InfluxDB Seguimiento
Supervisa el rendimiento de escritura de InfluxDB, el rendimiento de las consultas, las métricas del motor de almacenamiento y el estado de las políticas de retención en tiempo real sin necesidad de configuración.
¿Por qué realizar un seguimiento? InfluxDB?
InfluxDB es la base de datos de series temporales líder para métricas, eventos y análisis en tiempo real. La supervisión de InfluxDB garantiza una ingesta de datos correcta, un rendimiento óptimo de las consultas y una gestión adecuada de la retención.
Monitoreo de InfluxDB, explicado
El monitoreo de InfluxDB detecta estancamientos en el rendimiento de escritura, cardinalidad de series desbocada (el clásico modo de fallo de InfluxDB 1.x/2.x), acumulaciones en la compactación TSM, ralentizaciones de consultas y crecimiento de WAL antes de que provoquen pérdida de ingesta o timeouts de consulta en sus dashboards de Grafana. Para pipelines de sensores IoT, backends de métricas de aplicación y cualquier despliegue del stack TICK, la visibilidad por base de datos es lo que separa una alerta de 60 segundos de un incidente de varias horas persiguiendo puntos de datos perdidos. Xitoring autodescubre su InfluxDB, lee el endpoint nativo Prometheus /metrics y enruta las alertas a Slack, PagerDuty, Telegram o su guardia existente.
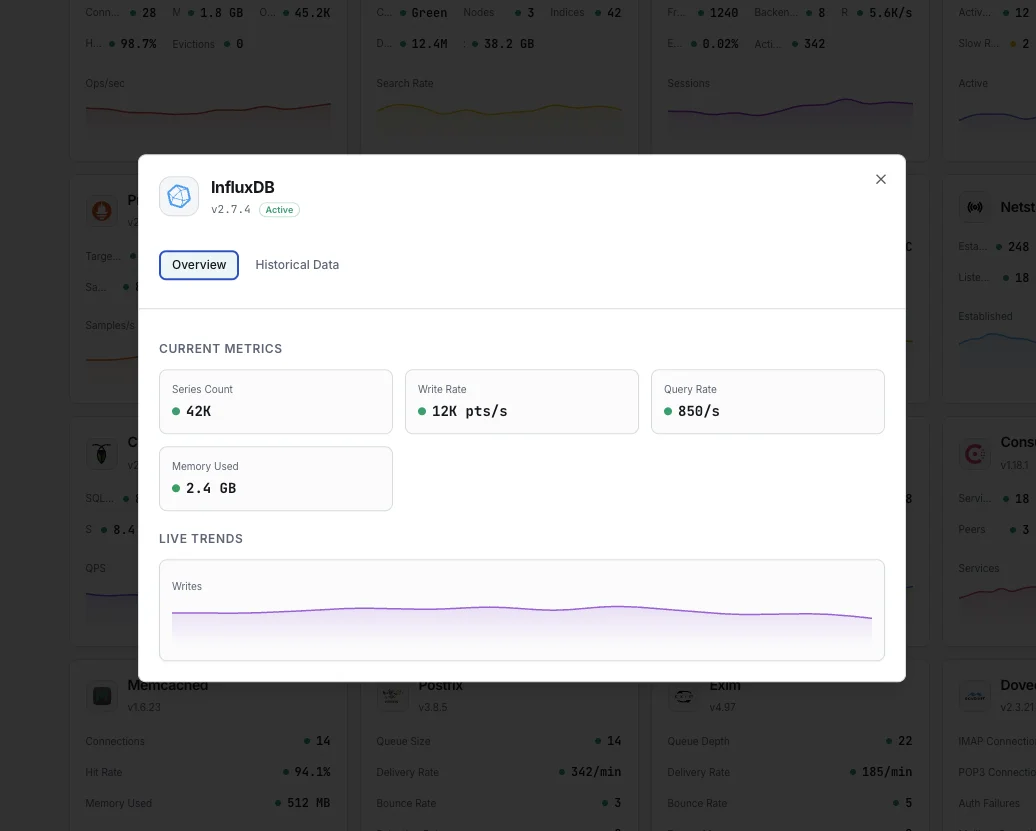
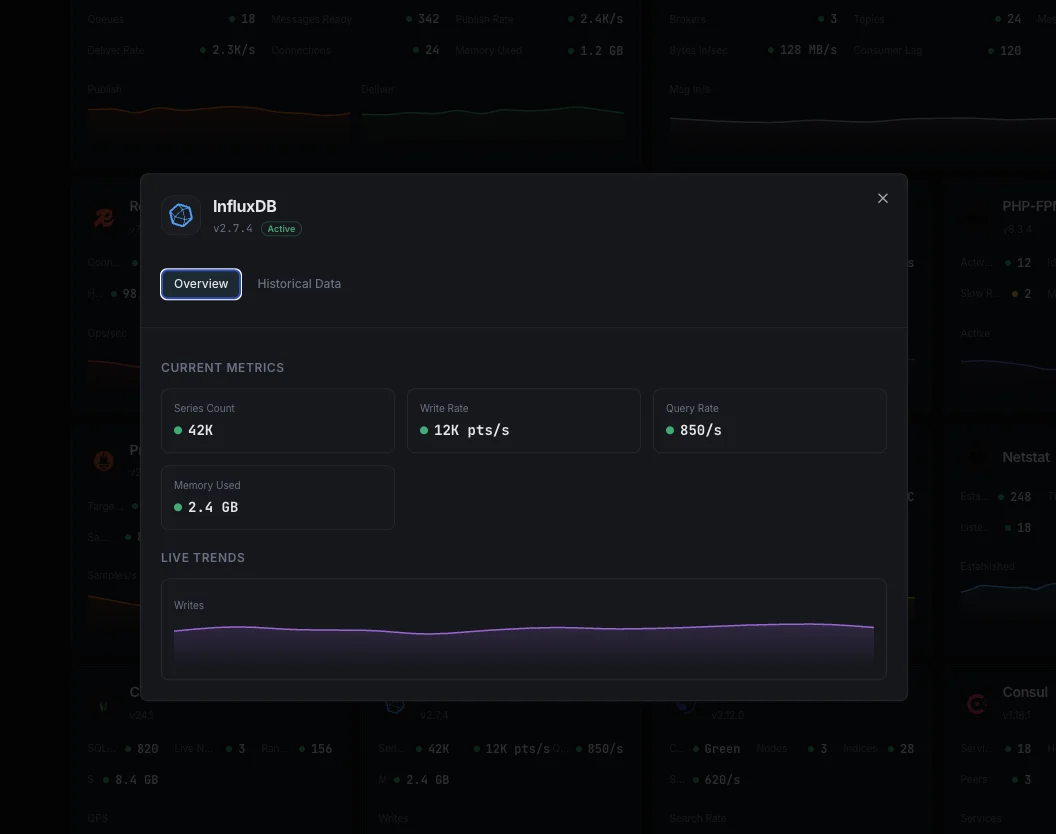
Lo que monitorizamos
Puntos escritos/s
Tasa de escritura de puntos de datos.
Duración de consultas
Tiempo medio de ejecución de consultas.
Cardinalidad de series
Total de series temporales únicas.
Tamaño del almacenamiento
Almacenamiento TSM en disco.
Tasa de compactación
Throughput de compactación TSM.
Tamaño del caché
Uso del caché de escritura en memoria.
Bytes en disco del WAL
`storage.tsm1.wal.currentSegmentDiskBytes` + `oldSegmentsDiskBytes`. El crecimiento del WAL sin consolidación TSM significa que el tiempo de recuperación se disparará al reiniciar.
Tamaño de almacenamiento en disco
`storage.tsm1.filestore.diskBytes` + numFiles por shard. Rastréelo frente a su política de retención — un alto número de archivos para el mismo tamaño de datos señala fragmentación.
