Disk Health Seguimiento
Supervise en tiempo real los atributos SMART de los discos, la temperatura, los sectores reasignados y los indicadores de fallos predictivos en unidades SSD y HDD.
¿Por qué realizar un seguimiento? Disk Health?
Los fallos de disco son una de las principales causas de pérdida de datos y de paradas imprevistas. La supervisión del estado de los discos de Xitoring utiliza la tecnología SMART (Self-Monitoring, Analysis, and Reporting Technology) para ofrecerte alertas tempranas antes de que las unidades fallen, y abarca SSD, HDD y configuraciones RAID tanto en Linux como en Windows.
Monitoreo de la salud del disco, explicado
El monitoreo de la salud del disco detecta el crecimiento de sectores reasignados, el desgaste de NVMe, los picos de temperatura y los indicadores de fallo inminente días o semanas antes de que las unidades mueran, tiempo suficiente para migrar los datos y cambiar la unidad sin tiempo de inactividad. Para servidores de bases de datos, hosts de backups y cualquier carga de trabajo donde un fallo de unidad signifique pérdida de datos, el monitoreo SMART es la alerta de mayor ROI que puede configurar. Xitoring ejecuta smartctl + nvme-cli localmente y envía las alertas a Slack, PagerDuty, Telegram o su sistema de guardias existente.
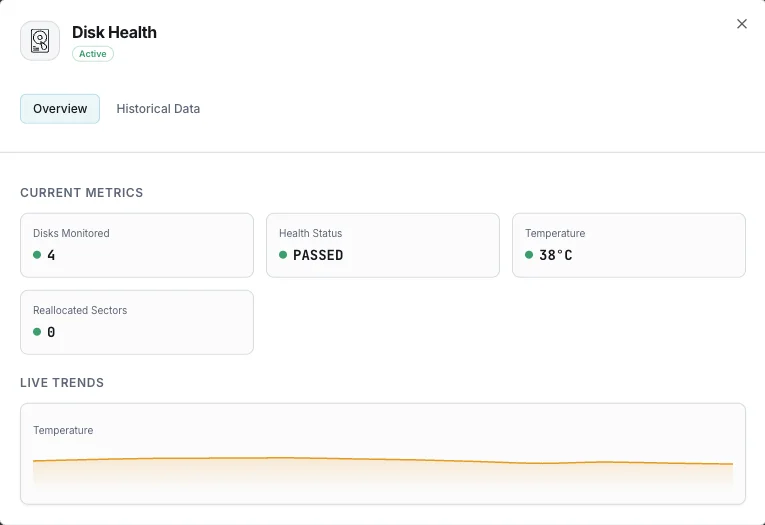
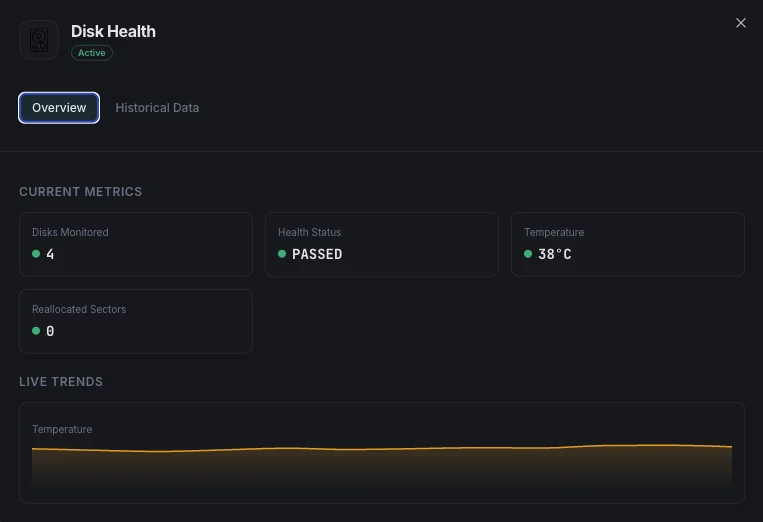
Lo que monitorizamos
Estado de salud SMART
Indicador global de salud del disco (aprobado/falló).
