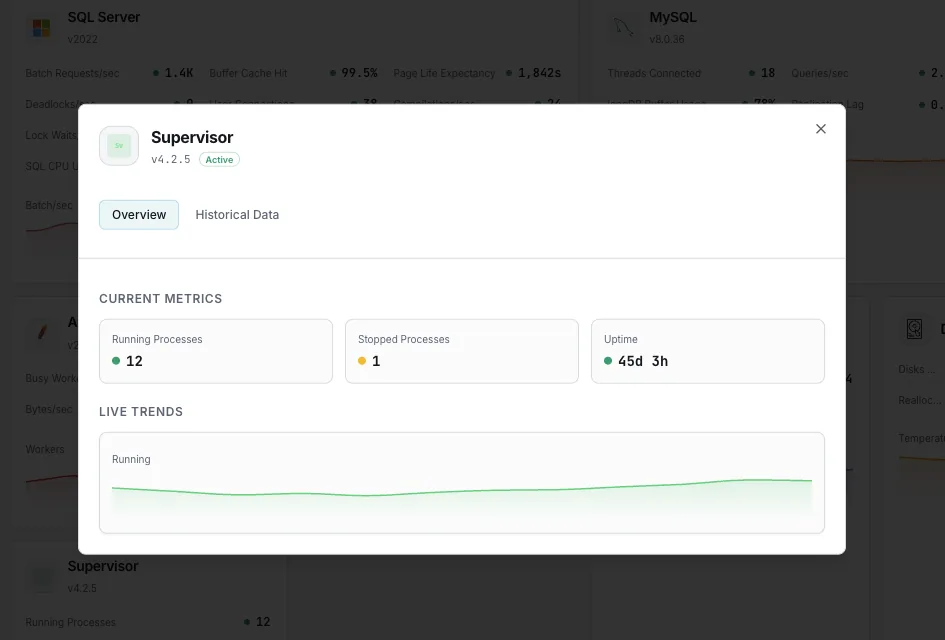
Supervisor 監視
Supervisorで管理されているすべてのプロセスについて、状態(`RUNNING`/`FATAL`)、稼働時間、予期せぬ終了、再起動ループ、終了コードなどをリアルタイムで監視します。`supervisorctl` によるエージェント方式を採用しており、プロセスが `FATAL` 状態になった瞬間にアラートが通知されます。
なぜ監視するのか Supervisor?
Supervisor(`supervisord`)は、Celery や Sidekiq のワーカー、Gunicorn や uWSGI といったアプリケーションサーバー、キューコンシューマー、そして長時間実行されるデーモンといったバックグラウンドプロセスを稼働させ続けます。しかし、`startretries` 回分の再起動に失敗すると、Supervisor は再起動を断念し、そのプロセスを `FATAL` 状態に置きます。そこでは、プロセスは静かに停止したままになります。 プロセスごとの監視の有無が、1行のアラートで済むか、あるいは何時間も誰にも気づかれずにキューが詰まってしまうかの分かれ目となります。
監督者の監視、 説明した
Supervisorによる監視とは、supervisordが管理するすべてのプログラムの状態を継続的に追跡し、プロセスがRUNNING状態から外れた際にアラートを発する仕組みです。Supervisorは、クラッシュしたプロセスを再起動するのに優れていますが、startsecsの間にstartretries回までしか再起動を試みません。 この制限を超えると、プロセスは FATAL 状態となり、Supervisor は再起動を試みなくなります。他のシステムはこれに気づきません。ホストもデーモンも稼働しているのに、キューの処理が単に停止してしまうのです。 Xitoringはsupervisorctlを通じてライブプロセステーブルを読み取り、各プログラムを個別に追跡し、ワーカーがFATAL状態になったり、BACKOFFループで不安定になったり、予期しない終了コードで終了したりした瞬間に、オンコール当番チームへアラートを送信します。
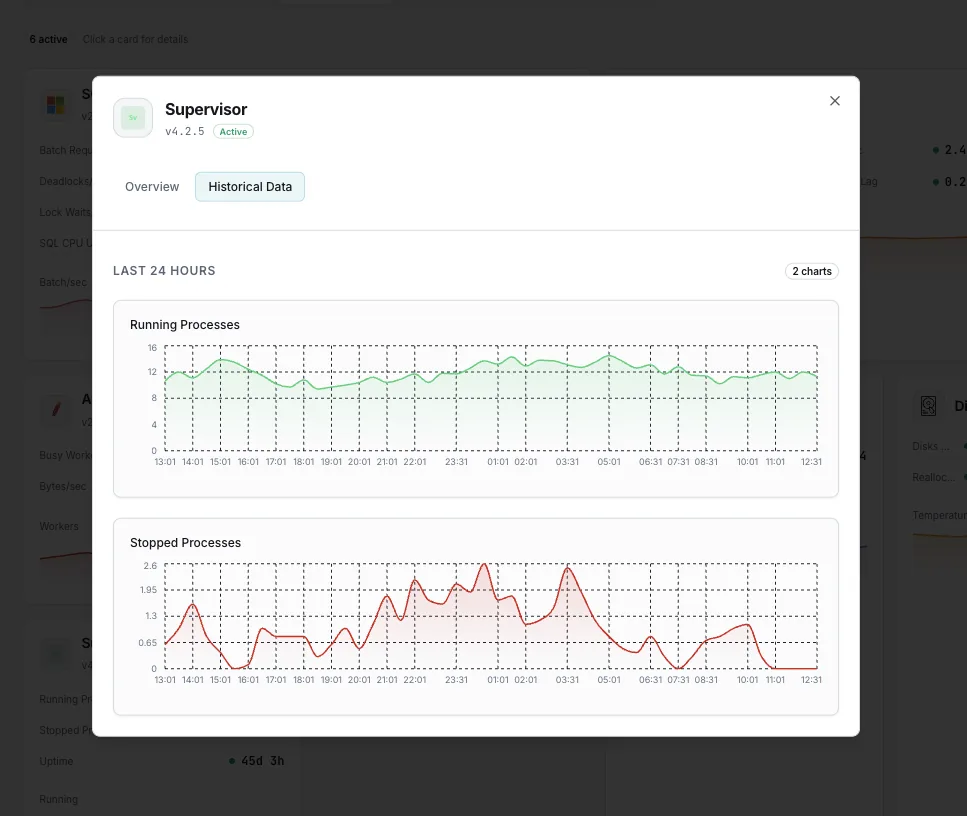
私たちが 監視するもの
プロセスの状態
各プログラムの現在の状態(`RUNNING`、`STARTING`、`BACKOFF`、`EXITED`、`FATAL`、`STOPPED`、`STOPPING`、`UNKNOWN`)。 Supervisorにとって最も重要なシグナルは、長時間実行中のワーカーが`RUNNING`以外の状態にある場合、それが問題であるということです。
FATAL状態
`startretries` を超え、Supervisor によって中止されたプロセスです。このプロセスは自動的に再起動することはありません。`FATAL` に含まれるプログラムはすべて、記事に値する重大なシグナルです。