Tasa de HTTP 4xx / 5xx
`httpd.clientError` + `httpd.serverError` (o el Prometheus `http_api_request_errors_total`). Los picos de 4xx señalan bugs de esquema/autenticación del cliente; los 5xx señalan fallos en el lado del servidor.
Conexiones / Fallos de autenticación
`httpd.req` (total de solicitudes HTTP), `httpd.authFail` (intentos de autenticación fallidos), `httpd.pingReq`. Los picos de fallos de autenticación indican Telegraf mal configurado o rotación de credenciales mal hecha.
Runtime — Goroutines y GC
Estadísticas del runtime de Go: `runtime.NumGoroutine` (detección de fugas de goroutines), `runtime.HeapAlloc` (heap activo), `runtime.NumGC`/`PauseTotalNs` (presión del GC). Detecte fugas y regresiones en los tiempos de pausa antes del OOM.
Escrituras de suscripción
`subscriber.pointsWritten` y `subscriber.writeFailures` — cuando Kapacitor o pipelines descendentes consumen vía suscripciones, así es como detecta su backpressure.
Configurables condiciones de activación de alertas
Configura alertas personalizadas en tu panel de control para recibir una notificación en cuanto las métricas de «InfluxDB» superen los umbrales que hayas definido.
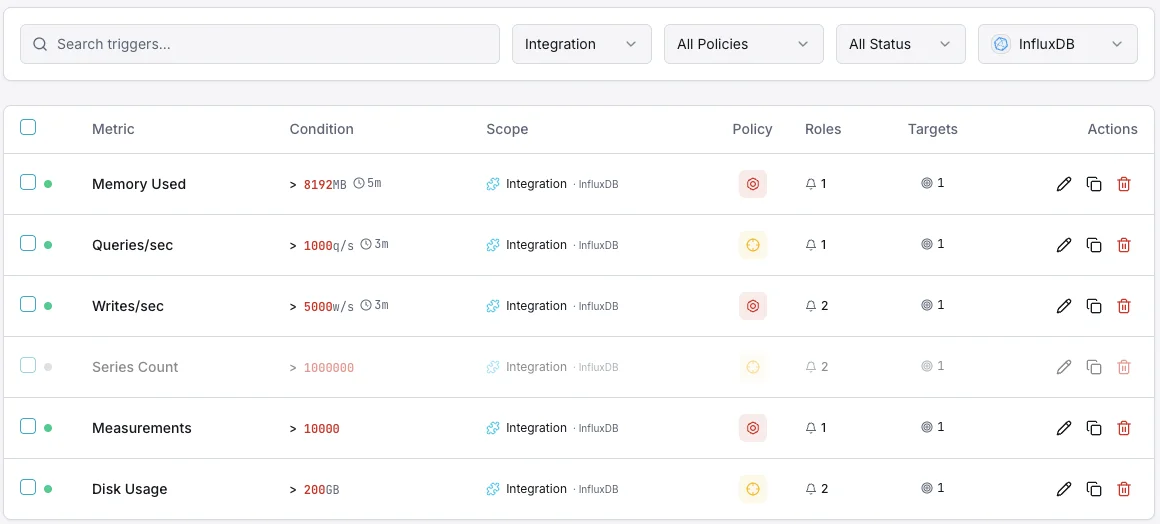
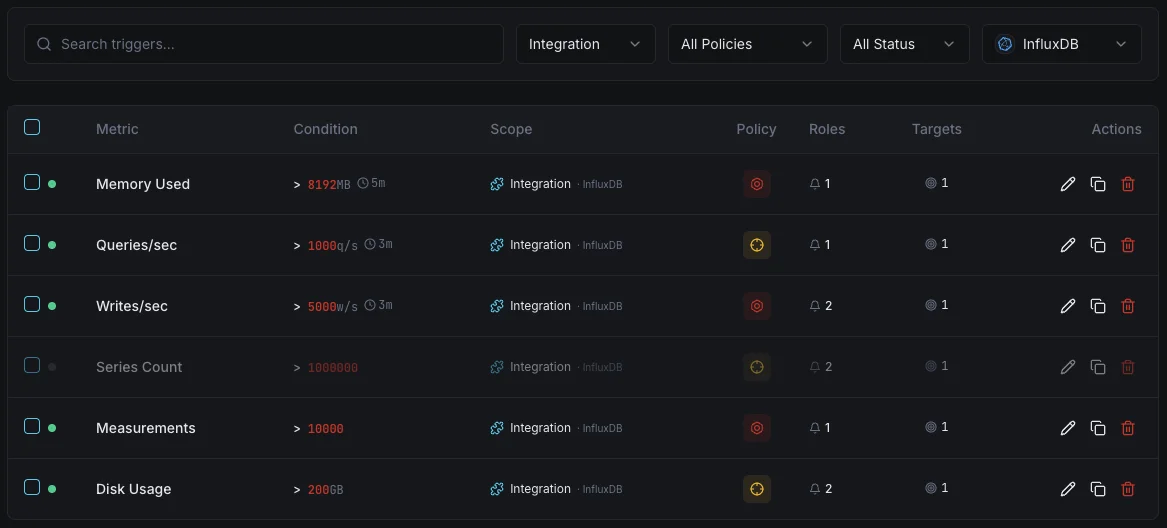
Throughput de escritura
advertenciaSe dispara ante anomalías en la tasa de escritura.
Duración de consultas
advertenciaAlerta sobre consultas lentas.
Cardinalidad de series
