoring.com/install.sh | sudo bash -s -- --key=YOUR_API_KEYHabilitar el plugin prometheus en CoreDNS
CoreDNS expone métricas en formato Prometheus a través de su plugin prometheus (endpoint por defecto :9153/metrics). Añade `prometheus :9153` a tu Corefile, recarga CoreDNS y confirma que el endpoint de metrics es accesible desde el host del agente.
sudo xitogent integrateHabilitar la integración de CoreDNS
Usa el panel de Xitoring o la CLI para habilitar la integración de CoreDNS. Xitogent detecta automáticamente el endpoint de metrics y comienza a recolectar métricas de consultas, caché y latencia.
Configurar umbrales de alerta (opcional)
Define umbrales personalizados para la tasa de SERVFAIL, el ratio de aciertos de caché o la latencia de resolución para recibir notificaciones en cuanto la fiabilidad o el rendimiento del DNS se degraden.
Verifica que funciona
Ejecuta este comando en el servidor para confirmar que Xitogent ha detectado la integración. En unos 30 segundos comenzarán a llegar métricas nuevas a tu panel.
sudo xitogent status¿Estás considerando alternativas?
Mira cómo se compara Xitoring frente a las alternativas para la supervisión de CoreDNS: precios planos, integraciones más profundas y un solo agente que cubre todo tu stack.



Con frecuencia preguntas formuladas
¿CoreDNS de Kubernetes?
¿Métricas de Prometheus?
¿Qué hace el plugin kubernetes?
¿Cómo monitoreo la tasa de aciertos de caché de CoreDNS?
¿Qué significa NXDOMAIN en las métricas de CoreDNS?
¿Cómo depuro CoreDNS en Kubernetes?
¿Cómo monitoreo la latencia del plugin forward de CoreDNS?
¿Cuándo debo usar NodeLocal DNSCache?
¿Qué versiones de CoreDNS son compatibles?
Empieza a seguir a CoreDNS hoy
Se configura en menos de 60 segundos. No se necesita tarjeta de crédito. Estadísticas completas desde el primer día.
Empieza tu prueba gratuita