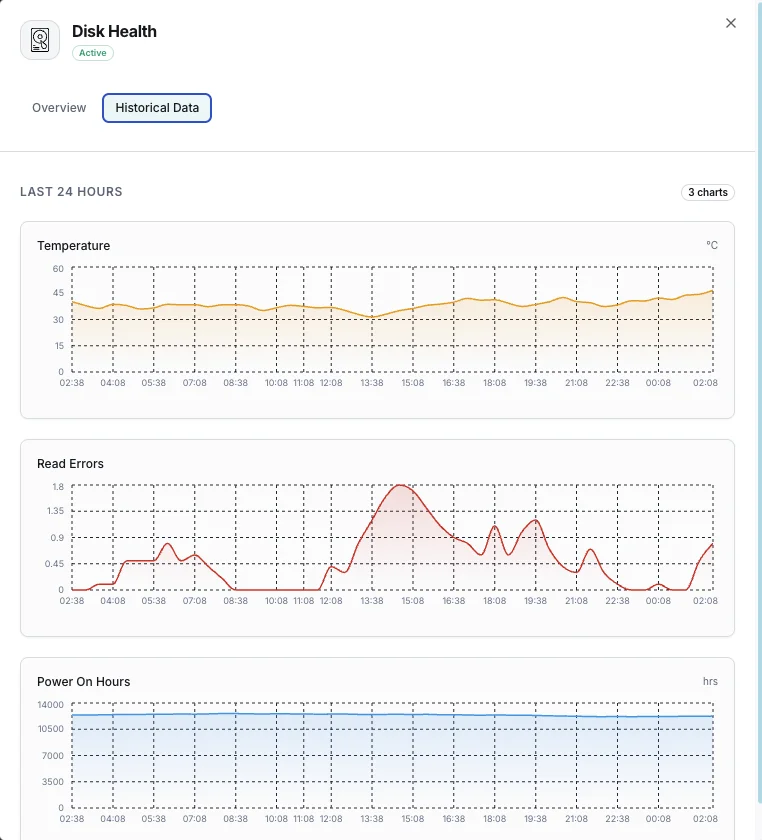
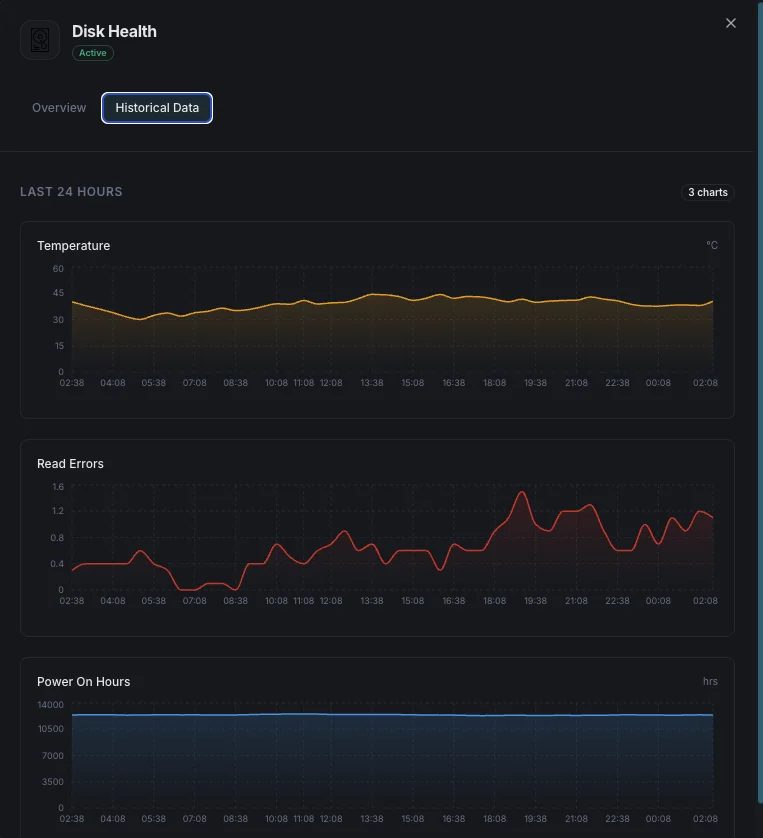
Temperatura
Temperatura actual del disco en grados Celsius.
Sectores reasignados
Cantidad de sectores defectuosos remapeados.
Horas de encendido
Horas operativas totales del disco.
Tasa de errores de lectura
Tasa de errores de lectura encontrados.
Sectores pendientes
Sectores esperando ser remapeados.
Temperature_Celsius (SMART 194)
Temperatura actual de la unidad. Los HDD se degradan por encima de 50 °C; los SSD de consumo hacen throttling por encima de 70 °C. Alerte en el máximo nominal del fabricante menos 10 °C para una advertencia temprana.