críticoSe activa cuando la cardinalidad es demasiado alta.
Tamaño del almacenamiento
críticoSe dispara cuando el almacenamiento supera el umbral.
Importancia de la monitorización de InfluxDB
InfluxDB maneja datos de series temporales a alta velocidad. La alta cardinalidad, la presión de escritura y los retrasos en la compactación pueden degradar el rendimiento.
- Realice un seguimiento del throughput de escritura para la salud de ingestión
- Monitorice la cardinalidad de series para prevenir OOM
- Detecte de forma temprana las consultas lentas
- Asegúrese de que la compactación se mantiene al día
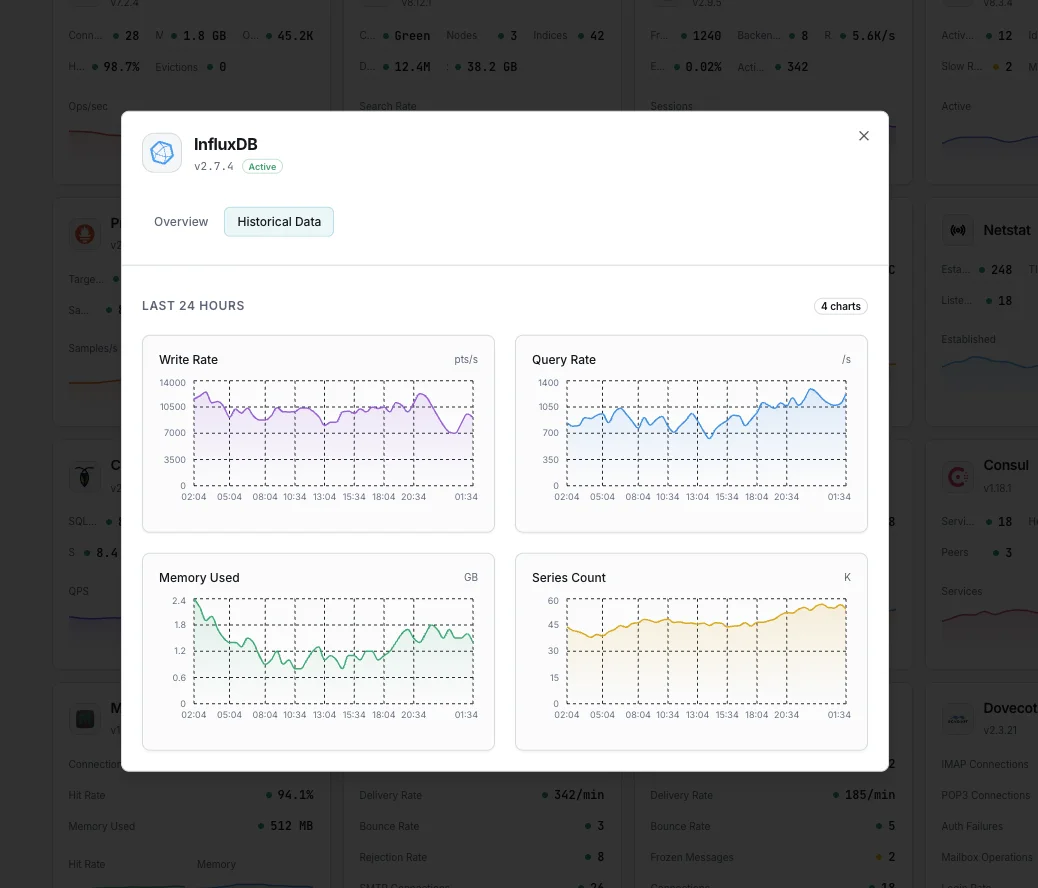
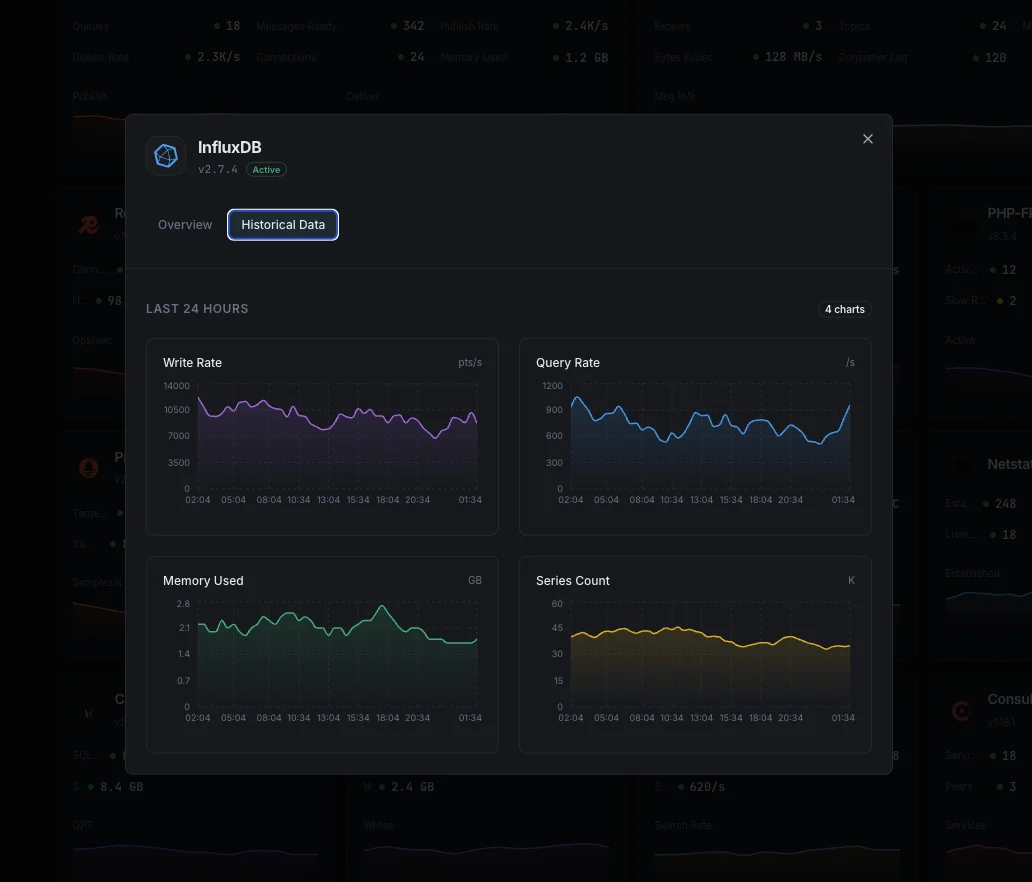
Por qué elegir Xitoring
Monitorización InfluxDB sin configuración.