BACKOFF / ループの再起動
`startsecs`の前に繰り返し終了し、再試行されているプロセスです。継続的な `BACKOFF` は、再起動のたびにCPUを消費し続け、トラフィックを処理できないままのフラッピング状態にあるワーカーを意味します。
稼働時間(起動からの経過時間)
各プロセスが現在のPIDを保持している期間。稼働時間が繰り返しリセットされるワーカーは、再起動の合間に一時的に `RUNNING` と表示されたとしても、実際には黙ってクラッシュループに陥っている。
プロセスPID
`supervisorctl status` コマンドで表示される、プログラムごとのライブ PID。これが表示されていれば、そのプロセスが単に設定されているだけでなく、実際に実行されていることが確認できます。
ラスト・エグジット・コード
直近の実行時の終了ステータス。プログラムの `exitcodes` と照らし合わせて、正常な終了と予期せぬクラッシュを見分けることができます。
実行時と設定時
宣言されたプロセス数(`numprocs`を含む)に対して、実際に`RUNNING`状態にあるプロセスの数をカウントします。これにより、グループ内でワーカーが不足している箇所が一目でわかります。
予期せぬ退場
`autorestart=unexpected` の設定時に、`exitcodes` に含まれないコードで終了します。これらは本来発生してはならないクラッシュであり、その発生件数が増加傾向にある場合は、リグレッションを示唆しています。
再起動回数
各プロセスが、時間の経過とともにどれくらいの頻度で再起動されたか。継続的に実行されるべきプロセスで再起動が頻繁に発生している場合は、不安定性やメモリリークの兆候である可能性があります。
停止中のプロセス
実行中であるべきなのに、`STOPPED` または `EXITED` 状態にあるプログラム。誰かが手動で停止したまま忘れてしまったワーカーや、自動再起動されずに終了してしまったワーカーを検出します。
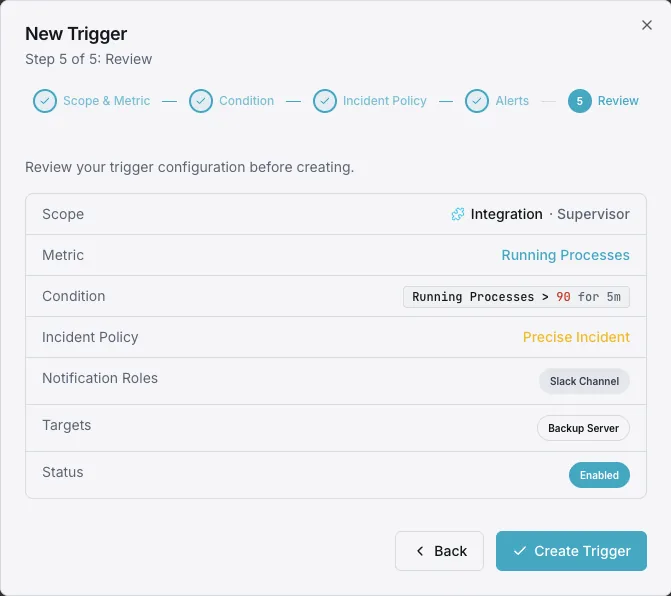
設定可能 アラートのトリガー
ダッシュボードでカスタムトリガーを設定し、Supervisorのメトリクスが定義した閾値を超えた瞬間に通知を受け取れるようにします。
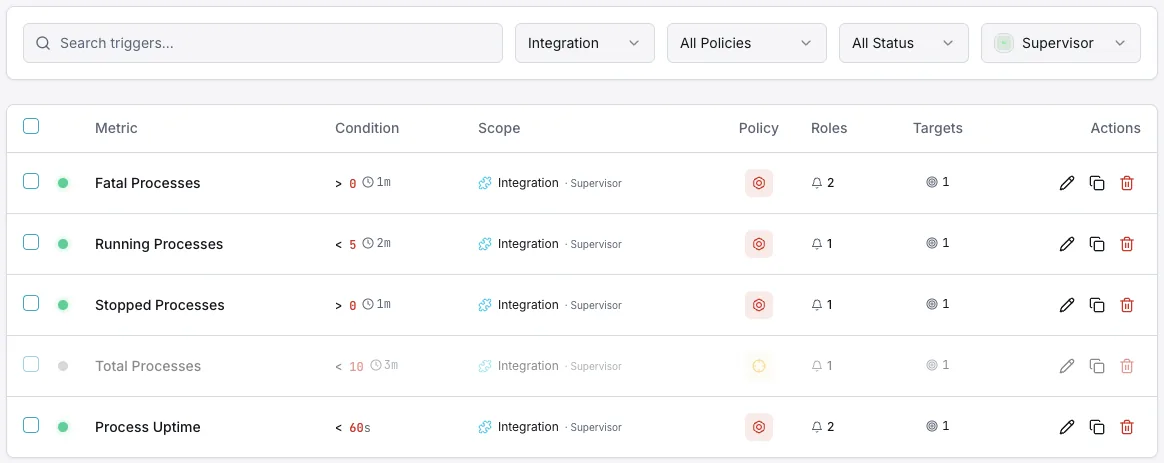
プロセス FATAL
重要なプロセスが `FATAL` 状態になったときに発生します。これは、スーパーバイザーがそのプロセスの再起動を断念し、誰かが介入するまでプロセスが停止したままになる状態です。
プロセスが実行されていません
重要な`RUNNING`であるべきプログラムが`STOPPED`、`EXITED`、または`UNKNOWN`になったときにトリガーされます。
ループを再開
警告`BACKOFF`が継続している場合や再起動が繰り返される場合のアラート — クラッシュを繰り返して安定しないワーカー。