UDMA_CRC_Error_Count (SMART 199)
Errores CRC relacionados con el cable en la interfaz SATA/SAS. Los valores crecientes señalan un cable defectuoso o una conexión floja: una solución fácil que a menudo se diagnostica erróneamente como fallo de unidad.
Desgaste de SSD (Wear_Leveling_Count + Total_LBAs_Written)
Seguimiento de la resistencia del SSD. `Wear_Leveling_Count` normaliza la vida restante; `Total_LBAs_Written` más el TBW nominal de la unidad indican el porcentaje de desgaste actual. Alerte al 80% utilizado.
percentage_used de NVMe
Desde `nvme smart-log`: la estimación del fabricante de la vida consumida (0-100%, puede superar el 100% en unidades desgastadas). Advierta por encima del 80%; crítico por encima del 95%.
available_spare de NVMe
Porcentaje de capacidad de reserva restante para el reemplazo de bloques defectuosos. Advierta por debajo del 10%; crítico por debajo del 5% (`available_spare_threshold` suele establecerse ahí).
critical_warning de NVMe
Bitfield de `nvme smart-log` que señala: reserva por debajo del umbral, temperatura por encima del umbral, fiabilidad del dispositivo degradada, modo solo lectura, fallo del backup de memoria volátil. Cualquier valor distinto de cero = alerta inmediata.
Configurables condiciones de activación de alertas
Configura alertas personalizadas en tu panel de control para recibir una notificación en cuanto las métricas de «Disk Health» superen los umbrales que hayas definido.
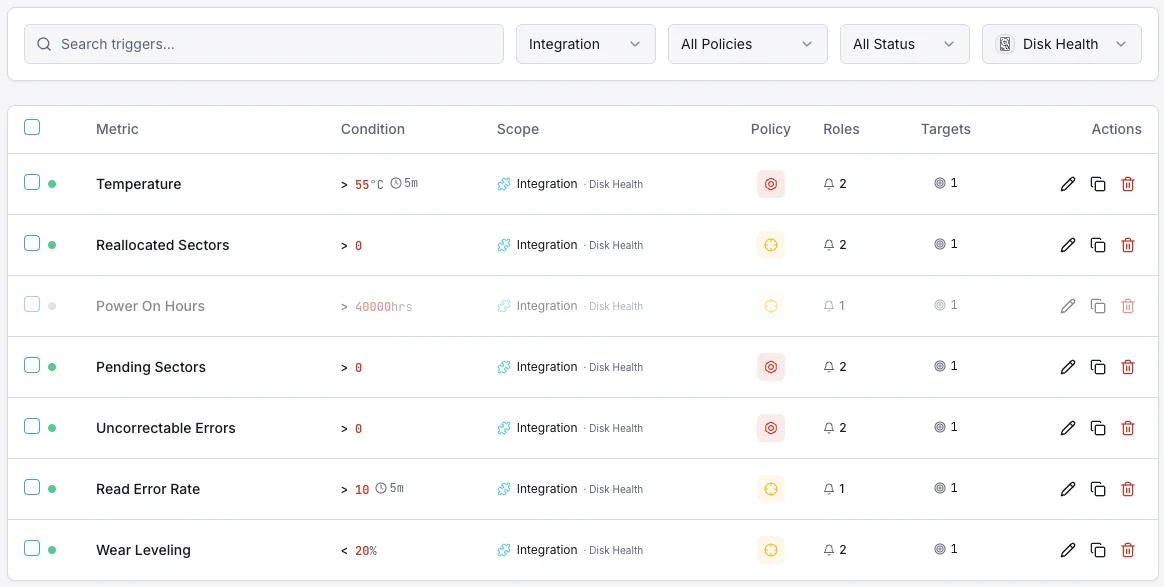
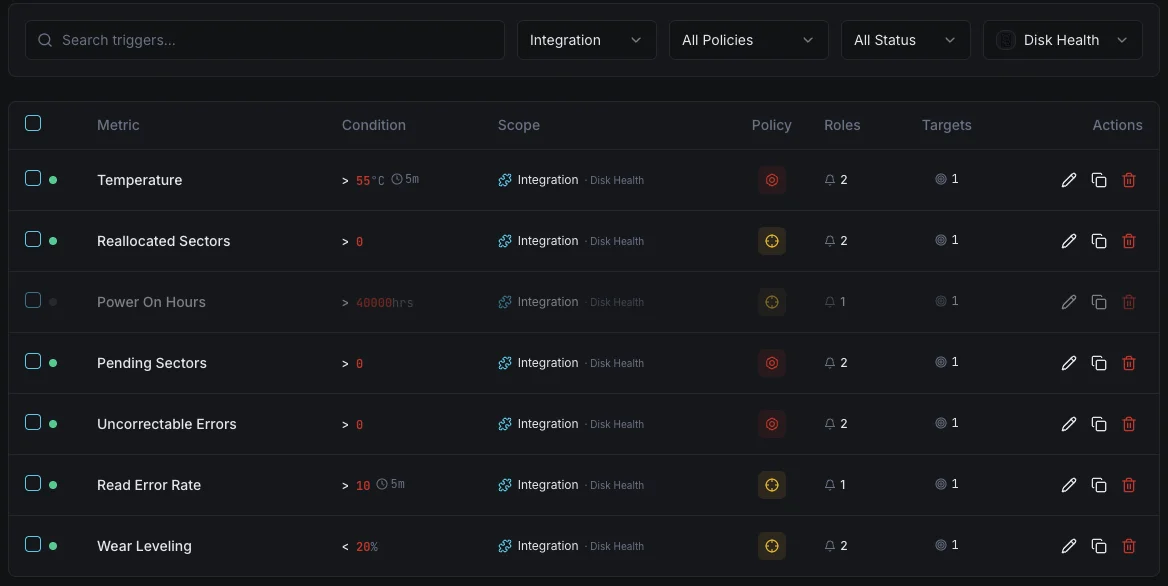
Estado de salud SMART
críticoSe dispara cuando SMART reporta un estado de salud fallido.
Sectores reasignados
críticoAlerta cuando el número de sectores reasignados supera el umbral.
Temperatura del disco
advertenciaSe activa cuando la temperatura del disco supera el rango operativo seguro.
Sectores pendientes
advertenciaSe dispara cuando el número de sectores pendientes indica un fallo potencial.
Importancia de la monitorización de la salud del disco
Los fallos de disco pueden provocar pérdida de datos y caídas costosas. La monitorización SMART ofrece señales tempranas — desde aumentos de temperatura y crecimiento de sectores reasignados hasta picos en errores de lectura — para que pueda actuar antes de que un disco falle.