- Instalación con un solo comando
- Nodos globales
- Panel unificado
- Alertas multicanal
- Retención histórica
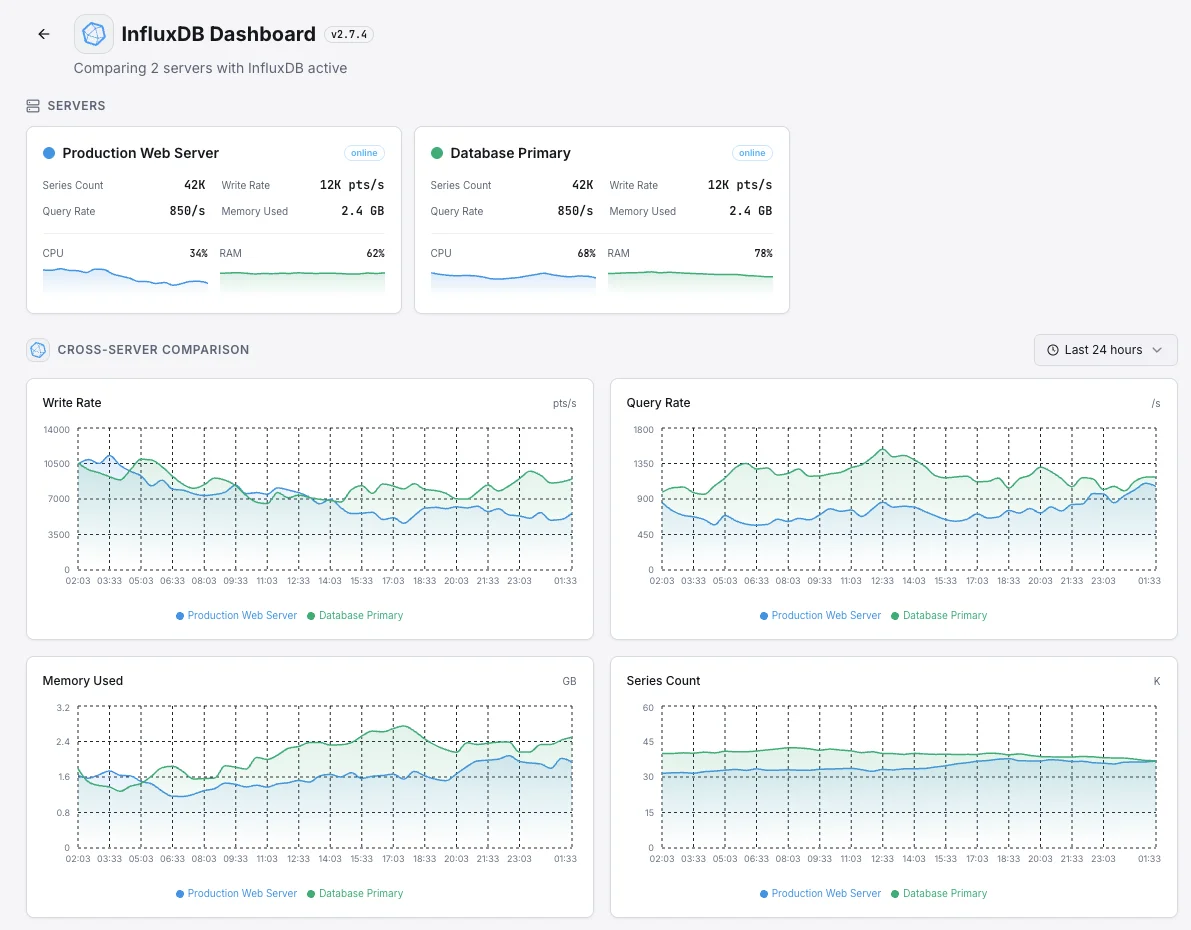