予期しない終了コード
警告プロセスが、設定された `exitcodes` に含まれない終了コードで終了した場合に発火します。
の重要性 監督者の監視
スーパーバイザーは、クラッシュしたプロセスを再起動し続けます――ただし、それができなくなるまでは。`startretries` を超えると、プロセスは `FATAL` 状態で保留され、完全に停止したままになります。ホスト側からは、そのことを知らせる何の通知もありません。
- `FATAL` が発生して再起動を停止したプロセスを捕捉する
- `BACKOFF`ループに陥っているフラッピングワーカーを検出する
- 稼働時間のリセットによるサイレント再起動の検出
- 従業員が予期せぬコードで退勤したタイミングを把握する
なぜ当社を選ぶのか Xitoring
ゼロ設定で導入可能なエージェントベースのSupervisor監視機能。supervisordが管理するすべてのプログラムにおいて、プロセスごとの可視性を確保します。
- 1つのコマンドでインストールと統合
- プロセス単位およびグループ単位の追跡
- 公開するXML-RPCやHTTPインターフェースはありません
- 当直ローテーションへのマルチチャネル通知
- 過去の状態と再起動履歴
共通スーパーバイザーによる監視 シナリオ
Supervisorが通常実行される場所――そして、誰も見ていないときに静かに失敗してしまうもの。
バックグラウンド処理ツール(Celery、Sidekiq、RQ、Resque)
キューワーカーとは、まさに「静かに終了してしまう」プロセスのことです。デプロイの失敗や不正なメッセージによって再起動ループに陥り、最終的に FATAL 状態になります。ワーカーの実行が停止した瞬間、キューが詰まったりジョブがタイムアウトし始める前に、アラートを発信します。
アプリケーションサーバーとデーモン(Gunicorn、uWSGI、Daphne、Node)
Supervisorがアプリケーションサーバーを管理している場合、デプロイ後にプロセスが起動しないということは、ホストの状態は「グリーン」のままでもサイトがダウンしていることを意味します。FATALやBACKOFFを即座に検知するため、顧客からの報告を待つことなく、リリースに失敗した場合は担当者に通知が行われます。
コンテナ内およびレガシーホスト上のプロセス
多くのコンテナや旧式のサーバーでは、systemdの代わりにSupervisorを実行し、1か所で複数のプロセスを稼働させ続けています。各プロセスを個別に追跡しているため、負荷の高いコンテナ内で1つのプロセスがクラッシュしても、他のプロセスに隠れてしまうことはありません。
Supervisor の 前提条件
これらが揃っていることを確認してください — 揃っていれば、ほとんどの導入は 60 秒で完了します。
- Supervisor(
supervisord)がインストールされており、少なくとも1つのプログラムを管理しているLinuxサーバー - 同じホストにXitogentがインストールされており、