- Evite la pérdida de datos con detección temprana de fallos
- Optimice el rendimiento identificando cuellos de botella
- Planifique la capacidad con análisis histórico de tendencias
- Mantenga el cumplimiento con monitorización de integridad de datos
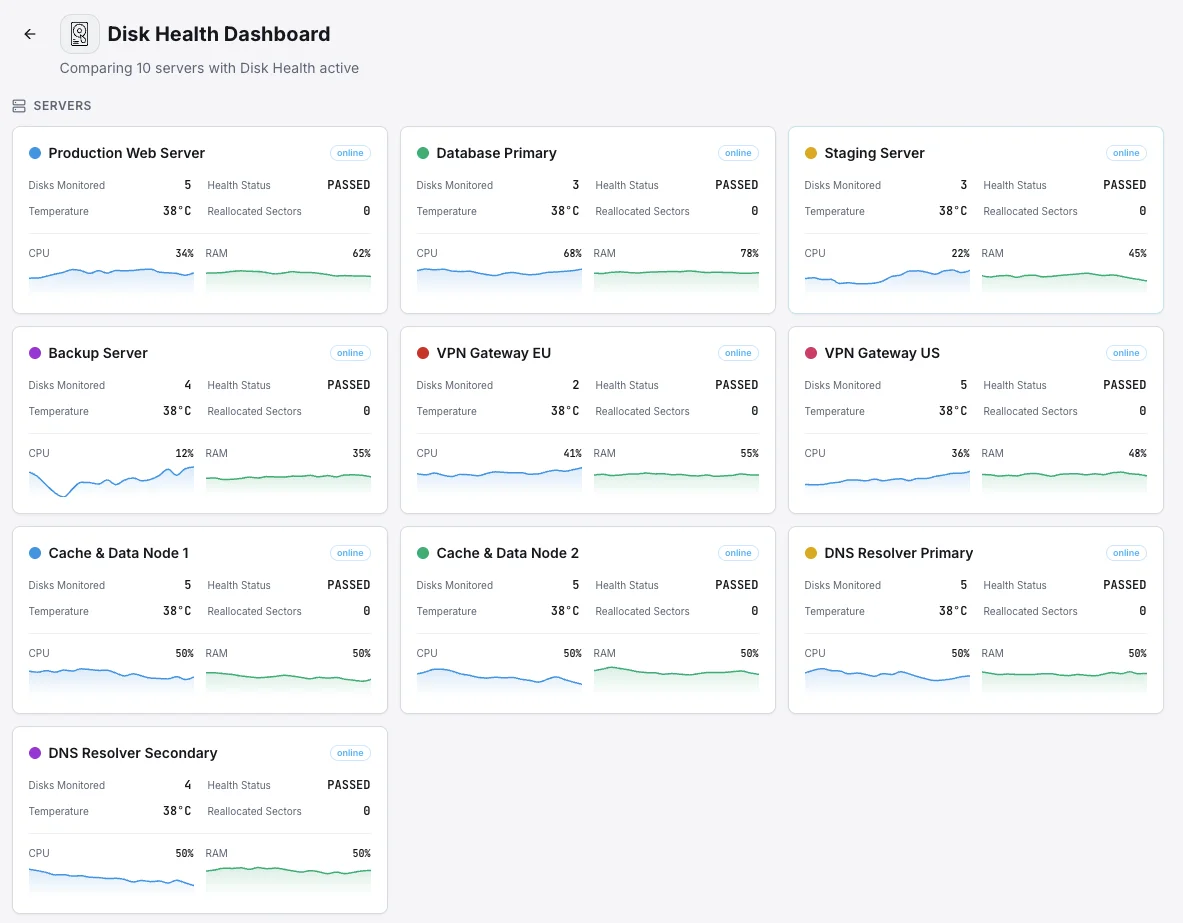
Por qué elegir Xitoring
Xitoring proporciona monitorización de salud de disco sin configuración con integración SMART para todos los tipos de disco. Obtenga alertas en tiempo real, tendencias históricas e indicadores predictivos de fallo en un único panel.
- Compatible con SSD, HDD y matrices RAID
- Configuración con un solo comando en Linux y Windows
- Umbrales personalizables de atributos SMART
- Alertas multicanal para eventos críticos de disco
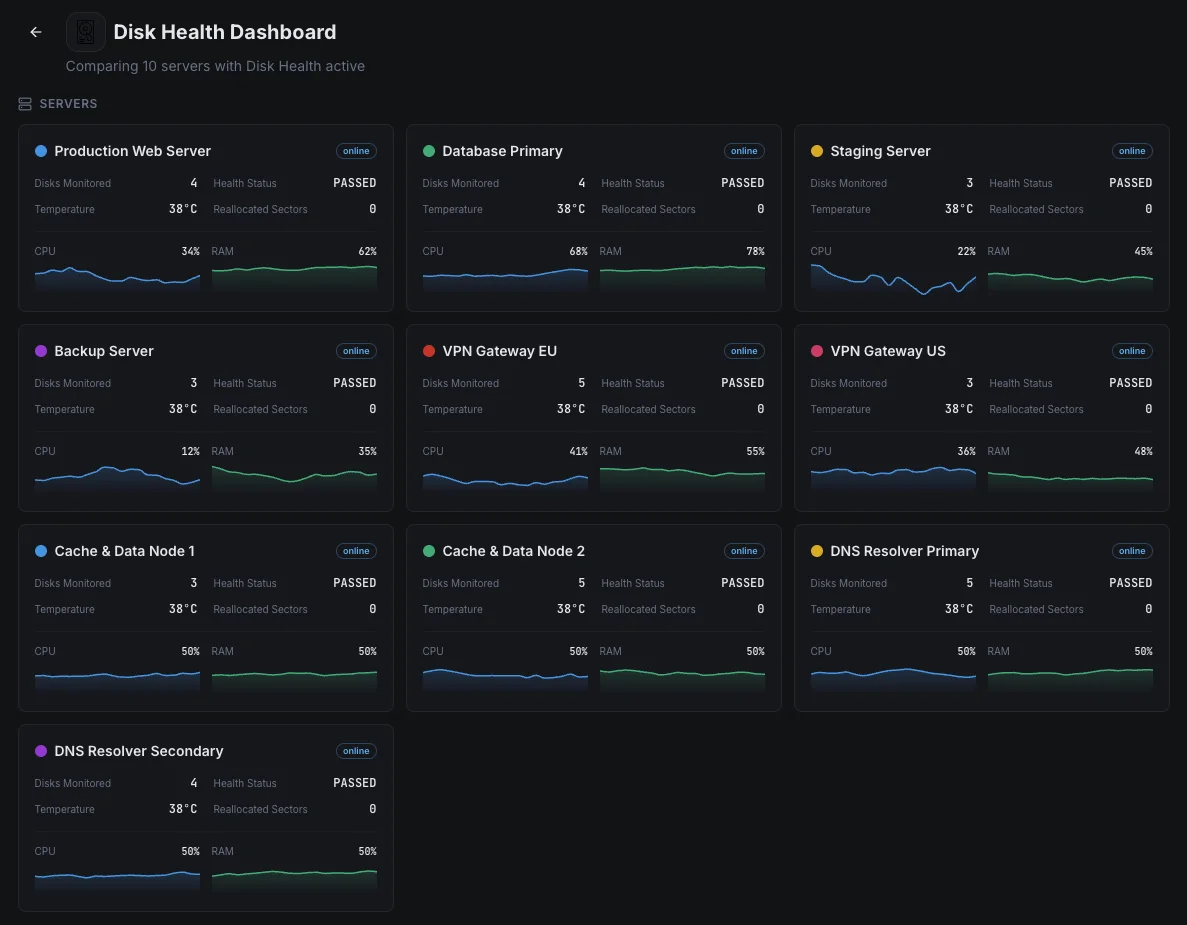
Escenarios habituales de monitoreo de la salud del disco
Dónde la monitorización de discos detecta con mayor frecuencia los fallos de las unidades antes de que causen daños reales.