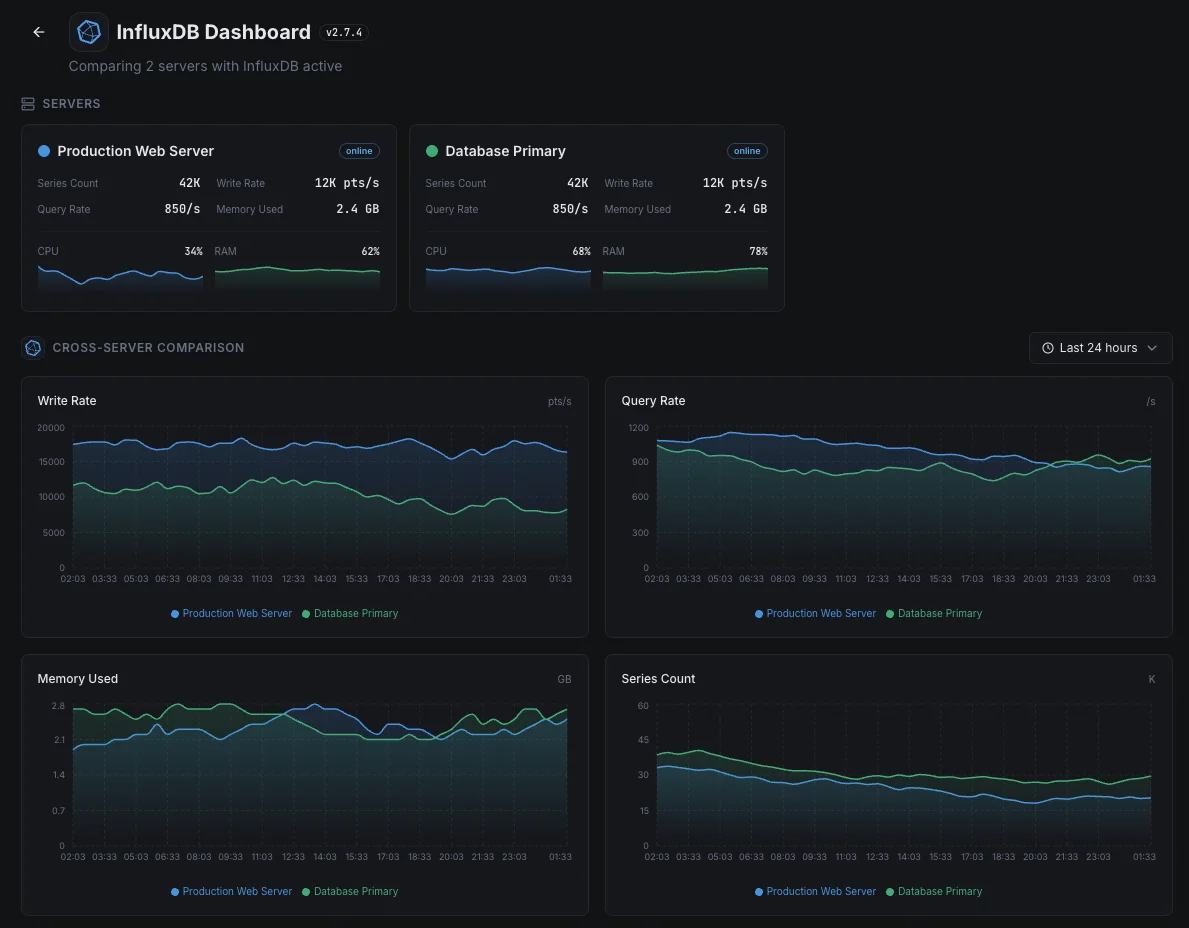
Escenarios habituales de monitoreo de InfluxDB comunes
Dónde suele ejecutarse InfluxDB hoy en día, y qué podría salir mal si nadie está vigilando.