supervisorctl statusを実行できる sudo xitogent integrateを実行し、「Supervisor」統合を選択してください
はじめに 議事録
サーバーにXitogentをインストールする
Supervisor を実行しているホストに、軽量な Xitogent モニタリングエージェントをインストールしてください。
curl -s https://xitoring.com/install.sh | sudo bash -s -- --key=YOUR_API_KEYSupervisor 連携を有効にする
`sudo xitogent integrate` を実行し、「Supervisor」を選択します。Xitogent は `/etc/xitogent/integrations/supervisor_integration.conf` を書き込み、`supervisorctl` を通じてプロセステーブルを読み取り、`supervisord` 配下のすべてのプログラムとグループを自動検出します。Supervisor の設定を変更する必要はありません。
sudo xitogent integrateトリガーの設定(任意)
Xitoringダッシュボードで、プロセスごとのトリガーと重大度を設定します。たとえば、プロセスが `FATAL` 状態になった場合にページ通知を送信したり、`BACKOFF` 状態が継続した場合や予期しない終了コードが発生した場合に警告を表示したりすることで、キューが詰まる前に障害情報を当直担当者に通知できるようにします。
動作確認
サーバー上でこのコマンドを実行して、Xitogent が連携を認識していることを確認してください。約 30 秒以内に新しいメトリクスがダッシュボードに流れ始めます。
sudo xitogent status代替ツールを 検討中ですか?
Supervisor 監視の代替ツールと比べて Xitoring がどう優れているかをご覧ください — 定額料金、より深い統合、そしてスタック全体をカバーする 1 つのエージェント。



頻繁に 質問をした
「スーパーバイザーによる監視」とは何ですか?
Xitoringは、スーパーバイザーのデータをどのように収集しているのですか?
Supervisorの連携設定はどのように行えばよいですか?
「Supervisor」プロセスの状態にはどのような意味があるのでしょうか?
「FATAL」状態とはどういう意味ですか?また、なぜそれが重要なのでしょうか?
スーパーバイザーの再起動ループをどのように検出すればよいですか?
「autorestart」の「true」、「false」、および「unexpected」にはどのような違いがありますか?
複数のプロセスやプロセスグループを監視することはできますか?
Supervisor 対 systemd — なぜ特に Supervisor を監視する必要があるのか?
探検を続けよう