Servidores de bases de datos
Una unidad fallida en una base de datos puede significar tiempo de inactividad, pedidos perdidos o, en el peor de los casos, datos corruptos. Vigilamos cada unidad en busca de las señales tempranas de fallo para que el equipo pueda reemplazar un disco con problemas según su propio horario — no en medio de una interrupción a las 3 AM.
Servidores de respaldo y archivo
El problema único con las unidades de respaldo es que un fallo permanece invisible hasta el día en que realmente necesitas la copia de seguridad — para entonces ya es demasiado tarde. Probamos cada unidad según un horario y detectamos el desgaste temprano para que nunca busques una copia de seguridad que no existe.
Servidores que escriben muchos datos (SSD)
Las SSD tienen un número limitado de escrituras antes de desgastarse, y las bases de datos ocupadas y las aplicaciones con muchos datos las agotan más rápido de lo que la mayoría de los equipos se dan cuenta. Hacemos un seguimiento del desgaste en porcentajes claros para que las unidades se reemplacen a tiempo — no después de un fallo repentino e irrecuperable.
Requisitos previos para Disk Health
Asegúrate de tener todo esto en su sitio — la mayoría de las instalaciones tardan 60 segundos una vez listo.
- Servidor Linux (Debian/Ubuntu, RHEL/CentOS, o distribución compatible)
- Paquete smartmontools instalado (smartctl) y lsblk disponible
- Acceso sudo / root — los datos SMART requieren permisos elevados
Empieza con minutos
Instalar los requisitos previos (Linux)
Instala smartmontools para habilitar la recolección de datos SMART. Comprueba que lsblk esté disponible en tu sistema.
# Ubuntu/Debian
sudo apt-get install smartmontools
# CentOS/RHEL
sudo yum install smartmontoolsHabilitar la integración de Disk Health
Ejecuta el comando integrate y selecciona Disk Health. Xitogent detecta automáticamente tus discos y comienza a recolectar datos SMART. No se requieren prerrequisitos en Windows.
xitogent integrateVerifica que funciona
Ejecuta este comando en el servidor para confirmar que Xitogent ha detectado la integración. En unos 30 segundos comenzarán a llegar métricas nuevas a tu panel.
sudo xitogent status¿Estás considerando alternativas?
Mira cómo se compara Xitoring frente a las alternativas para la supervisión de Disk Health: precios planos, integraciones más profundas y un solo agente que cubre todo tu stack.



Con frecuencia preguntas formuladas
¿Qué tipos de discos son compatibles?
¿Tengo que instalar algún programa adicional?
¿Puedo supervisar las unidades NVMe?
¿Con qué frecuencia se recopilan los datos?
¿Qué atributos SMART predicen el fallo de la unidad?
¿Cómo monitoreo la salud de las unidades NVMe?
¿Cómo monitoreo la salud del disco en Windows?
¿Con qué frecuencia debo ejecutar los autotests de smartctl?
¿Funciona con matrices RAID?
Empieza a seguir a Disk Health hoy
Se configura en menos de 60 segundos. No se necesita tarjeta de crédito. Estadísticas completas desde el primer día.
Empieza tu prueba gratuita