La base de datos detrás de los paneles de control de su equipo
Cuando los paneles de control en Grafana u otra herramienta se sienten lentos, la causa suele ser la base de datos subyacente, no el propio panel. Sacamos a la luz dónde reside realmente la lentitud para que el equipo arregle lo correcto en lugar de perseguir el síntoma.
Datos que fluyen desde sensores y dispositivos
Los dispositivos conectados, el equipo de fábrica y los sensores IoT envían mediciones cada segundo de cada día. Un respaldo silencioso en la tubería significa datos perdidos, y los datos perdidos se pierden para siempre. Vigilamos el flujo de principio a fin para que una sola lectura perdida active la alarma.
Métricas de aplicaciones e infraestructura en un solo lugar
Cuando la misma base de datos contiene métricas de aplicaciones y métricas de servidor, un problema con la base de datos oculta todas las señales a la vez. Vigilamos la base de datos en sí para que el propio monitoreo del equipo nunca se apague durante un incidente.
Requisitos previos para InfluxDB
Asegúrate de tener todo esto en su sitio — la mayoría de las instalaciones tardan 60 segundos una vez listo.
- InfluxDB 1.x o 2.x ejecutándose en el servidor
- Puerto HTTP de InfluxDB accesible desde Xitogent (predeterminado 8086)
- Opcional: un token de solo lectura si la autenticación de InfluxDB 2.x está habilitada
Empieza con minutos
Instalar Xitogent en tu host InfluxDB
Instala el agente de monitorización ligero Xitogent en el host que ejecuta InfluxDB.
curl -s https://xitoring.com/install.sh | sudo bash -s -- --key=YOUR_API_KEYConfirmar que InfluxDB es accesible
Verifica que InfluxDB está escuchando en su puerto HTTP (predeterminado 8086) y es accesible desde el host que ejecuta Xitogent. Xitogent preguntará por el host y el puerto durante el integrate — no se requieren ediciones de configuración adicionales ni exposición de endpoints.
sudo xitogent integrateHabilitar la integración de InfluxDB
Usa el panel de Xitoring o la CLI para habilitar la integración de InfluxDB. Xitogent detecta automáticamente tu versión de InfluxDB y comienza a recolectar métricas de escritura, consulta y almacenamiento.
Configurar umbrales de alerta (opcional)
Define umbrales personalizados para throughput de escritura, duración de consultas o cardinalidad de series para detectar presión de ingesta y crecimiento descontrolado de tags antes de que las consultas se ralenticen.
Verifica que funciona
Ejecuta este comando en el servidor para confirmar que Xitogent ha detectado la integración. En unos 30 segundos comenzarán a llegar métricas nuevas a tu panel.
sudo xitogent status¿Estás considerando alternativas?
Mira cómo se compara Xitoring frente a las alternativas para la supervisión de InfluxDB: precios planos, integraciones más profundas y un solo agente que cubre todo tu stack.



Con frecuencia preguntas formuladas
¿InfluxDB 1.x y 2.x?
¿Qué repercusión tiene?
¿Cómo detecto problemas de cardinalidad en InfluxDB?
¿Qué es la base de datos _internal en InfluxDB?
¿Cómo monitoreo las compactaciones de InfluxDB?
¿Cuál es la diferencia entre el monitoreo de InfluxDB 1.x, 2.x y 3.0?
¿Cómo detecto lentitud en las consultas de InfluxDB?
¿Cómo monitoreo el almacenamiento TSM de InfluxDB?
¿Esta integración afectará al rendimiento de InfluxDB?
Empieza a seguir a InfluxDB hoy
Se configura en menos de 60 segundos. No se necesita tarjeta de crédito. Estadísticas completas desde el primer día.
Empieza tu prueba gratuitaSigue explorando